
基于K-Means算法的配电网负荷和拓扑等效方法
2022-04-22 06:25杨金东李文
电力电容器与无功补偿 2022年2期
杨金东,李文
(1.云南电网有限责任公司电力科学研究院,昆明 650217;2.云南电网有限责任公司临沧供电局,云南 临沧 677000)
0 引言
为了对电能质量问题突出的农村电网进行治理和改造,必须建立配电网的数学模型来计算、分析配电网的潮流[1-5]。而在建立配电网数学模型的过程中,配电网系统往往存在线路拓扑复杂、用电负荷分散不集中的问题[6-8]。通过对配电网系统中的负荷和拓扑进行等效,在一定程度上简化配电网的数学模型[9-11],可以有效地解决配电网分析计算困难的问题[12]。
在负荷等效时,需要将负荷聚类进行分析,即利用负荷之间的相似度,对用户负荷进行分区聚类,进而有效识别不同负荷的用电规律和负荷特性[13-14]。文献[15]提出了采用DBSCAN算法、模糊均值算法(Fuzzyc-means algorithm,FCM)等进行电力负荷曲线聚类的方法。文献[16]提出了采用K-Means算法应用于电价划分与制定、负荷预测、负荷模型建立、电能质量检测等多种应用场合的方法,但对K-Means算法应用于配电网简化的研究还不完善。
在拓扑等效时,文献[17]提出了一种简化的配电网模型化方法,减少节点数量,且将配电线路和配变统一作为一种耗散元件考虑。但这难以准确计算出配电线沿线各处的电压降落和潮流分布。文献[18]采用了将一条馈线上的负荷看作是在线路上均匀分布的简化处理方法,建立了负荷均匀分布模型,从而得出了沿线的电压降落和线损的近似结果,但是当线路上的负荷分布不均匀时,负荷均匀分布模型会带来较大的误差。文献[19]提出了几种考虑负荷沿线分布的简化模型,在这些模型中,将一条线路上的所有负荷用一个等效负荷来表示,但是,求解时仍须确切地知道各个负荷(即配电变压器供出的负荷)的值。而实际上由于缺乏量测点,这些数据一般是难于获得的。
