
基于GA-BP算法的红茶色泽分类研究
2022-02-18 10:14谭卓昆段红星吴文斗
福建茶叶 2022年2期
周 兵,谭卓昆,段红星,刘 亮,张 竞,吴文斗
(1.云南农业大学理学院,云南 昆明 650201;2.云南大学 信息学院,云南 昆明 650500;3.云南农业大学茶学院,云南 昆明 650201;4.云南农业大学大数据学院,云南 昆明 650201)
中国有源远流长的茶文化,茶礼茶俗等。随着中国经济的发展,茶的需求量逐步增加,各类茶企发展迅速,茶产品层出不穷,为了有利于品牌的宣传,对茶叶品质进行评价成为必不可少的一环。传统评价方式易受评审人员与评审环境等诸多因素影响,如何使评价过程更为简便科学,是目前在茶叶评定领域较为迫切的任务之一,而色泽作为茶叶品质评审的主要内容,对其进行标准且科学的评价便极其重要。
目前对茶叶色泽的评价主要看茶叶外表色泽、茶汤色泽和叶底色泽,以此来了解茶叶品质的高低及制作工艺。但在实际评审过程中,往往因为不同人员对色泽的感官强弱不同,使得评价结果存在一定的主观误差。国外对茶叶品质因子和茶叶质量评定的研究应用越来越多,P Mishra等人在2019年使用近红外高光谱测量绿茶数据,构建绿茶分类模型,实现了16种绿茶产品的分类。国内大部分仍是采用人工感官审评的方法进行,但也不乏创新性的茶叶品质评价的研究。2016年,潘玉成等利用人工神经网络对绿茶色泽进行茶叶品质的评定,对标准样和预测样本获得了较令人满意的评判结果。2019年,帅晓华等人采用计算机视觉技术,对拍摄的茶叶和茶水图片进行识别分类,识别的准确率总体达到90%。两者的研究中选取的样本数较少,条件控制不足,即便是同一种茶类,由于品控因素,如干茶制作时温度、干湿度不同,都会对茶类的分级造成极大的影响。
为解决误差问题,本文设计的实验严格控制红茶干茶光照时长,茶汤冲泡的时间、温度、水质,以及叶底测量方式,最大限度排除环境因素带来的干扰误差。利用具有精确色彩识别能力的色差仪测定不同色泽类型的 L(亮度值)、a(红绿色值)、b(黄蓝色值)范围,基于GA-BP算法将测量的数值与人工感官评价的结果建立数学模型,找到红茶不同类型的干茶、茶汤、叶底色差值与人工感官评价的相关性,构建茶叶色度值参数与茶叶色泽类型数据评审模型,较好的实现了茶叶的分类识别,为茶叶色泽类型的数字化评定提供了科学依据。
1 材料与方法
1.1 红茶数据
1.1.1 干茶数据。红茶干茶通过将嫩叶,经发酵等工艺制作而成。本研究选取了市场上常见种类的红茶,如:古树红茶、名优红茶等茶种。为了使数据丰富,具备科学性、普适性,又从已选取的红茶种类中挑选了不同价位、不同品质及规格的红茶干茶。实验用的干茶样本如图1所示:

图1 部分干茶样本及相应色泽人工评审结论
通过筛选、评估,共选取63份红茶干茶,用色差仪测得380组数据,可分为乌黑、乌黑带毫、乌黑有毫、乌黑多金毫、乌褐显金毫、金黄共计六个干茶评定色类。
1.1.2 茶汤数据。用热水冲泡前述干茶样本即得茶汤数据。对汤色进行L、a、b值测量时,发现同一种茶类在不同温度、不同水质下测量的色差值不同;不同的温度、不同水质下的不同茶类测量的数据范围会相互重叠。所以我们选用同一种类的矿泉水,茶叶称量5克左右,将水加热至93℃时开始冲泡。用测温枪检测茶汤的温度,当茶汤降温至30℃左右时,对不同茶类的茶汤,在封闭式的色差仪中进行L、a、b值的测量。研究所用的红茶茶汤如图2所示。

