
高考语文阅读理解自动答题系统
2022-06-17 09:10谭红叶郭少茹王素格杨陟卓钱揖丽王元龙吕国英
中文信息学报 2022年4期
谭红叶,郭少茹,陈 鑫,王素格,李 茹,2,张 虎,杨陟卓,陈 千,钱揖丽,王元龙,关 勇,吕国英
(1. 山西大学 计算机与信息技术学院,山西 太原 030006; 2. 计算智能与中文信息处理教育部重点实验室,山西 太原 030006 )
0 背景
面向人类的标准化测试被认为是人工智能领域的一个挑战性问题[1-2],这类测试通过提供多样化的问题,考察被测试者掌握的各种知识与能力,如语言理解、数学计算、逻辑推理、常识建模等。虽然目前对机器智能没有严格给出定义,但人们对类人机器智能期待的目标之一是: 像人一样回答各种各样的问题,并通过标准化测试。
为了促进机器智能向类人智能迈进,研究者提出了利用标准化测试对机器智能进行有效和实用的评价,各国政府或研究机构也设立了许多相关项目,旨在让机器通过面向人的标准化测试。例如,美国艾伦人工智能研究所设立的“Aristo”项目[3],日本国立情报学研究所曾开展的“东大机器人项目”(Todai Robot Project)[4],以及我国政府推出的以高考试题为测试背景的“基于大数据的类人智能关键技术与系统”项目[5]。
阅读理解任务是给定一篇文本,要求测试者根据文本的内容对相应问题做出回答。该任务不仅是标准化测试的一项重要内容,而且能够客观反映并促进机器智能的发展,因此,近几年受到学术界和企业界广泛关注,已成为自然语言处理领域一个重要的研究分支。例如,微软、谷歌、百度、斯坦福大学、卡耐基梅隆大学等顶级 IT 公司与大学分别创建并发布各自的阅读理解测试数据集[6-17](如: MS-Marco、CNN/DailyMail,Dureader、SQuAD、HotpotQA、MCTest等)以推动相关技术的发展。在这些数据集的支持下,研究者提出了一系列基于深度学习的阅读理解模型和算法,并取得了令人振奋的进展。例如,一些深度学习模型在 SQuAD 数据集上的性能已经超越人类的表现。然而,这些数据集任务要么相对简单,要么偏重于某一方面的理解或推理能力。因此,模型所具备的语言理解能力与人的期望相差很远。
近几年,山西大学中文信息处理团队在科技部项目“基于大数据的类人智能关键技术与系统”的支持下,面向高考语文阅读理解任务,针对类型更丰富、更具挑战性的复杂语言问题,在语义表示、候选句抽取、鉴赏分析等阅读理解核心任务上进行了重点研究,并构建了包含多个答题引擎的现代文阅读理解答题系统。
本文将详细介绍这些研究内容,组织结构安排如下: 第1节分析高考语文阅读理解任务的特点;第2节介绍构建的阅读理解答题系统;第3节针对系统进行了实验,并对实验结果进行分析;最后给出项目组对阅读理解未来研究的思考与展望。
