
基于骨骼及表观特征融合的动作识别方法
2022-03-01 01:31王洪雁袁海
通信学报 2022年1期
王洪雁,袁海
(1.浙江理工大学信息学院,浙江 杭州 310018;2.大连大学信息工程学院,辽宁 大连 116622)
0 引言
作为机器视觉领域的研究热点,人体动作识别在智能监控、人机交互、自动驾驶等领域发挥重要作用[1]。基于表观序列的传统识别模型通过获取颜色纹理等来识别动作,此类方法易受光照、尺度、背景变化等因素影响,且由于深度信息缺失,因此识别性能较差[2]。针对此问题,Liu 等[3-4]提出基于深度图的识别方法,深度图所含深度信息对光照、背景变化具有较好稳健性,识别性能较好,但其信息冗余导致计算复杂,从而限制了此类方法的实际应用。
为解决上述问题,Shotton 等[5-7]提出低冗余高可分关节信息表示可显著提升动作识别性能。Vemulapalli 等[8]利用3D 关节坐标分析运动模式识别动作,所采用的运动信息提取方法简单高效,然而该方法忽略了关节间空域关系从而有限提升准确率。针对此问题,Ahmed 等[9]采用相对距离及角度编码关节改善准确率,然而其仅依赖手工特征的识别结果难以令人满意。随着人工智能快速发展,深度学习模型利用非线性神经网络抽取深层次动作特征提升准确率[10]。其中,基于卷积神经网络(CNN,convolutional neural network)优良的空域特征提取能力,Banerjee 等[11]将骨骼序列编码为伪图像,并基于CNN 抽取其深度特征以改进识别效果,然而所得编码图像缺失时域信息,导致准确率提升有限。针对此问题,具有良好时间建模能力的循环神经网络(RNN,recurrent neural network)可以较高准确率识别动作,然而RNN 所固有的梯度弥散缺陷使其难以学习较长历史信息[12]。基于此,长短期记忆(LSTM,long short-term memory)模型重构RNN 时序信息传递结构以获得优异的长时依赖关系刻画能力,可有效应用于动作识别[13-15]。Kwak等[16]将关节时序编码为图像序列,利用LSTM 模型抽取其时域特征改善识别性能。然而,上述基于深度网络的识别方法逐帧处理各幅图像,缺乏对关键图像及部位的挖掘,而动作序列通常存在较大信息冗余,使相关方法实时性较差且所获取高可分信息匮乏,导致准确率提升有限。基于此,Song 等[17]提出基于时空注意力机制的LSTM(STA-LSTM,spatio-temporal attention LSTM)模型,采用时空注意力机制抽取骨骼特征,并基于重要性赋予关节相应权重以增强关键图像及部位影响,从而提升动作准确率。然而,该方法仅考虑关节坐标而忽略空域拓扑信息,准确率改善有限。此外,上述基于3D骨骼的相关算法仅考虑骨骼深度信息,忽略了有效表达动作的外观特征。
针对上述问题,本文提出基于骨骼关节及表观特征融合的双流网络动作识别方法。所提方法首先基于关节空间拓扑构建空域约束;其次将所得空域约束及关节坐标转化为伪图像,并输入具有时空注意力机制的LSTM 模型以降低信息冗余,同时增强关键图像及关节的重要性提升关节深度特征表达有效性;再次基于时空注意力机制引入热图,定位图像重要关节点以提取其周围颜色纹理等外观特征;最后基于双流网络逐帧融合表观及关节深度特征序列以实现复杂场景下人体动作有效识别。
基于以上所述,本文贡献可简述如下。
1)利用所构建关节相对距离与高相关度关节对等空域约束有效补充骨骼时空动态信息,并将其转化为伪图像。
2)构建具有时空注意力机制的LSTM 模型,采用时序权重差值法去除相似帧,基于热图定位序列关键帧及关节,并以所得关键关节作为表观特征提取区域。
3)基于双流网络逐帧融合手工表观特征及LSTM 所得深度骨骼特征序列以有效识别相似动作。
1 基于关节及外观特征融合的识别模型
所提动作识别模型主要包含如下4 个部分:首先,构建关节空间约束,即关节相对距离与高相关度关节对;其次,构建具有时空注意力机制的LSTM模型;再次,基于热图定位重要关节并抽取附近颜色纹理等外观特征;最后,基于双流网络逐帧融合骨骼序列所得关节特征及表观序列所得外观特征以提升动作准确率。模型如图1 所示。

