
一种基于两级缓存的高效时序数据库系统
2022-04-18 02:58郭亮亮彭甫镕
测试技术学报 2022年2期
郭亮亮,靳 燕,杨 博,彭甫镕
(1.山西省信息产业技术研究院有限公司,山西 太原 030006;2.山西大学 大数据科学与产业研究院,山西 太原 030006)
0 引 言
时间序列数据是一种很重要的数据类型,广泛存在于工业控制、金融分析和物联网等领域[1].对时间序列数据进行分析[2]可以发现数据潜在的结构和知识,形成对设备、网络、市场的监控与预警.近些年来,随着大数据时代的到来和工业物联网技术的蓬勃发展,时序数据的采集、存储、分析应用已经形成了一套完整的体系[3].时序数据存储作为时间序列分析的一个重要环节,写入速度、并发能力和存储效率是存储技术的几大重点问题.现有时序数据库系统在面对海量时序数据存储时也会体现出明显的不足之处,主要体现在存储速度慢和空间利用率较低,这两个方面也是衡量时序数据库性能的重要指标.在实际应用中通常会结合具体应用场景对现有时序数据库做进一步优化[4].
基于两级缓存的高效时序数据库系统通过对OpenTSDB[5]时序数据库系统的分析,对影响数据存储速度的因素进行了优化.通过对比OpenTSDB,Gorilla[6]等压缩算法的稳定性、适用性,选择Gorilla压缩算法提升OpenTSDB在空间利用率方面的不足.该系统创新性地加入了两级缓存机制,使得存储速率得到了极大的增强.此外,利用Socket[7]的Server/Client模式进行数据接收,可以实现多数据源的同时接入,提高了系统的并发性.在对数据查询做可视化处理后,最终在OpenTSDB的基础上形成一个写入速度快、空间利用率高、稳定性好的时序数据库系统.
1 相关工作
伴随着大量时间序列数据的采集与应用,工业领域普遍的做法是使用商业实时数据库软件,如OSIsoft PI[8],Wonderware Insql[9],GE IHistorian[10]等作为时序数据的存储和读取工具.随着大数据技术的发展,近年来也有一些基于HBase[11],MongoDB[12]等大数据平台的研究.目前使用较多的时序数据库有InfluxDB[13],OpenTSDB等,InfluxDB是一款使用Go语言开发的时序数据库,主要使用基于Google的Bigtable[14]架构的LSM tree[15]进行数据存储,也是最为流行的一种工业时序数据库.OpenTSDB是基于Hbase的分布式可伸缩时序数据库,具有良好的分布式存储优势,易于列扩展,是一款流行的开源时序数据库.时序数据库的使用弥补了关系型数据库在面对时间序列数据存储时在性能和稳定性方面的劣势,优化了存储结构,使得数据的插入和查询更加便捷.然而,通过对现有时序数据库的对比发现,当前所使用的时序数据库在单机上的数据写入速度停留在几万条/s的级别.为此,本文通过深入研究OpenTSDB的数据通讯原理和存储方式,提出了一种两级缓存的方案,对写入速度进行优化.同时,引入时序数据压缩算法,在数据存储效率方面进一步提高性能.
2 OpenTSDB的并发访问与压缩分析
OpenTSDB的关键字包含metric(测度)、timestamp(时间戳)、value(值)、tag(标签),其写入过程是将各关键字的值转换成一条行记录Rowkey(包含metric,tag和时间分区),调用Hbase的写入接口将Rowkey当作行键值,时间偏移当作列名,时序值当作数据值写入数据库.OpenTSDB在启动时首先需要加载配置文件,之后初始化Netty对象生成一个HTTP服务,用于接收HTTP请求,最后初始化TSDB对象进行数据写入.
