
基于图网络优化及标签传播的小样本图像分类算法
2022-02-14 12:42刘颖车鑫
信号处理 2022年1期
刘 颖 车 鑫
(1.西安邮电大学图像与信息处理研究所,陕西西安 710121;2.电子信息现场勘验应用技术公安部重点实验室,陕西西安 710121)
1 引言
深度学习[1-2]的广泛应用在计算机视觉等领域取得了巨大进展,但作为一项数据驱动的技术,其性能严重依赖于海量带标签的图像数据,对于图像数据不足的情况,易出现过拟合现象。然而,收集大量的标注数据面临着许多挑战。一方面,对于公安领域、濒危物种以及医疗等领域,由于数据的特殊性及安全性,很难获取大量的图像样本。另一方面,对于数据的采集、标注需要消耗大量的人力物力资源,这一情况也制约着算法的性能。故此,如何通过少量的训练数据训练性能优良的网络模型成为了现阶段一个研究热点。小样本学习[3]旨在少量带有标签的样本上学习知识,对其余未带标签的新样本进行预测分类,成为解决这类问题的关键技术。
作为早期的尝试,朴素贝叶斯近邻方法[4]和KNN 算法[5]在小样本学习研究背景下证明了它的有效性,但分类精度有限。而元学习作为当前的研究热点,能够利用先前经验快速的学习新任务,不再孤立的考虑新任务,实现了良好的分类性能。元学习又叫做学会学习,它解决的是让机器像人类一样具备学会如何学习的能力[6]。常见的元学习方式是将学习算法编码进卷积神经网络中,包括基于度量的方法、基于模型的方法和基于优化的方法[7]。基于度量的方法是当前应用最广泛的方法,它是将图像映射到一个度量空间并使用某种度量方式计算不同图像样本的差异,例如,孪生网络[8]使用两路神经网络以提取样本特征,并通过距离度量公式实现分类;Matching Networks[3]通过余弦距离度量支持集样本和查询集样本间的相似性,查询集样本属于和它相似性大的支持集样本所在的类别;Prototypical Networks[9]对每个类别的样本提取中心点作为原型,通过欧几里得距离进行度量;CovaMNet[5]算法是一种基于分布一致性的协方差度量网络,通过计算类别和查询样本分布之间的一致性来度量类别和查询样本之间的关系。Graph Neural Networks(GNN)[10]是通过图神经网络学习节点之间的关系,并将其作为度量来对未知样本进行分类。Simon 等人[11]提出一种自适应子空间算法,该算法通过使用奇异值分解(SVD)为每个类别计算出一个特征空间的子空间,将查询样本的特征向量投影到子空间中进行距离度量。GCR(Global Class Representations)[12]提出一种新的小样本训练方式,将包含大量样本的基类别和少量样本的新类别一起进行训练,得到每个类别的表征定义为全局类别表征,将支持集类别表征通过注册模块得到注册类的全局表征,最后选出与当前Episode 类别表征最相近的n个类别表征,并使用欧式距离来进行度量。