图1 基于深度关节特征及手工外观特征融合的动作识别模型
1.1 关节空间约束
1.1.1 关节坐标
关节信息可有效表征人体姿态,从而可作为动作高可分表达,通过将动态关节信息输入深度网络以获取关节序列的深度有效特征,从而提升动作准确率。人体结构可分为左臂、右臂、躯干、左腿、右腿 5 个部分,对于全部关节点K(本文中K=25),Xt,k=(xt,k,yt,k,zt,k)表示第t(t=1,2,…,T)帧内关节k的坐标,则所有关节坐标可表示为Xt=(Xt,1,…,Xt,K),其中T为序列帧数。
1.1.2 相对距离约束
众所周知,无论是静止还是运动状态,关节间始终具有特定范围内距离关系,因此关节相对距离可有效表示人体局部感兴趣区域,并且对视角及光照变化具有较强稳健性。此外,运动过程中髋关节Xt,1=(x1,y1,z1)变化幅度较小,其余关节均围绕髋关节做定向圆周运动,因此,可将其取为坐标中心。由此,髋关节与其他关节之间的欧氏距离可表示为

其中,j=2,3,…,K。
为避免个体间身高差异,归一化dt,j_1可得如下相对距离

其中,dt,21_1为锁骨及髋关节的距离。由此,动作序列中第t帧内关节相对距离可表示为

1.1.3 高相关度关节对约束
人体骨骼中任意关节间皆存在一定数量骨骼边,某关节的运动将导致相邻关节同步运动,两关节间相连边越少,表明关节间距离较近,协作关系更密切、相关度更高。基于此观察,本文只选取相关度较高的一、二(即只有一或两条边相连关节对)级相关信息构建关节空域相关约束以降低计算复杂度,其中关节相对位置为

其中,Ct,i_j表示第t帧内第j个关节相对第i个关节的坐标,即二者空域拓扑信息。
综上所述,一、二级相关信息分别为

其中,h_k、m_n、o_p等表示仅由一条边相连的关节对,q_r、u_v、x_y等表示由两条边相连的关节对。
综上所述,有效表征某动作的关节序列时空信息可表示为

通常认为,整个动作期间可有效表达动作的图像帧及关节更具重要性[18],以序列“跳跃”为例,相较于直立帧及躯干,跳跃帧及四肢更具指标意义。基于此,本节提出如图2 所示的基于时空注意力的LSTM 模型以加权各帧及部位从而体现其重要性。

图2 基于时空注意力的LSTM 模型
1.2 具有空间约束的时空注意力LSTM 模型
1.2.1 空间注意力
如上所述,视频帧及各关节对动作识别影响不同,基于此事实,本节基于空间注意力机制加权各关节以反映其重要程度从而增强动作可区分度。设时刻t所有关节权重为αt=(αt,1,…,αt,l),l为输入特征ft维数,对应得分st=(st,1,…,st,l)可表示为

其中,为避免前向传播数值上溢问题采用tanh 激活函数,wf、wh分别为输入数据ft及上层LSTM 隐藏变量ht-1的加权矢量,b为偏差矢量。
基于上述关节得分,经由Softmax 计算,可得如下可有效表征关节空域重要性的权值

由此可得如下输入主LSTM 模型的空域加权特征

其中,⊙为Hadamard 积,表示矢量相应元素相乘。
1.2.2 时间注意力
动作识别过程中视频序列存在大量冗余帧,针对此问题,本节利用时间注意力机制加权序列以突出关键帧同时降低信息冗余度从而提升动作准确率。各帧权重βt可表示为

1.3 手工表观特征构造
动作识别中颜色纹理特征可直观反映姿态变化,由此可将包含丰富颜色及纹理信息的表观序列作为基于骨骼信息动作识别的有效补充。若对整幅图像提取外观特征,则难以直观反映动作细微差异。基于此,本节利用热图定位关键帧及关节(如图3 所示),并在其附近半径为R的圆形区域提取颜色纹理直方图,作为关节深度特征的有效补充。
由于关键帧通常处于稳态且相邻帧差异较小,因此应避免提取大量相似帧以降低计算复杂度同时改善准确率。本节以各帧时间注意力权重差值为区分准则来划分相似帧片段,并提取片段中权重最大帧来表征相似帧片段。注意到,相邻帧越相似、权重值越相近,则其差值越小。基于此,权重为βi(1≤i≤T)的序列帧i与参考帧(参考帧为各片段首帧,1≤i*≤N)之间的权重差值为βc,即

