
采用数据可听化的地形剖面线分析方法
2022-03-13 04:04余逸凡陈楠
华侨大学学报(自然科学版) 2022年2期
余逸凡, 陈楠
(1. 福州大学 空间数据挖掘与信息共享教育部重点实验室, 福建 福州 350108;2. 福州大学 数字中国研究院(福建), 福建 福州 350108)
原始的地形剖面线能够直观反映地势变化[1],沿特定地形特征线布设的地形剖面线避免了走向和位置的不确定性[2],而以流域为地形剖面线分析的基本单元,可以保证地理实体的完整性[3].在相同地貌类型区、特定尺度下,沿分水线布设的地形剖面线具有较为稳定的形态与结构特征[4-5].前人研究地形剖面线多借助数字高程模型(digital elevation model, DEM),采用统计量化或空间频谱分析的方法.如胡洁等[2]将地形剖面线看成一维连续空间域信号,采用空间频谱分析方法,通过辨识频率成分分析地貌侵蚀特征;殷宗敏等[6]以单元平均高程代替地形剖面线中的点状数据,运用地貌信息熵模拟地形起伏;贾旖旎[4]对地形剖面线的量化指标体系做系统研究,探究统计、形态,以及频率特征量化标准,并结合沿分水线、沟沿线、沟谷线布设的地形剖面线[7-10],能有效反应流域形态、土壤侵蚀及发育规律.此外,甘淑等[11],邹斌文等[12]分别对垂直于地形剖面线方向上一定缓冲区范围内的高程信息进行了统计分析;曹建军等[13]沿着不同方位角的间隔布设地形剖面线,进而支持黄土地貌类型的精确划分等;何清等[14]运用空间频谱分析的方法探究了二维地形频域的分布规律等.综上所述,目前方法主要通过统计量化或空间频谱分析的图形化方法分析地形剖面线,还没有学者从声音的角度探究地形剖面线特征.
声音和图形是人类获取信息的最重要途径,人对声音刺激的反映时间快于视觉.可听化就是用非语音声音信号表达信息[15],它把声音的多个参数(如幅度、频率、谐波成分、时长)等组合成一个整体,使得各个部分及整体都同样可辨别且有效.声音的音乐模型(包括音高、时值、响度、音色等)反映了人的一般听觉特征,从而将数据映射为符合人类认知的声音,用人类可辨析的声音信号表达信息.李伟等[16]系统探讨了地理信息的可听化表达,制作了降雨预报专题地图,为将可听化方法引入地学领域奠定了基础,同时为地理信息多维表达提供新的研究思路.谢文俊等[17]对数据-声音映射模型进行了深入研究,实现了PM2.5数据的可听化表达.田德森等[18],万刚等[19],张德等[20]用人类可辨析的声音信号表达地理信息,实现了专题地理信息的多维交互和有效表达.外国学者Monajjemi等[21]将生物大分子数据转化为乐声,达到促进数据解释的目的;Ezquerro等[22]实现沉积演替的可听化表达,探索了沉积继承中的时空变化规律等.因此,目前将声音用作数据观察方法已有丰富的研究成果.本研究引入声音知识,通过一系列声音指标对沿分水线布设的地形剖面线进行分析和描述,进而探究不同黄土地貌类型与不同声音模式的关系.
1 研究数据与方法
1.1 数据
黄土高原位于我国中部偏北,是我国四大高原之一,东西横跨经度13°20′(101°10′E~N114°30′E),南北纵贯纬度 6°25′(33°55′N~40°15′N),北接长城,南达秦岭,西抵祁连山,东至太行山,总面积达60余万km2.它是一个以黄土地貌为主体的区域地貌单元,既非单一的黄土地貌,又非各种地貌均占有同等地位.黄土高原是一个完整的区域综合体.黄土高原地理位置处在沿海向内陆,平原向高原过渡地带,具有典型的大陆季风气候特征.
