
基于调整方向感知的中文命名实体识别
2022-03-31 08:18陈伯琪
江苏师范大学学报(自然科学版) 2022年1期
陈伯琪, 陈 彬
(江苏师范大学 数学与统计学院,江苏 徐州 221116)
0 引言
命名实体识别(named entity recognition,NER)是自然语言处理的重要基础任务,是信息提取、问答系统、句法分析、机器翻译等自然语言处理任务的重要基础工具.基于深度学习的命名实体识别方法,在一定程度上克服了传统机器学习特征表达能力较弱和文本信息获取能力欠缺的问题,并运用神经网络的优势提升了特征提取的准确度和模型的学习能力,达到了更优的识别效果.Collobert等[1]利用多层感知器(multilayer perceptron,MLP)和卷积神经网络(convolutional neural networks,CNN)来避免使用特定的特征处理不同的序列标记任务,如词性和NER等.循环神经网络(recurrent neural network,RNN)有着很强的时序性,被广泛应用于自然语言处理任务中.目前,双向长短期记忆网络(bidirectional long short-term memory,BiLSTM)[2]是应用最广泛的RNN结构之一.由于BiLSTM在学习上下文表示方面的强大能力,大多数NER模型将其作为编码器[3-5].
Transformer编码器[6]采用全连接的自注意力结构对上下文进行建模,在语义特征提取、长距离特征捕获和综合特征提取等方面均优于RNN.由于Transformer具有更好的并行能力,因此被广泛应用于机器翻译、语言建模、情感分析和预训练模型等自然语言处理任务中.但Transformer使用的正弦位置嵌入可以获取距离信息,不能获取方向信息.同时,在使用Transformer的过程中,距离信息会在一定程度上丢失.然而,方向信息和距离信息在命名实体识别任务中都很重要,一个实体是连续的字跨度,对距离信息和方向信息的获取可以帮助某个字或者词更好地识别它附近的字或者词.为了使Transformer具有方向和距离感知能力,Yan 等[7]提出了一种改进相对位置编码的方法,该方法使用更少的参数,性能更优.为了提高基于Transformer的模型在中文命名实体识别任务中的性能,本文在Yan等[7]提出的TENER模型的基础上,结合方向感知和距离感知,提出一种基于调整函数动态调整方向感知的中文命名实体识别(Chinese named entity recognition based on adjusted direction-aware,C-ADA)模型,并进一步锐化注意力分布.通过与已有模型在MSRA[8]、Weibo[9]、Resume[10]3个中文NER数据集上对比, C-ADA模型效果更好.
1 相关模型
1.1 TENER模型
TENER模型[7]是基于Transformer编码器结合条件随机场构建的字符级和词级特征的命名实体识别模型,它利用相对位置编码,减少了参数数量,比基于BiLSTM的模型性能更好.通过改进注意力得分的计算方式,TENER模型可以区分不同的方向和距离,并结合方向感知、距离感知和非缩放的注意力,使得Transformer结构在NER任务上的性能大幅提升.
1.2 Transformer 编码器架构
Transformer编码器[6]由多个相同的基本层搭建而成,每一个基本层都由注意力层和前馈神经网络层两个子层组成,在两个子层中使用一次残差连接和标准化.将词向量输入到Transformer编码器中,经过编码器处理的结果输入到相对应的解码器中.Transformer是完全基于注意力机制的模型,编码器结构中大量使用多头注意力机制.缩放点积注意力是多头注意力机制的核心,输出公式为
Q,K,V=HWq,HWk,HWv,
其中:A(·)为注意力函数;s(·)为softmax函数;Q、K、V分别为查询向量矩阵、键向量矩阵和值向量矩阵;矩阵H∈Rl×d,l为序列长度,d为输入维度;Wq、Wk、Wv∈Rd×dk是3个可学习的矩阵;dk为超参数.
多头注意力是Transformer模型中的重要组件.在不同语义场景下,字语义向量之间的融合是多种多样的,因此,多头注意力机制提出在获取增强语义向量时采用不同的自注意力(self-attention)模块,在参数量总体不变的情况下,关注输入的不同部分,将查询、键、值3个参数进行多次拆分,并将各组拆分参数映射到不同子空间中计算注意力权重,然后输出多个向量的线性组合.多头注意力机制采用多组Wq、Wk、Wv,经过多次并行计算,来提高注意力机制的性能,计算公式为
Qi,Ki,Vi=HWq,i,HWk,i,HWv,i,
hi=A(Qi,Ki,Vi),
Hmulti(H)=(h1,h2,…,hn)Wo,
其中:hi为第i头注意力,i=1,2,…,n为(h1,h2,…,hn)的索引;Hmulti(·)为多头注意力函数;Wo∈Rd×d为可学习参数.多头注意力的输出[6]由前馈神经网络进行处理,公式为
NFF(x)=R(xW1+b1)W2+b2,
其中:NFF(·)为前馈神经网络函数;R(·)为Relu函数;W1∈Rd×df,W2∈Rdf×d,b1∈Rdf,b2∈Rd,df为超参数.
1.3 位置嵌入
为了解决自注意力无法捕捉语言顺序特征的问题,Vaswani等[6]提出使用不同频率正弦函数产生的位置嵌入,第t个位置嵌入表示为

