
基于多颗粒度文本表征的中文命名实体识别方法
2022-06-17 09:09张桂平蔡东风陈华威
中文信息学报 2022年4期
田 雨,张桂平,蔡东风,陈华威,宋 彦
(1. 沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136;2. 香港中文大学(深圳) 数据科学学院,广东 深圳 518172)
0 引言
中文命名实体识别CNER(Chinese Named Entity Recognition)是自然语言处理NLP(Natural Language Processing)的一项基本任务,与关系抽取[1-2]、指代消解[3]、问答系统[4]等任务关系密切。得益于机器学习技术和共享语料库的发展,命名实体识别近年来取得了长足的进展,在自然语言处理领域发挥着重要作用。
与中文分词[5]、词性标注[6]等任务类似,实体识别通常被视为序列标注任务。对中文而言,即为每个字符分配一个相应的标签,以判断字符在实体中的位置以及实体的类型。然而,中文句子由连续的汉字组成,与英文等语言不同,中文句子没有天然存在的分隔符。因此,识别实体边界时会受到分词错误的影响。例如,在“南京市长江大桥”中,正确的分词结果为“南京市/长江大桥”,此时二者倾向于地理位置类型的实体;若分词结果为“南京市长/江大桥”,二者则更倾向于人物名称类型的实体。
命名实体通常包括人名、地名、组织名等名词,因此直观地看,中文命名实体识别可以先对句子分词,然后再给每个词语分配对应的标签[7],所以分词作为中文自然语言处理的基本任务,可以为识别实体边界提供帮助。在中文NER任务中,为了更准确地识别实体边界,缓解字符嵌入带来的语义表示不充分问题,外部知识中的预训练词典被许多研究者引入到模型中。
Zhang等[7]在探究词序列的显式利用过程中,提出了Lattice LSTM模型,该模型利用预训练的词典,提取出序列中潜在的成词单元,并将字符与对应单元通过Lattice结构融合,较好地缓解了实体识别中的边界识别错误。由于上述Lattice的方法较复杂,不利于GPU的并行计算,Li 等[8]提出了Flat-Lattice的方法,将Lattice结构转换为一系列的跨度组合,同时引入特定的位置编码,并使用了Transformer的编码器作为文本编码层,在多个数据集上都有较好的识别性能。Sui等[9]提出了一种协作图网络,利用三种不同的方式将字符和词序列相结合,以此获取不同的词汇知识。
以上方法虽然探讨了字表征和词表征对命名实体识别的影响,但是仍然存在两个难点。第一,上述方法没有显式地将模型内部字符特征与对应的所有N-gram特征相结合。第二,预训练词典中的N-gram虽然包含潜在的成词信息,但是存在较多的噪声,对模型的性能会产生不利的影响。针对第一个问题,本文设计了一种N-gram编码器,其能够有效地利用N-gram表征,提取其中潜在的成词特征,然后将模型隐藏层输出与对应的N-gram表征进行结合,从而显式地利用词典中的N-gram。针对第二个问题,本文利用开源的分词工具和预训练词向量,在模型输入端引入了一种新的词粒度表征,通过字、词、N-gram的结合,降低了词典噪声对模型的影响。
综上,现有的命名实体识别模型在输入端大多使用字向量,本文分析了预训练词典被应用在NER任务时的优缺点,提出了一种基于多颗粒度文本表征的NE-Transformer模型。本文的贡献如下:
(1) 本文首次在中文命名实体识别任务中联合了三层不同颗粒度的文本表征。
(2) 本文提出了NE-Transformer模型(N-gram Enhanced Transformer),在模型输入端融合了字向量和词向量,并使用N-gram编码器引入潜在的成词信息,缓解了实体边界识别错误的问题。
(3) 在多个数据集上的实验表明,NE-Transformer模型较Baseline模型有更突出的性能表现。
