
基于多重规则和路径评价的在线中英文手写识别方法
2022-03-12 05:56付鹏斌刘鹏辉杨惠荣董澳静
计算机工程 2022年3期
付鹏斌,刘鹏辉,杨惠荣,董澳静
(北京工业大学 信息学部,北京 100124)
0 概述
中英文混合文本识别是一个涉及字符切分、分类和识别的复杂上下文问题。目前,对于印刷体中英文混合文本识别的研究成果较多,且识别率较高[1-2]。在手写文本识别方面,文献[3]将输入的手写中文文本行切分为字符片段,动态构建候选序列,并通过结合多种上下文信息搜索最佳路径,实时得到识别结果。文献[4]基于半马尔科夫条件随机场构建识别候选序列,自然融合候选片段置信度、几何和语义得分进行路径评价,并提出一种前后向阵列修剪算法,减少使用语言模型训练的计算量。文献[5]提出一种结合三元语言模型紧凑的CNNBLSTM 方法,使用多阶段训练方法实现多感受野机制,该方法达到了业界前沿的效果。文献[6]开发了“谷歌”在线手写识别系统,支持22 种脚本和97 种语言,实现了快速、高准确度的识别。文献[7]开发了在线手写识别系统,支持102 种语言,识别效果较好。但上述在线手写文本识别方法的研究[8]以及相关识别的研究[9-11]仅能支持单一语言的文本识别,缺乏对中英文混合手写文本识别的支持。在商业领域,绝大多数国内输入法不支持中英文混合手写识别。法国公司Myscript 开发的手写笔记软件nebo 支持中英文混合手写识别,且识别效果在业界处于较高水平,但软件收费且核心识别技术不对外公开。因此,亟待研究一种有实用价值的在线中英文混合手写识别技术。
本文提出一种在线中英文混合手写文本识别方法,使用基于多重规则的切分算法得到字符片段,并在分类算法中进行中英文片段分类。在此基础上,结合自然语言模型和动态规划算法得到字符序列,分别送入基于CNN 的在线手写识别模型,最终得到中英文混合手写文本识别结果。
1 预处理
联机手写数据通常是通过手写板、手写笔或鼠标得到的按书写笔画排序的点数据序列。在无约束情况下,手写文本常常会出现字符粘连、交错、噪声点以及文本行书写倾斜的情况,影响识别效果。特别是文本行的倾斜,会对后续文本切分和识别带来严重的影响,因此预处理阶段的重要工作除了降噪外就是进行文本行的倾斜矫正。由于文本行的字符中心大致符合直线拟合趋势,因此采用最小二乘法对手写文本行进行倾斜矫正。
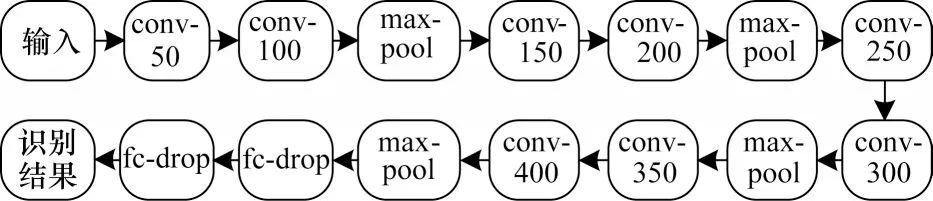
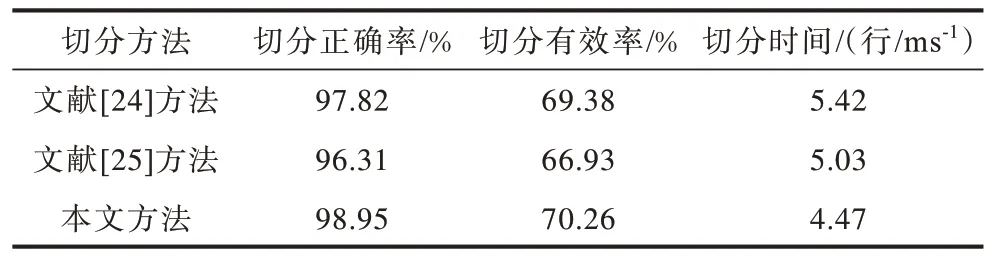
令每个笔画的点坐标序列为P[(x0,y0),(x1,y1),…,(xn,yn)],则该笔画中心点为。对文本行中所有笔画中心点(xi,yi),0 结合最小二乘法思想: 求得拟合直线后,计算文本行中心点,计算公式如式(6)所示: 其中:xmin,xmax分别为文本行点坐标序列中x的最小值和最大值。 拟合直线与水平面的夹角为α,文本行围绕中心点进行中心旋转α度。倾斜矫正效果如图1 所示。 图1 倾斜矫正效果Fig.1 Tilt correction effect 由于预处理后得到的笔画序列包含中、英文字符且可能存在字符重叠、粘连问题,因此需要进行字符切分,且字符切分算法的好坏将直接影响文本识别结果。欠切分方法得到的字符片段可能包含多个字符,会导致识别错误,而过切分方法得到的字符片段通常包含单个字符或单个字符的子片段,可通过合并算法获得正确字符。因此,本文结合字符笔画的几何特征和空间特征,设计了基于多重规则和路径评价的中英文混合文本分割算法。 