其中:t为目标索引,j为上下文标记索引.
2 C-ADA 模型
2.1 调整方向感知
在方向感知过程中,不同位置的sinx和cosx只能在[-1,1]上进行周期性波动.但在实际问题中,实体的方向信息并不是完全不变的周期性波动.本文提出利用调整函数对方向感知过程中的周期性波动进行动态调整,使方向感知上的波动程度发生变化.同时,使用锐化参数m进一步锐化注意力.
利用函数1-|tanhx|对方向感知进行动态调整,公式为
Q,K,V=HWq,HWdk,HWv,
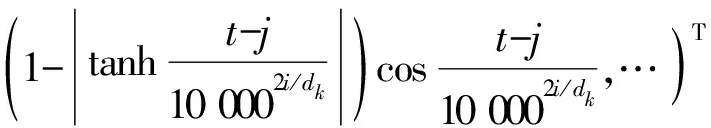
(1)
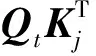
由于1-|tanhc0t|)sinc0t为奇函数,在偏移量为t时,前向相对位置编码和后向相对位置编码是相反的,因此Rt-j可以区分不同的方向和距离.调整函数1-|tanhc0t|,可使方向编码随着位置的改变产生波动幅度的变化.
性质1方向信息的集中性即尾部压缩性.

证由于
f(x)=1-|tanhx|

则
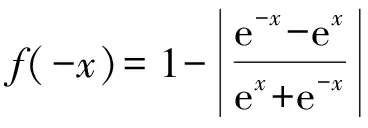
即f(x)为偶函数,且|f(x)|≤1=f(0).
当x∈(0,+∞)时,
f′(x)<0,
(2)
当x∈(-∞,0]时,
f′(x)>0,
(3)
故f(x)在x∈(0,+∞)上单调递减,在x∈(-∞,0]上单调递增,值域为(0,1].
记g(x)=f(x)sinx,由sinx为奇函数知g(x)为奇函数.由(2)、(3)及sinx的周期性知,当|x|→∞时,|g(x)|波动趋于0.f(x)、g(x)的图像如图1所示.调整函数f(x)使方向编码的波动程度在正方向和负方向均为下降趋势,同时,将方向编码的尾部取值压缩至接近0.当|x|=π时,g(x)的取值接近0.可见,模型获取的绝大部分方向信息集中在(-π,π).

