
基于贪吃蛇算法和部首识别的手写文本切分
2022-02-21 04:43付鹏斌董澳静杨惠荣
华南理工大学学报(自然科学版) 2022年1期
付鹏斌 董澳静 杨惠荣
(北京工业大学 信息学部,北京 100124)
汉字种类多、结构复杂、书写随意性强,手写文本中极易出现交错、粘连、重叠、字内字间距离不固定等现象。错误的切分必然导致错误的识别,因此提高手写文本切分正确率对识别有着重要的意义。目前,文本切分方法主要有投影法[1]、连通域搜索[2]、滴水算法[3]、基于识别反馈的切分方法[4- 5]和基于字体结构的切分方法[5- 6]。单一切分算法难以有效解决手写文本切分中的复杂问题。Zhao等[7]提出了一种粗切分与细切分结合的方法,首先通过垂直投影和背景骨架分析得到粗切分结果,然后细化粘连字符,找出候选笔画和特征点,利用模糊决策规则得到细切分结果,然而这种模糊决策的标准不易被确定。马瑞等[8]提出多步切分方法,利用Viterbi算法[9- 10]进行初切分,然后基于骨架图像分析粘连字符,最后利用A*算法求出最优切分路径,该方法切分效果明显好于单一算法,但未能解决字符多重粘连问题。李小园等[11]提出基于结构聚类和笔画分析的方法,仅针对两个汉字粘连的情况。Xu等[12- 13]定义双层学习滤波器提取候选粘连点,但滤波器对无约束手写数据的适应性不高。对于过切分字符,吴相锦等[14]依照字距和宽高特征进行合并,实现较简单,但准确性不高;Wu等[15]利用识别置信度指导合并,效果较好,但由于将整个文本切分序列作为搜索全集,合并计算量较大。近年,有学者提出基于无切分的端到端场景文本识别方法[16],由于中文文本行的语义关联性不够强,效果不算很好,同时该方法要求海量数据和高硬件性能。
本研究提出的基于贪吃蛇算法和部首识别的手写中文文本切分方法,模拟贪吃蛇运动轨迹作为切分依据,结合汉字特征、宽高阈值、部首结构、邻域上下文信息和识别置信度等,对中文文本进行切分和合并,得到正确的文本切分结果;其可应用于教育领域的主观题自动阅卷等方面。
1 基于贪吃蛇的手写中文文本切分
1.1 贪吃蛇切分算法设计
基于垂直投影的切分算法只能形成竖直路径,无法解决字符之间的交错、粘连、重叠等问题;基于连通域的切分方法容易使连通元过碎,而真正粘连的字符,也不能通过连通域切分开;滴水算法通过模拟水滴向低处滚动形成非线性切分路径,该算法可以取得比竖直切分更好的效果,但由于水滴在笔划内部形成垂直渗透,造成字符损伤,并不适合处理具有复杂结构的手写中文文本。
本研究的贪吃蛇切分算法,通过模拟贪吃蛇在文本图像中爬行得到非线性切分路径。将待切分文本图像中的字符作为贪吃蛇爬行过程中的障碍物,规定爬行起点,且爬行趋势为竖直方向。以向下爬行为例,若蛇在爬行过程中遇到障碍物,则沿障碍物边缘继续向下;若蛇进入字符凹陷区域,则逐步回溯,回溯轨迹不加入有效路径,最终到达终点的有效轨迹形成原始切分路径,之后依据多重约束规则对其进行优化,得到候选切分路径。贪吃蛇爬行过程中不穿过字符笔划,因此减少了字符损伤。
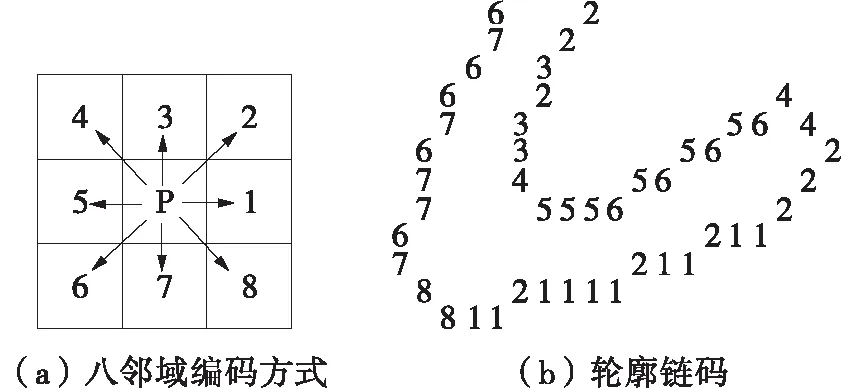
待切分文本图像为预处理后的二值图像,贪吃蛇每一步爬行均与当前点下面3个像素和左右2个像素有关,其爬行规则如图1所示,其中:·表示当前点位置;b表示字符像素点;w表示背景像素点;★表示任意像素点,即该点的像素值不会影响贪吃蛇的路径选择;→表示贪吃蛇下一步的运动轨迹;=>表示像素转换。图1(a)示出了当前点邻域5像素的位置及命名。如图1(b)所示,只要p3为背景像素,则下一步都将向p3爬行;若p3为字符像素,依次按照图1(c)-1(f)判断下一步爬行方向,根据背景像素点的位置,贪吃蛇可以向右下、左下、右、左爬行,但不切断字符像素;特殊情况为图1(g)所示,贪吃蛇进入字符凹陷区域,无法向下行进,则回溯到前一点,同时将该点标记为字符像素点。

