
增强神经网络算法构建混合模型的建筑能耗短期预测
2022-04-29 05:42王珏
科技创新与应用 2022年10期
王 珏
(上海电力大学 电子与信息工程学院,上海 200000)
公共建筑面积与能耗逐年增长,建筑节能对全球节能减排有着重要意义。建筑能耗受到多方面的影响,如室内外温湿度、设备运行情况、人流密度等。基于数据驱动的预测模型,需要大量的数据作为算法支撑,其中气象数据是多维度且复杂的,不必要的自变量也会产生误差[1]。若仅对每个变量分别进行分析,会形成信息孤岛,导致预测结果必然存在偏差。对于波动性过大数据,PCA存在丢失有效信息的问题,不能做到精准降维[2]。
由于建筑能耗数据具有非线性不稳定的特点,近年来,研究人员主要通过机器学习(Machine Learning,ML)方法来对建筑能耗进行预测。其中深度学习可以从大量无标识数据中自动获取有效特征,比物理模型计算出的预测结果效率更高[3]。随着能耗数据噪声增加,单一模型已经不能适应数据特征,混合模型逐渐得到应用[4]。
本文以上海市嘉定区某建筑大楼(下文用A建筑表示)为研究对象,通过公共能耗检测系统获得该建筑夏季一周内每5 min记录1次的空调冷负荷作为样本数据进行训练测试,提出一种面向建筑能耗短期预测的混合模型AE-AdaBoost-BP。本文主要内容包括:(1)对明显波动与非线性的大量数据标准化处理后剔除毛刺;(2)使用DAE对多维气象参数精准降维;(3)对AdaBoost算法进行改进,优化了迭代过程;(4)利用改良后的AdaBoost算法优化BP神经网络的权值与阈值完成对建筑能耗的预测;(5)应用DAE-AdaBoost-BP混合模型对上海某大型建筑能耗进行短期预测,仿真结果验证了该模型的可行性。
1 模型原理
1.1 去噪自编码器
自编码器(AutoEncode,AE)属于无监督学习,利用神经网络的结构对数据进行降维。自编码器结构内有一个隐含层,输入层和输出层维度相同,隐含层的维度可选择。该网络可由2部分组成,输入层经过一次编码得到隐含层,隐含层再经过解码得到输出层,通过训练网络中的权重和偏置,得到输入层和输出层误差最小时的参数,自编码器结构图如图1所示。
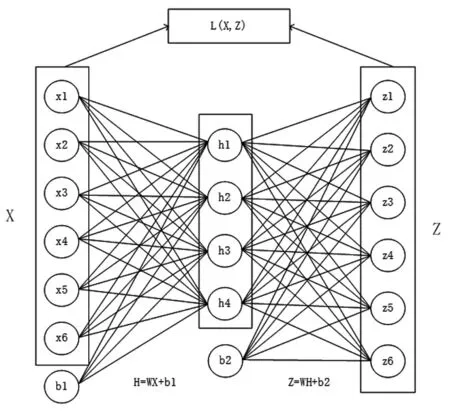