在面对海量数据时,OpenTSDB有自己的压缩策略:将Rowkey相同的一行多列的数据合并为一行一列数据.具体做法是将同一个Rowkey对应的所有列(时间偏移)和所有值(时间序列值)分别合并为一个数组进行存储.因为所有时间偏移的长度一样,合并后的数组长度除以单个时间偏移的长度即可对合并后数据进行切分,获得单个时间偏移.对合并后的数据值做同样操作也可以得到相应的元素.通过将一行多列合并为一行一列,可以有效减少Rowkey的数量,提高数据的存储效率.
OpenTSDB在构建Rowkey的时候并不是直接使用原始值,而是将metric, timestamp, tagk, tagv分别用了一个3 B的uid做了替代,可以减少Rowkey的存储空间.所以这里需要一个表来做uid和真实值之间的转换,这个表就是tsdb-uid表.uid表中有两个family,分别是uid-name的映射(name family)和name-uid的映射(uid family).另外还有一行特殊的数据,就是uid已分配情况记录表.tsdb-uid表会在执行OpenTSDB创建表的脚本时创建.
通过对以上OpenTSDB的写入和压缩方案的介绍可以看出,OpenTSDB还有很多需要进行优化的方面,其采用基于Netty[16]的Web服务,会导致数据传输性能下降,同时OpenTSDB为保证线程安全,面对数据高速写入时异步机制会产生高度频繁的数据压栈操作,导致性能下降.在压缩算法方面,OpenTSDB自带的压缩算法只是将源数据进行了简单的合并操作,相比Gorilla压缩算法将数据转换为字节码进行存储,OpenTSDB的压缩算法在压缩效率上有明显的不足,所以,会导致其空间利用率较低.在面对海量时序数据的存储时,针对OpenTSDB暴露出的在吞吐量和空间利用率方面的不足,本文设计了基于两级缓存优化与Gorilla压缩算法的高效数据库系统.
3 基于两级缓存的写入速度优化
为了提高写入效率和系统稳定性,提出采用两级缓存机制进行数据存储优化.针对大量数据源并发写入对服务器资源占用问题,提出基于消息网关的一级数据缓存机制.通过消息网关保证系统接受大量数据源传来的数据之前对数据进行临时缓冲,减少网络系统I/O数量,提高系统通讯效率.第二级缓存用于写入数据的批处理,在执行数据写入前建立缓存区,当缓存区的数据达到一定量的时候进行一次批量写入,以此节省因频繁执行写入操作带来的磁盘索引消耗.
一级缓存建立在数据采集与时序数据库之间,在做数据缓存的同时可以将数据源传来的数据做格式转化,将采用不同协议采集到的数据转化为时序数据库写入接口所接受的格式.一级缓存使用Flume[17]作为缓存器,Flume是一个提供缓存机制的日志处理工具,用于数据采集,并对数据做简单处理后转发到指定接收端.Flume的每一个处理单元为一个Agent,其中包含数据源Source、缓存区Channel和输出Sink.Source将单个或多个事件推入缓存区Channel中供Sink对数据做持久化处理,缓存区Channel大小可以通过配置文件进行设定,Channel中的数据会保存到Sink完成对数据持久化操作,并将数据以固定的格式传输到该系统的写入接口.一级缓存的工作流程如图1 所示.