图1 f(x)与g(x)的函数图像Fig.1 Function graph of f(x) and g(x)
2.2 条件随机场
考虑到标签之间的依赖性,在序列建模层上使用条件随机场(conditional random field,CRF).CRF是在给定随机变量序列的前提下,输出与输入变量序列相关联的一组随机变量序列的条件概率模型.中文命名实体识别任务可以简化为根据一组输入随机变量序列X={x1,x2,…,xm-1,xm}预测输出随机变量Y={y1,y2,…,ym-1,ym}的过程.条件随机场公式[11]为
其中:F(Y,X)=(f1(Y,X),f2(Y,X),…,fK(Y,X))T,表示全局特征向量;w=(w1,w2,…,wK)T为权重向量.
3 实验分析
3.1 标注策略与评价指标
命名实体识别又称为序列标注任务,常用的标注策略有BIO、BMES、BIOES 等.本文中MSRA、Weibo、Resume 3个数据集都采用BIOES标注策略,其中:B标签代表一个实体的开始,I标签代表一个实体的内部,E标签代表一个实体的结束,O标签代表一个非实体,S标签代表一个单独的词作为一个实体.评价模型的优劣采用精确率、召回率、F1得分表示[12],混淆矩阵如表1所示.

表1 混淆矩阵Tab.1 Confusion matrix
3.2 实验环境及实验参数
实验训练过程环境配置如表2所示.模型具体参数设置如表3所示.在实验中,锐化参数m经过多次调整.可以看出,与MSRA和Weibo数据集相比,Resume数据集的锐化参数更小,即注意力锐化程度更高.

表2 环境配置Tab.2 Environment configuration
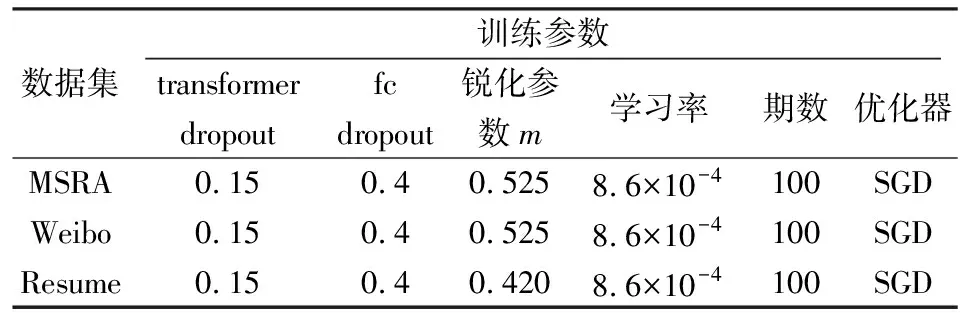
表3 模型参数Tab.3 Model parameters
3.3 模型结果对比

图2 C-ADA模型与TENER模型在MSRA数据集上的精确率和召回率Fig.2 Precision and recall rates between C-ADA and TENER on MSRA