1 任务分析
高考语文现代文阅读理解要求考生能根据不同阅读目的,针对阅读材料特点,运用恰当方法阅读多种文本,并回答相关问题。以北京高考为例,通过分析近10年高考语文阅读理解题目,发现其特点与难点主要体现在以下几个方面。
1.1 阅读材料内容广泛
高考语文现代文阅读理解体裁主要包括科技文和散文。科技文阅读材料多为最新的科学技术、研究及发现等内容。例如,2021年为“人工智能深度学习技术”,2020年为“嫦娥四号”和“玉兔二号”,2019年为“城市化与生物多样性”。散文阅读材料涉及许多作家的文学作品,2021年为作家牛汉的散文“心灵的呼吸”,2020年为作家沈从文先生的“从音乐和美术认识生命”,2019年为作家赵园的“北京的大与深”。这些材料的主题、用词与写作风格迥然不同,已有的词典与训练语料无法做到全覆盖。
1.2 题目类型多样,要求考生全面把握作品内容
阅读理解题目从形式上看主要包括选择题和问答题,从内容上看主要包含: 文中重要词语、句子的理解和解释;文中信息的分析、筛选、整合、运用;对多个信息的比较、辨别,文本结构、作者思路的梳理和分析;文本内容的归纳和概括;作者思想感情、观点态度的理解、分析和概括;依据文本内容进行的合理推断;文学作品思想内容、作者情感的把握和评价;文学作品语言、表现手法和艺术形象的赏析(如2016年24题为: 文章第四段运用了多种手法,表达了作者对老腔的感受。请结合具体语句加以赏析);从不同角度和层面对文本内容或形式的体察、阐发和评价(如2017年23题为: 文章叙写了玛利亚乌热尔图和走出山林的人们,请分别概括他们各自: 根河之恋的表现。作者这样构思体现了怎样的匠心?);基于知识积累和生活经验对文本意蕴的思考、领悟和阐释(如2019年21题为: 试借助这种由表及里的感知方式,来谈谈你对自己所生活的周边世界(如城镇、社区、学校、 家庭等)的认识与思考)。
可以看出,阅读理解类考题要求考生从不同层面、不同角度把握作品的基本内容、写作手法、结构安排与情感主旨。
1.3 需要多种答题技巧与能力
我们将阅读理解高考语文并解答提问所需的能力总结归纳为以下3个层次。
层次1: 文本细节信息的捕获与理解,具体表现为细节推理能力。从高考题目表现形式来看,主要指区分选项与原文之间的细微语义差异的题目。这类题目的选项与原文在大多时候词重叠程度很高,仅存在一些如修饰语、数量词方面的细微差异。
层次2: 文本局部信息的整合与推理,具体表现为句子之间不同语义关系的理解。
层次3: 全局信息的整合与推理,具体表现为对整个文本主旨思想、组织结构、作者情感与态度的理解。
2 高考语文阅读理解自动答题系统
2.1 系统架构