BSNet(Bi-Similarity Network)算法[13]提出一种双相似性度量网络,根据不同特征的两个相似度度量学习特征图,能够学习到更多有区别性和更少相似性偏差的特征信息,从而显著提高模型的泛化能力。基于模型的方法,如Santoro等人[14]提出基于记忆增强的算法,结合了LSTM 和额外的内存存储模块。其优势是减少了网络的参数量,避免了对训练数据的依赖。MetaNet[15]是通过基学习器与元学习器之间的高阶信息反馈学习新的任务。文献[16]采用更传统的带有闭式解的可微分回归方法(如:岭回归、逻辑回归)来替代K-NN、LSTM 等学习算法,以一种新颖的思路降低数据维度的同时保证基学习器的学习能力。文献[17]提出了一种任务无偏的思想,通过引入正则化损失项(最大化熵减和最小化不平等性)的方式约束模型,能够在参数更新时,减小训练任务偏好,提升模型的泛化能力。基于优化的方法,如:MAML(model-agnostic meta-Learning)[18]使用少量的梯度迭代步骤就可以学习到适用于新任务的参数。基于特征增强元学习优化方法[19],首先利用凸优化问题的性质来优化基学习器,之后使用压缩双线性网络来增强通道间关系并实现降维,同时通过空间注意力来增强特征表示。不同于以上基于优化的方法,Aravind 等人[20]提出一种优化的MAML 算法,该算法的核心是利用隐微分,在求解过程中仅需内循环优化的解,而不需要考虑整个内循环优化器的优化过程,在不增加计算成本的同时,解决梯度消失问题。
由于图神经网络在表示样本间关系方面的优势,现阶段越来越受研究者的广泛关注。该网络结构由节点和边组成,其中节点表示的是一个样本图像,由节点产生邻接矩阵表示为边,即样本间的关系,通过迭代地执行节点特征和节点关系更新,预测没有标签的样本图像,从而完成小样本图像分类任务。2018 年,Victor[10]首次将图神经网络引入小样本图像分类任务中,提出了一个端到端的GNN,它利用支持集和查询集进行特征提取,并以此作为图网络的节点获得边作为度量,通过迭代地更新图的过程构建类间和类内样本的关系完成分类任务。与之不同,CGA-GNN(Category-relevant Graph Affinity-Graph Neural Network)[21]通过对GNN 加入一种新的类别相关的图相似度度量来显式地描述查询集样本与支持集样本之间的关系。TPN(Transductive Propagation Network)[22]并未直接使用图网络对未知样本预测,而是通过图网络输出的特征将标签从支持集样本传递到查询集样本实现分类。EGNN(Edge-labeling Graph Neural Network)[23]采用边标记的框架,显式地建模类内相似性和类间差异性,通过迭代更新边的标签并用于样本聚类。