在接下来的内容中,第1节介绍相关研究,第2节详细介绍基于多颗粒度文本表征的命名实体识别模型,第3节对实验结果进行对比分析,最后一节是全文总结。
1 相关研究
早在1991年,就有学者研究了从金融新闻报道中自动抽取公司名称的算法[10],该研究通常被认为是命名实体识别研究的前身[11]。在1995年第六届MUC会议中,NER作为一个明确的任务被提出[12]。随后在NER各阶段的发展历程中,出现了不同的主流方法,包括传统方法和基于深度学习的方法。
在传统方法中,使用规则进行NER的方法会消耗大量的时间和精力,且领域迁移性差。基于机器学习的方法虽然摒弃了制定规则所需的繁琐步骤,将NER统一作为序列标注任务来完成,但需要大量已标注好的训练数据并人为定义特征模板,然后通过实验进行反复调整,同样耗时耗力。因此,可以自动学习出文本特征信息的深度神经网络方法在近年来取得不错的进展。
将神经网络应用到NER任务时,需要在输入端对词语进行编码,因为字符嵌入在性能上要优于词嵌入[13],因此将字符向量作为模型的输入是进行NER任务的常规操作。Huang等[14]首次将双向长短时记忆网络Bi-LSTM(Bidirectional Long Short-Term Memory)应用到序列标注任务中,有效提高了词性标注、实体识别的预测精度。随后,Lample等[15]、Dong等[16]、Zhang等[17]在此基础上展开了一系列的研究。
然而,仅使用字符嵌入无法准确地表示词语边界,在识别结果中存在由于边界识别错误而引发的问题。为缓解这一现象,预训练的词典被引入到了NER任务中。Zhang等[7]利用Lattice LSTM的结构,将与字相关的词粒度信息融入模型中,实现了字词信息的结合。Liu等[18]提出了Word-Character LSTM模型,将字词信息结合的同时,减少了字符间信息的传递,并设计了四种编码策略来加速模型训练。Cao等[19]在进行实体识别任务的同时,引入了分词任务,采用对抗学习的方法将任务共享的信息融入到了中文NER内。
虽然BiLSTM-CRF主流框架在命名实体识别领域被广泛的研究,但是LSTM无法对一个位置同时关注其上下文的信息,加上长距离的依赖关系也会随着句子长度的增加而逐渐被忽略,因此近年来,Transformer架构[20]开始在NLP领域的多项任务中崭露头角,如文本生成[21-23]、机器翻译[20]、预训练模型[24-26]等。由于传统的Transformer并不十分适用于NER,因此Yan等[27]提出了一种改进的Transformer结构,引入了定向的相对位置编码,同时可以捕获不同字符间的距离信息,使Transformer能够更准确地识别命名实体。Li等[8]克服了Lattice LSTM模型无法充分利用GPU并行计算的问题,将Lattice转化为体现词语长度的平面结构,并提出了四种位置编码,在NER任务中取得了不错的成绩。此外,Nie等[28]提出了SANER模型,针对非正式文本,在TENER模型的基础上,结合预训练的词典,引入字符的相似词,设计了一种语义增强模块,在非正式文本领域发挥了高性能的表现。
由于中文命名实体识别仍然存在实体边界识别错误的问题,因此本文在SANER模型的基础上,将输入文本的字、词表征进行组合,并在Transformer中引入N-gram编码器,将N-gram中的潜在词信息融入模型主干,从而更准确地识别实体边界。
2 基于多颗粒度文本表征的Transformer命名实体识别框架
本节描述了提出的基于多颗粒度文本表征的命名实体识别模型,其结构如图1所示,其包含三个模块: ①向量表示模块,使用低维稠密的字向量和词向量表示每个字符蕴含的特征,使用随机初始化的方法创建N-gram向量; ②文本编码层,捕获字符的上下文信息,并使用N-gram编码器引入潜在词语信息,为模型主干补充潜在词语特征; ③CRF解码层,使用CRF作为模型的解码器。