结合高考语文题目特点,基于阅读理解核心技术,构建了高考语文阅读理解答题系统。该系统包含资源层、技术层、引擎层以及展示层,如图1所示。
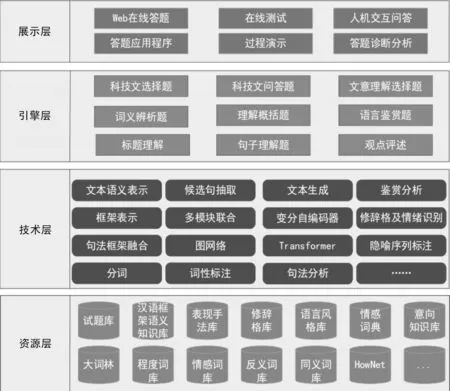
图1 高考语文阅读理解答题系统架构
资源层为高考语文阅读理解自动解答提供资源支持,主要包括两类资源: 一类是自然语言领域中已有的资源,如同义词库、HowNet等;另一类是针对高考语文阅读理解问题构建的特色资源,包括试题库(科技文题目总数为16 096,散文题目总数为7 916)、汉语框架语义知识库(框架总数为1 320个,词元总数为21 145个,例句总数为19 165句,篇章总数为1 002篇)、表现手法库(1 025条)、修辞格库(15 117条)、语言风格库(7 064条)、规模为近20万条的情感词典、意向知识库(1 224条)等。这些特色资源都是从文本中自动抽取样例,再经过人工标注与校对建立而成。
技术层为高考阅读理解自动答题提供技术支持。本文将阅读理解相关技术分为两类: ①NLP基础技术,该类技术为自然语言领域中相对成熟的技术,如分词、词性标注、句法分析等; ②阅读理解关键技术,指实现高考阅读理解自动解答必不可少且具有特色的技术,如文本语义表示、候选句抽取、鉴赏分析等技术。
其中,候选句抽取技术作为阅读理解基础技术,为各个答题引擎提供基础技术支撑。文本表示技术主要基于句法框架语义等多源信息,增强科技文选择题和问答题的解答。鉴赏分析技术从语言鉴赏的角度,支撑散文鉴赏题的解答。
引擎层通过将不同核心技术进行有效结合,实现对高考语文阅读理解问题的自动解答。核心引擎包括: 科技文选择题引擎、科技文问答题引擎、散文选择题解答引擎(文意理解选择题引擎、词义辨析题引擎)、散文问答题解答引擎(理解概括题引擎、语言鉴赏题引擎)等。
展示层通过多种方式、多种途径呈现系统的答题结果,包括: Web在线答题、在线测试、人机交互问答、答题应用程序、过程演示、答题诊断分析等。
2.2 阅读理解关键技术2.2.1 基于框架的文本语义表示
阅读理解材料体裁多样、风格迥异,因此如何有效获取不同主题、不同风格的文本语义表示是解答问题的前提与挑战。针对该问题,本文提出了基于框架的文本语义表示技术,旨在利用场景信息获取文本的语义表示。
基于框架的句子表示句子语义表示是机器阅读理解核心关键技术。针对如何有效利用知识进行句子语义表示问题,我们提出了基于框架的句子表示模型,通过建模句子蕴含的框架语义场景图式化信息,达到丰富句子语义信息的目的。利用框架关系建模文本中框架间的语义关联,采用聚合函数将句子的多个框架语义结构信息进行有效集成,获取包含框架语义信息的句子表示[18]。相关实验表明,该方法能有效提升机器阅读理解模型对文本语义场景的理解能力。