本研究选取代表黄土高原典型地貌的6个研究样区.各样区在黄土高原的空间分布由北向南依次处于神木县、绥德县、延川县、富县、宜君县和淳化县的境内(图1),分别对应风沙-黄土过渡区、黄土峁状丘陵沟壑区、黄土峁梁状丘陵区、黄土沟壑区与丘陵沟壑区交错过渡地带、黄土梁状丘陵区、黄土塬梁丘陵区地貌.本研究使用1∶10 000比例尺地形图(陕西省测绘局提供),并按照国家相关技术标准制作的5 m分辨率的DEM数据.

图1 研究样区分布图Fig.1 Distribution map of study area
1.2 分析方法
1.2.1 技术路线 声音以波的形式存在,声音的音高是人能感受声音差异的直观物理属性,是由物体振动的频率决定,频率越高,音高就越高,反之亦然.人耳对声波的频率变化是指数敏感的[16],能分辨2 Hz的最小频率差,对按21/12倍的规律排列的音高频率听起来是等差音高序列,且2倍频率以内的两个音高对应一个八度音程[23].在一个八度音程以内,根据弦的振动频率与其长度是成反比的规律,按和谐程度可分为最常用的七声音阶[24],即对应唱名do,re,mi,fa,so,la,si,音名C,D,E,F,G,A,B;同时,根据十二平均律[17],可将一个八度音程划分为十二个均等的部分,即公比为21/12,分别对应2n/12,n=1,2,3,…,12的等比序列关系,从而确定了七声音阶中全音、全音、半音、全音、全音、全音、半音的频率关系.如C和D为全音关系,即对应两个半音,音高频率比值为22/12;B与下一个八度音程的C为半音关系,音高频率比值为21/12.
音高频率f的国际标准值为440 Hz,即音名C,D,E,F,G,A,B,C(对应下一个八度音程)分别对应音高频率f,1.122f,1.260f,1.335f,1.498f,1.682f,1.888f,2f.此外,时值是音高的持续时间,若以t(单位为s)为基本时值,则包括t,1/2t,1/4t,1/8t,1/16t,1/32t,1/64t的等比时值序列[24],分别对应全音符、二分音符、四分音符、八分音符、十六分音符、三十二分音符和六十四分音符等.
对沿分水线布设并以集水点为起始和终止点的地形剖面线,按1 m间隔均匀生成点,从5 m高分辨率DEM上采集高程值(充分保证每一条流域边界剖面线的采样精度).对分水线上所提取的高程值进行归一化处理(文中均采用极大值极小值归一化方法),同时对七声音阶的音高频率和时值进行归一化处理,将高程值映射为声音的音高;依次统计相邻的相同音高个数,归一化处理后映射为声音的时值.具体技术路线如图2所示.

图2 技术路线图Fig.2 Technology roadmap
1.2.2 声音映射 根据国际标准音高的频率值为440 Hz,每两个半音频率之比为21/12[14],由此可以确定七声音阶的音高.声音的音高序列和时值序列,分别如表1,2所示.

表1 音高序列Tab.1 Pitch sequence

表2 时值序列Tab.2 Time value sequence
根据以上归一化处理的音高和时值,以某个样区为例,可以对其地形剖面线上所提取的高程值映射为声音的音高和时值,包括以下几个步骤.
步骤1首先对该样区DEM提取分水线.分水线示意图如图3所示.具体过程包括对DEM填洼、计算流向和汇流累计量,将水流累积阈值设置为150(主要是为了不遗漏在DEM上不易表现出的坡面汇流形成的细小沟道),从而定义最小的地表径流;然后,根据流向和筛选过流量的栅格数据生成河流链接,再结合流向数据提取小流域,将小流域栅格数据转换为矢量面,结合DEM,通过目视解译检验、合并小流域;最后,随机选取3个完整流域分别提取分水线,按1 m间距沿分水线均匀生成点.