图3 C-ADA模型与TENER模型在Weibo数据集上的精确率和召回率Fig.3 Precision and recall rates between C-ADA and TENER on Weibo
比较C-ADA模型与TENER模型在MSRA、Weibo和Resume 3个中文NER数据集上的训练效果(图2—图4),可以看出,本文提出的C-ADA模型在3个中文数据集上的精准率和召回率都比TENER模型有了一定提升,且精确率的提升更为显著.
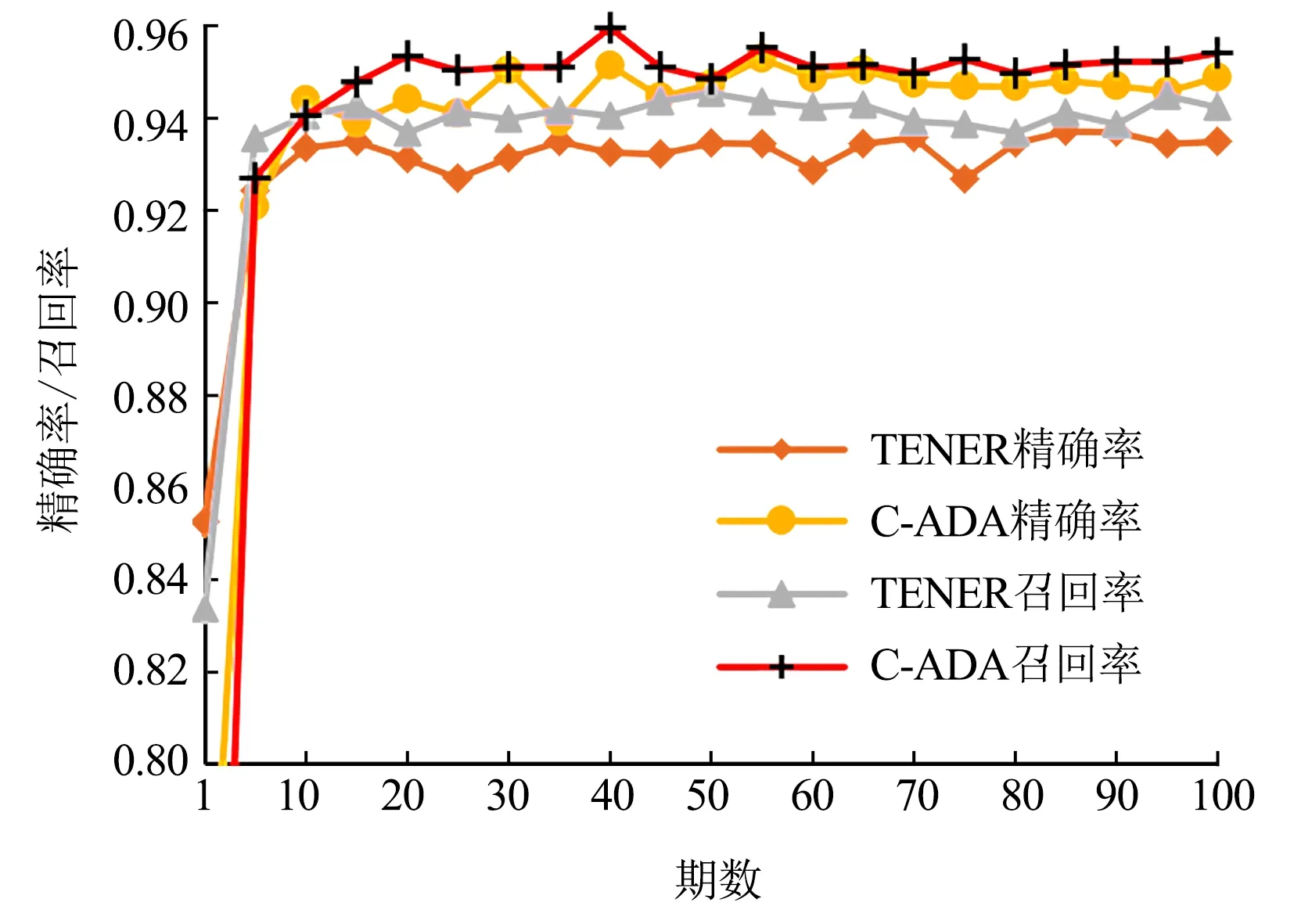
图4 C-ADA模型与TENER模型在Resume数据集上的精确率和召回率Fig.4 Precision and recall rates between C-ADA and TENER on Resume
通过与BiLSTM,ID-CNN、Transformer、TENER 4类模型在3个中文NER数据集上进行对比(表4)发现,本文提出的C-ADA模型的F1得分均最高.其原因在于调整函数对方向感知过程中的周期性波动进行动态调整,使模型对于方向的感知更加敏感.

表4 各模型在测试集上的F1得分Tab.4 F1 score of each model on the test set
4 总结
本文在Yan 等[7]提出的TENER模型基础上利用调整函数对方向感知进行了改进,通过调整函数使方向感知在不同的位置不仅保持了相对的波动程度,同时增加了整体上的变化趋势,使方向感知更加敏感.在命名实体识别任务中,具有整体变化趋势的方向感知能够更好地捕捉位置不同和实体多样性带来的方向变化.另外,本文在实验的基础上,利用参数m使得注意力更加锐化.在Weibo、Resume、MSRA 3个中文NER数据集上的实验结果表明,本文提出的C-ADA模型效果优于BiLSTM,ID-CNN、Transformer、TENER模型.不足之处在于,本文使用的锐化参数m对注意力的锐化作用仅在3个中文数据集上进行了验证.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
制造技术与机床(2017年7期)2018-01-19
传媒评论(2017年3期)2017-06-13
西安工程大学学报(2016年6期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
探测与控制学报(2015年4期)2015-12-15