图2 部分茶汤样本及相应色泽人工评审结论
本研究选取了60份红茶干茶进行冲泡,用色差仪测得400组数据,可分为杏黄、橙黄、橙红、红亮、红浓、红艳、红暗共计七种茶汤评定色类。
1.1.3 叶底数据。叶底也叫茶渣,即干茶经开水冲泡后所展开的叶片。红茶叶底越有光泽,品质越好。判断方法是首先将泡过的茶叶倒入洁净的器皿中,再将茶叶拌匀铺开进行观察后给出结论。由于发酵程度不一致,相同种类红茶的叶底色泽也是不同的,为了尽量减少这个问题带来的误差干扰,评审人员以大面积的茶叶色泽分布作为叶底颜色分类的依据。

图3 部分叶底样本及相应色泽人工评审结论
在色差仪测量叶底前,首先用机器将叶底打碎,收入相应容器中,再对其进行L、a、b值的测量,使数据更加稳定、可靠。本研究选取了63份红茶叶底,用色差仪测得380组数据,可分为泛青、泛青稍带红、棕红较匀稍青、棕红、红共计五大叶底评定色类。
1.2 实验仪器
本次研究的测量仪器采用封闭式的色差仪(深圳市三恩时科技有限公司的 YS6060 色差仪),实物图如图4所示,该仪器能够减少在不同环境条件下,给数据测量带来的误差干扰,同时本研究的色差值数据是由专业人员进行专业测量、评估,测量的 L、a、b值更加准确。

图4 色差仪实物图
1.3 实验设计
1.3.1 GA-BP网络搭建。GA-BP算法就是使用遗传算法(GA)将BP神经网络的权值和阈值作为初始种群,不断的迭代进化,寻找出全局最佳的权值和阈值,实现对BP神经网络的优化。GA-BP算法流程如图5所示:
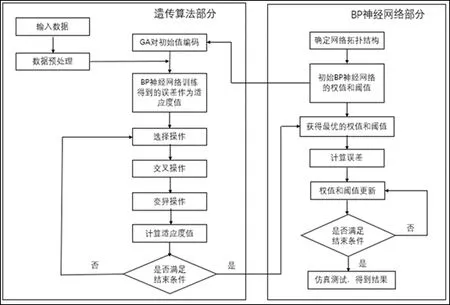
图5 GA-BP算法流程图
1.3.2 网络参数设置及测试。BP神经网络模型隐含层包含的神经元节点个数能反映出整个网络的非线性水平,进行参数设置时,找到该网络最佳隐含层节点数是十分困难的。若隐含层节点个数过多,不仅会增加神经网络的学习时间,而且还会出现“过拟合”现象;若隐含层节点个数过少,网络甚至无法训练或使用。我们通过对样本数据准确率结果分析,判断各节点数对网络模型的影响,确定相关模型的最优隐含层节点数。隐含层节点常用计算公式如下所示:
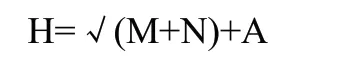
式中 H——隐含层节点数;
M——输入层节点数;
N——输出层节点数;
A——取1到10的整数。
红茶干茶、茶汤、叶底网络模型的隐含层节点范围如表1所示。
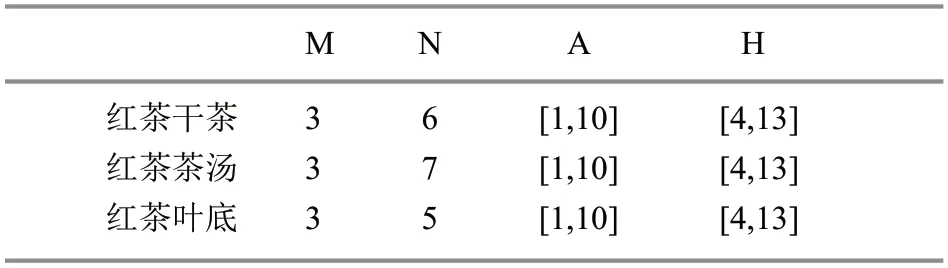
表1 各样本种类隐含层范围的确定
依次选取可能的隐含层节点数,测试相应数据集的准确率,训练集数据的各隐含层节点数与各样本准确率的分布如表2所示。