对于在线手写文本而言,文本的切分就是笔画序列的正确分割和整合。本文结合水平相对位置、垂直重叠率、面积重叠率对笔画进行整合,相关定义如下: 定义1垂直重叠率是相邻两个笔画在垂直方向重叠的比率。 根据定义1 进行笔画整合的示意图如图2(a)所示,其中:lo为两笔画重叠长度;la为笔画a1的长度;lb为笔画b1的长度。 定义2面积重叠率是相邻两个笔画或笔画组合片段的最小外包矩形面积的重叠部分与两块面积中较小者的比值,其计算公式如式(8)所示: 根据定义2进行笔画整合的示意图如图2(b)所示,其中:So为重叠面积;Sc为笔画c的最小外包矩形的面积;Sd为笔画组合片段d的最小外包矩形的面积。 图2 笔画整合示意图Fig.2 Schematic diagram of stroke integration 切分算法使用相邻两笔策略,假设2 个相邻笔画a和b,a书写在前,b书写在后,手写文本的笔画序列使用如下规则进行整合: 规则1水平相对位置规则。若笔画b的最右端在笔画a最右端的左侧,则认为2 个笔画属于同一字符片段,进行笔画整合,如图2(a)中a1和b1。 规则2垂直重叠率规则。若笔画a和笔画b的垂直重叠率超过阈值(本文取50%),则认为2 个笔画属于同一字符片段,进行笔画整合,如图2(a)a2和b2所示。 根据上述两个规则,笔画序列中的某些笔画已完成了整合,称为笔画组合片段;若2 个相邻笔画或笔画组合片段c和d不满足规则1、2,如图2(b)所示,则需使用如下规则进一步整合: 规则3面积重叠率规则。若c和d的面积重叠率超过阈值(本文取40%),认为2 个笔画或笔画组合片段属于同一字符片段,进行笔画整合。 笔画整合完成之后,若笔画组合片段的宽度值超过阈值(本文取笔画片段高度的1.8 倍),则认为该笔画存在连笔情况,应进行切分。 根据大量统计和相关文献[12]的研究可知,中文字符中的大部分连笔笔画均具有一个明显的特征,即存在一个较长的、方向稳定的笔画,且笔画的书写方向为从左下方到右上方。不仅中文连笔字符具有这个特征,而且英文也具有同样特征。另外,英文还有一种连笔情况,即字符笔画的书写方向为从左上方到右上方。连笔笔画还具有相同的位置特征,即连笔笔画的位置位于整个笔画的中间部位。依据这2 个特征就可以找到字符连笔笔画并进行切分。 本文使用八方向特征来处理字符连笔的切分。八方向特征是特征提取中常用的方法[13],它是四方向特征(水平、垂直、斜上、斜下)的细化,能够较好地提取8 个方向的笔画,八方向分解图如图3 所示,字符连笔情况多出现在D7、D8 的方向特征图中。 图3 八方向分解Fig.3 8-direction decomposition 八方向特征图是通过计算字符点序列中每个点的方向生成。给定某一字符中的某个坐标点pk,前一点为pk-1,后一点为pk+1,它的方向向量计算公式如下: 得到方向向量Vk后,将其投影到8 个方向上并进行向量分解,得到八方向特征图。 针对字符连笔书写情况,本文设计了一种检测连笔笔画并切分的方法,具体步骤如下: 步骤1连笔检测。计算字符笔画或笔画组合片段的宽度值,如果宽度值大于阈值,那么认为该笔画或笔画组合片段存在连笔情况,筛选出该笔画或笔画组合片段,如图4 所示,其中词组“中国”是一笔写出来的。 图4 笔画筛选示意图Fig.4 Diagrammatic sketch of stroke filter 步骤2根据筛选出的连笔笔画生成对应的八方向特征图,并根据连笔方向情况选择D7、D8 方向图,如图5 所示。 图5 特征方向图搜索Fig.5 Search for feature direction diagrams 步骤3搜索连笔笔画。