本文提出一种基于K-Means算法的配电网负荷和拓扑等效,利用台区拓扑和台区内监测数据,对配电网中的负荷和拓扑进行等效,从而实现配电网数学模型的简化。首先,通过地理信息GIS系统中的台区线路的拓扑结构,结合计量自动化系统中的负荷电压、容量等数据,根据电压相似、距离相近等效原则(下称:压、距等效原则)对台区内的用户进行划区、聚类;其次,根据等效负荷的容量分布与6种台区典型等效拓扑结构比对,进一步确定该台区的拓扑等效结构类型,完成配电网数学模型的简化;最后,给出了云南省某一台区的案例分析,并验证了所提配电网负荷和拓扑等效方法的正确性。
1 配电网负荷和拓扑等效方法
1.1 原理介绍
1.1.1 简化原理
配电网简化分为两个阶段:负荷等效和拓扑等效,简化原理见图1。首先通过K-Means算法对图1(a)中台区用户进行分区,依据压、距等效原则将符合条件的负荷聚类,完成负荷等效。接下来,利用统计学知识分别计算出各个分区的负荷容量,根据负荷容量分布结果,与台区典型拓扑数据库进行比对后,确定拓扑等效结构并完成配电网的简化,配电网的简化结果如图1(b)所示。
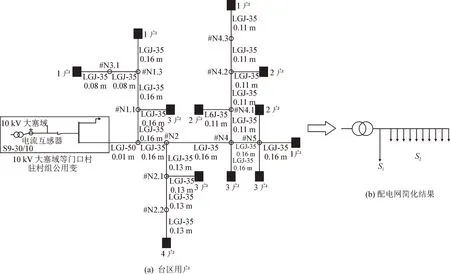
图1 配电网简化原理图Fig.1 Simplified schematic diagram of distribution network
1.1.2 K-Means算法
K-Means算法是最常用的一种聚类算法。算法的输入为一个样本集(或者称为点集),通过该算法可以将样本进行划分聚类,将具有相似特征的样本聚为一类[20-22],算法原理见图2。
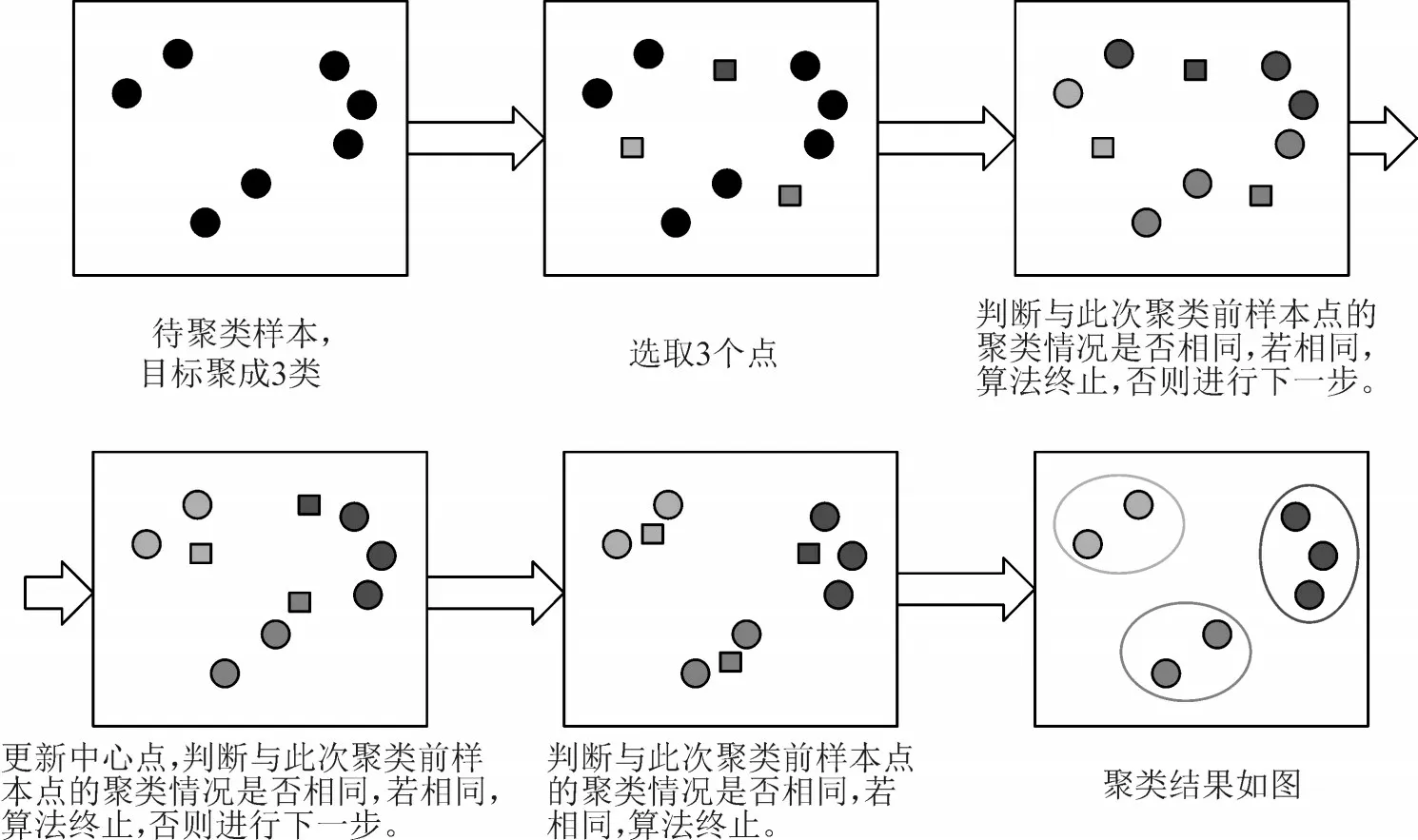
图2 K-Means算法原理图Fig.2 Principle diagram of K-Means algorithm