表2 各样本训练集隐含层节点数的准确率
通过对比不同隐含层节点数对应的训练集识别的准确率,将均方误差最小时的隐含层节点数目确立为最佳。求得红茶干茶、茶汤、叶底的最佳隐含层节点数目分别为13、10、8。另外,在其它网络参数的配置上,本研究设置网络的训练次数为1000次,显示频率为25,即每训练25次显示1次,学习速率为0.01,动量因子为0.01,最小性能梯度为10-6,并设置最高失败次数为6次。
1.3.3 学习方式的选择。为寻找最适合本次研究的学习方式,选择红茶干茶色泽数据集对增加动量算法、弹性BP算法、自适应学习算法、共轭梯度算法、LM算法分别进行测试。通过网络训练,再随机选取数据对模型进行测试,比较不同学习方式对测试数据集预测的准确率,结果如表3所示。

表3 不同学习方式对干茶色泽预测的准确率
测试的结果显示LM算法的效果最好,三次平均准确率可达到93.75%,因此后面的研究过程中选择该算法对网络进行训练。
2 结果与分析
2.1 红茶干茶数据的测试结果及分析
为了检验GA-BP算法应用效果,我们选用了100组干茶数据对模型进行测试。同时,将标准BP神经网络模型作为对照组,将两种模型的测试结果进行分析。根据测试结果可知标准BP神经网络对红茶干茶色泽数据识别效果一般,准确率只有85.86%,而且存在少部分识别结果和正确结果误差较大的数据。而GA-BP神经网络模型分类识别更为精准,数据准确率为94.95%。
2.2 红茶汤色数据的测试结果及分析
在茶汤数据的测试中,选用了105组红茶汤色数据对GA-BP模型与标准BP模型进行测试,标准BP神经网络分类识别的准确率为80.95%,使用GA-BP算法的网络模型的准确率可达到95.23%。
2.3 红茶叶底数据的测试结果及分析
在叶底数据的测试中,选用了95组红茶叶底数据对模型进行测试。标准BP神经网络对大部分数据识别比较精准,但是也存在少部分识别结果和正确结果误差较大的数据,其分类识别的准确率为88.54%,而GA-BP网络模型极大提高测试集数据分类识别的准确率,其测试准确率为90.62%。
3 结论
经过红茶的干茶、汤色、叶底数据的测试,使用GA-BP算法对干茶、汤色、叶底数据测试的准确率分别为94.95%、95.23%、90.62%,模型的分类识别效果较好,GA-BP算法使得全局寻优能力、数值范围交叉的数据处理能力更佳,分类结果与专家评估较为一致,通过本次研究获得的网络模型,机器视觉识别的结果可以与人工评审结果做最好的关联。这不仅大大减少了人工评审带来的主观误差,也能为茶叶色泽类型的量化审评提供科学依据,较好地推动茶产业的数字化发展进程。
猜你喜欢
数学大王·趣味逻辑(2022年8期)2022-07-10
ELLE世界时装之苑(2022年1期)2022-01-08
东方企业家(2019年11期)2019-10-30
阅读(快乐英语高年级)(2019年5期)2019-09-10
VOGUE服饰与美容(2019年6期)2019-07-17
茶道(2019年1期)2019-02-16
茶道(2018年9期)2018-02-16
传奇·传记文学选刊(2017年7期)2017-07-21
世界热带农业信息(2014年12期)2015-01-21
阅读与作文(初中版)(2014年7期)2014-08-21