在特征方向图中,搜索到的范围内较长的连续点序列即为连笔笔画,W为特征方向图的宽度。 步骤4连笔笔画切分。在现有研究中,切分点大多采用连笔笔画的中点,且在切分过程中并不会删除连笔区域的冗余点坐标数据,即只做切分,不做其他处理。但是,冗余的点坐标数据对字符识别准确率有一定影响。因此,本文定位2 个切分点,并删除连笔部分的冗余笔迹,即2 个切分点中间的点坐标数据做删除处理。切分点的位置定在笔画的除连笔部分剩余其他部分的最小外包矩形与字符笔迹的交点上,如图6 所示,图中圆圈为确定的2 个切分点。 图6 确定切分点示意图Fig.6 Schematic diagram of determining the point of division 经过以上步骤,得到字符连笔切分的效果如图7所示。 图7 连笔切分效果图Fig.7 Effect drawing of continuous pen segmentation 预处理完成的手写文本笔画序列通过水平相对位置、垂直重叠率、面积重叠率3 个规则进行整合,之后进行连笔检测并切分,最终得到切分完成的中英文字符片段序列,切分算法如算法1 所示。 算法1基于多重规则的中英文手写切分算法 由于两种语言类别数相差较大、字符结构不同、相关度不高,混合识别不能达到较好的效果。因此,通过基于多重规则的切分算法得到的字符片段需要进行中英文分离,把分离后的中、英文字符片段序列进行合并,之后分别送入单语言模型进行识别。中英文混合字符片段的分离通过基于笔画个数、宽高比、中心偏离距离、平滑度等几何特征和字符片段识别置信度相结合的分类算法来完成。 如图8 所示,本文提取的字符片段几何特征包括字符片段的宽度、高度、宽高比、笔画个数、字符间距、中心偏移距离、平滑度。具体定义如下: 图8 几何特征提取Fig.8 Geometric feature extraction h:字符片段的高度值。 w:字符片段的宽度值。 hw:字符片段的宽高比值。 n:字符片段的笔画个数。 d:字符片段间的距离。 定义4文本行高度估计值H。对所有笔画按高度值升序排序;如果输入笔画数小于阈值β,则H取所有笔画中的高度值最大的笔画高度。如果输入笔画数大于阈值β,则H取笔画序列中高度值较大的1/2 笔画的平均值。设置阈值β(本文为10)是为了防止输入笔画过少,导致H估算偏差较大。 定义5中心偏移距离z。字符片段中心点与文本行中心线的距离,字符片段中心点在文本行中心线下方为负值,在文本行中心线上方为正值。 定义6字符片段的笔迹平滑度k,反映了书写笔迹的弯曲程度。每个笔画上随机选择5 个点,计算每个点的局部曲率值,假设笔画L由坐标点构成,则对应的方程为y=f(x),笔画L在点M(x,y)处切线的斜率为y′=tanα,则 定义7识别置信度是为了估计字符识别结果的准确性。本文识别置信度为卷积神经网络输出的Softmax 概率值。 根据以上特征,本文设计了基于几何特征的粗分类器和基于识别置信度的细分类器。 将以下4 个特征作为粗分类器的主要依据: 1)中文字符片段的笔画个数明显多于英文字符片段; 2)中文字符片段的高度高于英文字符; 3)英文字符片段笔迹的平滑度高于中文字符; 4)英文字符中心点位于文本行中心线下方。 粗分类器能够将大部分字符片段正确分类,而无法分类的字符片段将进入细分类器。细分类器包含了基于CNN 的在线手写英文识别模型和在线手写汉字识别模型。进入细分类器后,每个字符片段将会得到2 个模型对应的识别置信度,若手写汉字识别模型的识别置信度较大,则归为中文片段,否则归为英文片段。