图1 贪吃蛇爬行规则Fig.1 Rules of snake’s crawling
本算法对手写文本进行两次切分,分别为粗切分和二次切分。粗切分主要分割非粘连字符和交错字符,在此基础上,结合宽度和宽高比阈值判断粘连字符,并以候选粘连点作为贪吃蛇爬行的起点,进行粘连字符的二次切分。
1.2 基于多重约束规则的候选路径优化
贪吃蛇在文本图像爬行后的原始轨迹存在冗余,本研究结合字符平均宽度、水平重叠率、分段投影特征建立路径优化规则,得到文本候选切分路径。水平重叠率、单列投影特征定义如下。
定义1 左右两字符块在垂直方向上的重叠长度与两字符块宽度比值的最大值记为水平重叠率,数学定义为
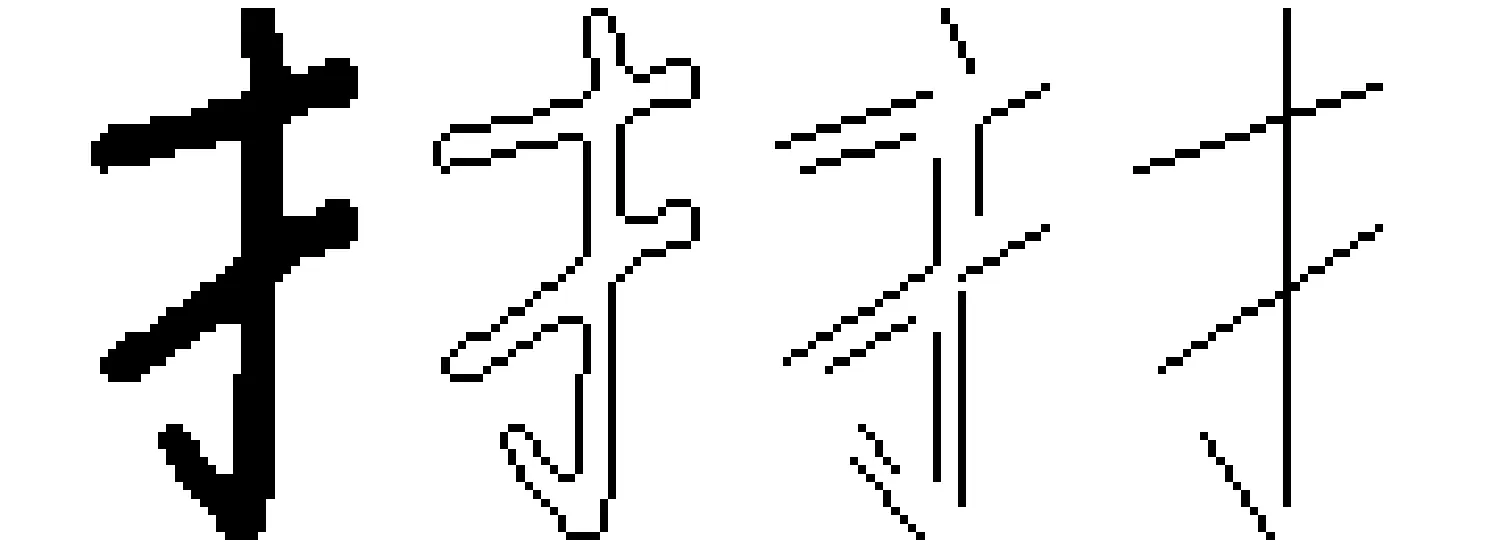
(1)
其中,WL和WR分别为两字符块的宽度,XL为左侧字符块横坐标的最大值,XR为右侧字符块横坐标的最小值,XL≥XR。
定义2 分段投影特征,即以像素点(y,x)为界,将所在列像素点分为上下两段,分别统计字符像素个数,用G1(y,x)和G2(y,x)分别表示点(y,x)上方和下方的字符像素个数。
将预处理后H×W的字符图像用I表示,H为高,W为宽。其中I(h,w)=1表示字符像素,I(h,w)=0表示背景像素,h=1,2,…,H;w=1,2,…,W。假定路径列表为P=[P1,P2,…,Pi,…,Pn],其中Pi={(y1,x1),(y2,x2),…,(ym,xm)}表示一条路径的坐标点集合,i=1,2,…,n。多重约束规则定义如下:
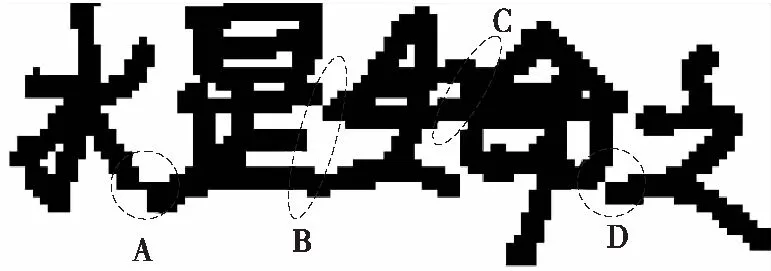
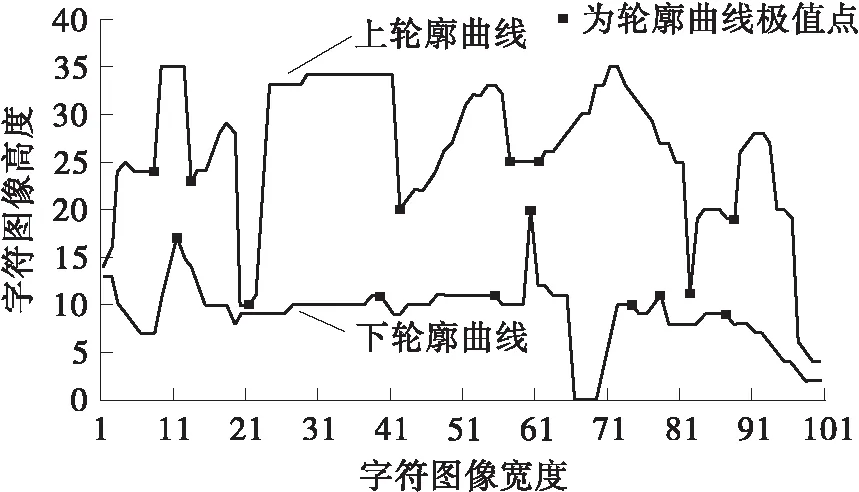
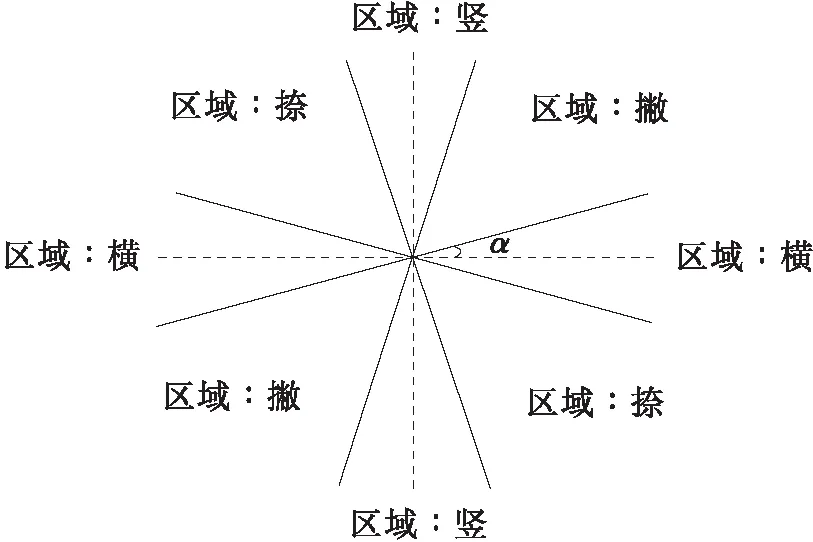
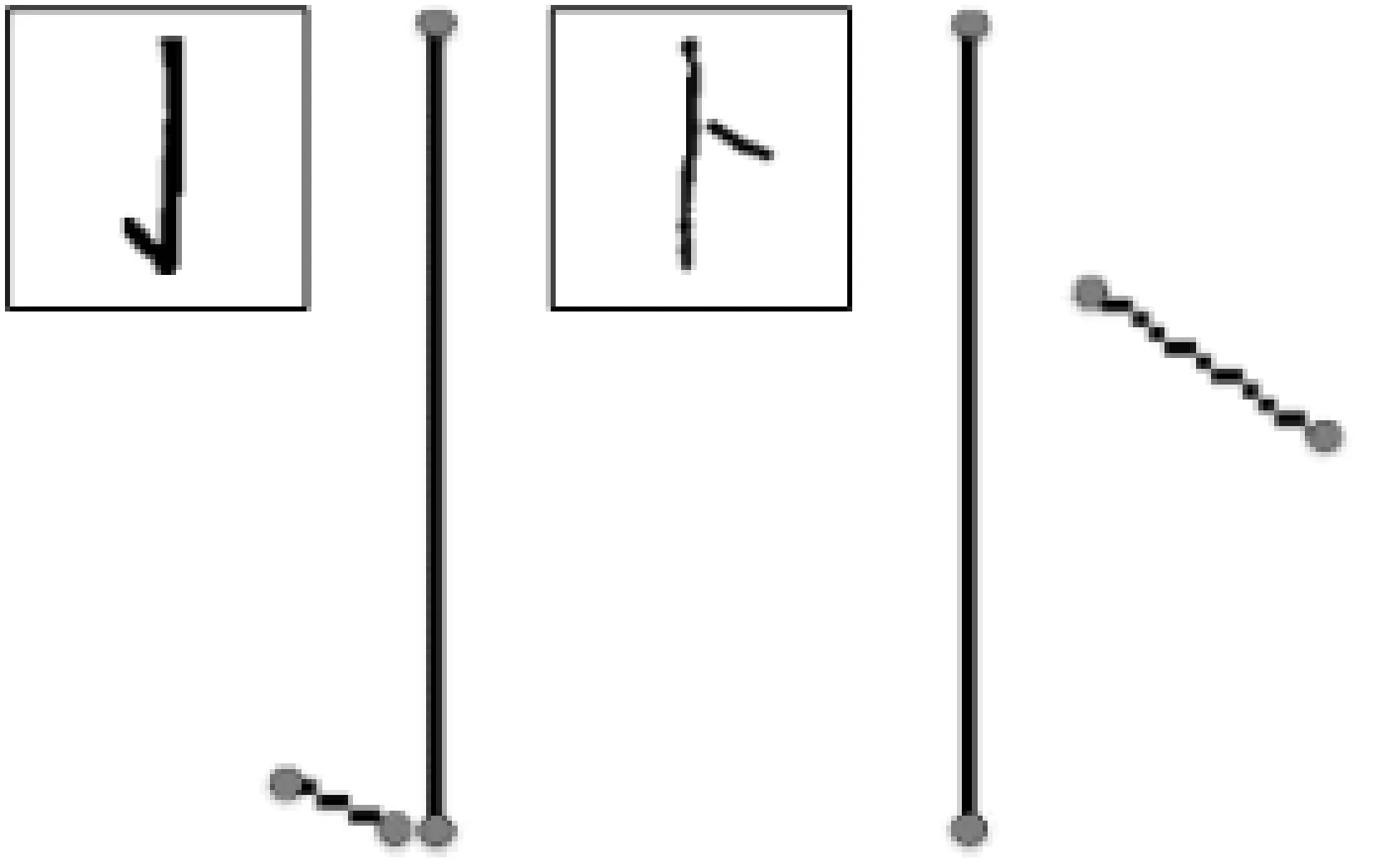
规则1 若Pi到Pi+k(0 规则2 若Pi左右两侧字符块的LX≥TX,则删除Pi。其中,TX为水平重叠率阈值,本文取TX=50%。 规则3 若Pi为非线性路径,存在(y,x)∈Pi,G1(y,x)=0,则在从点(y,x)向上形成垂直路径;G2(y,x)=0,则在点(y,x)向下形成垂直路径,删除原Pi。 规则4 若Pi到Pi+c(0 水平手写的文本粘连大多是由连笔或字间距较近造成的,粘连类型可分为简单粘连和复杂粘连。如图2所示,A、D区域都只有一笔粘连,属于简单粘连;B、C区域存在多笔粘连的同时还存在笔划重叠,属于复杂粘连。根据汉字内部笔划紧凑,字间笔划稀疏的特点,简单粘连点一般在字间笔划薄弱的位置,复杂粘连点处的结构与汉字内部结构相似,多为笔划交叉点。本研究基于轮廓曲线局部极值提取简单粘连点,基于骨架特征提取复杂粘连点,并结合笔划估计宽度、两点距离、四方向笔段长度、邻域像素个数建立粘连点筛选机制,确定候选粘连点。相关定义如下。 图2 粘连点类型Fig.2 Adhesion point type 定义3 字符轮廓曲线由每列字符像素边界点坐标组成,字符上轮廓曲线如式(2)所示: Sup(x)=min{y|I(y,x),x=1,2,…,W} (2) 字符下轮廓曲线如式(3)所示: Sdown(x)=max{y|I(y,x),x=1,2,…,W} (3) 定义4 水平和竖直扫描二值图像,统计连续字符像素个数mi(其中1 (4) 定义5 某一特征点分别在0°、45°、90°、135° 4个方向上连续字符的个数为四方向笔段长度。 采用差分遍历向量法分别计算上轮廓曲线的波峰和下轮廓曲线的波谷,得到局部极值点,将其加入粘连点集合。为了更加直观,以图像左下角作为原点绘制轮廓曲线,如图3所示。利用细化算法[17]提取字符骨架,扫描字符像素点,若其八邻域内有3个及以上字符像素,则认为该点为骨架点。由于骨架提取过程中存在一定程度的毛刺和畸变,导致提取到冗余骨架点,如图4所示。 