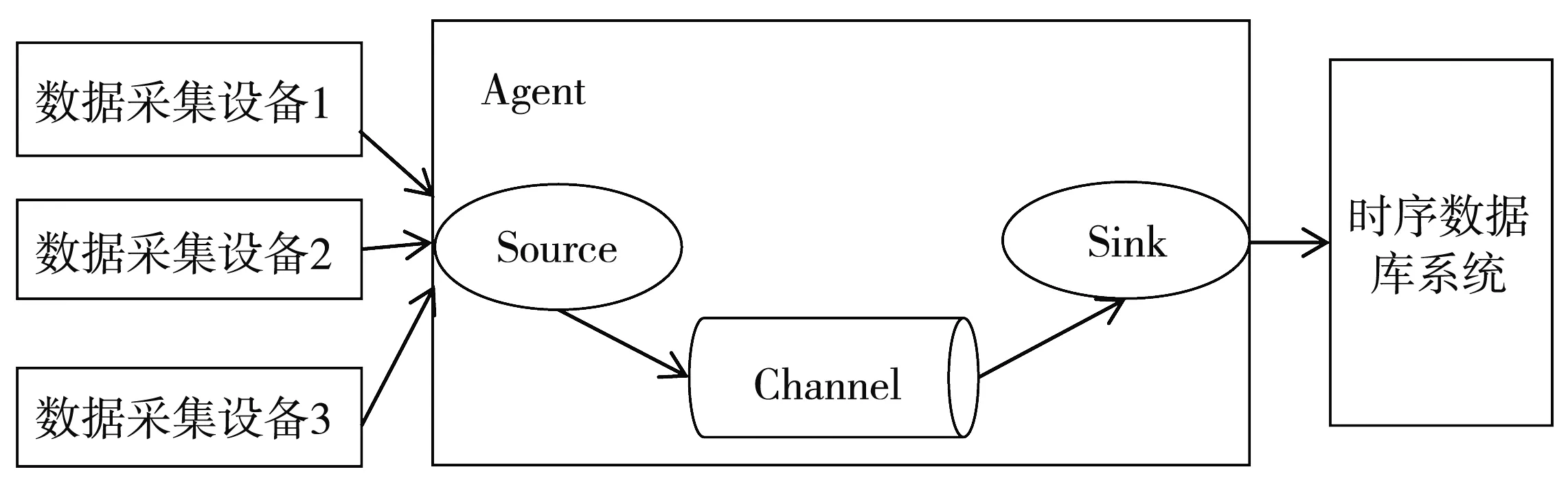
图1 一级缓存工作流程图
在引入基于消息网关的数据缓存机制以后,可以避免收集到的所有数据一次性涌入数据库,OpenTSDB原有的Netty服务会因为异步调用产生的堆栈和压栈操作导致高频次的缓存,极其浪费CPU资源.为此,本文提出建立TCP直连机制,建立消费者-生产者模式的队列机制,以此来最大程度地利用CPU和内存资源.
二级缓存是在时序数据库内部,在数据接收与写入Hbase之间.当有数据需要写入Hbase时,若频繁调用写入接口则会产生大量的磁盘索引消耗[18].本文提出在调用Hbase写入接口之前设立缓存区,可以使数据进行批量写入,当数据条数不满足设定的阈值时,则会将数据存入缓存区,等到缓存区内数据达到一定条数时,会进行批量写入.若数据量较小无法达到缓存区阈值,则根据数据停留时间进行强制性写入,以确保时序数据处理时的时效性.二级缓存工作流程如图2 所示.

图2 二级缓存工作流程图
4 基于Gorilla的扇区压缩算法引入
OpenTSDB当前支持HBase作为其主要存储后端,为了利用HBase的排序和区域分布,所有OpenTSDB数据点都存储在一个表中(默认情况下表名为tsdb),所有值都存储在t列族中.OpenTSDB将metric,tags,timestamp属于同一时间段内的所有数据放到一个扇区中.传统OpenTSDB只是根据metric将所有同一扇区中的数据合并存放,没有进行任何压缩,导致数据写入后的压缩比在4∶1左右.为此,针对时序数据的特点,对时序数据提出压缩后存储.
Gorilla压缩算法使用单个字符串键识别时间序列,并依赖更高级别的工具来提取和识别时间序列的元数据.算法的主要作用是对8 B的double类型数据进行压缩,转换为字节流,按照一定的格式不断追加.Gorilla压缩算法采用依据时间序列中数据点的压缩策略,使得其压缩过程中不必对整个时间序列进行压缩,可以节约大量的压缩成本.Gorilla压缩算法将时间序列的每个数据点表示为一对64 b的值,代表时间戳和当时的值.时间戳和值分别使用关于时间序列之前值的信息进行差异性存储和压缩.Gorilla压缩算法将这个数据流压缩成按时间划分的块,存储在一个2 b 的报头中,值以7位存储,总大小只有9 b.然后用一个2 b头进行编码,编码为有11个前导零、1个有意义的位和实际值.总共以14 b存储.相比于OpenTSDB的压缩算法只改变数据格式进行存储,Gorilla压缩算法采用字节码的压缩方式可以实现更高的压缩效率.Gorilla压缩算法的压缩流程如图3 所示.其中Gorilla压缩器的原理如图4 所示.