具体的字符片段分类算法如算法2所示。 算法2基于几何特征和识别置信度的分类算法 针对算法2 中分类器的限定条件作如下说明:在一般情况下,英文字符的笔画最多为3 个,若n≥5,可以认为该字符片段为中文;若hw<1,z<0,d≥行高,即字符片段的宽度小于高度、字符片段的中心点位于文本行中心线的下方且字符片段间的距离相对较大,可以认为该字符片段为英文;经过对大量英文字符的平均曲率进行计算统计,发现k的最小值约为0.4,若k≥0.6,可以认为该字符片段为英文,若k≤0.2,则认为该字符片段为中文。 通过上述文本切分和字符片段分类的算法,得到了字符串基本切分片段,由于中文字符笔画数多、结构复杂,且大部分字符不能一笔完成,因此字符片段中存在欠合并的现象。所以,本文结合自然语言模型和动态规划的路径评价算法搜索最优的字符合并路径。基于字符片段识别框架,首先将一个字符串切分为基本片段,接着将一个或者多个基本片段合并为候选字符,生成候选识别网络,如图9 所示。候选字符首先被基于CNN 的在线手写中、英文字符识别模型进行识别并得到识别置信度;然后结合自然语言模型,通过路径评价算法得到路径评分;最后,使用路径搜索算法选出评分最优的合并路径,得到合并完成的待识别字符序列。 图9 部分候选识别网络Fig.9 Part of the candidate identification network 对于自然语言概率模型而言,假设文本行S的识别结果为R=(R1,R2,…,Rn),以P(S)代表该识别结果的概率,则概率评估函数为: 根据链式法则,概率评估函数可转化为: 由于输入法对识别时间要求较高,考虑到计算量以及语料库的大小,本文使用N-gram 模型的二元语言模型来计算式(16)的概率,因此: 其中:每个字符出现的概率只取决于前一个字符。 本文训练的自然语言概率模型所使用的数据库为搜狗实验室公开发布的搜狐新闻数据(SogouCS)以及全网新闻数据(SogouCA)。在不考虑其他模型的情况下,自然语言模型概率最大的字符组合即为最佳的识别路径。如图10 所示,为字符片段通过计算自然语言模型概率得到的最优识别路径。 图10 二元语言模型路径Fig.10 Binary language model path 对字符片段组合加以规则约束,可以减少候选片段组合的数量,进而提高路径搜索效率。本文定义规则如下: 1)候选字符合并个数不超过3 个; 2)候选字符合并后的宽度不超过高度的2 倍; 3)待合并的2 个候选字符的水平距离不超过候选字符宽度的1.5 倍。 基于规则的组合策略,对候选字符片段进行组合,一次组合称为路径s。组合后的片段分别提取特征得到X=(x1,x2,…,xn),如果假设字符串识别结果为R=(r1,r2,…,rn),那么该识别结果的后验概率[14]为: 其中:P(s|X)代表在获取特征X的情况下组合路径s的后验概率,P(R|Xs)代表在获取组合路径s的情况下识别结果R的后验概率。 考虑到字符片段组合后包含大量的路径以及能够避免大量的计算,最优结果可以近似计算为: 其中:P(s|X)以判断该字符是否有效切分来表示当前路径的概率。由于本文使用的文本行数据库没有切分点数据,以及加入了基于规则的组合策略,因此本文没有使用该分类器的概率值。 因为本文识别技术主要应用于输入法,没有考虑符号、数字等其他字符,所以没有使用几何模型,仅使用了单字符识别概率值和自然语言模型。P(R|Xs)可以表示为: 其中:p为常数;p(ri|xi)为字符分类的结果;p(R)为自然语言模型的结果。 