假设需将待聚类样本分为3类,即K=3;随机选取3个聚类点,或称为质心,针对样本里的每个点,分别计算其与3个质点的距离,分别将这些样本点分配到最近质心代表的簇中。一次迭代结束之后,针对每个簇类,重新计算中心点,然后针对每个点,重新寻找距离自己最近的中心点。这个过程将不断重复直到满足某个终止条件。
终止条件可以是以下任何一个[23-25]:
1)没有(或最小数目)对象被重新分配给不同的聚类。
2)没有(或最小数目)聚类中心再发生变化。
3)误差平方和最小。
1.2 负荷等效方法
配电网简化中的负荷等效流程见图3。
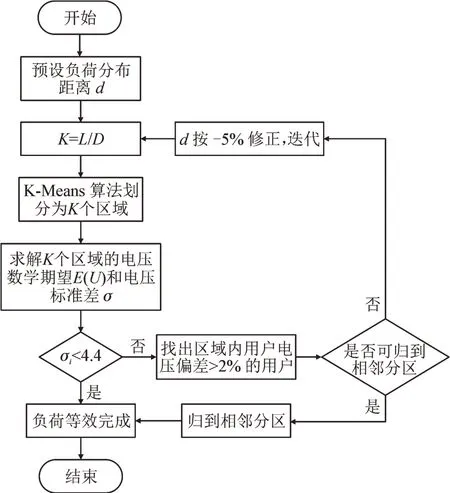
图3 负荷等效方法Fig.3 Load equivalent method
算法流程如下:
Step 1:根据台区实际杆塔间的平均距离数据,预设一个负荷分布距离值d,结合台变出口至线路最远端距离L,确定K值,得到K-Means算法的负荷划分区域个数K;台区所有用户负荷形成样本集合D,D={o1,o2,...,oN},N代表用户个数。
Step 2:从所有用户负荷样本集合D中随机选择K个用户负荷样本作为K-Means算法初始的K个中心点mj(j=1,2,...K)。
Step 3:计算样本oi(i=1,2,…,N)到各个中心点m(jj=1,2,...K)的距离,通过o对应i最小的lij,确定oi分到那个簇内,此时更新聚类划分簇C j=C j⋃{oi},j=1,2,…,K。
Step 4:样本集合内所有用户负荷完成聚类划分簇,形成了划分区域的样本集合,C={C1,C2,...,C k},针对已划分的K个区域样本集合C,计算分区后的平方误差SSE(sum of squared error),
Step 5:K-Means算法进行启发式迭代计算,迭代次数为M,m=1,2,...,M,对Cj(j=1,2,...,K)中所有的样本点重新计算新的中心点,并重新进行聚类划分簇,经过M次迭代后得到分区的最小化平方误差SSE,输出更新的划分区域的样本集合C={C1,C2,...,C k}。