融合句法和框架的句子表示句法和语义信息是句子理解的重要组成部分。针对如何构建多源知识表示学习模型问题,提出了基于句法和框架语义的句子表示模型,通过将句法和框架映射到相同的语义空间,实现句法和框架联合增强的句子表示。采用位置感知融合方法,充分利用句子中每个标记的句法和框架语义信息,获取同时蕴含句法和框架信息的句子表示[19]。相关实验表明,句法和框架语义信息能有效提升模型的阅读理解性能。
2.2.2 候选句抽取
从形式上,阅读理解材料篇幅过长,包含大量与解题无关的冗余信息,因此如何有效筛选材料关键信息,进而对问题进行解答,显得尤为重要。从内容上看,阅读理解任务考察了系统对信息的筛选、整合等能力。候选句抽取作为一种可以有效建模重要信息的技术,为解答阅读理解问题提供重要技术支撑。
基于框架语义的候选句抽取通过抽取与问题相关的候选句,可有效减少噪声数据对模型的影响。针对候选句抽取,我们提出了基于框架语义的候选句抽取方法,通过分析句子所涉及的语义场景,得到句子间的语义关系。利用框架词元库标注选项和句子的目标词和框架,根据标注结果计算框架之间的相关性和目标词之间的关系,抽取与问题语义一致的句子作为候选句[20]。
基于多模块联合的候选句抽取针对候选句数据集中存在正负样本不均衡及多步推理问题中的候选句难以直接抽取的问题,提出了基于多模块联合的候选句抽取模型。首先采用部分标注数据微调预训练模型;然后通过TF-IDF递归式抽取多步推理问题中的候选句;最后结合无监督方式进一步筛选模型预测结果,降低冗余性。该方法从相关性、覆盖率、冗余性三个角度提升候选句抽取的效果,有效抽取出与选项相关的候选句[21]。
基于网络图答案句抽取为了正确抽取隐含答案句,我们提出基于网络图的方法。通过建模问句与候选句之间的语义、逻辑关系,对答案句进行分析、筛选和推理。构建问句与候选答案句的关联矩阵,该矩阵不仅包括问句和候选句之间的问答语义关联,同时包括候选句之间的篇章语义关联;综合利用各种语义关系对候选句进行全局优化排序;最后选取分数最高的Top-6候选句作为最终的答案句[22]。
2.2.3 鉴赏分析
语言鉴赏问题是在理解文本语义的基础上,针对文本采用的语言技巧等多种手法进行赏析。因此,需要从语言学及认知学等多个角度,针对修辞格及隐喻识别开展相关的研究,支撑该类题目的解答。
基于多任务学习的修辞格及情绪识别方法文学作品常利用修辞格增强语言表达效果,含蓄地传递创作者的情绪。修辞格与情绪识别是语言鉴赏过程中的核心任务。通过数据统计发现,修辞格与情绪类别间具有强关联性。因此,针对数据的这一特性,提出了一种基于多任务学习的修辞格及情绪识别方法,使两个识别任务的性能相互促进。具体地,在句子语义及句法表示的基础上,分别设计修辞格及情绪分类器,获取句子的修辞格及情绪关联分布表示,并提出融入关联表示的修辞格与情绪的多标签预测,从而得到句子的修辞格及情绪标签集[23]。