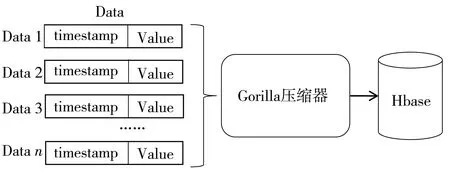
图3 Gorilla压缩算法压缩流程
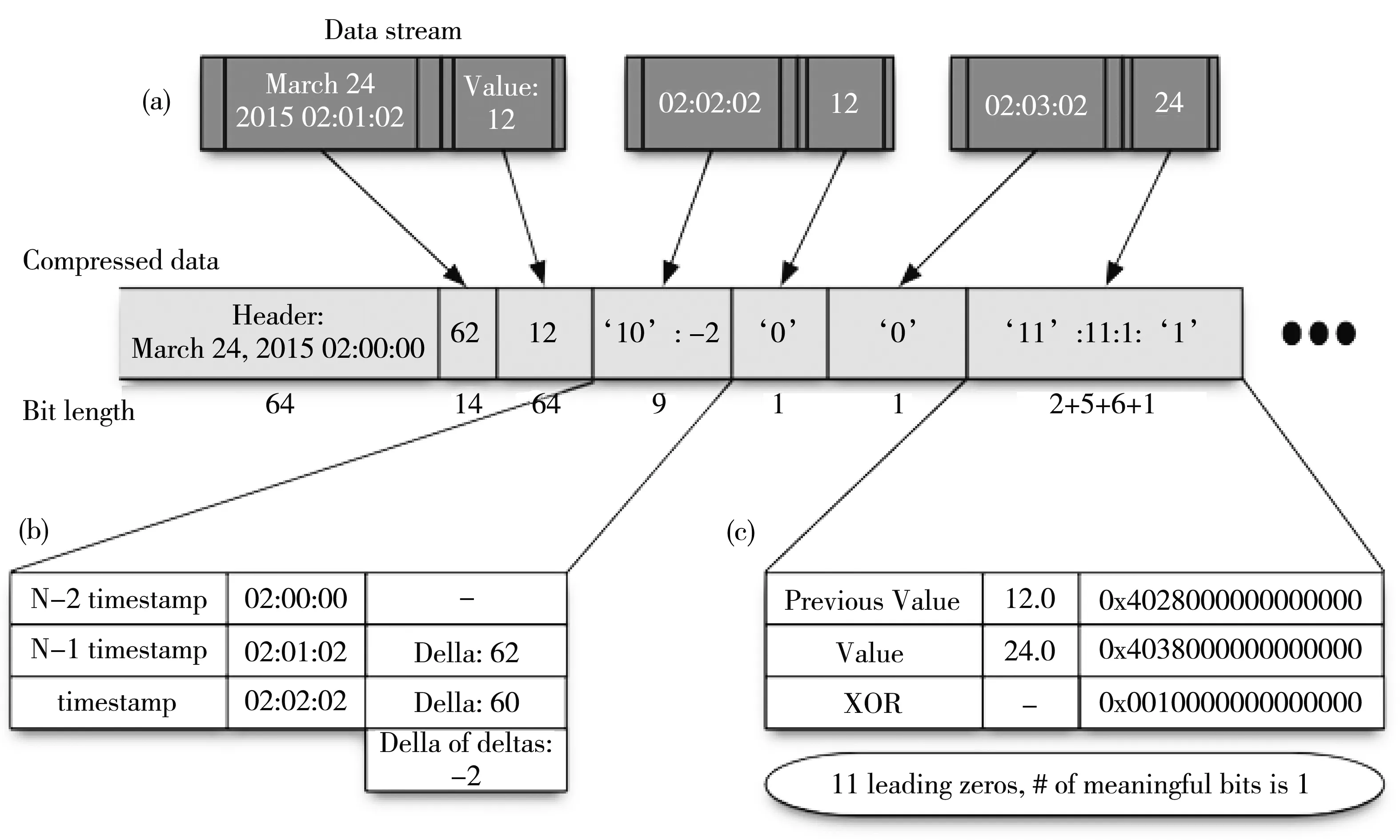
图4 Gorilla压缩器原理[19]
为了在基于两级缓存的高效时序数据库系统中引入Gorilla压缩机制,将同一扇区的数据进行合并,使用Gorilla进行压缩再写入HBase.为区分Gorilla压缩后的数据与未压缩数据,在OpenTSDB的Quantifier中加入标志信息.为了让加入压缩机制的OpenTSDB能够兼容原有数据格式,在SaltScanner类子类ScannerCB的call回调函数中对返回的块数据进行解压替换处理.先判断Quantifier中是否含有Gorilla的压缩标志,并根据压缩情况采用Gorilla算法进行解压,将解压后的数据重新返回到ScannerCB子类的call回调函数中,以此实现对查询结果的解压.加入Gorilla压缩算法后的OpenTSDB不仅提高了存储效率,还完全兼容原有的写入与查询方法.