Step 6:根据电压相似和距离相近原则,对所划分区域进行评判,对不符合压、距等效原则的分区,负荷分布距离值d按照-5%修正后,再次迭代,直到所有分区均符合要求,迭代结束。
电压相似和距离相近原则是为确保分区的准确性和科学性所提出的负荷分区的评判标准。在满足压、距等效原则的基础上,划分的区域才被允许成立。
电压相似原则为:K-Means分区完成后,根据式(2)-(3)计算各个区域的电压数学期望值和电压标准差,若电压标准差,则该区域可以直接等效,否则,利用距离相近原则等效,负荷等效模型见图4。
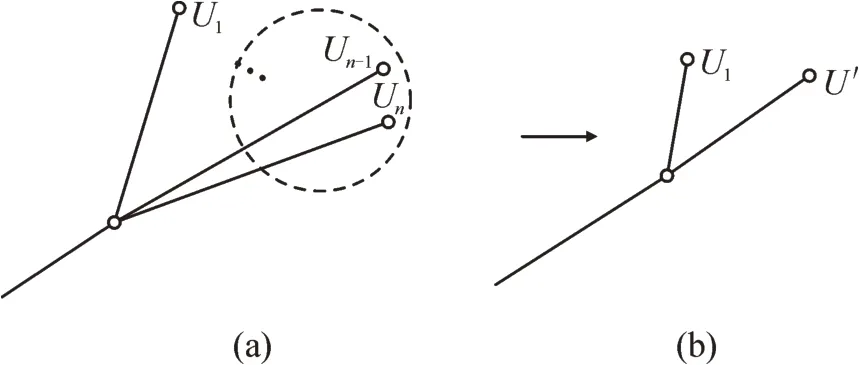
图4 负荷等效模型Fig.4 Load equivalent model
距离相近原则为:在电压标准差σ>4.4,不能按照电压相似原则等效的区域,继续计算该区域内各个用户的电压偏差,找出电压偏差ΔU%>2%的用户,判断其电压偏差是否在相邻区域(直径90 m内)允许范围,再根据电压相似原则完成负荷分区。

如图4(a)所示,某分区内n个负荷的电压分别为U1、U2、…、Un,该区域内的电压标准差σ>4.4,则进一步分别计算每个负荷的电压偏差为
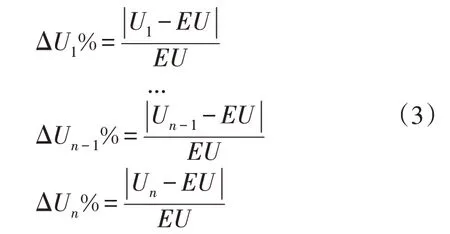
假设ΔU1%>2%,则U2、…、Un等负荷可以根据电压相似原则等效为一个负荷,U1则根据距离相近原则与相邻区域进行适配,并划分到其他区域的,最终等效结果如图4(b)所示。
1.3 拓扑等效方法
在完成负荷等效建模后,需要进行拓扑的等效模型建立,在拓扑模型建立上,需要同时兼顾计算实现的难度和精确度[26-27]。精确的电压损耗模型需要较大的计算量和一定的理论基础,并不适合现场运行人员使用,过于粗略的模型在计算精度上又难有保证。