图1 NE-Transformer模型图
2.1 向量表示模块
分布式词向量表征是当前神经网络方法中常用的一种对字符进行编码的选择。与高维稀疏的独热向量相比,低维稠密分布式词向量的每个维度表示一个潜在的特征,由于分布式表示可自动在文本中进行学习,因此其能够捕获词语的语义和语法特征[29]。此外,由于实体识别跟分词任务关系密切,本文通过引入词向量和N-gram向量来丰富字符编码的表示。
2.1.1 字向量
当命名实体识别被视为序列标注任务时,常使用字向量对文本编码。针对一句话X={x1,x2,…,xn},n表示输入序列的长度,第i个字符的字向量表示如式(1)所示。
(1)

2.1.2 词向量
虽然使用字符编码的方式不再要求对文本分词,但是单一字符在一定程度上缺乏词的语义信息,无法体现词语的特点,因此本文引入了词向量作为对字向量的补充。在现有方法中,一般先利用Word2Vec[31]等工具生成预训练的词典,然后在词典中抽取存在的Bi-gram与字符向量拼接,作为模型的输入。与该方法不同,本文利用Tian等[32]发布的分词系统WMSeg,先对数据集中的句子进行分词,然后在腾讯词向量[33]中提取对应的向量作为与字符对应的词向量,使用该分词系统的原因是其在中文分词任务中表现出了十分优越的性能。在X中,第i个字符对应的词向量如式(3)所示。
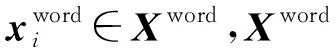
2.1.3N-gram向量
N-gram作为一种外部知识类型,对中文分词、词性标注等序列标注任务有正面影响[25-26,34]。
由于N-gram可以为模型提供潜在的构词特征,因此本文除了使用预训练的字向量和词向量,还使用随机初始化的方式为每个N-gram分配了一个向量,如式(4)、式(5)所示。
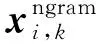
2.1.4 模型输入
在NLP任务中,获得高质量的文本特征表示是模型取得高性能表现的关键[35],因此模型的输入采用了字向量和词向量的拼接,第i个字符的最终向量表示如式(6)所示,当预训练的词典中不包含当前使用的字向量或词向量时,模型会使用均匀分布的方法来随机初始化一个字向量或词向量。输入句子的矩阵表示如式(7)所示。
2.2 文本编码层
由于传统的Transformer不能很好地适用于命名实体识别任务,因此本文在文本编码层使用了改进的Transformer编码器——TENER[27],并添加了语义增强模块[28]。为了进一步缓解实体边界模糊的问题,本文在模型主干外引入了N-gram编码器,以此提取N-gram中潜在的成词信息。本节介绍了模型主干和N-gram编码器的相关内容。
2.2.1 语义增强的Transformer
由于在非正式文本中,存在数据稀疏问题,所以其中的命名实体个数很少,常常在几句话中才会出现一个符合要求的命名实体。Nie等[28]提出了一种语义增强的模型SANER,利用改进的Transformer编码器TENER和字符的相似字,丰富了非正式文本中字符的语义信息。由于该模型能够充分挖掘字符语义信息,因此本文使用SANER模型作为模型主干和基线。
改进的Transformer编码器通过在多头注意力(Multi-Head Attention)中引入定向的相对位置编码,明确了不同方向字符给当前字符带来的方向信息和距离信息,由式(8)来表示。
H=Adapted-Transformer(E)
(8)
其中,N={h1,h2,…,hi,…,hn}是对应的隐藏层输出。此外,在得到字符i的相似字Ci={ci,1,,ci,2,…,ci,j,…,ci,s}后,通过式(9)、式(10)计算每个相似字对第i个字符的注意力得分,并加权求和。
其中,ei,j表示第i个字符对应的第j个相似字的编码。
最后通过门控机制来平衡特征提取模块和语义增强模块的信息,如式(11)、式(12)所示,W1,W2都是可学习的参数矩阵,oi表示门控单元的最终输出向量。
2.2.2N-gram编码器
受Diao等[25]的启发,本文增添了N-gram的编码信息来引入潜在词语语义,从而提升模型效果。为了更充分地挖掘句子中N-gram的潜在成词信息,并与模型主干相匹配,本文使用了具有L层的N-gram编码器来提取N-gram的特征表示,并使之与模型中字符的隐藏层向量相结合。
为了建模N-gram之间的依赖关系,提取N-gram潜在特征,同时能够与模型主干的子层相对应,我们选择了Transformer的编码端作为N-gram编码器,由于模型不关注各N-gram的位置,所以在N-gram编码器中没有添加位置编码,只使用了传统的多头注意力计算得分,计算过程如式(13)、式(14)所示。

其中,G(l)表示N-gram编码器在第l层的输入,当l等于1时,G(l)等于Engram,此外,Wq,Wk,Wv是可训练的参数矩阵。之后,我们将注意力得分送入层归一化和前馈神经网络中进行运算,得到第l层的输出,计算过程用式(17)代替。
2.3 CRF解码层
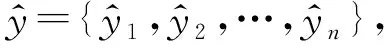