图3 轮廓曲线与极值点Fig.3 Contour curves and extremum points 图4 骨架点提取Fig.4 Skeleton point extraction 定义规则对冗余骨架点进行过滤。 规则5 若骨架点所在的四方向笔段长度均小于Um,认为该点为孤立的噪点,则删除该点。 规则6 若两个骨架点距离较近,满足Ds 如图5所示,经过滤,去掉了大多数冗余点,将其加入粘连点集合。大多数情况下,粘连点位于字符中间,且邻域像素密度较小,与轮廓粘连点距离较近。将粘连点集合对应到粘连字符原图,建立粘连点筛选规则,确定候选粘连点。 图5 骨架点过滤Fig.5 Skeleton point filtration 规则8 保留距离轮廓粘连点2Um范围内的骨架点。 规则9 保留相邻Um范围内邻域像素个数最小的粘连点。 1.4.1 基于贪吃蛇的手写中文文本粗切分算法 对手写文本首先进行粗切分,使非粘连字符和交错字符得到正确切分。根据手写文本字间笔划稀疏的特点,粗切分起点由垂直投影值和笔划宽度自适应得到。垂直投影列表记为V=[V1,V2,…,VW],则粗切分起点(y,x)应符合式(5)定义: (5) 其中ξ是调节参数。ξ越大,蛇的初始爬行路径越多,本研究取ξ=3,得到起点集合A(x) ={(y,x|y=1,x∈[1,W]}。 基于贪吃蛇的手写中文文本粗切分算法(SnakeSegmentB)实现过程如下: (1) 输入二值化的文本图像I。 (2) 初始化切分路径列表P,一次爬行轨迹集合Pi。 (3) 计算垂直投影列表V和笔划宽度Um。 (4) 计算贪吃蛇爬行起点集合A(x)。 (5) 遍历A(x),依据第1.1节贪吃蛇爬行规则向下爬行,将有效轨迹坐标加入Pi;若Pi终点坐标在图像最后一行,则将Pi加入到P;否则,Pi置空;直到遍历结束。 (6) 对P,应用规则1-4。 (7) 输出手写文本切分路径列表P。 图6示出了文本图像粗切分过程。图6(a)为输入的文本图像;图6(b)为图像的垂直投影直方图,结合笔划宽度自适应得到贪吃蛇的爬行起点;图6(c)为贪吃蛇的原始爬行轨迹。可以看出:进入字符凹陷区域的贪吃蛇无法向下行进,需进行回溯,最终到达文本底部的原始轨迹存在重叠,且两字符之间有多条路径;由于爬行起点设置比较宽泛,当蛇经过字符间较窄区域之后,会得到相同轨迹。因此,采用多重约束规则对原始路径进行优化,得到粗切分路径,如图6(d)所示。粗切分结果中仍存在粘连字符,需进一步处理。 (a)骨架点提取 (b)垂直投影直方图 (c)贪吃蛇原始爬行轨迹 (d)应用规则后的切分路径图6 文本图像的粗切分过程Fig.6 Rough segmentation process of text image 1.4.2 基于贪吃蛇的手写中文文本二次切分算法 手写文本粗切分后,粘连字符易被当成一个字,造成分割不足。传统的切分算法处理粘连效果不好,如图7所示。 图7 传统算法切分图Fig.7 Segmentation graphs by traditional algorithms 由于汉字的方块字特点,其宽度、宽高比一般在一定范围内。因此,设置宽度、宽高比阈值选出粘连字符,进行基于贪吃蛇算法的二次切分,主要包括提取候选粘连点和筛选分割路径。基于贪吃蛇的手写中文文本二次切分算法(SnakeSegmentT)实现过程如下: (1) 输入二值化的文本图像I,手写文本切分路径列表P。 (2) 初始化粘连点集合E(i)和一次爬行轨迹集合Pi。 (3) 遍历P,计算字符的宽度Wei、宽高比Rwhi、平均宽度Wavgc和平均宽高比Ravg。 (4) 若Wei>Wavgc&&Rwhi>Ravg,则判定其为粘连字符,计算轮廓曲线局部极值点,加入E(i);提取骨架点并应用规则5和规则6,加入E(i)。 (5) 对E(i)应用规则7-9,得到二次切分起点B(x) ={(y,x|y∈[1,H],x∈[1,W]}。 (6) 遍历B(x),检测粘连点四方向的最短笔段,进行像素反转,令贪吃蛇在该粘连点处双向爬行,对于一个粘连区域,可能形成多段路径,因此Pi=l1∪l2∪…lj∪…∪lk,lj(j=1,2,…,k)表示从粘连点出发的一段路径。 (7) 若Pi终点坐标在图像最后一行,则将Pi加入到P;否则,Pi置空。 (8) 对粘连字符形成的Pm到Pm+k,应用规则1-4。 (9) 循环步骤(2)-(8),直到判定没有粘连字符。 (10) 输出手写文本切分路径列表P。 图8示出了粘连字符图像二次切分过程。图8(a)为通过宽度阈值和宽高比阈值选出的粘连字符图像,其示出了所提取的候选粘连点。图8(b)示出了粘连点像素的反转,即字符在粘连点处的断开。之后以候选粘连点作为起点,应用贪吃蛇切分算法,并进行路径优化,得到二次切分结果,如图8(c)所示。可以看出,本研究提出的算法在粘连字符切分中获得了较好的效果。经过粘连点提取算法处理,分割点一般包含在候选粘连点中,结合贪吃蛇切分算法可使分割路径更加准确。 图8 粘连字符二次切分Fig.8 Additional segmentation of adherent characters 部首的笔段信息相对其他特征更具有代表性,现有的笔段提取方法多采用细化的方式,但细化过程计算量较大,且会产生不可预知的效果,并不适于提取手写部首的笔段。 图像的轮廓包含着比其他位置更多的信息,因此本研究设计了基于轮廓编码的部首笔段提取方法,主要步骤如下: (1)提取字符轮廓,并对轮廓像素点进行Freeman编码[18]。 (2)基于连续相同或相近方向码提取线段。 (3)根据倾斜角对线段进行聚类。 (4)合并倾斜角相同或相近的线段,得到最终笔段。 通过八邻域模板检测轮廓,规定每个轮廓点最多有2个相邻点,以保证轮廓编码的唯一性。Freeman链码是一种依据邻域点和中心点的连线方向对曲线编码的方法,本研究采用可以更好描述轮廓形状的八邻域编码方式(如图9(a)所示),分别用1,2,…,8等8个链码值表示当前点与中心像素点P的邻接方向,编码结果为一系列具有特定长度和方向的连续直线段,如图9(b)所示。 图9 轮廓编码Fig.9 Contour encoding 由于噪声以及笔划边缘不光滑等原因,导致轮廓链码在局部范围内快速变化,不利于后续的线段提取,因此需要对链码进一步平滑。令C={f1,f2,…,fn},表示当前轮廓的链码集合,n为轮廓所包含的像素点个数,Cj={fj-s+1,fj-s+2,…,fj}表示以链码fj结尾、长度为s的一段链码,即Cj⊆C,Cj中各链码元素及其组合方式共同确定是否对f(2j-s+1)/2进行平滑。平滑复杂程度与s的大小有关,s越大越复杂;本研究取s=3,只考虑被平滑点的前后两点。通过分析轮廓链码特征,待平滑边缘分为直角型和钝角型两种类型,如图10所示。不同类型判断依据如式(6)所示。为简要起见,表1示出了部分直角型和钝角型的链码串及轮廓形状。 图10 待平滑类型Fig.10 The type to be smoothed (6) len(fi)表示一段具有相同fi链码的长度。若Cj为直角型,且len(fi-2)和len(fi)均小于Um,则按式(7)平滑fi -1;否则,按式(8)平滑fi-1;若Cj为钝角型,且fi-2=fi,则令fi-1=fi;否则,判断len(fi-2)和len(fi),若两者都小于Um,则不改变fi-1的值;否则按式(8)平滑fi-1。平滑后链码如图11所示。 fj-1=(fj-2+fj)/2 (7) (8) 表1 部分直角型、钝角型链码串及轮廓形状Table 1 Part of right angle,obtuse angle chain and outline shape (a)平滑前 (b)平滑后图11 平滑后链码Fig.11 Smoothed chain code 一条线段满足:①最多包含3种链码,即fi-1、fi、fi+1;②假定fi为主链码,则fi可表示该线段方向,fi-1、fi+1分布在链码转折处,经过链码平滑,出现次数很少。