进行负荷等效后,将负荷沿线分布划分为负荷沿线均匀分布、负荷沿线递增分布、负荷沿线递减分布、递增锯齿状分布、递减锯齿状分布以及梯形分布这6种情况。
负荷沿线分布的模型中,把所不需要研究的首端其他线路合并为首端负荷,定义为S1,并且S1与变压器间的线路阻抗忽略不计;要研究的线路上的负荷定义为S2。S2按负荷均匀、递增或递减分布,递增锯齿状分布、递减锯齿状分布以及梯形分布进行处理,为理论计算方便,负荷分布按公差d进行等差分布处理。在低压配电网中,对地电纳效应不明显。在计算中忽略线路和变压器等效模型中的对地支路。变压器等效为串联的电阻和电抗,具体数值由给定的变压器参数求得。
台区负荷拓扑等效模型见图5。
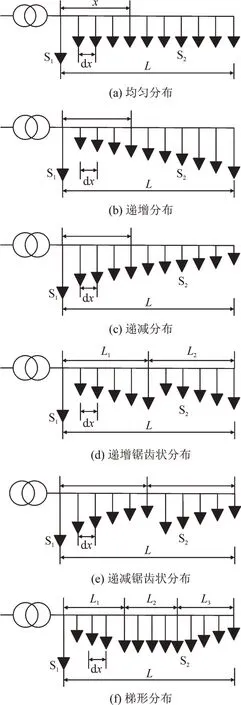
图5 台区负荷模型Fig.5 Platform load model
为计算方便,这里给出6种台区拓扑等效模型的电压降落计算公式,其中a=2I/L,代表电流随线路改变的速率:
负荷沿线均匀分布,电压降落为
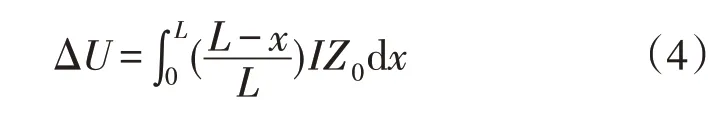
负荷递减分布,电压降落为
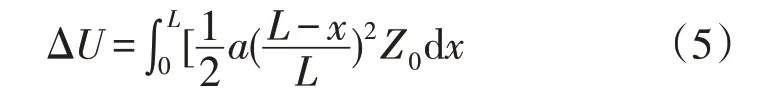
负荷递增分布,电压降落为
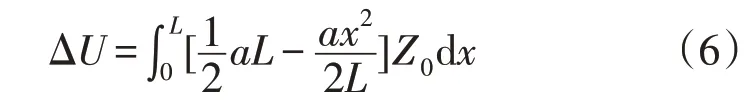
负荷递增锯齿状分布,电压降落为
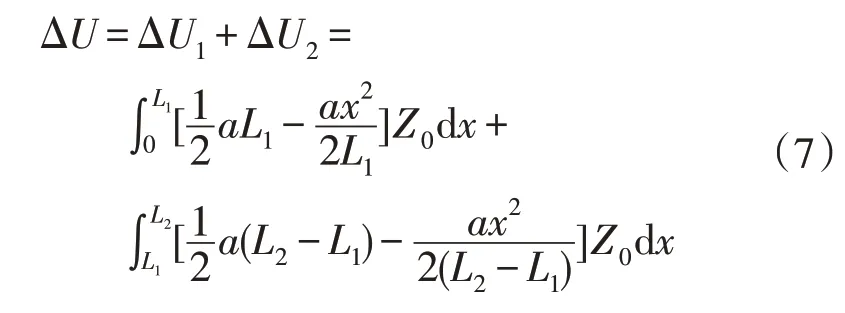
负荷递减锯齿状分布,电压降落为
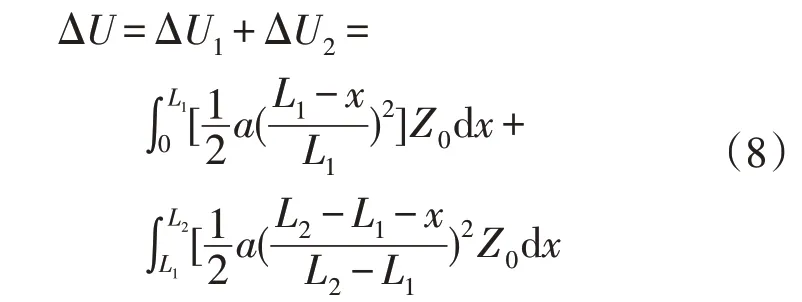
负荷梯形分布,电压降落为
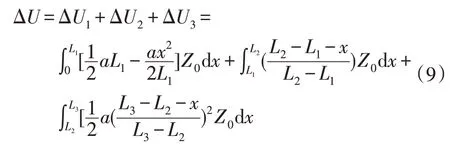
2 实例验证
本节给出云南省某10 kV配电台区的配电网负荷和拓扑等效实例,该配电台区的线路拓扑图见图6。
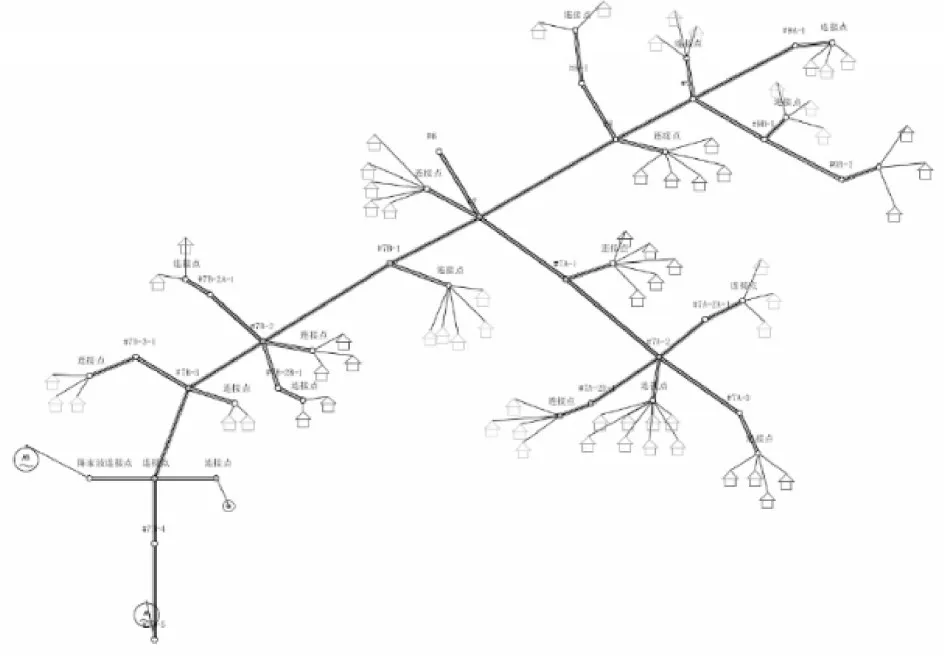