图1自编码器结构图
图1 中b1和b2是输入层和隐含层的偏置,W1和W2是网路各变量的权重,X和Z分别是输入层和输出层,H为中间的隐含层,L(X,Z)为目标函数。当目标函数达到最小值时的权重和偏置即为所求,隐含层即降维后的数据,使用隐含层的数据即可代表原输入数据的主要信息。
去噪自编码器(DenoisingAutoEncode,DAE)是改良版的自编码器,并使得特征值具有一定的鲁棒性。其原理是以一定的概率分布,是输入层的部分数据置为0,即使得部分输入层数据丢失,使用丢失过后的数据去进行编码。破损的输入层数据与原输入层数据相比,丢失的数据中也将噪声一起丢弃,具有一定的去噪功能,这样得到的特征值鲁棒性更高。其基本构架如图2所示。
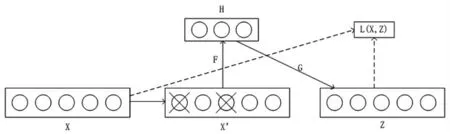
图2 去噪自编码器结构图
1.2 BP_AdaBoost原理
BP神经网络作为人工神经网络中最常见的算法之一,其缺点是很容易陷入局部最小值,对BP神经网络的优化主要在寻找全局最优解上面,如遗传算法和BP神经网络的结合,但遗传算法的优化效果并不是绝对的,没有解决全局最优解的问题。
集成学习作为机器学习的一个分支,在算法上展现了更高的精度。集成算法和多种基础算法都可以结合,并且相对于基础算法在精度上有一定的提升[5]。AdaBoost算法属于Boosting算法中的一种,需要选择一种基算法并进行优化,本次实验将采用BP神经网络作为基础算法。
算法步骤如下:
(1)数据训练集:T={(x1,y1),(x2,y2),…(xm,ym)},BP迭代次数为K,集成学习模型为f(x);
(2)初始化权重为:D(1)=(w11,w12,…w1m);w1i=i=1,2…m,对于k=1,2…K,具有权重Dk的训练集样本得到输出模型Gk(x);
(3)计算训练集上的最大误差Ek=max|yi-Gk(xi)|i=1,2…m;
(4)计算每个样本的相对线性误差eki=
(8)若k<K,则k=k+1,返回步骤(3),若达到最大迭代次数,得到集成学习模型:f(x)=
2 ADE-AdaBoost-BP预测模型建模
2.1 数据来源和处理