因此,可依据主链码提取线段。一个笔划可能被提取为多条线段,而属于同一笔划的多条线段之间具有相同或相似的倾斜角,并且线段距离不超过笔划宽度。设L为线段集合,其元素为五元组(xi,yi,xj,yj,θ),其中xi、yi、xj、yj为线段端点坐标,θ为线段与X轴正方向的夹角。Mseg为聚类集合,其元素为三元组(θi,Nsegi,Jsegi),其中θi为该类中心,Nsegi为该类线段个数,Jsegi为该类线段集合。基于轮廓编码的部首笔段提取算法(Stroke Extract)的实现过程如下: (1) 输入过切分字符图像。 (2) 初始化线段集合L,聚类集合Mseg。 (3)轮廓检测,编码并平滑,得到链码集合C。 (4) 遍历C,若fi=fi-1,则fi属于当前线段;否则,计算|fi-fi-1| mod 4的值,若其值为2,当前线段Li提取完毕;若|fi-fi-1| mod 4≠2,分别计算当前线段起点与fi-1、fi两点连线的θi-1、θi,若|θi-1-θi|≤5°,则fi属于当前线段,否则当前线段提取完成;若len(Li) ≥Um,则加入集合L;直至遍历结束,得到线段集合L。 (5)遍历L,取当前线段θ,若Mseg中存在|θi-1-θi|≤5°,则将当前线段加入Jsegi,并按式(9)更新θi,按式(10)更新Nsegi: (9) Nnumi=Nnumi+1 (10) 若|θi-1-θi|>5°,新增聚类中心θ,初始化Nsegi=0,Jsegi=Ø;直至遍历结束,得到聚类集合Mseg;在Mseg中,每一类中的线段可能属于同一笔段,也可能属于多个笔段,根据平行线间距离和线段重叠部分来判断是否对两条线段进行合并。 (7) 输出笔段集合HStroke={(xi,yi,xj,yj,θ)}。 笔段提取效果如图13所示。 图12 线段距离Fig.12 Line distanceion 图13 笔段提取Fig.13 Stroke extraction 部首作为汉字的一部分,结构相对简单,一级常用汉字中包含左右结构的部首只有几十类,且大多数在七笔画以内,因此本研究采用特征提取的方式识别部首,选取有代表性的特征作为识别依据。本研究结合笔段类型、笔段长度、笔段个数、相对位置、交叉点、横纵交截、宽高比多维特征对部首进行识别。 部首的笔段主要分为横、竖、撇、捺4种类型,轮廓链码1、5对应横笔段,3、7对应竖笔段、2、6对应撇笔段,4、8对应捺笔段。根据轮廓编码的不同,笔段长度的计算方式也不同,如式(11)、(12)所示: (11) (12) 在部首结构中,笔段存在相离、相连、相交3种位置关系,相连在书写过程中较为随意,因此结合相离和相交两种位置关系提取笔段特征。对于相离的两笔段,其相对位置主要有上下、左右和斜方。对于相交笔段,使用交点个数作为特征,每类部首包含的交点个数一般不同。 横纵向交截特征可在一定程度上表现部首笔划紧密程度,其定义如下。 定义6 在图像每一行插入水平射线,在每一列上插入垂直射线,射线上像素的黑白交替变化次数即为横纵向交截特征。 经过笔段提取之后,每个部首用一个字典序列Fi={Y:{‘Ynum’:Ynums,‘Yseg’:Ysegs}}表示其笔段信息。其中,Y={t|t=T,H,S,P},为笔段类型,T、H、S、P分别表示横、竖、撇、捺4类笔段。由于手写汉字存在一定差异,并不能保证横平竖直,因此根据图14设置笔段模糊分类范围;Ynum为某一类型笔段的数目,Yseg为该类笔段集合。在笔段提取过程中,曲线、折线、弯钩等被线段化,所以部首所提取到的笔段数一般大于其实际笔画数。 图14 笔段模糊分类范围Fig.14 Stroke segment classification scope 4种笔段可以大体反映一个部首的形状,虽然4种笔段有许多组合方式,但并不是任意的组合就可以形成部首,这一点在简单部首中表现更为明显。