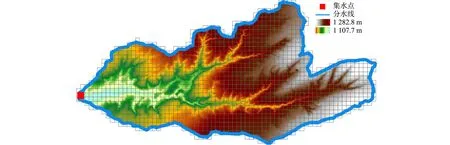
图3 分水线示意图Fig.3 Water dividing line
步骤2使用5 m高分辨率DEM,将高程值提取至分水线上的点(即从集水点起始并终止于集水点),并进行归一化处理.数据归一化后的高程值计算式为

(1)
步骤3根据表1,将高程值映射为音高,映射规则采用左闭右开区间.例如,该样区分水线上某点高程值(1 107.700 m)的归一化数值(0)落入以下区间[0,0.122),则规定其对应于此区间左界(即0)所对应的音名C和唱名do(表1).
步骤4根据表2,将相邻的相同音高个数归一化处理后映射为时值.例如,该样区分水线上某连续点音高均为C/do,且相邻的相同音高个数为82.相邻的相同音高个数中的最小值为9,最大值为2 107,使用式(1)可以计算其归一化数值为0.036.由于0.036落入以下区间(0.031,0.063],因此采用向区间右侧数值映射的规则.即规定此归一化数值0.036,对应于此区间右界(即0.063),而0.063所对应的时值为十六分音符(表2).
1.2.3 声音指标分析 不同间隔的音高组合声音模式存在差异,音高组合类型如表3所示.由表3可知:七声音阶中每两个音高的组合关系[26],三个及三个以上音高按照相差3个或4个半音的关系组合构成和弦[26].此外,低音会产生滞重感,通常变化缓慢,否则会造成混浊和不清晰;而高音则产生轻盈感,快速变化不会影响可听度[12].

表3 音高组合类型Tab.3 Pitch combination
不同长度的时值可以组合为九种基本时值组合类型,如表4所示.时值组合以拍子参照,以小节为单位.拍子的选择参考最短的时值确定.例如,某个样区地形剖面线声音的时值中最短时值为六十四分音符,则规定其选择以十六分音符为1拍,然后将所有时值转化为十六分、三十二分和六十四分音符的时值序列(从而保证所有时值组合都对应九种基本类型).转换规则为1个全音符等于16个十六分音符,依次类推.同时,规定每小节对应1拍,以便于统计小节的总个数;依次将时值按照小节进行组合,统计相应的时值组合类型个数.

表4 时值组合类型Tab.4 Time value combination
此外,与音高和时值相关的声音指标还包括音高个数,即相邻不相同音高的总个数;音高组合类型个数,即相邻音高组合中完全不协和类型以外的个数;音高变异系数是音高数据标准差与平均数之比.其依次受地形起伏剧烈程度、起伏变化类型多样性,以及起伏变化幅度的影响等.同理,小节数是以拍子为参照,统计的小节总个数;时值组合类型个数是时值组合中1个单位拍(如十六分音符)类型以外的个数;时值变异系数是时值数据标准差与平均数之比.音高和时值的声音指标综合反映了沿分水线布设地形剖面线的起伏剧烈程度、变化幅度,以及多样性等特征.

图4 音高组合示意图Fig.4 Pitch combination diagram
每个样区随机选择三条分水线,对应的声音指标的数值均取平均值.例如,某个样区三条分水线上所提取的高程值,对应声音指标小节数分别为135,164,62,计算均值为120;时值组合类型个数分别为5,7,7,计算均值为6,则规定该样区对应的小节数为120,时值组合类型个数为6.
某样区地形剖面线音高组合示意图,如图4所示.图4中:纵轴的1,2,3,4,5,6,7分别对应音名C,D,E,F,G,A,B,唱名do,re,mi,fa,so,la,si;横轴对应栅格序号;加粗黑线代表地形剖面线中起伏变化剧烈程度越大的部分;间距稀疏或稠密交错分布代表起伏变化类型越多样的部分.从图4可知:两点相距越远,时值(表2)越大.