(19)
其中,Wc和bc是计算标签yi-1到yi转移得分的可学习参数,L是所有标签的集合。
3 实验与分析
3.1 实验数据
本文采用了Peng等[37]发布的Weibo NER数据集,Zhang等[7]发布的Resume数据集以及Weischedel等[38]公布的OntoNotes4数据集,三种数据集都采用BIOES标注方案[15],各数据集的详细情况如表1所示。
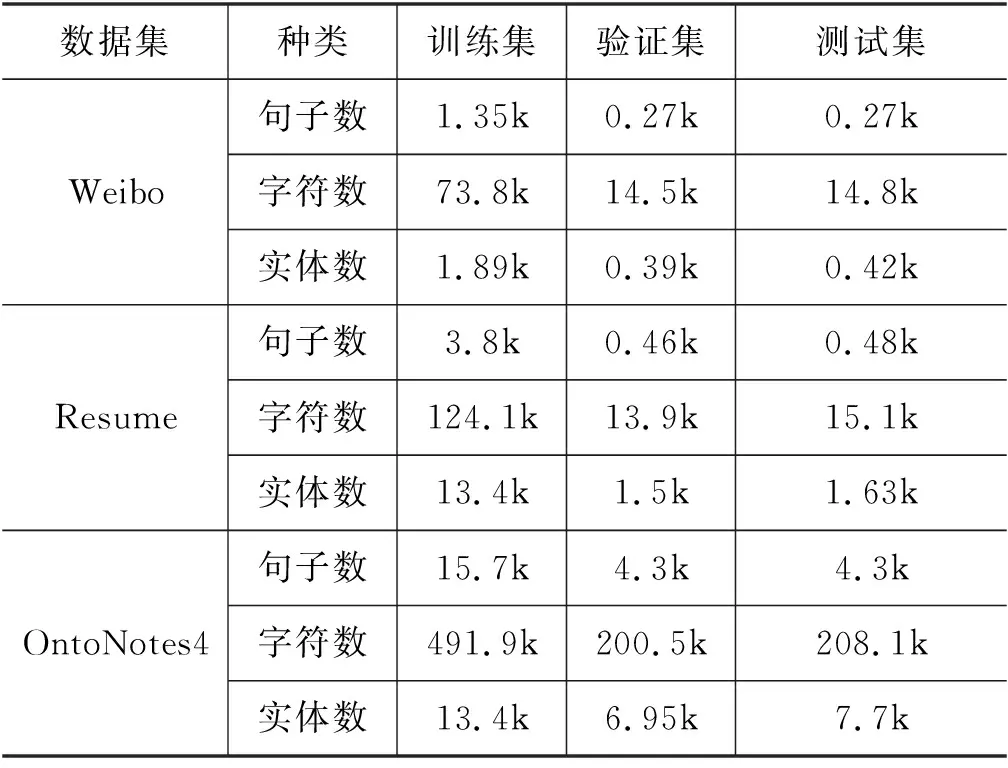
表1 数据集详细介绍
Weibo数据集属于社交媒体领域,包含4种实体类别: 人名(PER)、机构(ORG)、地点(LOC)和地理政治(GPE),共28个标签。
Resume数据集属于中文简历领域,包含8种实体标签: 人名(NAME)、机构(ORG)、地点(LOC)、职业名称(TITLE)、教育组织(EDU)、国家(CONT)、专业(PRO)、种族(RACE),共28个标签。
OntoNotes4数据集属于新闻领域,包含四种实体类别: 人名(PER)、机构(ORG)、地点(LOC)和地理政治(GPE),共17个标签。
3.2 实验参数设置
本文实验采用PyTorch1.4框架,使用的预训练词向量包括Giga[7]、腾讯词向量[33]和BERT[24]。此外,本文还使用了表2的参数对模型进行了微调,最后利用在验证集上性能表现最好的模型对测试集进行评估。在超参数中,Transformer编码器的多头注意力头数变化集合为{4,8,12},编码器子层的数量集合为{1,2,4},编码器输出的隐藏层向量长度为[64,128,256],MaxN-gram length表示模型采用的N-gram最大长度,设为5。