多级分类可以加快识别速度,因此首先依据笔段数目进行一级分类,当总笔段数sum(Ynums)≤TSN时定义为简单笔段,当sum(Ynums)>TSN时,定义为复杂笔段,其中TSN为笔段数阈值。经实验分析,本研究取TSN=3。 简单笔段的部首可以直接通过笔段类型、数目和位置结构来判断。 当总笔段数sum(Ynums)≤3时,主要有丨、丿、丶、亅、卜、亻、冫、乚、氵、彡、彳、刂、忄、卩、厶15组可能的情况,而这15组部首首先在笔段组合方式上就有很大差异,如“彳”的笔段组合可表示为“0120”,即“彳”由一竖两撇笔段组成,而“乚”由于手写习惯的不同,在笔段提取后,可能存在“1200”、“1110”、“1101”几种情况。根据笔段不同的组合方式可以将简单笔段的大部分部首区分开。对于特殊情况,如“亅”和“卜”都是由一竖和一捺组成,且在笔段长度上也没有明显特征,但两者捺笔段的位置是明显不同的,如图15所示。因此,在一级分类的基础上,简单笔段的部首识别,根据笔段类型及其数目的不同组合方式进行二级分类,一些部首在二级分类后已经可以得到分类结果,而相近笔段的部首再结合笔段长度和位置特征设计三级分类器完成识别。 图15 笔段相对位置Fig.15 Relative position of stroke segments 复杂部首,笔段位置关系也更加复杂,直接通过笔段位置判断会包含大量的计算。因此采用模板匹配的方式进行识别。将横、竖、撇、捺4种笔段信息作为前4维特征分量的基础上,加入交点个数、横向最大交截数、纵向最大交截数、宽高比四维特征,用于复杂部首的识别。特征模板的建立基于课题组收集到的陕西省某高中课堂手写数据,从中分割出部分部首,进行预处理和归一化,每类部首最终保留5组特征向量。识别过程使用加权欧氏距离计算待识别字符与模板字符的距离: (13) 其中:n为特征维数;xi为待识别字符的第i维特征;μi为第i维特征的均值;σi为第i维特征的标准差;βi是第i维特征的修正系数,βi=0表示该特征未提取到,其他情况下βi=1。 部首识别(RadicalRecognition)的实现过程为: (1) 输入待识别字符图像,笔段集合HStroke={(xi,yi,xj,yj,θ)}。 (2) 初始化字典序列F={Y:{‘Ynum’:Ynums,‘Yseg’:Ysegs}}。 (3) 遍历HStroke,根据θ进行笔段分类,更新Ynum,将(xi,yi,xj,yj)加入Yseg。 (4) 若sum(Ynums)≤TSN,进行二级分类,若笔段特征与候选样本完全一致,则识别输出;若属于笔段相近字符,进行三级分类,若笔段特征与候选样本完全一致,则识别输出;否则,标记为拒识字符。 (5) 若sum(Ynums)>TSN,提取字符交点特征、横纵向交截特征、宽高特征,与笔段信息组成特征向量。 (6) 模板匹配,计算d2,若min(d2) (7) 输出分类结果。 经上述切分,同一汉字由于左右部分间距过大,会出现过切分现象。在GB2312—80的3755类一级汉字中,包含了2 049类左右结构的汉字,177类左中右结构的汉字,占多半部分,因此,过切分字符的合并对于文本切分也非常重要。过切分的字符中一般包含部首,其作为汉字特有的结构,虽然手写风格多变,但相对位置并不会改变。如“亻”、“氵”一般出现在汉字左边,“刂”、“攵”出现在右边,“阝”左右都可组成汉字。因此,可利用部首的结构特征在字符合并之前确定合并方向,进一步计算待合并字符局部上下文的几何置信度和识别置信度,取置信度最高者作为最终合并结果。 根据中文形态特征,部首的书写一般比单字窄,又由于每位书写者所写成的单字宽高比值变化不大。由此,可得出部首的宽高比与单字的宽高比存在较大差距。