某样区地形剖面线时值组合示意图,如图5所示.图5中:x对应时值;y对应音高.图5(a)的x2对应地形剖面线上高程值均匀下降的情况;图5(b)中x2对应加速下降的情况(减速下降的情况依次类推);图5(c)中x2对应山峰;图5(d)中x2对应山谷.因此,结合声音的音高和时值组合特征,可以表征地形剖面线上起伏变化的情况,并通过一系列声音指标对沿分水线布设的地形剖面线进行分析和描述.

(a) x2对应均匀下降 (b) x2对应加速下降 (c) x2对应山峰 (d) x2对应山谷 图5 时值组合示意图Fig.5 Time value combination diagram
此外,可以借助声音软件(如MuseScore)对映射的音高和时值产生声音.例如,设置速度为每分钟60拍子,如以十六分音符为1拍,则规定1拍对应的时长为1 s等,进而探究不同黄土地貌类型与不同声音模式的关系.
文中选取广义欧式距离的邻近性度量指标,对实验结果进行验证.广义欧式距离指在n维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离),其计算式为
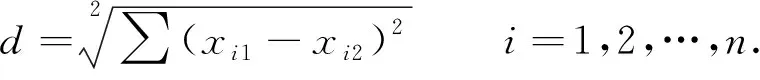
(2)
式(2)中:xi,1,xi,2分别表示第一、二个点的第i维坐标.
选取平均坡度与样区地形剖面线声音指标做对比分析.其中,平均坡度是分水线上所生成点对应坡度的平均值,其计算式为
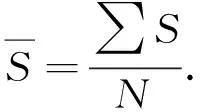
(3)
2 试验结果与讨论
2.1 音高指标分析
在6个样区中随机选取18条沿分水线布设的地形剖面线,每个样区任取一条地形剖面线的音高随着栅格序号变化,如图6所示.
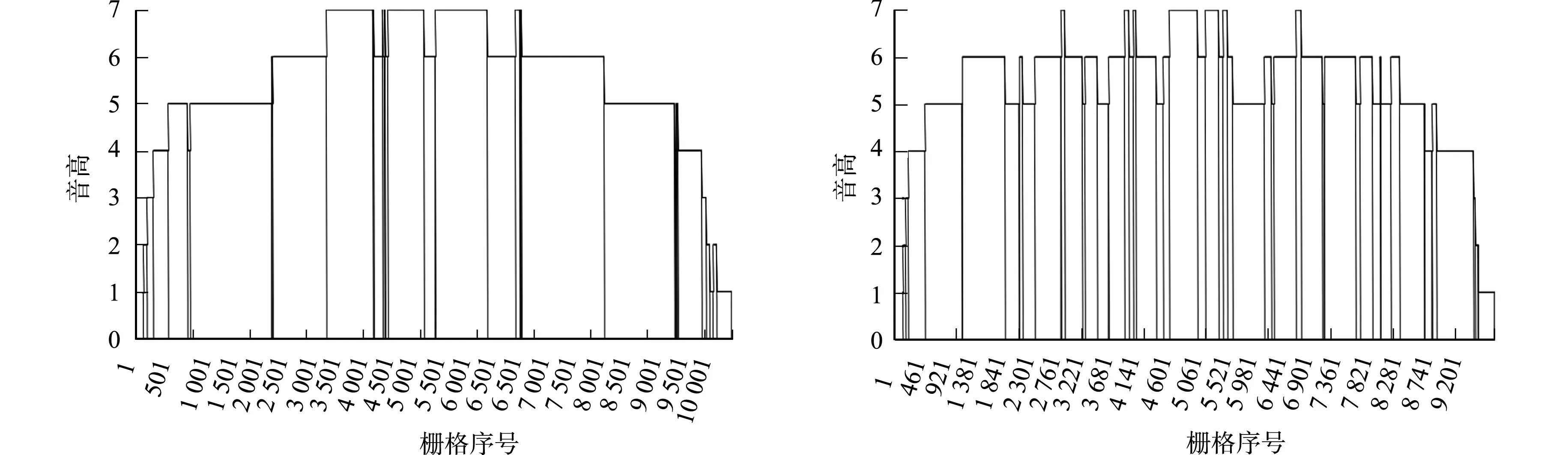
(a) 神木样区 (b) 绥德样区
从图6可知:神木、宜君、淳化样区音高分布较稀疏,绥德、延川、富县样区音高分布较密集.音高个数由南向北依次为19,25,83,113,82,31,分别对应淳化、宜君、富县、延川、绥德、神木样区.绥德、延川、富县样区的音高个数均值为93,大于神木、宜君、淳化样区的音高个数均值25,其由南向北表现为小-大-小的交错分布趋势.