基于语义场景不一致的隐喻序列标注方法隐喻是认知领域中利用具体概念理解抽象概念的一种机制。文学作品中常利用隐喻形象地刻画抽象概念,为文本的语义理解带来了很大的挑战。然而,前人的研究忽略了隐喻句中词语语义场景不一致的特性。因此,提出了一种基于语义场景不一致的隐喻序列标注方法,通过度量句子中词语间的语义场景不一致,提升隐喻词语的识别效果。具体地,设计抽象分布表示刻画句子中每个单词的语义场景,利用分布表示间的距离衡量词语的语义场景不一致,并将其作为损失函数的正则项,使得模型更准确地识别句子中的隐喻词[24]。
2.3 主要答题引擎
科技文选择题解答引擎科技文选择题基于对文章的理解从多个选项中选出最佳答案。首先,利用多模块联合的候选句抽取方法获取与问题相关的候选句;其次,通过词性标注工具标注句中的名词成分,结合句法分析将句中名词成分及与其具有直接句法关联的元素抽出,名词与其具有直接句法关联的元素一同组成关键元素图节点;然后,使用GAT(Graph Attention Networks)[25]对关键元素图中的节点进行学习,将所得的图节点表示融入BERT,得到文本增强表示;最后将信息输入模型表示层,进而预测问题答案[26]。
科技文问答题解答引擎科技文问答题需要抽取文章中与问题相关联的内容,并对相关联的内容进行理解与分析,进而归纳概括出问题答案。首先,采用基于框架语义的候选句抽取方法获取候选句与问句之间的语义关联;其次,利用基于图网络答案句抽取技术获取问题的答案,构建基于图神经网络的异构网络图,将丰富的节点(句子节点、词语节点)和节点之间的关系(框架关系、篇章主题关系)引入图神经网络模型;然后,采用GAT对图中的关键节点进行表示学习,在网络图中,问句与候选句节点不仅可以通过中继节点交互,还可以通过框架语义和篇章主题关系相互更新;最后,将候选句节点的表示输入模型预测层,把分数最高的6个候选句标记为答案句。
散文选择题解答引擎主要解答两类选择题: ①文意理解题,需要通过分析文本与选项之间的语义蕴含关系来选取问题的答案。首先,将文本的词性特征、命名实体特征、字符嵌入特征等多特征进行聚合;其次,采用双向GRU网络完成对文本序列的上下文嵌入表示;再次,利用多重注意力[27]机制对候选句抽取和蕴含分析进行联合建模;最后,使用多向匹配策略[28]进行特征融合,通过对矩阵进行聚合及归一化处理,得到最终的蕴含分数。实验结果显示,本文模型能有效消除pipeline方法的误差累积问题。②词义辨析题,指给定目标词及其释义,判断该释义是否符合目标词所在上下文。采用基于语义与情感一致性的计算方法,首先,对文档与选项进行预处理,选取被抽取词语所在句子及上下各一句作为所需要的语境;然后,计算被解释词语所在句子与释义替换后句子的语义相似度,并加入情感极性和上下文修饰语信息进行辅助判别;最后,根据最终分数进行排序,得到词义辨析的最佳答案[29]。