表2 模型超参数设置
3.3 实验与分析
本文使用标准的精确率P(Precision)、召回率R(Recall)、F1值作为模型的评价指标。
3.3.1 整体模型对比
表3~5分别列出了下述各模型在3个数据集上有关精确率P、召回率R、F1值的对比结果。
对比模型除了上文提到的Lattice LSTM[7]、TENER[27]、Flat[8]、协作图网络[9]、BERT[24]、SANER[28],还包括Zhu等[39]提出的CAN-NER模型,该模型首次将CNN与局部注意力机制结合起来,以增强模型捕获字符序列之间局部上下文关系的能力;Meng等[40]提出的Glyce,该方法引入了中文字形信息,在多项NLP任务中表现出了良好的性能;Nie等[30]提出的AESINER模型,用键值对记忆网络将句法知识融入模型主干;以及Diao等[25]提出的中文预训练模型ZEN,Song等[26]提出的ZEN2等。
综合表3~5可知,本文提出的NE-Transformer模型在Weibo、Resume、OntoNotes4上的F1值分别达到了72.41%,96.52%,82.83%,其中在Weibo数据集上的性能提升最大,这是由于Weibo语料属于社交媒体领域,文本格式不规范,并且文本中的词汇边界相较于其他领域更加模糊,因此词粒度信息的融入使得字符的编码特征蕴含更丰富的语义信息,从而更容易获得较高的性能。此外,由于现有模型[30,40]在Resume数据集上已经达到了较高的得分,故而本文模型在该数据集上与上述模型性能相当。

表3 Weibo数据集实体识别实验结果

表4 Resume数据集实体识别实验结果
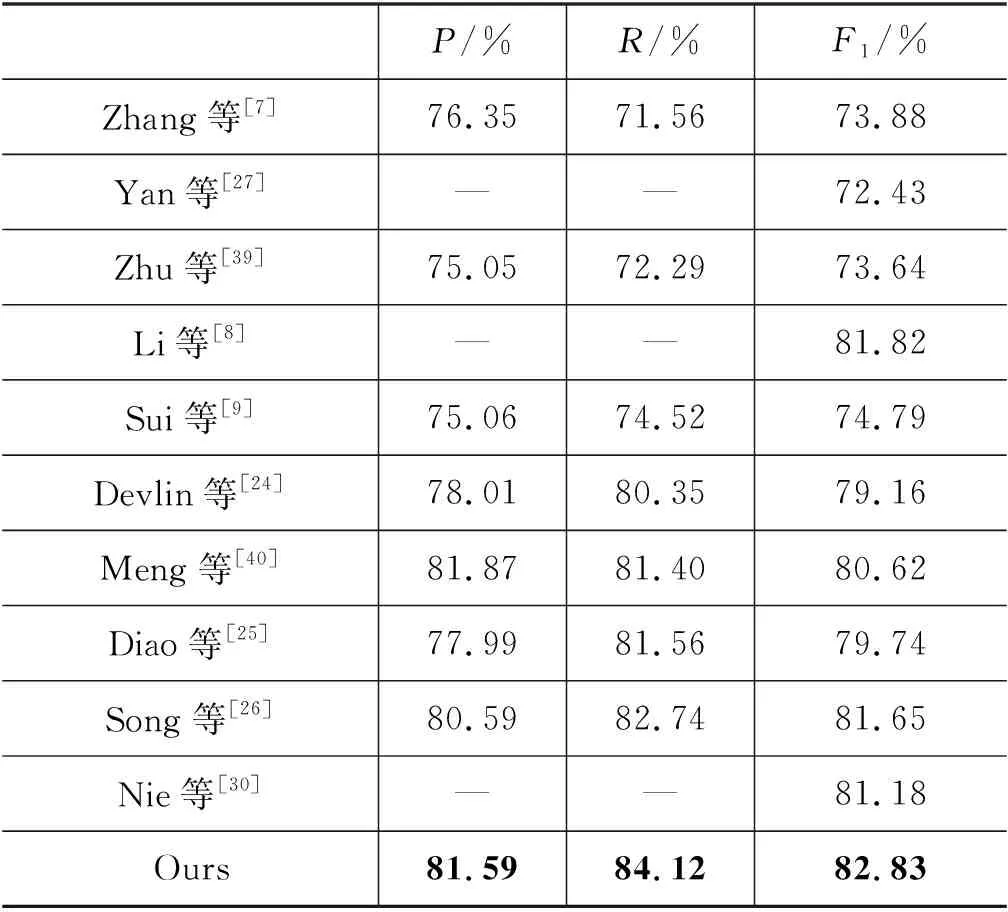
表5 OntoNotes4数据集实体识别实验结果
3.3.2 实验结果与分析
为了研究改进方案的有效性,本文对三种数据集进行了对比实验,结果如表6所示,表格中的Y和N分别代表使用或者不使用对应的外部知识。