从图6还可知:6个样区音高组合类型个数均为0,即相邻音高差值均为1,但是在中间位置出现连续的上升和下降;音高升降次数(即将相邻音高依次进行一次相减和相加,结果为0的情况)由南向北依次分别为6,12,63,90,64,18,分别对应淳化、宜君、富县、延川、绥德、神木样区.绥德、延川、富县样区的音高升降次数均值为72,大于神木、宜君、淳化样区的音高升降次数均值12,其由南向北同样表现为小-大-小的交错分布趋势.
此外,计算的音高变异系数由南向北依次为0.499,0.436,0.292,0.294,0.256,0.397.绥德、延川、富县样区的音高变异系数均值为0.281,小于神木、宜君、淳化样区的音高变异系数均值0.444,表现为大-小-大的交错分布趋势.音高变异系数与音高升降次数、音高个数呈负相关关系,其相关系数中的最小值为-0.900.
2.2 时值指标分析
6个样区时值总时长由南向北依次分别为4.498,3.588,15.899,17.091,22.088,7.944,由南向北均呈现小-大-小的交错分布趋势.对时值组合关系进行分析,在每个样区任选一条沿分水线布设的地形剖面线,其时值随着栅格序号变化的瀑布图,如图7所示.
从图7可知:神木、宜君、淳化样区较稀疏,绥德、延川、富县样区较稠密,由南向北呈现出稀疏-稠密-稀疏的交错分布趋势.
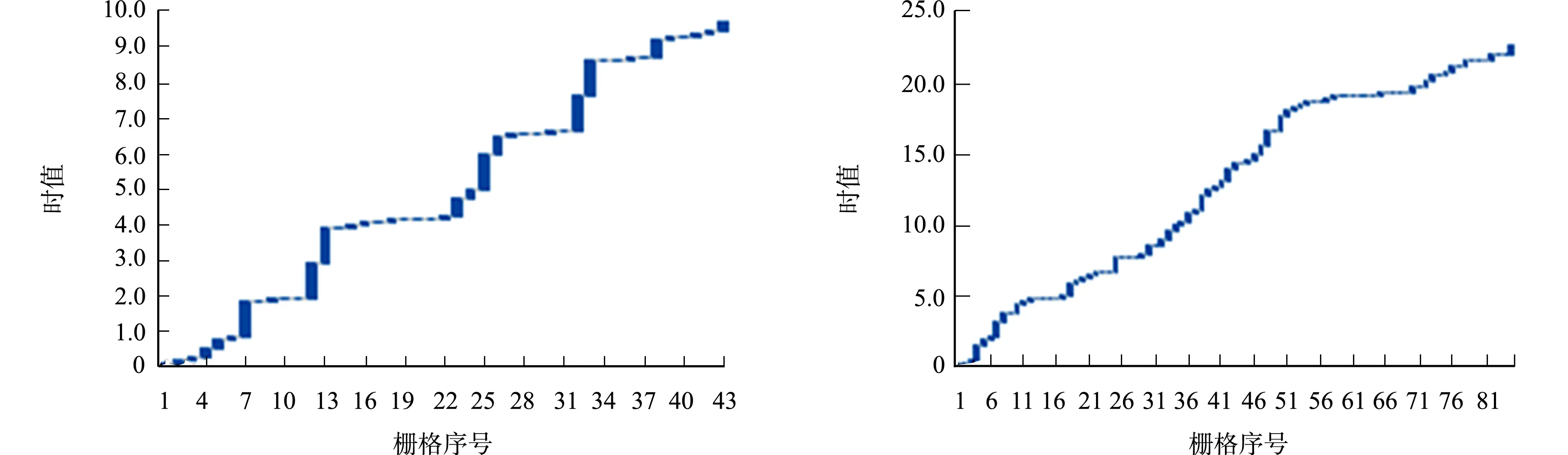
(a) 神木样区 (b) 绥德样区
选择以十六分音符为1拍,每小节对应1拍,统计各样区声音指标时值组合类型个数,如表5所示.从表5可知:6个样区由南向北小节数依次为72,58,252,273,352,120,分别对应淳化、宜君、富县、延川、绥德、神木样区.绥德、延川、富县样区小节数的均值为293,大于神木、宜君、淳化样区小节数的均值83,总体上表现为小-大-小的交错分布趋势.