散文问答题解答引擎主要解答两类问答题: ①理解概括题。根据问题,结合背景材料概括生成答案。首先,通过LDA进行主题聚类,并结合词性、词频等特征筛选,将问题与背景材料词语进行主题关联;然后,利用Word2Vec进行语义相似度计算,获取扩展主题词;最后,在问题解答过程中,依据问题关联的主题词,与背景材料句子进行相似度计算,从而获取问题的答案句。②语言鉴赏题,针对特定文本,从语言风格、修辞格、隐喻及写作手法等多个角度进行鉴赏,并结合答题模板生成答案。首先,对特定文本,利用基于多任务学习的修辞格及情绪识别方法与基于语义场景不一致的隐喻序列标注方法,分别进行语言技巧识别;然后,依据识别结果及问题包含的语言风格、修辞格及写作手法类别,抽取系统知识库中相应模板,融合生成最终答案。
3 实验与分析
3.1 实验设置
为了对比本文系统与基线模型,我们构建了一个数据集GCRC(A New MRC Dataset from Gaokao Chinese for Explainable Evaluation)[30]。该数据集包含5 000多篇文本、8 700多道选择题(含近15 000个选项)。所有题目均来自近10年的高考测试题,题目质量高,但难度大。具体信息如表1所示。
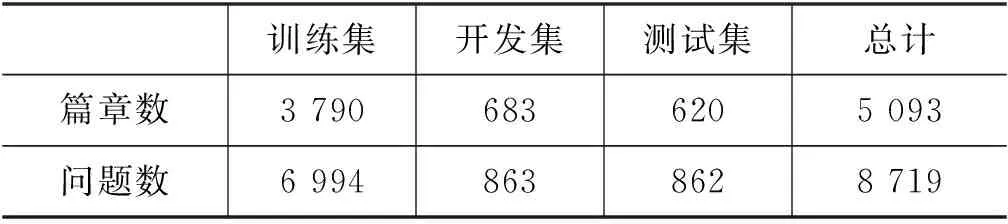
表1 GCRC数据集相关信息
3.2 实验结果分析
3.2.1 选择题总体实验结果
表2在GCRC数据集上对比了本文构建的系统和现有基线模型的答案准确率。与目前性能最优的XLNet相比,本文构建的系统获得了明显的性能提升。
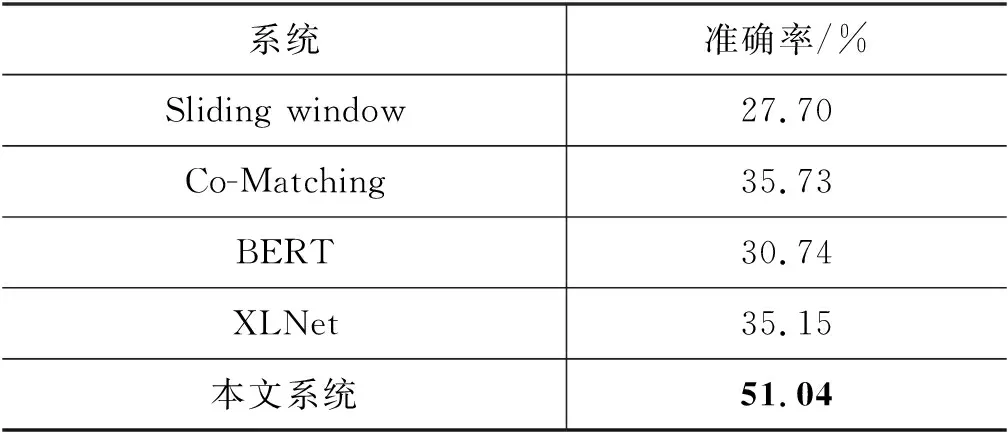
表2 GCRC数据集实验结果
3.2.2 高考科技文与散文具体得分结果
我们还进一步分析了系统在高考科技文和散文阅读理解上的具体得分与表现。
(1) 科技文实验结果分析
表3展示了系统在2016—2020年高考真题及模拟题上的答题效果。现阶段科技文选择题答题引擎在文本细节信息的捕获与理解上效果比较好,如2020年第3题,对“月背遥操作技术五个部分”的理解,选项D“休眠、唤醒: 受月球环境影响,玉兔二号需在每个地球日休息半日、工作半日”,原文信息为“休眠和唤醒与月球的环境有关。月球的一天为 27个地球日左右……为确保安全,在月夜到来之前,需让月球车车体……进入休眠状态”,系统通过分析“地球日”与“月球日”之间的差异,给出问题的答案。现阶段科技文问答题答题引擎能够利用相关句抽取技术从文章中抽取与问题相关的句子,如模拟测试卷E中问答题,“结合以上三则材料,谈谈实施乡村振兴战略需要哪些方面共同努力?并简述各方面所起的作用”,系统总结出三篇材料的核心内容并进行归纳,答案涵盖了实施乡村振兴战略三个方面内容及其作用,与题目要求一致。