5 系统测试
实验对原OpenTSDB的写入速度做了测试,并与改进后的时序数据库系统的写入速度进行对比测试.实验所用设备配置信息为:主频:2.20 GHz,处理器:i7-8750H,内存16.00GB,硬盘:SSD固态硬盘.
5.1 单机环境写入速度
为验证本文所提出的时序数据库系统在写入速度方面的改进效果,对主要改进步骤对写入速度的影响进行实验测试.实验设置生成20个测试文件,其中每个文件中包含200万条数据.写入过程中先根据线程个数将数据读入内存,之后进行对应线程的并发写入.原始OpenTSDB的写入速度和每一步优化后的时序数据库系统的写入速度如图5 所示.
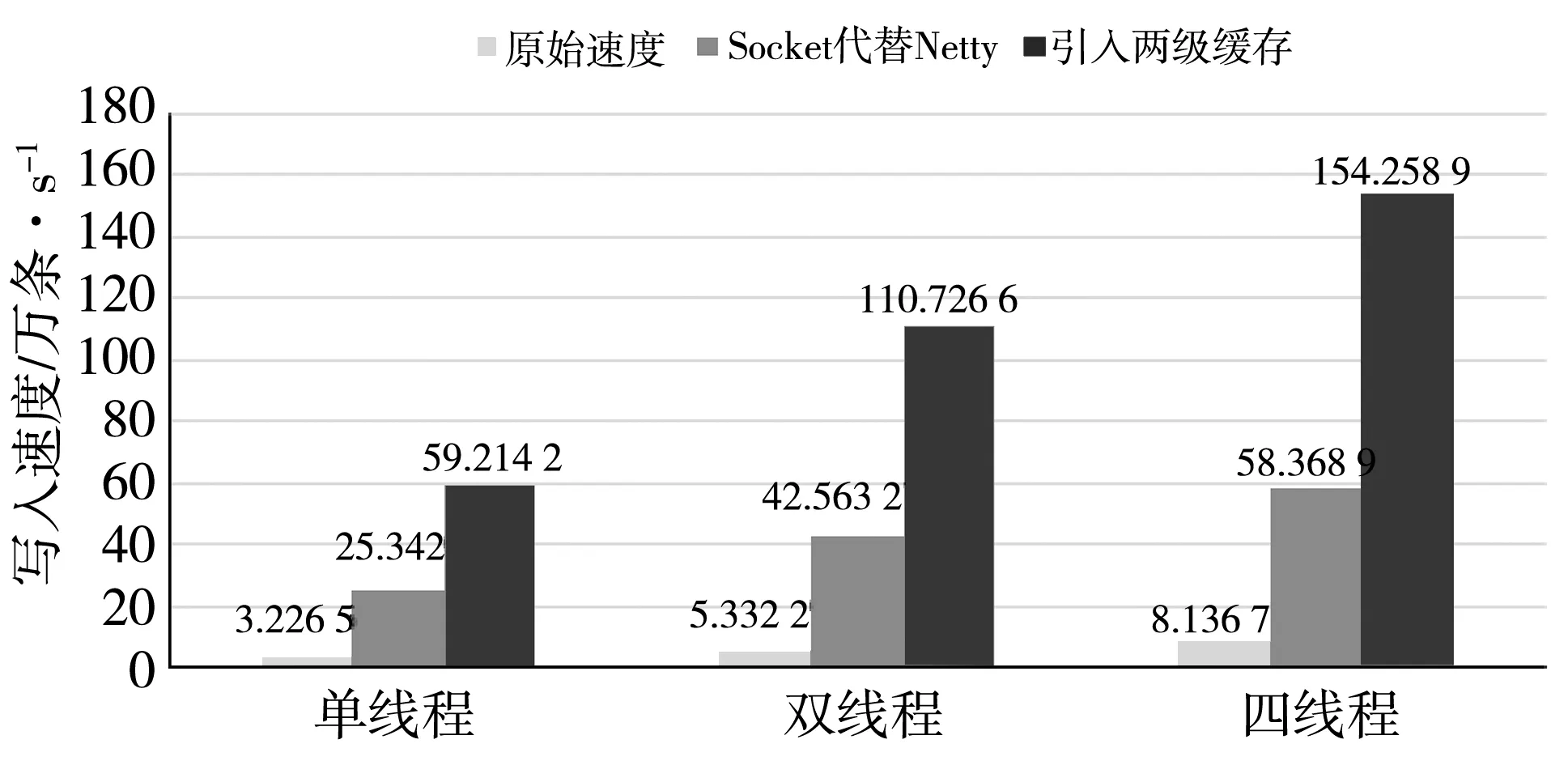
图5 OpenTSDB写入速度对比
通过实验对比测试可以看出,相比于OpenTSDB的写入速度,建立两级缓存机制的数据写入速度增加了近20倍,这是因为在面对大量数据时,该系统中特有的二级缓存机制对数据进行了批量写入,相比OpenTSDB,该系统对Hbase的写入接口调用次数更少,节约了大量的系统资源,同时将原来基于Netty的HTTP服务改为了基于Socket的TCP服务也会节约大量的系统资源,达到提高写入速度的目的[20].
5.2 压缩比分析
OpenTSDB利用一种特殊的表结构作为索引,将同一metric的数据按时间戳排列进行合并存储,压缩策略的核心是数据合并,其压缩比在4:1左右.在引入Gorilla压缩算法后,该系统的压缩比达到了接近25∶1,Gorilla压缩算法使用的策略是将原数据转换为字节码进行存储,可以节省大量的存储空间,在数据查询时只需要将原字节码转换为相应的数据即可.
压缩比测试一共进行了10轮,首先生成一批数据,记录数据文件的大小为a(MB),再记录未写入数据前数据库表结构文件的大小b(MB)和写入数据以后数据库表结构文件的大小c(MB),设压缩比为φ,则压缩比
为保证写入环境一致,在每一次压缩比测试过程中先对数据库表做清空,所以b为常数,经测试b=0.002 507(MB).具体测试结果如表1 所示.