从表5还可知:绥德、延川、富县样区的三十二分音符时值组合类型个数中的最小值为12,大于神木、宜君和淳化样区中的最大值4. 前六十四和后六十四分音符的时值组合类型个数呈对称分布, 相关系数为0.885.总体上,前附点大于后附点时值组合类型个数.由于黄土塬的平坦特性,宜君和淳化样区的附点时值组合类型个数受集水点两端的高程值影响较大,导致其后附点时值组合类型个数也会出现大于前附点时值组合类型个数的情况.

表5 时值组合类型个数统计表Tab.5 Statistical table of pitch combination
对比6个样区的9种基本时值组合类型个数的频率,可以发现,宜君和淳化样区的相关系数均为0.859;神木、绥德和富县样区的相关系数中的最小值为0.886,而二者之间相关系数中的最大值0.330.此外,延川样区与神木、绥德、富县样区的相关系数中的最小值为0.694.因此,总体上宜君和淳化样区的时值组合类型个数变化趋势较为一致,而神木、绥德、延川、富县样区的时值组合类型个数变化趋势较为一致.这与用小节数、音高升降次数,以及音高变异系数等声音指标衡量的结果(宜君和淳化样区对应的小节数58,72,取较小值;神木、绥德、延川、富县样区的小节数120,352,273,252,取较大值)一致.
由表5可以计算出, 6个样区时值变异系数由南向北依次为 0.811,0.705,0.583,0.610,0.468和0.631.神木、宜君、淳化样区时值变异系数的均值为0.716,大于绥德、延川、富县样区的0.554,表现为大-小-大的交错分布趋势.此外,时值变异系数与小节数、时值总时长均呈负相关关系,其相关系数中的最大值为-0.878;与音高个数、音高升降次数均呈负相关关系,其相关系数中的最大值为-0.700;而与音高变异系数呈正相关关系,其相关系数为0.937.
对比6个样区声音模式,其声音指标的数值可以进行定量化描述.总体上,绥德、延川、富县时长较长(时值总时长分别为22.088,17.091,15.899),神木、宜君、淳化时长较短(时值总时长分别为7.944,3.588,4.498);绥德、延川和富县样区(时值组合类型个数为153,177,139,小节数为352,273,252),对应节奏变化快速;神木、宜君、淳化样区(时值组合类型个数为43,16,7,小节数为120,58,72)节奏变化缓慢.根据小节数与时值组合类型个数之和,绥德样区为505,对应节奏变化最快速而且多样;宜君样区和淳化样区分别为74,79,对应节奏变化最缓慢而且稀少;中间延川、富县和神木样区依次分别为450,391,163.
2.3 整体分析
6个样区的小节数由南向北依次为72,58,252,273,352,120,表现为小-大-小的交错分布趋势,对应样区简单-复杂-简单的复杂程度分布,这与前人的研究结论一致[1,4].此外,绥德样区声音指标的数值最大,与前人研究结论中的粗糙度、盒维数等衡量样区地形起伏剧烈程度和和复杂性的量化指标相符.同时,发现了6个样区声音模式与实际地貌类型存在明显的对应关系,结合声音指标的数值,可以从声音的角度整体刻画地貌起伏特征和地貌类型.