考虑到不同分类器的权重问题以及克服路径长度的影响,本文使用了修正的片段宽度加权方法,通过公式两边取对数,并在每一项前加入权值来解决权重问题;通过归一化字符片段宽度以及语言模型对整个长度做归一化来克服路径长度的影响。计算公式如下: 其中:wi代表第i个路径中片段的宽度;代表单字符分类器概率结果的对数值;代表自然语言模型的概率结果的对数值;λ1为自然语言模型参数。 通过路径评价算法得到本次组合的评分,接下来,要从所有组合路径中选择一条评分最高的路径。虽然采用了基于规则的组合策略对字符片段组合加以约束,但仍有大量的组合方式。若对全部的组合方式进行计算,文本识别性能将会变得极为低效。所以,快速有效的路径搜索算法对提高文本识别的性能至关重要。路径评价函数是计算所有候选字符得分的加和值,取最大加和值的字符路径为最优路径,因此可以使用动态规划算法进行路径搜索,在搜索的中间节点中保留一条最优路径,从而使路径搜索快速且有效。路径搜索的算法如算法3 所示。 算法3路径搜索算法 在文字识别领域,CNN 模型取得了巨大的成功[15-17]。本文把前述分割得到的中、英文字符序列分别送入CNN 模型并进行训练识别。 单字符的识别采用了经典的CNN模型LeNet-5[18-19],并在其基础上进行改进: 1)输入输出层:输入尺寸修改为本文输入尺寸,后续各层的尺寸相应改变,在输出层添加Softmax 激活函数,从而加速模型收敛,缓解Sigmoid 函数发生梯度消失的问题。 2)卷积层、池化层:当分类数越大时,模型所需要的特征信息也相对增多,于是增加模型的层数和特征图数量;按照两层卷积层、一层池化层的组合排列,添加了6 层卷积层和2 层池化层,特征图的数量从50 到400 逐层增加。卷积层采用3×3 大小的滤波器,池化层采用2×2 的滤波器。 3)全连接层:本文采用2 个全连接层,每层有1 024 个单元。由于训练样本有限、模型参数过多、模型层次过深,导致训练时易发生过拟合现象。为避免该现象的发生,本文加入了dropout 算法。 基于以上改进,本文设计并实现了14 层CNN 模型,模型包括8 层卷积层、4 层池化层、2 层全连接层,如图11 所示。 图11 CNN 模型结构Fig.11 Structure of CNN model 由于英文字符类别数较少,因此本文将提取的单字符特征图作为网络模型的输入。 对手写字符进行线性插值、平滑、归一化等预处理后,通过计算该字符的最小外包矩形得到字符边界,将其平均分为12×12=144 块,使该字符的所有点坐标落入小方块中,统计每个小方块中字符点坐标的个数,若个数大于0,则该方块的特征值为1,否则为0;得到12×12 的特征图,特征图提取过程如图12所示。最终,把得到的特征图作为CNN 的输入。 图12 特征图提取Fig.12 Feature map extraction 模型训练的数据集为哈尔滨工业大学收集的HIT-OR3C[20]中的Letter 子集以及华南理工大学收集的SCUT-COUCH2009[21]英文字母子集。 文中用于在线手写中文汉字识别的流程大致分为3 个步骤:预处理,特征提取,CNN 训练识别。 首先,对字符进行预处理。主要有长宽比映射关系归一化、平滑、线性插值、加入虚拟笔画等,加入虚拟笔画有助于字形的区分(这里的虚拟笔画是指上一笔结束点和下一笔起始点之间的连线,也就是当书写完成当前笔画后准备书写下一笔画时,笔尖脱离纸面在空中划出的轨迹),如图13 所示。 图13 虚拟笔画Fig.13 Virtual stroke 然后,将预处理后得到的字符点坐标序列进行方向分解,生成D1~D8 这8 个方向的特征,即点坐标的八方向特征图提取。 