图6 云南省某10 kV配电台区拓扑Fig.6 Topology of a 10k V distribution station area in Yunnan Province
该台区配电变压器容量为50 kVA,线路主干线路376 m,主线路杆塔共9根,杆塔间距为47 m,共接入用户共计67户。
通过地理信息GIS系统中的得到台区线路的拓扑结构,结合计量自动化系统中的负荷电压、容量数据,利用本文提出的压、距等效原则对台区内的用户进行划区、聚类,再根据等效负荷的容量分布与上文所提6种台区典型等效拓扑结构比对,最终确定了该台区的拓扑等效结构类型,最终该配电网台区的负荷和拓扑等效结果见图7。

图7 配电网负荷和拓扑等效结果Fig.7 Equivalent result of load and topology of distribution network
表1为7个分区的电压数学期望E(U)和电压标准差σ计算结果。
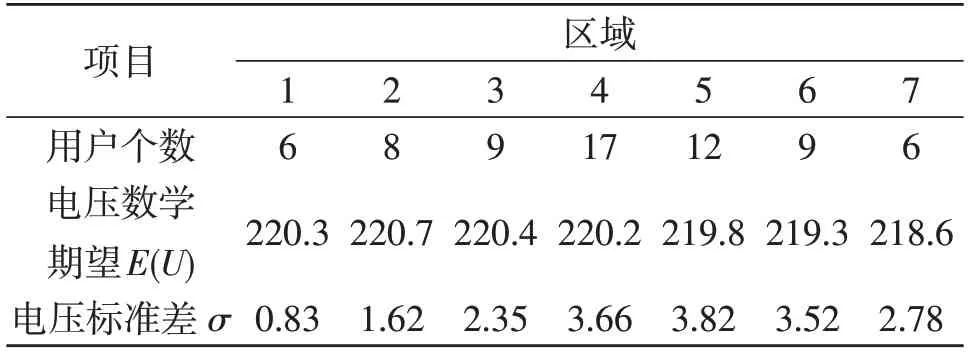
表1 7个分区的电压数学期望E(U)和电压标准差σ计算结果Table 1 Calculation results of voltage mathematical expectation E(U)and voltage standard deviationσfor 7 divisions
为验证配电网负荷和拓扑等效结果的正确性,结合表1中的电压数据,对每个负荷分区的电压指标(电压标准差、电压偏差)进行测算核验。
在负荷等效时,由于主干线路376 m,主线路杆塔共9根,杆塔间距为47 m,经综合考虑后预将数据分为7组,随机选取7个用户作为初始的聚类中心,最终负荷等效结果见图8。
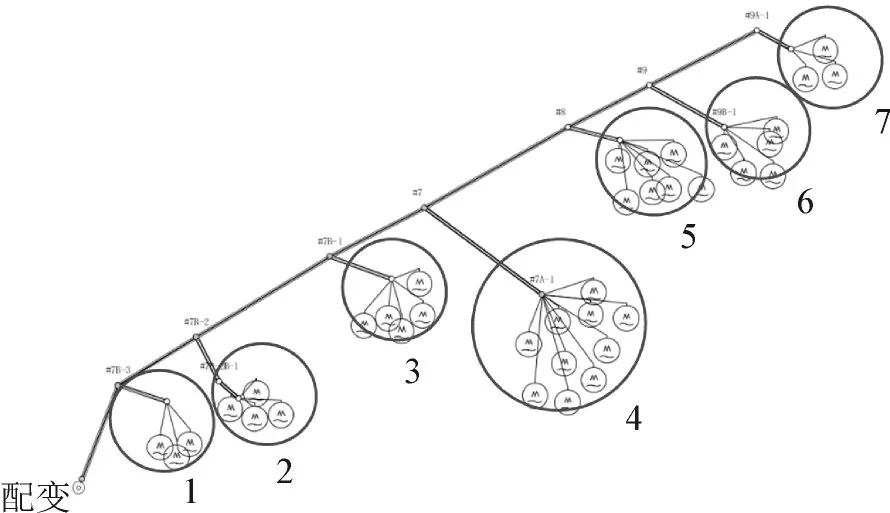
图8 负荷等效结果Fig.8 Equivalent result of load