现有算法主要从构建有效的图网络结构入手,通过几个卷积块提取图像特征,而未深入挖掘图像特征对于图网络性能的影响。本文算法通过增强目标显著性区域特征来初始化节点特征,从而获得样本间更丰富的关系型信息来对图网络进行优化。具体来说,该模型由图神经网络[10],CBAM(Convolutional Block Attention Module)注意力模块[24],以及标签传播模块[22]构成。通过CBAM 模块增强图像中有区别部分的权重来对图节点初始化,有效地提高图像目标域特征的表征力。之后通过节点之间的信息传递得到图网络的边作为度量,从而隐式地加强类内样本的相似性,增大类间样本的差异性。最后使用边进行标签传播来预测未知样本,提高模型的分类准确性。
本文其余部分结构如下,第2 节详细地描述了本文算法;第3 节给出了实验结果和分析;第4 节对全文进行总结。
2 本文算法描述
2.1 问题定义
在小样本图像分类过程中,数据集由训练集、验证集和测试集组成。其中,训练集用于学习不同任务的分类器,验证集用于分类器模型的选择,测试集用于分类器模型的测试,数据集之间没有交集。采用匹配网络[8]的定义,将数据分为多个子任务T,每个子任务T都包含一个支持集S以及一个查询集Q。从训练集中随机采样N类数据,每类数据再随机抽取K个样本作为支持集S==1,2,...,K;n=1,2,...,N},共计ST=N*K个有标注数据;然后从上述采样的N类中剩下的样本中选取b个样本作为查询集Q==1,2,...,b,n=1,2,...,N},共计QT=b*N个,其中x和y分别表示图像和类别标签。同样,验证集与测试集也进行同样的设置来模拟小样本学习的情况。研究目的是要在仅有N×K个样本的支持集参考下,对查询集中所有样本作出正确分类,这样的问题称为N-way Kshot问题。
2.2 算法框架
如图1所示为本文算法框图。通过突出目标的显著性区域来初始化图节点特征,增强样本之间的相关性。该算法包括嵌入模块、CBAM 注意力模块、图神经网络模块和标签传播模块。对于嵌入模块,我们采用四层卷积块提取图像特征。另一方面,为了避免特征冗余,添加了CBAM注意力模块来增强关键区域特征权重,并以此作为初始化节点特征来提升特征的表示能力。之后根据图神经网络构建节点之间的关系,并对其使用标签传播来预测未知样本。
2.2.1 嵌入模块
该嵌入模块由4 个卷积层构成,不同于GNN 算法的嵌入模块,本文算法的每个卷积层仅具有64个大小为3×3 的卷积核。该操作目的在于减少网络的计算参数,加快学习速率。每个卷积层的网络结构如图2所示。