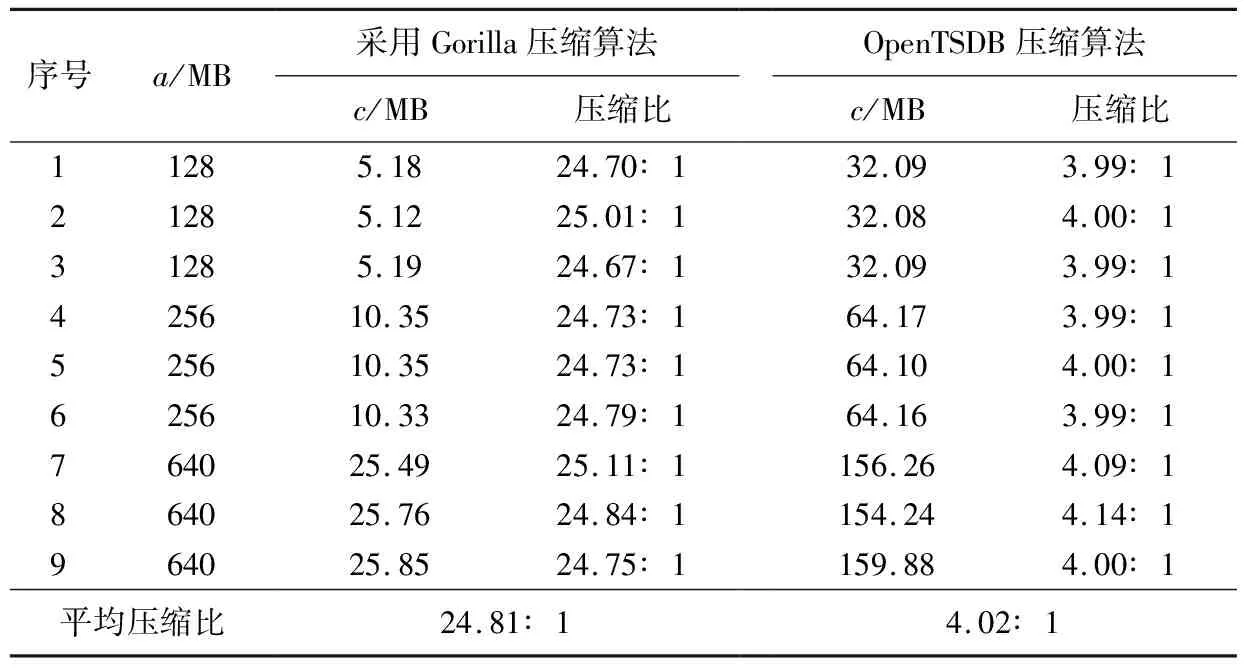
表1 压缩比测试结果表
引入Gorilla压缩算法后,在该系统的第二级缓存中,系统会对接收到的数据先打包为数据块,当数据块的个数达到一定阈值时进行一次批量写入,这样就确保了数据写入Hbase的效率,使得调用Hbase写入接口的次数减少,节约因频繁调用写入接口产生的大量的磁盘索引时间,在节约了系统资源的同时还会提高系统稳定性.
6 结 论
本文通过对OpenTSDB的分析和研究,实现了一种基于两级缓存的高速时序数据库系统.该系统应用于数据源和Hbase之间,实现了时序数据的高性能写入和存储,其两级缓存机制有效地解决了当大量数据同时进行存储时数据库系统的效率问题,引入的Gorilla压缩算法解决了Hbase在数据存储上的空间消耗量大的问题,同时数据的批量写入也解决了OpenTSDB在数据存储时频繁调用Hbase写入接口造成的时间和系统资源损耗问题.该系统的使用极大地提高了时序数据存储的稳定性和并发性,为解决工业时序数据的存储和分析提供了一种新的可靠的方法.
猜你喜欢
内燃机学报(2022年1期)2022-01-25
汽车与运动(2021年11期)2021-03-22
电脑爱好者(2018年14期)2018-08-05
电子技术与软件工程(2016年22期)2016-12-26
汽车之友(2016年21期)2016-11-08
电脑知识与技术(2016年16期)2016-07-22
科教导刊·电子版(2016年18期)2016-07-18
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
科技视界(2016年3期)2016-02-26