虽然CNN 在数据处理时,不需要显式构造特征,但原图输入最具有代表性,且将对最终的分类结果产生积极的影响。因此,本文把8 方向特征图加上原图构成9 通道特征图(由9 张32×32 像素的图组成)作为CNN 的输入,如图14 所示。 图14 9 通道特征图Fig.14 9 channel characteristic diagram 模型训练的数据集为中科院收集的CASIAOLHWDB 1.0[22]、CASIA-OLHWDB 1.1 以及HIT-OR3C的中文子集。 本文所提在线中英文混合手写文本识别方法通过预处理、文本切分、字符片段分类、字符片段合并以及单字符识别,最终得到文本识别结果,识别流程如图15 所示。 图15 本文方法识别流程Fig.15 Identification procedure of the method in this paper 选用公开的在线手写中文文本数据集CASIAOLHWDB2.0-2.2[23]以及本文采集的在线混合手写中英文文本行数据集OH-C_E_TextDB,并将常用中文字词和英文单词随机重组为文本样本,共计3 000条,30 名采集人员(大学生10 名,研究生10 名,教师10 名)进行手写数据采集,每人随机采集100 条。部分文本样本如表1 所示。 表1 部分样本数据Table 1 Partial sample data 本文通过切分正确率Rc和切分有效率Rν来验证过切分算法的性能,计算公式如下: 其中:Mc表示真实切分点与正确切分点的匹配个数,即正确切分个数;Mt表示真实切分点总数;Mz表示所有切分点的个数。Rc的值越大说明命中正确切分点的数量越多,Rν的值越大说明字符出现过切分的情况更少。 表2 和表3 分别给出了本文切分算法及其他切分算法在CASIA-OLHWDB 2.0-2.2 数据集、OH-C_E_TextDB 数据集上的切分性能测试结果。 表2 不同方法在CASIA-OLHWDB 2.0-2.2 数据集下的切分对比实验结果Table 2 Experimental results of segmentation comparison of different methods under CASIA-OLHWDB 2.0-2.2 data set 表3 不同方法在OH-C_E_TextDB 数据集下的切分对比实验结果Table 3 Experimental results of segmentation comparison of different methods under OH-C_E_TextDB data set 通过表2 和表3 的对比实验结果可以发现,本文切分算法相比其他切分算法的切分正确率、切分有效率均有所提高,并且减少了切分耗时。相比表2,本文切分算法在表3 的切分正确率、切分有效率有所提升,而其他2 种切分算法均有所下降。究其原因,发现OH-C_E_TextDB 数据集中有大量的英文连笔和中文连笔数据,而其他2 种算法对字符连笔情况处理效果较差,尤其是英文连笔的切分。图16 给出了3 种切分方法在实际数据中的对比图。通过实验结果可知,本文切分算法不仅对在线手写中文文本行切分有效,而且对包含字符连笔的在线混合手写中英文文本行切分有较好的切分效果。 