通过如上图4个相同结构的卷积层提取支持集和查询集样本图像特征,如式(1),其中,Fs和Fq分别表示经过嵌入模块提取后的支持集特征和查询集特征。f(·)表示为具有全连接层的4层卷积神经网络,support和query表示为支持集和查询集样本。
2.2.2 CBAM 注意力模块
为了优化图网络节点特征,本文提出使用CBAM注意力机制来增强显著性区域特征。如图3所示,该注意力模块结合了通道注意力(CAM)和空间注意力(SAM)模块。其中,通道注意力是用来学习需要关注“什么”的问题;空间注意力是学习需要关注的“在哪里”的问题。通过结合两种注意力来形成一种互补的作用,从而进行图神经网络节点特征初始化。
首先将嵌入模块获取的图像特征映射F∈RC×H×W作为输入特征,其中C表示通道数,H表示图像的高,W表示图像的宽;通道注意力模块通过利用特征的通道间关系产生通道关注,分别进行全局平均池化和最大池化,从而获得两个通道描述符∈R1×1×C和∈R1×1×C。将其输入到具有两层神经网络的感知器,并将得到的两个特征相加后经过一个Sigmoid激活函数得到权重系数MC。
其中σ(·)表示为Sigmoid 函数,θC表示为2 层感知器(W)的参数。最后,使用权重系数MC和嵌入模块获得的特征F相乘即可得到缩放后的新特征F′。
空间注意力通过利用特征的空间关系来产生。将F′进行平均池化和最大池化得到两个通道描述符∈R1×H×W和∈R1×H×W,并将这两个描述符通道拼接在一起,经过一个激活函数为Sigmoid的7×7的卷积层,得到权重系数MS。
其中θS表示卷积层(Conv)的参数,C(,)表示两个描述符的拼接,σ(·)表示为Sigmoid 激活函数,将权重系数MS与F′相乘得到最终细化后的特征图F″∈RC×H×W。
2.2.3 图神经网络
通过将CBAM 模块提取的图像特征与相应的独热编码(one-hot Encoding)标签进行拼接(对于未知样本,与全零标签进行拼接)视为图神经网络的初始节点特征,将其作为节点输入到如图4 所示的三层图网络中,并从当前节点的隐藏信息学习边的特征表示,即为图中节点间的关系,
其中Zi表示为更新的图节点特征,φ为一个对称函数,它是通过两个节点向量差的绝对值叠加多层神经网络构造的。再根据式(5)更新图节点特征,
其中g(·)表示为更新图的全连接层,Ai表示为第i个图中的边。通过迭代计算三次,不断进行节点间信息传递,得到一个三层的图神经网络,提升了图网络的学习性能。
2.2.4 标签传播模块
通过初始化节点特征,使得图神经网络节点之间的关系得到了增强。并将节点之间边的权重进行归一化操作,用来进行对未知样本的预测。如图5 所示,根据图神经网络构建的样本间的关系进行标签传播。
首先构造一个尺寸为(N×K+Q)×N的非负矩阵M,其中N表示支持集包含的类别数,K表示每个类别包含的样本数,Q表示查询集样本数。矩阵B∈M通过迭代的方式进行更新:
其中,Bt表示为第t次迭代的预测矩阵,E表示归一化的边权重,即E=,其中D为对角矩阵,A为学习到的边权重,α∈(0,1)表示为传播信息的数量。Y∈M,若带有标签的样本来自于支持集,则Y=1,否则为0。迭代之后,B将收敛为B*=(I-αE)-1Y,I表示为单位矩阵。并最终利用Softmax 进行概率的预测,实现小样本图像分类任务。
3 实验结果
3.1 数据集介绍
本实验在以下5个小样本图像数据集上测试验证模型的性能,其示例如图6所示。
miniImageNet[3]:是由Google DeepMind 团队提出的小样本学习任务最常用的基准数据集之一。包含100 个类别,每个类别600 张图像,共计60000张图像数据。64 类作为训练集、16 类作为验证集、20类作为测试集。
CUB-200[25]:是由加州理工学院提出的细粒度鸟类图像数据集,包含200 种鸟类,130 类作为训练集、20 类作为验证集、30 类作为测试集,共计6033张图片。
Stanford Dogs[26]:是由斯坦福大学提出的细粒度小狗图像数据集,包含120 种狗,70 类作为训练集、20 类作为验证集、30 类作为测试集,共计20580张图片。
Stanford Cars[27]:是由斯坦福大学提出的细粒度汽车图像数据集,包含196 类汽车,130 类作为训练集、17 类作为验证集、30 类作为测试集,共计16185张图片。
CIIP-TPID[28]:是由西安邮电大学图像与信息处理研究所建立的轮胎花纹图像数据集,包含67类不同品牌型号的轮胎花纹图像。其中,表面花纹数据集(每类80张)、压痕花纹数据集(每类80张)以及混合花纹数据集(每类160张)。44类作为训练集、10类作为验证集、13类作为测试集。且该数据集为2019年亚洲ACM多媒体挑战赛提供轮胎花纹图像数据[29]。
3.2 实验设置与评价指标
本算法采用LeakyReLU 作为激活函数,交叉熵损失函数作为损失度量,将Batch size 大小设为10。采用Adam 优化器,其初始化的学习率为0.0005,每迭代20000 次使学习率衰减一半,衰减权重为10-6。且为了较为公平的对比算法性能,所有算法的嵌入模块均仅由几个简单的卷积层构成。
实验中,采用2.1节所述的N-way K-shot作为评价指标。通过执行5-way 1-shot、5-way 5-shot得到分类准确度来验证本文算法的优越性,
3.3 实验结果
实验一,miniImageNet小样本图像分类
如表1 所示,在miniImageNet 数据集上执行5-way 1-shot、5-way 5-shot 进行测试,图像输入尺寸为84 ×84。与两个经典的小样本图像分类算法K-NN、NBNN 和基于元学习的小样本图像分类算法进行对比测试,验证本文算法的优越性。