基于此,令δ为相似帧权重差值阈值,当βc<δ时,表明后续帧和当前参考帧类似;当βc≥δ时,帧i*为新参考帧,最终提取所有参考帧N构成关键帧。
需要注意的是,关键帧内不同权重关节可影响相似动作判别,由各关节权重所得热图则表征了重要关节运动趋势,如图3 所示相似动作中具有代表性的三帧,其手部周围区域体现相似动作细微差异。基于此,通过提取手部颜色纹理特征,并加以关节点权重以增强外观信息,从而可有效获取手物信息以作为关节特征的有力补充。

图3 基于热点定位重要关节
1.3.1 LBP 纹理特征
由于局部二值模式(LBP,local binary pattern)具有灰度不变及旋转不变性[19],光照变化稳健性较好,因而在图像识别领域得到广泛应用[20-21]。基于此,重要关节附近纹理可基于LBP 表达。设nc为中心点灰度值,n0~n7为邻域点灰度值。以nc为阈值依次比较邻域像素点,若像素灰度值大于阈值将该点标记为1,否则为0。将结果采用顺时针构成二进制序列,作为该点LBP 值,计算式为[18]

1.3.2 HSV 颜色直方图
颜色直方图可有效描述各色彩比例,HSV 颜色模型将亮度色度分离,因而不易受光照变化等因素干扰[22]。基于此,本节基于HSV 颜色空间模型构建颜色特征。HSV 空间中色调H 较饱和度S 及亮度V 敏感,故赋予H 通道更多量化级别。此外,量化间隔越大则信息损失越多;间隔越小则信息损失越少,同时数据量显著增加,进而导致计算复杂度上升。由此,本节基于文献[23]构造如下量化等级


将上述非均匀量化HSV 合成如下矢量G

其中,Qs、Qv分别为S、V分量量化级数。
由式(14)~式(16)可知,HSV 分别量化为8、3和3 级,则Qs=3,Qv=3。同时HSV 分别取最大值7、2 和2,则G取值范围为[0,71]。基于此,可将HSV 空间表述为包含颜色级别为72 的特征向量,统计该颜色级别频率以获得HSV 颜色直方图,则为各子块对应直方图向量。
热图所指示关键关节周围提取颜色纹理分布直方图,为保证局部区域性质,可先拼接单个圆形区域,再将表观序列圆形区域乘以对应关节点权重依次连接可获得参考帧颜色纹理特征(如图4 所示)

图4 颜色纹理直方图融合

1.4 基于深度关节与表观特征双流融合
综上所述,通过具有空间约束的时空注意力机制LSTM 模型(STA-SC-LSTM),提取运动变化关键关节特征,基于热图定位表观关键帧及重要关节以手动提取重要关节周围颜色纹理等表观细节信息,所提动作识别模型基于双流网络融合所得深度关节及表观特征。
根据表观及深度特征特殊对应关系,本节采用更利于提升准确率的逐帧融合再序列融合方法,以突出局部重要部位互补性。根据上述权重差值βc判定各段相似帧的参考帧,同时记录各段相似帧数量(1≤i*≤N),则表观序列参考帧位置i*对应由 LSTM 模型提取关节深度特征序列位置(当i*为1 时,φ0=1)。基于此,参考帧表观特征与对应深度关节特征以权重占比λ2与λ1融合。其中,λ1+λ2=1(二者可经由实验确定,具体参见实验部分),对应帧融合特征可表示为
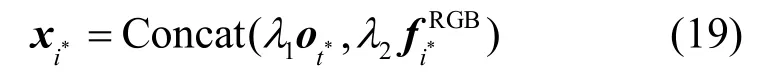
同时,无参考帧对应的深度特征补0 以降低系统复杂性。最后序列融合特征(其中,i=1,…,C,C表示动作类别数)映射至全连接层并基于Softmax 函数识别动作