小节数与时值组合类型个数之和,由南向北依次为79,74,391,450,505,163,其总体分布趋势与小节数量化的结果完全一致.但该声音指标同时考虑了起伏剧烈程度和起伏变化类型的多样性,更好地衡量了6个样区的复杂程度.此外,相比于音高个数和音高升降次数对采样点数敏感,音高组合类型个数、音高变异系数,则更能表现音高纵向变化;小节数、时值总时长、时值组合类型个数和时值变异系数,则可以表现音高横向组合规律;时值组合类型个数与小节数之比,则衡量了特定起伏剧烈程度下起伏变化类型的多样性.因此,综合考虑可以选择音高组合类型个数、音高变异系数、时值组合类型个数、时值变异系数、小节数、时值总时长,以及时值组合类型个数与小节数之比等7个指标作为最终的地貌类型区分的参考依据.

图8 音高与平均坡度的关系 图9 时值与平均坡度的关系Fig.8 Relationship between pitch and average slope Fig.9 Relationship between time value and average slope
利用声音的数据观察方法,还有望应用在地理信息表达、地图可视化[16-20],以及地形剖面线[1,4]等领域的研究.它可以表示连续变化数据的整体趋势信息,还有助于弥补地理信息可视化在视觉障碍群体中存在信息传递不畅的不足.此外,声音可以表示多维数据流,有望同时接收多条地形剖面线[7-10]对应的声音信号,获取比单条分析地形剖面线更多的地学信息.然而,该方法也存在一些不足,声音信号具有瞬时和抽象的特性,通常无法一次听出特定的信息,需要结合声音指标数值进行定量化描述;地学信息包含大量不同方面的信息,目前只引入两个声音参数,还不足以完全表达所有地学中的空间信息.由于人对声音信号的反应时间是0.12 s,高于视觉信号的0.15 s;人耳可以辨别的编码数目超过100个,超过了人眼可以辨别的灰阶数目.因此,将声音用作数据观察方法,有望从地形数据中挖掘比图形化方法更多的地学信息.
2.4 结果验证
在黄土高原任选一个样区(位于安塞县境内109°19′E~109°28′E,36°51′N~36°57′N,属于典型黄土丘陵沟壑区),使用1∶10 000比例尺地形图(陕西省测绘局提供),按照国家相关技术标准制作的5 m分辨率的DEM数据,验证音高变异系数等7个声音指标对地貌类型的区分能力,结果如表6所示.
由表6可知:安塞样区的音高变异系数等7个声音指标与绥德样区相应指标最为接近.相应的广义欧式距离为48.456,是所有样区广义欧式距离最小者.由此判定安塞检验样区的地貌类型应该为黄土丘陵沟壑区,这与实际情况相符,从而印证了此7项声音指标对地貌类型的区分能力.因此,可以根据样区的声音指标对样区的地貌类型进行推测,此方法有待在其它地貌区域进一步验证.