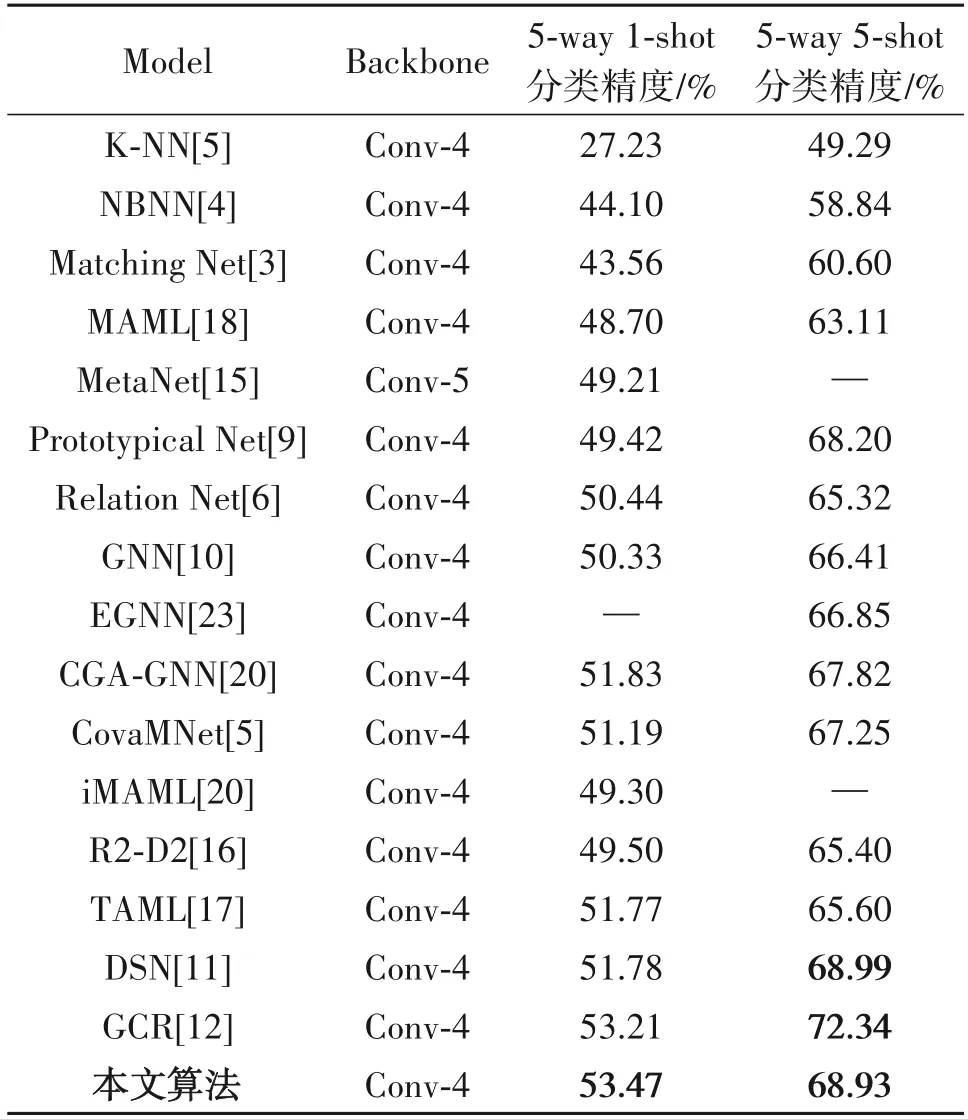
表1 在miniImageNet上实现小样本学习的分类精度Tab.1 Classification accuracy of few-shot learning on miniImageNet
通过实验发现,本文算法在miniImageNet 数据集上实现了优良的小样本图像分类性能。相对于GNN 算法精度有了明显的提升,5-way 1-shot、5-way 5-shot 精度分别提高了3.14%和2.52%。在1shot实验中,本算法精度均高于其他小样本学习算法,相比于次优GCR 算法,精度高出0.26%;但在5shot实验中,精度低于最优算法3.41%,但分类精度与次优算法基本持平,验证了本文算法对于解决经典的小样本学习问题是有效的。
实验二,小样本细粒度图像分类
如表2、表3 所示,分别在三个小样本细粒度基准数据集和自建的轮胎花纹图像数据集上进行实验,其中,对于表2 数据集,输入图像尺寸为84 ×84,对于表3 轮胎花纹数据集,输入图像尺寸为48 ×48。不同于一般的粗粒度图像分类任务,细粒度的图像分类任务更具挑战性,因为细粒度数据集的类间差异较小,类内差异较大。同样,与经典的小样本图像分类算法和基于元学习的算法对比,验证本算法同样适用于小样本细粒度图像分类任务。
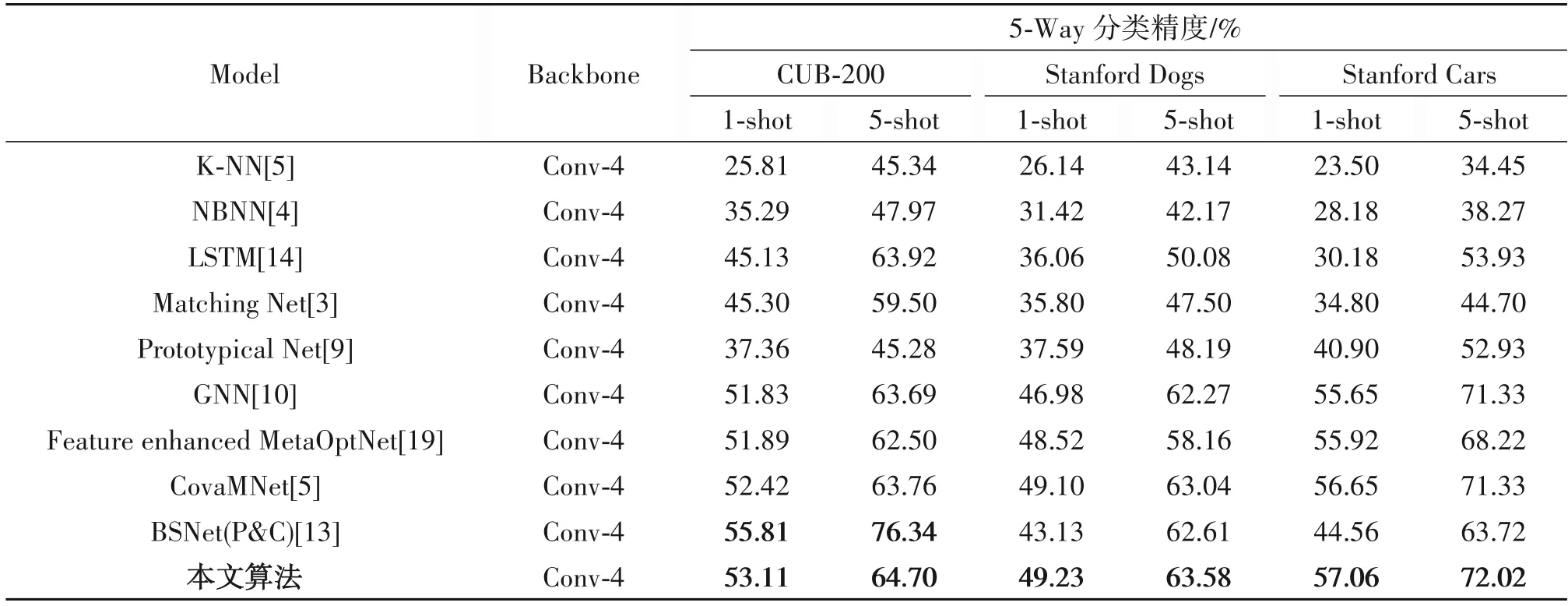
表2 在三个细粒度基准数据集上的5-way 1-shot和5-way 5-shot分类精度Tab.2 Classification accuracy of 5-way 1-shot and 5-way 5-shot on three fine-grained benchmark datasets
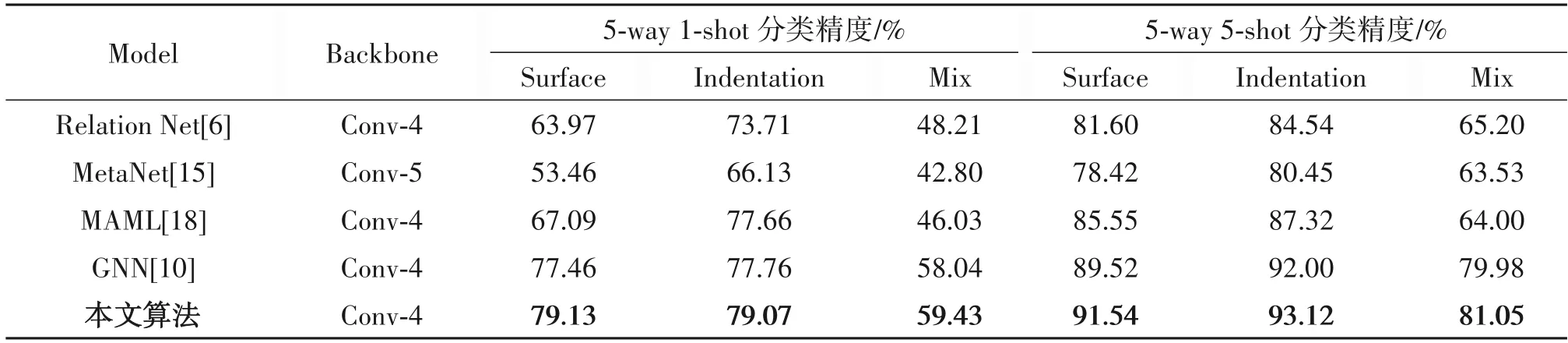
表3 在CIIP-TPID上实现小样本学习的分类精度Tab.3 Classification accuracy of few-shot learning on CIIP-TPID
通过以上实验发现,除CUB-200 数据集外,本文算法分类结果均优于其他算法,证明本算法在解决小样本细粒度图像分类问题上依然是有效的。对于1-shot 任务,比GNN 算法平均提高了1.55%的分类精度;对于5-shot 任务,相较于GNN 算法平均提高了1.2%的分类精度。
实验三,半监督学习实验
通过以下实验,我们对本文算法进行半监督的5way-5shot 实验。与监督学习相比较,半监督学习中支持集样本的标签分别随机用20%、40%、60%的真实标签标注,如表4所示,为不同数据集上进行半监督小样本学习的分类精度。