设置宽高比阈值TWH,对部首和单字分类,如式(14)所示: (14) 其中,Rwhi为每个待识别字符的宽高比,取TWH=0.5。 设Ci, j为连续路径Pi,Pi+1,…,Pj之间的组件,该组件宽度和高度分别为wi, j和hi, j。组件Ci, j为一个汉字的几何置信度为 (15) 由几何特征zk(k=1,2,3)及权重因子wk共同决定: (1)组件Ci, j的平均宽度差异度为 (16) 其中Wavgc为平均字符宽度。 (2)组件Ci, j的平均宽高差异度为 (17) (3)组件Ci, j的字内密集度为 (18) 其中,ds,s+1表示相邻组件最小外接矩形之间的距离。本研究中,w1=0.3,w2=0.4,w3=0.3。 识别置信度通过将待识别图像输入到预先训练好的卷积神经网络[19]中得到。经大量实验验证,该识别模型在所收集的样本数据中,识别准确率可达到93.87%。将组件Ci, j的识别置信度记为Oi, j,则组件Ci, j的合并置信度如式(19)所示: Ki, j=ηZi, j+(1-η)Oi, j (19) 其中,η为几何置信度和识别置信度的占比系数,0≤η≤1,本研究取η=0.45。 基于部首识别的过切分合并算法(Radical-Merge)的实现过程如下: (1) 输入二值化的文本图像I,手写文本切分路径列表P。 (2) 遍历P,计算字符的宽度Wei、宽高比Rwhi、平均宽度Wavgc和平均宽高比Ravg。 (3) 若Rwhi≤TWH,则通过Stroke Extract算法提取该字符笔段信息,执行步骤(4);否则,执行步骤(7)。 (4) 通过RadicalRecognition算法进行识别,若得到分类结果,执行步骤(5);若RadicalRecognition拒识,执行步骤(6)。 (5) 根据步骤(4)的分类结果计算字符合并方向,在此方向上取3Wavgc范围内的字符计算不同组合方式的Ki, j,取max(Ki, j)作为合并结果,删除Pi+1,Pi+2,…,Pj-1。 (6) 在左右方向上分别取3Wavgc范围内的字符计算不同组合方式的Ki, j,取max(Ki, j)作为合并结果,删除Pi+1,Pi+2,…,Pj-1。 (7) 循环执行步骤(3)-(6),直至Rwhi>TWH。 (8) 根据P切分文本图像,并净化。 (9) 输出文本切分结果。 图16示出了过切分字符的合并过程。图中,WHR表示字符宽高比,OCR表示识别置信度。“氵”的宽高比符合过切分字符,对其识别之后,可判断出合并方向为向右,计算其右侧邻域内字符合并的置信度得出最优合并结果。由于大部分部首位置结构相对明确,合并方向单一,大大降低了计算量。 图16 过切分合并Fig.16 Over-segmentation merge 收集了陕西省某高中期末考试语文试卷中300张手写文本图像,对本研究提出的算法进行实验验证。图17示出了一个文本的切分过程。如图17(a)所示,首先基于水平投影算法对文本图像进行行切分,共得到1 542行手写数据。图17(b)为基于贪吃蛇算法的文本粗切分结果,图17(c)为基于贪吃蛇算法的二次切分结果,图17(d)为基于部首识别的过切分字符合并结果。从图中可以看出,本研究提出的算法取得了较好的切分效果,能够准确地切分到每个汉字的主体结构。 基于贪吃蛇算法进行手写文本二次切分时,有一些粘连字符存在共享笔划、多重粘连、粘连区域较大等情况,导致切分路径不能精确分割字符边缘,但通过手写汉字识别模型验证可知,这种情况对汉字识别准确率的影响极小。因此,本研究认为这种情况属于正确切分。本研究将错误情况分为3种,分别为漏切、过切和误切,见图18。图18(a)中,“一”和“样”有共同笔画,由于无法正确提取到粘连点,造成漏切。图18(b)中,“确”被分为了“石”和“角”,这两部分的宽度以及宽高比接近单字,且可以单独成字,识别置信度较高,导致未能合并。图18(c)中,由于“长”右下方的捺笔段与“官”水平重叠率较高,应用多重约束规则之后,判定该笔段所属“官”,造成误切。 (a) 手写文本数据 (b)基于贪吃蛇算法的文本粗切分 (c)基于贪吃蛇算法的二次切分 (d)基于部首识别的过切分字符合并图17 文本切分Fig.17 Text segmentation 图18 错误情况Fig.18 Error cases 为验证本研究提出的算法的有效性,采用切分正确率、粘连字符切分正确率、过切分字符合并正确率作为评价标准,数学定义分别如(20)、(21)、(22)所示: (20) 其中,u为切分正确率,TP为切分正确的字符个数,TN为切分错误的字符个数。 (21) 其中,q为粘连字符切分正确率,AP为切分正确的粘连字符个数,AN为误切数,AW为漏切数。 (22) 其中,r为过切分字符合并正确率,OP为正确合并数,OM为欠合并数。 对1 542条手写数据进行实验,共包含27 372个字符,统计实验结果:TP、TN、AP、AN、AW、OP、OM分别为22 487、4 885、12 163、1 329、1 934、8 101、1 622。可以看出:学生手写数据存在大量粘连情况,切分过程中,较容易出现过切分现象。根据式(20)-(22)计算可得出,本研究提出的算法在粘连字符切分方面,可达到78.84%的准确率,对于过切分字符,合并正确率在83.32%,整体切分正确率为82.15%。 为进一步验证本文算法的有效性,表2示出了不同切分方法的统计结果。 表2 不同切分方法对比Table 2 Contrast of different segmentation methods 从表中可以看出,本研究提出的方法在获得较好切分效果的同时,平均处理时间最短。本研究利用贪吃蛇算法进行粗切分,之后仅针对粘连字符进行二次切分,在过切分合并过程中,通过部首的位置特征确定合并方向,减少了大量的计算。 手写文本变化多端,字符间极易发生粘连、交错、重叠等现象,切分过程中也极易出现过切分现象。针对以上问题,本研究提出的基于贪吃蛇算法和部首识别的手写文本切分方法取得了较好的效果,且在时间效率上优于其他算法。但对于一些复杂结构的字符粘连情况,如共享水平笔画、竖直笔画重叠等,很难准确找到粘连位置将字符完整分开。因此,需进一步研究复杂粘连字符的分割。另外,在过切分合并过程中,由于一些偏旁部首也可以独立成字,当书写者书写的字体宽高特征不明显时,很难判断当前字符是作为偏旁部首还是作为单字,可进一步结合语义对切分结果进行后处理。1.3 基于轮廓曲线极值和骨架特征的候选粘连点提取

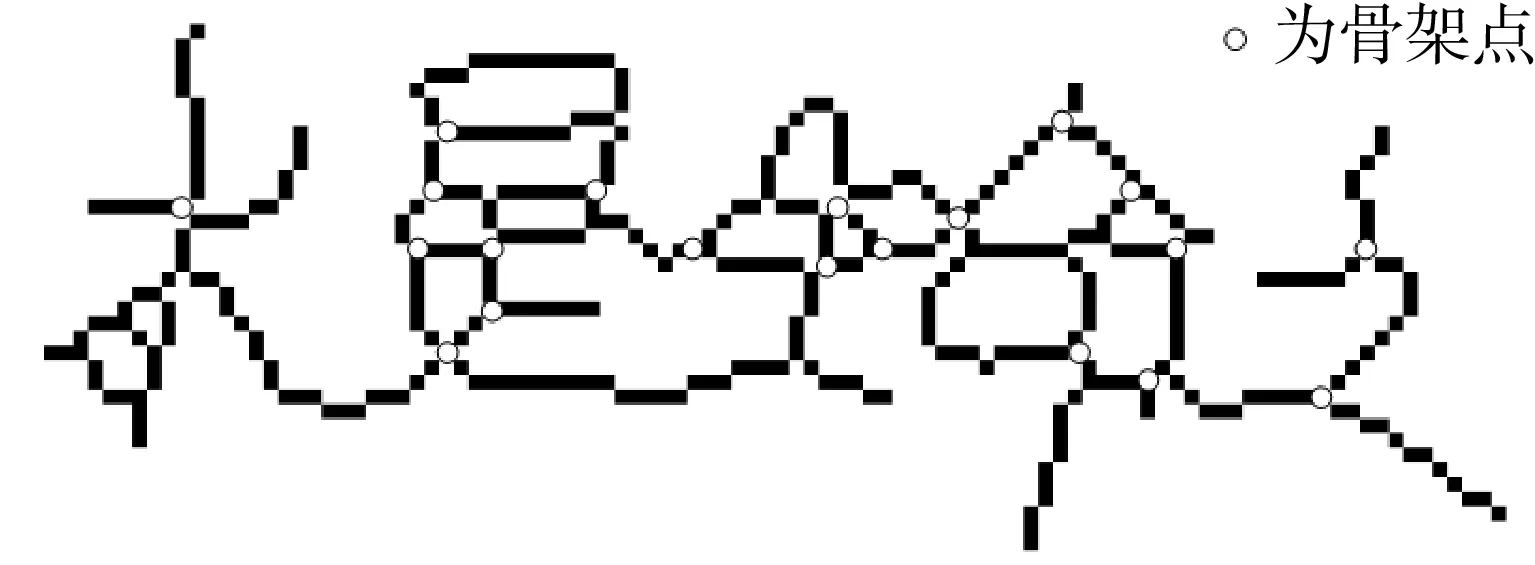
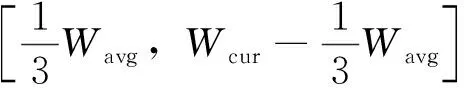
1.4 基于贪吃蛇的文本切分算法






2 基于部首识别的过切分合并
2.1 基于轮廓编码的部首笔段提取


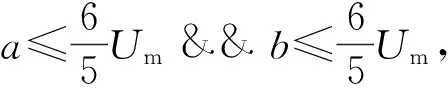

2.2 基于多级分类的部首识别
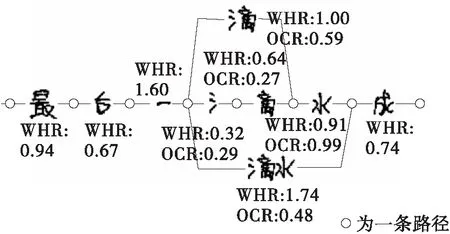
2.3 基于部首识别的过切分字符合并算法
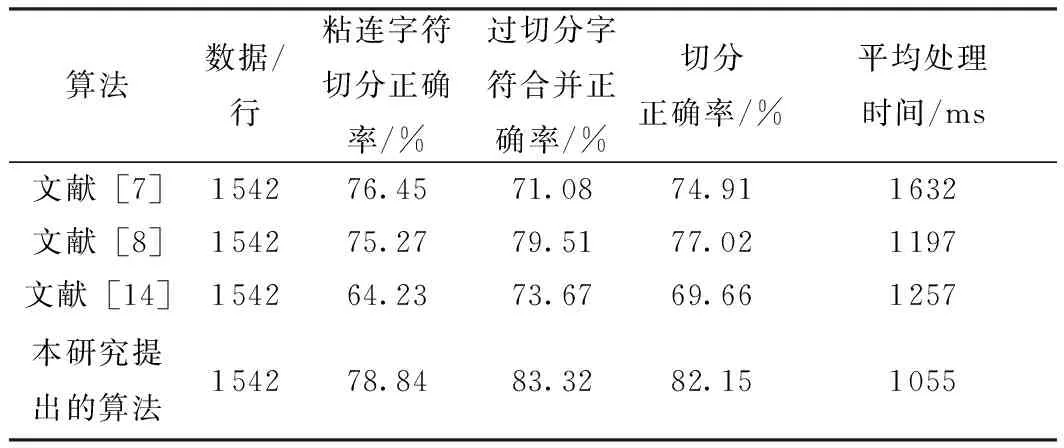
3 实验结果与分析



4 结语
猜你喜欢
故事作文·低年级(2021年12期)2021-12-21电脑报(2021年41期)2021-11-04电脑知识与技术(2019年29期)2019-12-16电脑爱好者(2019年8期)2019-10-30文苑·经典美文(2019年8期)2019-08-06作文周刊·小学二年级版(2019年12期)2019-04-26课堂内外(初中版)(2018年12期)2018-03-08前卫文学(2016年3期)2016-07-01学苑创造·A版(2014年7期)2014-11-15党建文汇·上(2014年8期)2014-10-27