为提升训练效果,构造如下正则化损失函数

其中,第一项基于交叉熵y=(y1,…,yC)T为真实动作,为第i类动作预测概率;第二项为模型参数正则化约束以抑制过拟合,λ为损失函数平衡因子,W为模型参数。
2 实验结果及分析
基于NTU RGB-D、Northwestern-UCLA、SBU Interaction Dataset 这3 个公开动作识别数据集,本节通过与基于手工特征、CNN、RNN 及LSTM 等模型的动作识别方法在视角变化、主体多样化及同类动作多样化等方面对比,验证所提方法有效性。
2.1 实验环境
本节实验基于TensorFlow 深度学习框架,处理器Intel Core(TM)i7-7700,主频3.60 GHz,32 GB内存,NVIDIA GeForce GTX 1070。选取4 层LSTM作为主网络,时空注意力分别基于单个LSTM,每层神经元个数均为128,表观特征提取半径为5 像素点,初始学习率为0.002,每经过30 次训练学习率缩小至10%,采用动量为0.8 的随机梯度下降法作为优化函数Adam,平衡因子λ=10-5,批处理大小为64,Dropout=0.45 以防止过拟合。
2.2 NTU RGB-D 数据集
NTU RGB-D 数据集为目前包含受测对象和行为类别数目最大的RGB-D 行为数据集[24]。该数据集由40 位受测对象通过3 台Kinect V2 摄像机从-45°、0°、45°这3 个不同角度采集60 类动作,56 880 个视频片段与三维骨骼数据序列。其中包括个体日常动作(如跌倒、呕吐、鼓掌等)、人物交互(如梳头、撕纸、踢东西等)、双人交互(如推、拍后背、手指对方等),以及诸如喝水与刷牙、阅读与写作、握手与传递物品等具有细微差别的动作。
交叉主体(cross subject)实验将40 类受测对象分为训练及测试集[24],训练集编号为1、2、4、5、8、9、13、14、15、16、17、18、19、25、27、28、31、34、35、38,其余为测试集,训练集和测试集分别为40 320 和16 560 个样本;交叉视图(cross view)实验选取第一台摄像机采集样本为测试集,其余为训练集,训练集和测试集分别为 37 920和18 960 个样本。
本节实验交叉主体与交叉视图迭代训练中训练集与测试集对应的准确率与损失曲线如图5 所示。由图5 可知,模型准确率随着训练次数增加而增加,迭代至220 次时准确率趋于稳定且损失值收敛。此外,基于NTU RGB-D 数据集可得交叉主体及交叉视角准确率分别为88.73%和90.01%,其识别结果可由图6 所示的混淆矩阵表征。

图5 NTU RGB-D 数据集中训练集与测试集对应的准确率与损失曲线
图6 中各列及各行分别为所提方法预测结果及对应真实类别,主对角线元素表示该动作准确率,其余为识别错误率。由图6 可知,交互相似动作,即喝水、刷牙与打电话,阅读、写作、键盘打字与玩手机的交叉主体及交叉视角准确率分别不低于84%和86%;双人交互相似行为,即握手和传递物品的交叉主体及交叉视角准确率分别不低于80%和88%。此外,其他动作交叉主体及交叉视角准确率分别为85%~92%和87%~94%。由此可知,主题多样化及视角变化等复杂场景下所提方法具有较高准确率。

图6 基于NTU RGB-D 数据集所得混淆矩阵
基于NTU RGB-D 数据集,所提方法及主流方法所得交叉主体及交叉视角准确率如表1 所示。
由表1 可知,基于可变参数关联骨架的LARP(lie group action recognition point)[8]与基于3D 几何关系的Dynamic skeletons[25]没有考虑深度时空信息,因而准确率不高;Multi temporal 3D CNN 将关节映射至3D 空间并通过3D CNN 提取深度特征,从而可有效提升准确率至66.85%、72.58%[26],然而其没有考虑骨骼识别时域信息;ST-LSTM+Trust Gate[27]与Two-Stream RNN[28]分别以相关关节作为双流RNN 输入以充分利用时空信息,然而输入时序存在较大信息冗余,从而影响识别效果;基于此,STA-LSTM[17]基于时空注意力机制以识别关键帧及关节,从而将准确率提升至73.40%、81.20%,然而该方法只考虑关节特征而忽略拓扑关系,故准确率改善有限;DS-LSTM(denoising sparse LSTM)[15]考虑帧间帧内关节链接相对运动趋势,Fuzzy fusion+CNN[11]编码关节间空间关系以提升准确率,然而二者缺乏外观特征,从而限制识别能力;所提方法将空间约束输入具有时空注意力机制的LSTM 模型以抽取深度时空特征,并基于热图抽取表观特征为有效补充,从而提升准确率至88.73%、90.01%,这表明复杂场景下所提方法具有较高准确率。