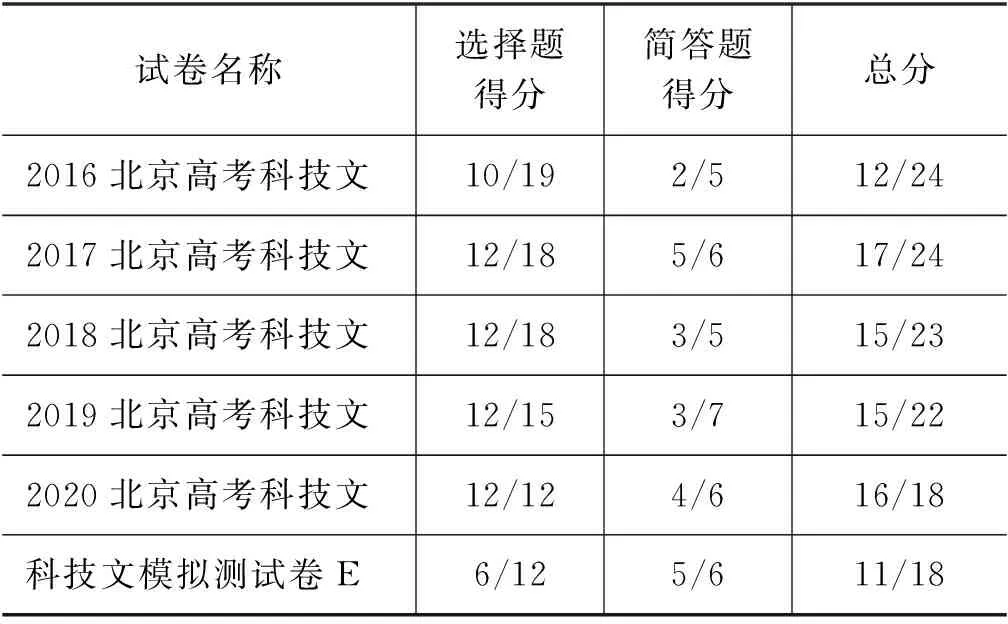
表3 高考语文科技文自动答题系统得分
(2) 散文实验结果分析。
表4展示了系统在2016—2020年高考真题及模拟题上的答题效果。答题系统在散文阅读理解中,具备结合问题从背景材料中筛选信息的能力。如2017年20题选项A“传统的鄂温克人生活在山里,以打猎为生,驯鹿是他们生活、劳动的重要帮手”;2019年20题的简答题,根据题干: 作者为什么说“你在没有走进这些胡同人家之前,关于北京文化的理解,是不便言深的”?请结合上下文具体说明。答题系统可以正确从文中抽取答案支撑句。但是散文文体语言抽象,题目包含对背景材料深度概括、主旨抽取及其语言鉴赏等多种题型。目前系统依赖抽取相关句设计答题模板,针对不同题型给出相应的答案。目前对于高度抽象的选项,涉及主旨概括、标题理解、不常用修辞格鉴赏的简答题,答题结果不尽人意。
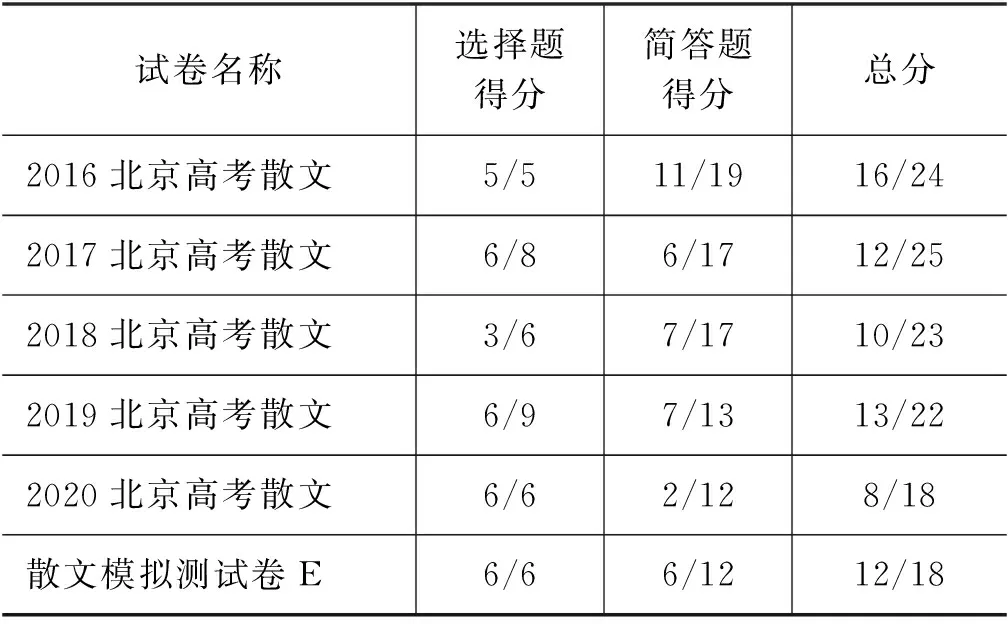
表4 高考语文散文自动答题系统得分
3.3 错误分析
3.3.1 选择题错误分析
通过对回答错误的选择题进行分析,本文将系统回答错误的题目划分为3种类型,如表5所示。
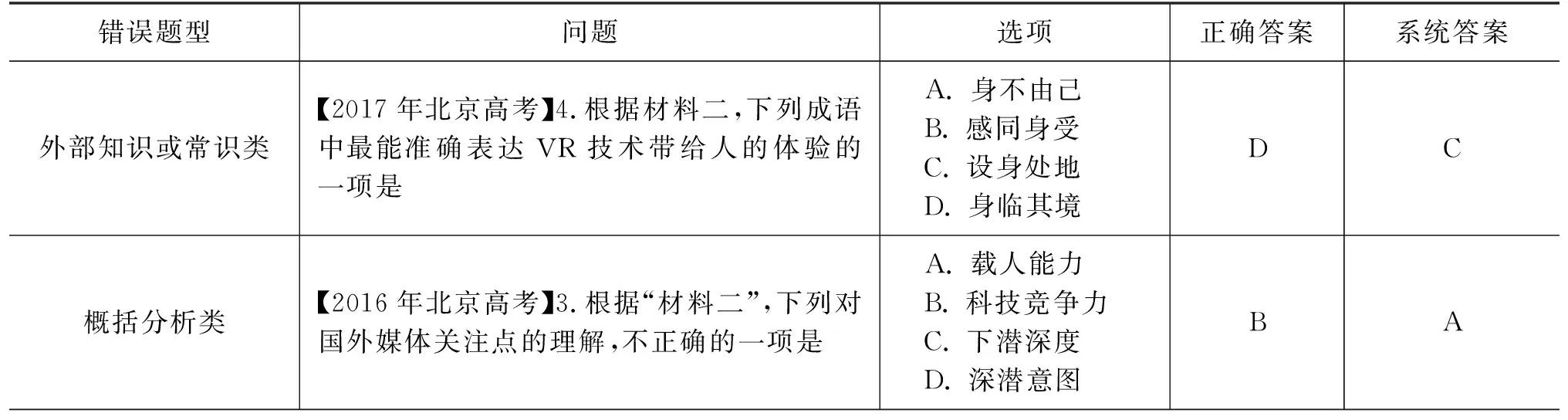
表5 选择题错误题目示例

续表
(1) 外部知识或常识类选项。该类问题需要模型利用外部常识知识,结合文本内容找到符合文章主旨或特定要求的选项。此类题目要求模型具有外部知识理解能力。例如,表5中第1题,需要系统对选项中成语与文本语义对比分析,选出正确答案。由于模型难以正确理解“身临其境”等成语的语义,因此不能正确回答该类题目。
(2) 概括分析类选项。该类题目需要模型对文章有多层次的解读与归纳(如文章主旨、段落大意等)。例如,表5中第2题,需要从文章的2、3、4段归纳出“国外媒体关注点”,然后与选项中内容匹配,选出正确答案。由于模型现有答题流程中缺少对文章层次结构的分析,因此难以回答该类题目。
(3) 时间推理类选项。该类题目需要模型从原文多个事件涉及的时间中推理某个事件的发生时间。此类题目要求模型具有时间推理能力。例如,表5中第3题,需要从“蛟龙号下潜到3759米”的时间“2010年”与“蛟龙号下潜到5 000米”的时间“2011年7~8月”,推理出题干中的“蛟龙号首次下潜到4 000多米”的时间为“2011年”。由于模型尚不具有时间推理能力,所以回答错误。