表6 融入词表征和N-gram表征的F1值结果对比
表6的第一行为baseline,模型输入部分只使用字向量,文本编码层不使用N-gram编码器,第二行在baseline的基础上加入了N-gram编码器,第三行在baseline的基础上加入了词向量,第四行同时引入了词向量和N-gram编码器。
由表6可以看出,添加词向量和N-gram编码器的三种方案相较于baseline都有一定的性能提升,其中baseline即未添加词向量和N-gram编码器的模型。而仅添加N-gram编码器时,Weibo语料的F1值下降了0.1%,导致这种现象出现的原因可能是Weibo语料中存在的实体较少,而模型学习到了较多的N-gram噪声,使得模型性能下降。值得注意的是,虽然仅添加N-gram编码器对模型性能的影响不明显,但是将词与N-gram特征结合后,模型性能得到了较大的提升,在Weibo、Resume、OntoNotes4数据集上F1值分别提高了1.25%、0.32%、0.44%,这可能是因为加入词向量之后,减少了N-gram噪声对模型的影响,使得模型能够更准确地识别实体边界。
同时,添加词向量与添加N-gram编码器对不同领域的数据集产生了不同的影响,在社交媒体领域,词向量比N-gram编码器的作用更大,提高了0.58%;而在新闻领域,即OntoNotes4数据集,N-gram 编码器为模型带来了更好的性能,提升了0.13%。
为了进一步分析词向量和N-gram编码器的效果,表7统计了词向量和不同N-gram数量对模型的影响,包括精确率P、召回率R和F1值。
通过表7可以看出,在NE-Transformer中,随着N-gram长度的增加,模型的F1也得到了不同程度的提升,并且当N-gram长度为4时,三个数据集上的F1达到最优,与仅添加词向量的模型(baseline加词向量)相比,F1值分别提高了0.67%,0.20%,0.41%,这表明不同长度的N-gram对模型都有正面的效果,但是超过一定的界限(即N-gram长度为4)时,反而会使得模型学习到不必要的噪声,使得模型F1值出现了下降。
同样值得注意的是,表7的结果表明词、N-gram特征在不同的方面影响了模型性能。与baseline相比,添加词特征后,在Weibo、Resume、OntoNotes4三个语料上的精确率P分别提升了3.21%、0.35%、1.85%,在此基础上添加N-gram编码器后,召回率得到了明显的提升,产生这种结果的原因可能是词、N-gram的加入弥补了单个字符缺失的词语义信息,同时降低了N-gram噪声对识别效果的影响,因此二者的结合进一步提升了命名实体识别的效果。

表7 最大N-gram数量对三种数据集的影响
3.4 案例分析
为了验证NE-Transformer模型能够识别出更多的实体,我们在Weibo数据集中选择了两个实例进行分析。表8、表9列举了在实验结果中出现的经典案例。在两个实例中,Baseline存在的问题都是实体边界错误,案例1的句子为“好男人就是我”,其中的人物实体“男人”被识别为“好男人”。例2的句子为“爸爸妈妈想你们了”,其中的人物实体“爸爸”和“妈妈”被识别为一个实体,即“爸爸妈妈”。而通过NE-Transformer结合字、词、N-gram的信息之后,两个实例的实体边界均得到了正确的识别。

表8 案例分析1

表9 案例分析2
由此可以看出,本文提出的NE-Transformer模型通过使用N-gram编码器在模型内部引入与字符相关的N-gram,同时在模型输入端加入词表征,能够更准确地识别实体边界,并更加有效地建模上下文关系,从而达到更好的效果。
4 总结与展望
本文针对公开的三种中文命名实体识别数据集,提出了一种基于多颗粒度文本表征的中文命名实体识别方法,首先使用分词系统对语料分词,在模型的输入端将字、词向量进行融合,并随机初始化了N-gram向量,丰富了字向量的语义表示。随后,我们探索了预训练词典在NER任务中所发挥的作用,并首次直接联合了三层不同颗粒度的文本表征,包括字、词、N-gram表征,同时设计了一种有效的联合方法,缓解了模型在训练过程中遇到的实体边界模糊问题。在三种数据集上的实验结果表明,本文模型较baseline可以更好地识别句子中的命名实体,并在社交媒体语料中取得了目前最好的效果。未来可以考虑将NE-Transformer模型应用到其他序列标注任务中,并探索N-gram的其他使用方式对命名实体识别的影响。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
校园英语·月末(2021年13期)2021-03-15
——编码器
演艺科技(2020年7期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
智富时代(2019年6期)2019-07-24