表1 NTU RGB-D 数据集各方法所得交叉主体及交叉视角准确率
2.3 Northwestern-UCLA 数据集
Northwestern-UCLA 数据集由1 494 个序列组成,由10 名实验者完成如下10 类动作[30]:单手捡、双手捡、扔垃圾、行走、坐下、站起、穿、脱、扔、拿。该数据集由3 个不同视角采集获得,前2 个摄像机所得样本为训练数据,其余样本为测试数据。
如表2 所示,基于骨骼特征手工提取的HOJ3D(histograms of 3D joint)方法[31]假设骨骼垂直于地面以投影聚类判别动作,忽略骨骼空域关系,从而导致准确率较低;LARP[8]则基于可变参数关联骨架表征动作,因而性能优于HOJ3D,但是其忽略骨骼动态信息;HBRNN-L(hierarchically bidirectional RNN LSTM)[32]考虑关节时域特征,从而获得78.52%的准确率,但是其缺乏外观信息难以区分相似动作;Multi-view dynamics+CNN[33]提取多视角动态图像以应对空域变化,考虑外观特征,但是其缺乏时序特征;所提方法基于具有时空注意力机制的LSTM 模型以有效表征重要关节动态信息,并基于热图抽取颜色纹理信息,从而获得动作高可分表达,进而将准确率提升至85.73%,分别比HBRNN-L和Multi-view dynamics+CNN 提升7.21%和1.53%,这表明不同视角及主题多样化条件下所提方法具有较高识别能力。

表2 Northwestern-UCLA 数据集实验结果
2.4 SBU Interaction 数据集
SBU Interaction 数据集包含如下8 类交互动作[34]:靠近、远离、踢、推、握手、拥抱、递书本、拳击,共分为5 个交叉集,选取其中4 个作为训练集,其余为测试集,对各交叉集验证结果取平均值作为最终准确率。
所提方法及对比方法所得准确率如表3 所示。由表3 可知,所提方法准确率可达95.46%,分别比STA-LSTM[17]、ST-LSTM+Trust Gate[27]、Two-Stream RNN[28]提升3.96%、2.16%、0.66%,这表明小样本数据集下所提方法准确率较高。

表3 SBU Interaction Dataset 数据集实验结果
2.5 消融实验
为进一步验证所提方法有效性,基于上述数据集研究所提方法中具有空间约束时空注意力LSTM 模型及特征融合模块对准确率影响,所得结果如表4 所示。由表4 可知,相较于仅基于时空注意力的STA-LSTM 模型,STA-SC-LSTM 所得准确率分别提升2.43%、1.52%、0.83%,表明所构造空域约束条件可提升动作识别能力;相较于仅基于关节时序特征的STA-SC-LSTM,双流融合所得准确率分别提升12.90%、7.29%、8.15%及3.13%,表明表观特征可作为骨骼深度特征的有效补充以弥补基于关节时空特征的相关模型对相似动作较低区分度的缺陷。

表4 不同模型实验结果
2.6 双流融合权重设置
融合深度关节及手工表观特征可有效提升相似动作判别性能,然而融合权重难以由理论确定。由此,本节基于上述数据集,通过实验确定融合权值。具体地,(λ1,λ2)可依次设为(0.4,0.6)、(0.5,0.5)、(0.6,0.4)和(0.7,0.3)。由表5 可知,权重由(0.4,0.6)变化至(0.5,0.5),即关节特征权重占比增加则准确率提升,表明识别结果主要依赖于关节特征。当权重由(0.6,0.4)变化至(0.7,0.3),准确率降低,表明外观特征缺乏,从而影响相似动作区分。由上述分析可知,权重为(0.6,0.4)时识别精确度最高,由此设定λ1=0.6、λ2=0.4为融合权重。

表5 不同融合权重比的实验结果
3 结束语
本文提出基于关节序列深度时空及表观特征融合的动作识别方法。所提方法首先构建关节空域拓扑约束以增强关节特征表达有效性,其次构造具有时空注意力的LSTM 以定位高可分重要帧及关节,再次基于热图提取关键关节周围颜色纹理表观特征,最后逐帧融合关节深度及外观特征以获得高可分的动作有效表达。实验结果表明,在NTU RGB-D、Northwestern-UCLA 以及SBU Interaction Dataset 数据集上,所提方法的准确率分别为88.73%、90.01%,85.73%和95.46%,明显高于现有主流识别方法,表明视角变化、噪声、主体多样化等复杂场景下所提方法的有效性。需要注意的是,由实验可知,相较于交叉主体,交叉视图准确率改善幅度较小,基于此,未来研究将着重关注多视角场景下表观及关节高可分稳健特征抽取及有效融合方法。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
世界科学技术-中医药现代化(2021年8期)2021-12-21
河北果树(2021年4期)2021-12-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
小学生学习指导(低年级)(2020年11期)2020-12-14
福建基础教育研究(2019年10期)2019-05-28
作文大王·低年级(2018年10期)2018-12-06