数据来源包含1栋楼3层同位置各房间的夏季空调冷负荷。气象数据来自于中国气象数据网,包含大气温度,空气湿度,辐照度等数据。各种数据由传感器测量得到,故可能存在一定的异常值,对原始数据进行归标准化处理,得到均值为0,方差为1的正态分布数据,再通过箱线图检验数据是否存在异常值,如图3(a)所示。
通过图3可以观察到,辐照度和辐照得热的数据上存在一些异常点,对异常数据点进行异常值修改,得到校正后的箱线图,如图3(b)所示,经过矫正过的数值为后续算法所使用到的数据。
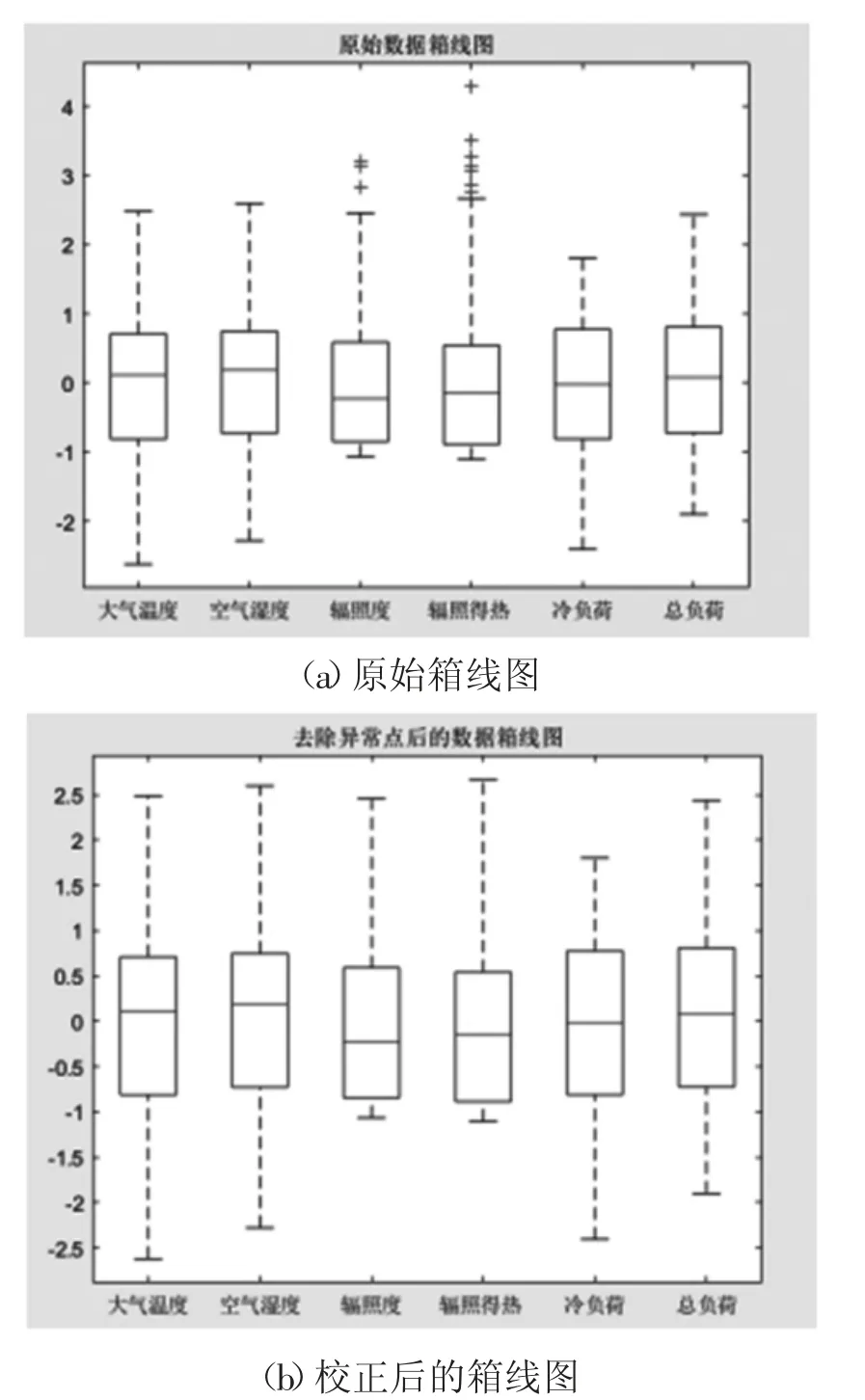
图3 误差箱线图
2.2 预测模型建立
AdaBoost算法的核心思想是在每次计算结果上进行重新权重调整,再次进行训练,算法流程图如图4所示。处理过后的训练集通过BP算法得到预测模型Gk(x)以其预测误差eki,根据预测误差再调整训练集权重,并作为下一次BP算法的训练集。经过多次循环得到K个预测模型,再通过组合方式将这些基础模型整合为1个集成模型,作为本篇论文预测模型。
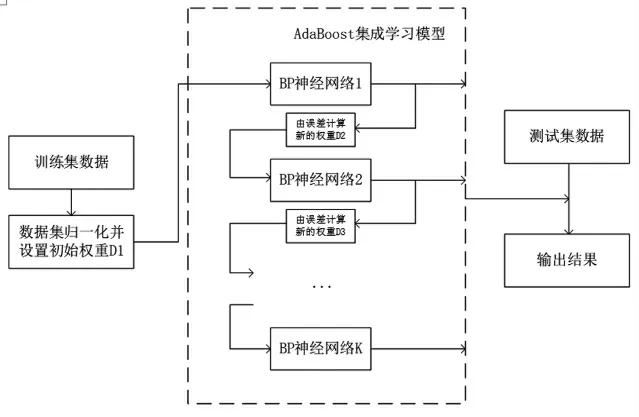
图4 AdaBoost和BP结合的流程图
3 案例分析
本次实验利用matlab2019版本进行预测仿真测试,将矫正过后的气象数据经过DAE分别降维为3维和4维,作为算法的数据输入,输出为各个房间冷负荷的预测值,作为BP网络的训练输入和输出。经实验表明输入层设置为3,隐藏层设置为5,输出为1层,传递函数分别为tansig,tansig和purelin,训练函数为trainlm,训练次数为1 000,训练精度为0.001,学习率为0.1 h,得到的预测效果最佳。
算法的精度由均方根误差(RMSE),平均绝对百分比误差和(AMPE)决定系数R2作为评价指标,公式的计算过程如下:
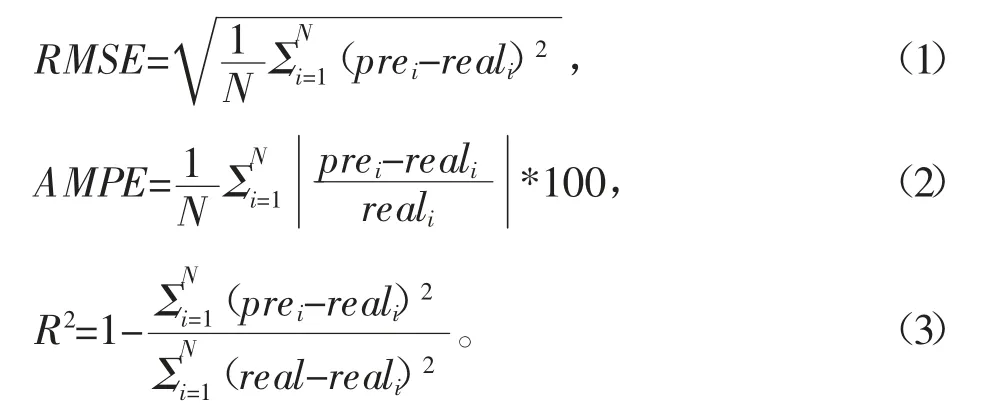
本次实验1分为2步进行,首先按对遗传算法和AdaBoost优化效率作对比,接着对常用回归算法多元线性回归(MLR)和BP神经网络及其优化作对比。