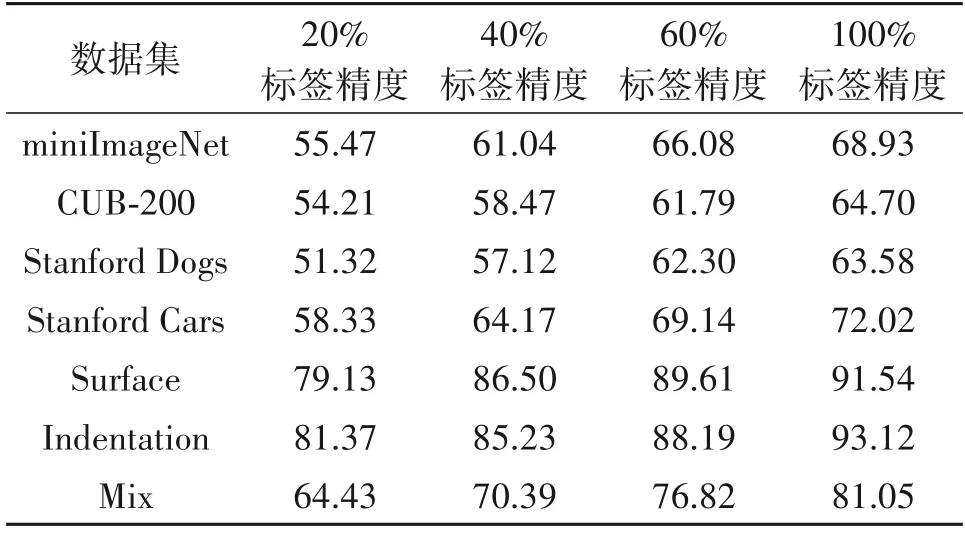
表4 本算法执行半监督学习的分类精度Tab.4 Classification accuracy of the algorithm performs semisupervised learning
通过半监督实验发现,本文算法在半监督学习下依然适用,能够在仅有少量标签信息的图像分类任务中保持有效性。如miniImageNet 数据集下,仅有60%标签数据的情况下,仍能达到其他算法在全监督学习的分类效果。尤其在仅有60%标签的情况下,平均仅低于全监督情况下3.0%的分类精度,验证了本文算法使用未知查询集样本来构建图神经网络的方法是有效的。
3.4 实验结果分析
通过以上实验发现,基于元学习的算法分类精度远高于传统的小样本学习算法,原因在于传统的小样本学习算法没有训练阶段,对新任务学习能力不足,体现了元学习方法的优越性。
其次,通过实验一和实验二对比发现,在全监督学习下基于元学习的小样本图像分类算法在miniImageNet 数据集下的分类精度普遍高于细粒度基准数据集下的分类精度。这是由于细粒度图像类间差异小,类内差异大,使得分类难度加大。
最后,通过以上三个实验证明,本算法在全监督和半监督学习下依然有效,对于1-shot 和5-shot的分类任务精度均有明显提升,证明本算法通过对图节点优化增强了节点之间边的度量关系,即为样本之间的相关性,对其使用标签传播预测未知样本标签,能够获得优良的分类精度。
4 结论
本文提出一种基于图网络优化及标签传播算法来解决小样本图像分类任务。通过引入CBAM注意力模块增强图像显著性区域特征,获得更具表征力的目标特征作为初始化节点来优化图网络。之后通过多次迭代来实现节点之间的信息传递得到样本之间的关系型信息,即节点之间的边,从而隐式地增强样本之间的相关性。最后通过标签传播来引导未知样本进行有效分类。通过大量实验验证了本算法在全监督和半监督学习情况下的有效性。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
现代电力(2022年2期)2022-05-23
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
电子制作(2019年24期)2019-02-23
领导决策信息(2018年16期)2018-09-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2017年12期)2017-04-23
数学学习与研究(2017年3期)2017-03-09
Coco薇(2015年11期)2015-11-09