图16 不同切分方法在实际数据中的对比Fig.16 Comparison of different segmentation methods in actual data 为证明本文方法的有效性,采用字符串编辑距离的思想,具体用了3 个评判标准:文本行识别率(Row Rate,RR),文本正确率(Correct Rate,CR),文本精确率(Accurate Rate,AR),计算公式如下: 其中:Tr代表识别完全正确的文本行数;Tz代表识别的总文本行数;Nt代表每行真实文本个数;De代表真实字符与识别结果对比的删除错误数目;Se代表真实字符与识别结果对比的替换错误数目;Ie代表真实字符与识别结果对比的插入错误数目。 在OH-C_E_TextDB 数据集上的实验结果表明,本文方法对在线混合手写中英文文本的识别正确率、文本识别精确率以及文本行识别率分别可达93.67%、92.25%、91.53%,验证了本文在线中英文混合手写文本识别方法的有效性。 把本文识别方法应用到在线输入系统中,该系统利用动态维护候选字符序列的思想,进行实时切分识别。对系统进行实时性分析发现,每当新笔画输入时,系统动态更新笔画序列并进行切分、分类、合并以及识别,当抬笔时间超过1 s 时,系统判定字符输入结束并立即输出识别结果。系统识别效果如图17所示。图18展示了输入“online 手写中English 混合识别”的具体识别过程。由图18 可知,字符连笔可以被正确分割并识别;在书写中文字符“识”的过程中,先写‘讠’,系统更容易认为是英文字符‘i’,而当把另一部分‘只’书写完成后,正确识别为“识”。 图17 在线中英文手写识别效果Fig.17 Online Chinese and English handwriting recognition effect 图18 文本识别过程Fig.18 Text recognition process 针对多数在线输入法不支持中英文混合手写文本识别的问题,本文提出一种在线中英文混合手写文本识别的新方法。通过切分文本得到字符片段,并使用分类算法对字符片段进行分类。此外,结合自然语言模型和动态规划算法将字符片段合并为字符序列,并通过在线手写识别模型得到中英文混合手写文本识别结果。实验结果表明,相比其他切分算法,本文算法对在线手写中文文本行及包含字符连笔的在线混合手写中英文文本行均能较好地进行切分,在线中英文混合手写文本识别正确率达93.67%。但本文研究的文本识别方法没有考虑标点符号、数字等特殊字符,下一步将通过研究中文、英文、数字、符号4 种类别的识别方法,完善本文模型。
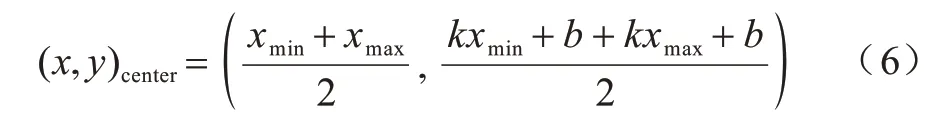

2 中英文混合文本分割
2.1 基于多重规则的中英文手写文本切分










2.2 基于几何特征和识别置信度的字符片段分类算法




2.3 结合自然语言模型和动态规划算法的路径评价


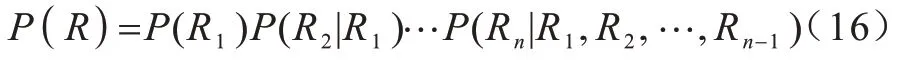







3 基于CNN 的在线手写字符识别
3.1 CNN 模型
3.2 在线手写英文字符识别

3.3 在线手写中文汉字识别


4 实验与结果分析

4.1 实验数据

4.2 结果分析






5 结束语
猜你喜欢
隧道建设(中英文)(2022年2期)2022-03-10
故事作文·低年级(2021年12期)2021-12-21
作文成功之路·小学版(2020年7期)2020-08-24
汉字汉语研究(2020年2期)2020-08-13
中华神经创伤外科电子杂志(2019年2期)2020-01-04
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
中华神经创伤外科电子杂志(2019年1期)2019-02-28
电子制作(2018年18期)2018-11-14