分别求取7个区域的电压数学期望E(U)和电压标准差σ,计算结果见表1。再计算出所有等效区域内各用户电压情况,其中区域1内各用户电压偏差情况见表2。
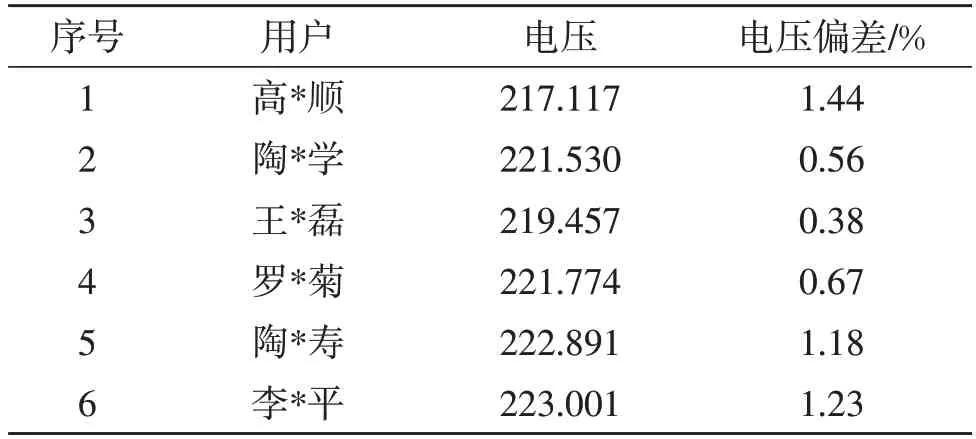
表2 区域1各用户电压偏差情况Table 2 Voltage deviation of each user in area 1
由表1、表2中数据可以看出,划分的7个区域内,电压标准差σ<4.4,区域内用户的电压偏差均<2%,所以K-Means划区聚类算法结果合理。
通过负荷等效,以及计算出负荷容量分布,负荷沿线负荷分布近似为梯形分布,拓扑等效模型正确。
3 结语
本文基于台区拓扑和台区内有限电压监测数据,提出了一种基于K-Means算法的配电网负荷和拓扑等效方法,通过理论分析和应用实例得到结论如下:
1)基于K-Means算法的配电网负荷和拓扑等效方法所需数据来源于地理信息GIS系统和计量自动化系统,数据来源可靠且获取方式较为方便。
2)相较于其他配电网等效方法,本文所提方法仅利用台区拓扑和台区监测数据即可实现对配电网中的负荷和拓扑的等效,实现方式简单易行。
3)提出利用电压相似和距离相近原则对所划分区域进行评判和修正,保证了负荷分区的准确性和科学性。
猜你喜欢
大众科学(2022年5期)2022-05-18
科学导报(2022年17期)2022-04-02
环球时报(2022-03-29)2022-03-29
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中国电气工程学报(2019年25期)2019-09-10
科技风(2018年20期)2018-10-21
科学与财富(2018年14期)2018-06-11
电子技术与软件工程(2016年23期)2017-03-06
中国新通信(2016年11期)2016-08-09