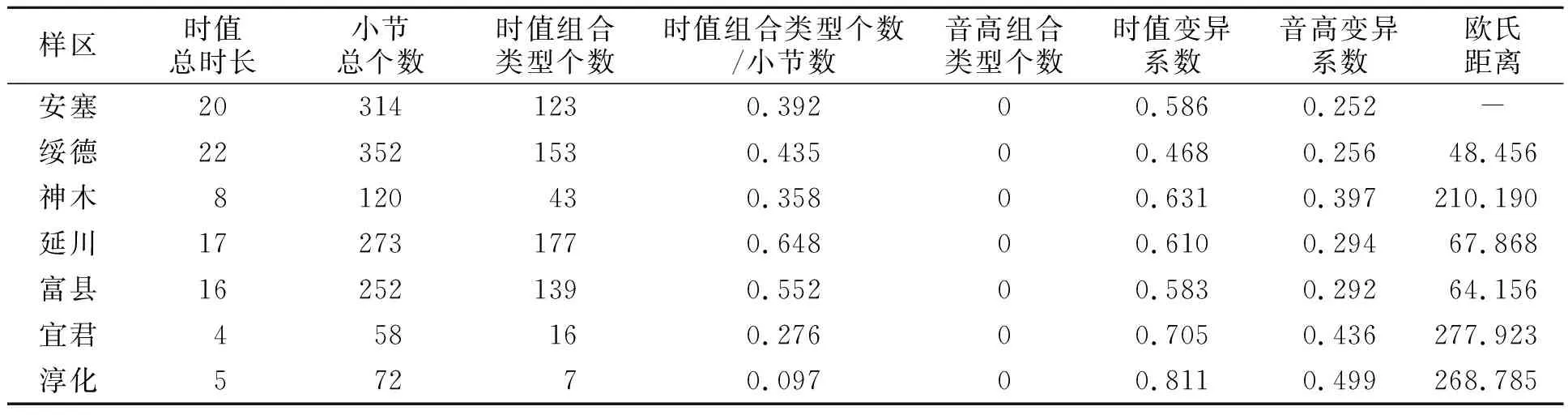
表6 样区声音指标统计表Tab.6 Statistical table of sound indexes
综上所述,样区沿分水线布设地形剖面线的声音指标可以直接进行地貌类型的区分.综合表6中的量化指标比单一的高程信息蕴涵更多的地形起伏、转折信息,可以从乐理角度整体刻画地貌类型.此外,该方法的量化指标多,指标之间相互关联,便于对地形剖面线进行整体和精细化分析;与坡度等地形因子存在强相关性,从而可以表征沿分水线布设地形剖面线处正地形的坡面情况,为水土流失的治理提供可靠信息支持.
3 结论
引入声音知识,将沿分水线布设地形剖面线上所提取的高程值映射为音高和时值.通过一系列声音指标对地形剖面线进行分析和描述,探究了不同黄土地貌类型与不同声音模式的关系,得到以下3点主要结论.
1) 可以利用声音的数据观察方法,对沿分水线布设的地形剖面线特征进行分析.该方法得出6个样区复杂程度由大到小依次为绥德、延川、富县、神木、淳化和宜君样区,对应声音指标的数值依次为505,450,391,163,79,74,由南向北表现为小-大-小的交错分布趋势,对应样区简单-复杂-简单的复杂程度分布.
2) 6个样区的声音模式与实际地貌类型存在明显的对应关系,声音指标的数值可以进行定量化描述.对于时值组合类型个数及其与小节数之比,宜君和淳化样区的最大值为16,0.276,对应节奏变化缓慢;而神木样区为43,0.358,对应节奏变化缓慢,但是较为多样;绥德、延川和富县样区的最小值为139,0.439,对应节奏变化快速,而且较为多样.
3) 6个样区的7个声音指标可以直接进行地貌类型的区分.安塞与绥德样区声音指标的广义欧式距离为48.456,是所有样区广义欧式距离最小者,同为黄土丘陵沟壑区,从而印证了7项声音指标对地貌类型的区分能力.综上所述,声音指标可以用来分析地形剖面线特征,进而充分借助声音表达信息的能力,深入挖掘沿分水线布设地形剖面线中蕴含的地学信息.
猜你喜欢
中国科技纵横(2022年17期)2022-10-25
文萃报·周五版(2022年24期)2022-06-21
戏剧之家(2021年18期)2021-11-14
小学生学习指导(低年级)(2021年9期)2021-10-14
高中生·青春励志(2019年3期)2019-04-12
学生导报·东方少年(2019年27期)2019-01-14
文艺生活·中旬刊(2016年11期)2016-12-13
东疆学刊(2015年3期)2015-12-23
读写算·小学低年级(2015年12期)2015-12-12
科技资讯(2014年36期)2015-03-30