3.3.2 简答题错误分析
针对系统在高考阅读理解简答题上的解答结果,将其失分原因划分为两种类型。具体示例如下:
问题: 【2017年北京高考】23.文章叙写了玛利亚乌热尔图和走出山林的人们,请分别概括他们各自: 根河之恋的表现。作者这样构思体现了怎样的匠心?
系统答案: 乌热尔图是根河的儿子; 出乎意料的是,乌热尔图后来辞去京官重返故乡; 乌热尔图在回到草原以后的日子里,完成了《呼伦贝尔笔记》等一系列著作和摄影作品,那是他数十载的文化寻根,是他作为一个鄂温克的儿子,对母亲的深情眷恋与报答; 生活在根河的大多数鄂温克人恋恋不舍地告别了山林,将更多的空间留给了无边的草木以及驯鹿、黑熊、狼、灰鼠和蝴蝶; 在离城市不远的一个地方,新建了童话般的家园,这座小城就叫了根河; 走到窗前一看,根河就在眼前,河对面的广场上已经有许多人在翩翩起舞,似乎这个小城的人都聚集在此了。
标准答案:
表现: 玛丽亚索——恬然的生活在鹿群里
乌热尔图——辞去京官重返故乡
走出山林的人们——将更多的空间留给无边的草木和动物,对根河对、自然的挚爱。
匠心: 他们代表了鄂温克人几种典型的生活状态,虽然生活方式和具体做法不同,但是都表现出对根河、对大自然的无限深挚的爱恋。
(1) 系统答案缺乏概括。答题系统抽取出乌热尔图与走出山林的鄂温克人对根河表现的支撑句,但未对其做进一步概括。
(2) 系统未能挖掘深层主旨信息。对于题干“构思体现了怎样的匠心”,系统缺乏对背景材料深层主旨信息的提炼。
4 总结与展望
面向人类的标准化测试是人工智能领域一项长期的挑战性任务。本文针对高考语文阅读理解核心技术与答题系统进行研究,在相关数据集上取得了一定效果,表明系统可以获得一定程度的语言理解与推理能力,但该项研究只是迈向类人语言理解道路上的第一步,未来还需要深入研究更有效的语义表示方法与模型,探索不同类型知识的统一表征与知识聚合方法,探究对抗学习、迁移学习等前沿技术在阅读理解中的应用,促进模型具备融入外部知识的复杂综合推理能力、概括分析能力、语言鉴赏能力。
猜你喜欢
名师在线(2022年16期)2022-11-20
北京航空航天大学学报(2022年8期)2022-08-31
数学小灵通(1-2年级)(2022年6期)2022-06-17
数学小灵通(1-2年级)(2022年5期)2022-06-01
数学小灵通(1-2年级)(2022年3期)2022-03-17
北华大学学报(社会科学版)(2021年4期)2021-11-23
数学小灵通(1-2年级)(2021年3期)2021-04-13
中学生英语·外语教学与研究(2020年6期)2020-08-13
文学教育下半月(2016年5期)2016-06-02
长江学术(2016年4期)2016-03-11