实验1对BP算法优化作对比,使用上述3项指标作为对比参数,对比效果如图5所示。实验分别为BP,GA-BP,AdaBoost-BP,DAE-AdaBoost-BP,由于BP神经网络的模型训练具有一定的不稳定性,且选择的训练次数较小,每次收敛的结果都不同,故使用对应程序各训练5次,作为对应预测精度对比参考。
由图5可知,BP神经网络的结果最不稳定,鲁棒性最差;GA-BP算法在一定程度上进行了优化,但并不代表每次训练得到的结果优于BP算法;AdaBoost算法均优于BP算法和GA-BP算法,具有很好的预测结果;经过DAE处理过后的AdaBoost算法得到的结果为最优解。

图5 误差评价
实验2进行算法间的对比,同时使用MLR,BP和AdaBoost-BP对冷负荷进行预测,MLR算法调用python软件中sklearn程序模块,预测精度见表1。BP及其优化算法的精度为多次训练结果的中位数。
由表1可以看出,MLR算法实现虽然简单,但是精度较低,BP神经网络经过多次训练的平均值高于MLR算法的精度,经过AdaBoost模型得到的BP算法在各项指标上都有明显的提升,经过DAE降维的算法能够得到更好的精度,且收敛数据更快。
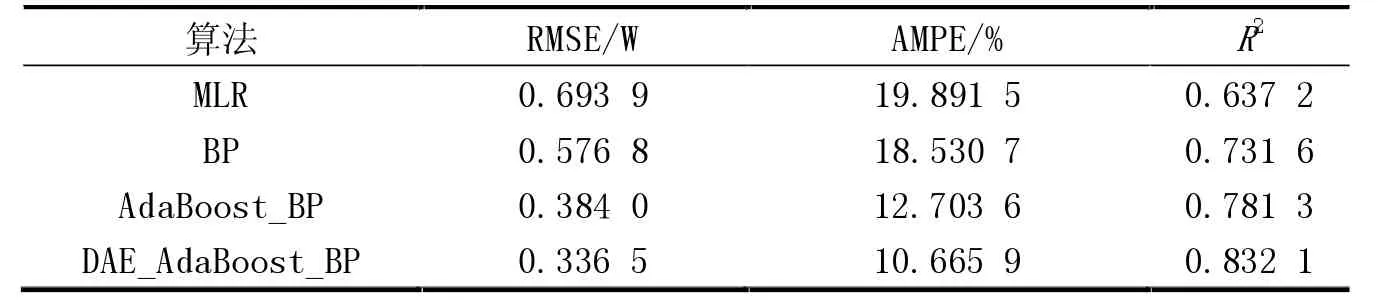
表1 多种算法预测训练结果
4 结束语
本文对上海某栋建筑能耗和气象数据作为研究对象,提出了通过DAE对数据降维,再通过集成学习算法AdaBoost与BP网络的结合对建筑的冷负荷进行了预测,结果表明具有很好的预测效果,在均方根误差,平均误差百分比和决定系数3个方面得到了很大的提升,为管理者提供了良好的数据支持。后续工作将冷负荷预测扩大到整栋建筑的能耗预测,并将通过物联网架构对整栋建筑进行全方位的智能管理,构建相应的管理架构。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
舰船科学技术(2022年11期)2022-07-15
昆钢科技(2022年2期)2022-07-08
传感器世界(2022年3期)2022-05-24
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
数字技术与应用(2021年1期)2021-03-24
建材发展导向(2021年23期)2021-03-08
知识就是力量(2019年7期)2019-07-01
