
基于深度卷积神经网络的海洋多目标涡旋检测方法
2022-07-27 09:13刘启明杨树国
青岛科技大学学报(自然科学版) 2022年4期
刘启明,杨树国,赵 莉
(1.青岛科技大学 数理学院,山东 青岛266061;2.青岛市中医医院(市海慈医院),山东 青岛266033)
涡旋是世界海洋中普遍存在的一种中尺度海洋现象,是指尺度小于罗斯贝波的海水旋转运动的总称,其中半径为第一斜压罗斯贝半径量级(即10~100 km)的涡旋被称为中尺度涡旋;而半径小于第一斜压罗斯贝半径且大于边界层湍流尺度的涡旋被称为次中尺度涡旋(即0.1~10 km)。按照旋转方向可分为气旋涡和反气旋涡,北(南)半球气旋涡中,海水呈逆(顺)时针旋转。无论南北半球,由于地球自转诱导的科氏力,气旋涡(反气旋涡)的中心伴随着辐散(辐聚),所以产生上升流(下沉流)[1]。因此,这些涡旋一方面将海洋深层的冷水和营养盐输送到海洋上层,另一方面也会将海洋表面的暖水输送到海洋深层,通过对水体的混合和运输改变海洋的温盐场结构,进而对海洋动力过程、生态系统变迁及全球气候变化产生重要的影响[2]。因此,对于海洋涡旋检测的研究具有重要的科学意义和实际应用价值。
上世纪以来,国内外众多海洋学者对海洋涡旋的检测问题进行了大量研究,取得了一系列研究进展,提出了诸多检测算法。目前,传统的检测算法主要有基于物理特征、流场几何特征、手工标注特征及混合算法等方法。其中,基于物理特征的Okubo-Weiss(OW)参数法[3-4]深受学者青睐,多应用于地中海海域、秘鲁海域[5-6],它可以较好地将涡旋特征从特定情景场中提取出来,但参数的选取过分依赖于专家经验,并且直接影响检测的精度,因此该方法的检测准确度较低。基于流场几何特征的Winding Angle(WA)缠绕角方法[7],通过计算并筛选流场瞬时闭合曲线的方式对涡旋进行识别,但由于涡旋在形成及消亡过程中往往不具备流场闭合曲线的特征,因此该方法的漏检率较高;类似地,NENCIOLI也提出了一种纯粹基于几何特征的方法(vector geometry,VG)方法[8];这些基于流场几何特征的检测方法都存在共同的缺点,即需要对数据进行逐点检测,再利用流场几何特征进行判断,为了保证涡旋识别的准确率往往致使计算量过大、效率过低。基于手工标注特征的方法一般涉及到的特征比较低级,无法表现出涡旋的高动态性。另外也有一些学者将上述的传统算法加以融合而发展出混合算法,例如YI等提出的基于海表面异常高度和物理特征(OW)参数法的涡旋检测方法[9]、MCWILLIAMS提出的将流场几何特征和相对涡度结合起来的海洋涡旋检测方法[10]。虽然混合算法具有其融合的各个子算法的优点,但是对历史数据的质量要求较高,并强烈依赖于专家经验,因此检测涡旋的效率依旧较低。
近年来,随着深度学习的蓬勃发展,人工智能技术在各领域得到高效应用,学者们开始将传统的方法与深度学习进行结合,取得了卓越成就[11]。例如深度学习通过创建多层神经网络,对训练样本进行拟合,已经被广泛应用于语音、图像的识别和检测等方面[12-13]。同时,伴随着超分辨率遥感卫星技术的快速发展,越来越多的高时空分辨率的海洋表面高度遥感图像数据可以供研究人员使用,已有学者针对海洋涡旋检测的特点,把海洋表面高度数据视为二维图像,结合机器学习和深度学习的方法对海洋涡旋进行检测识别。如ASHKEZARI等[14]通过构建涡旋相位角特征矩阵,利用支持向量机(SVM)进行分类训练,再通过使用滑动窗格进行涡旋检测。LGUENSAT 等[15]在经典的语义分割框架中,利用编码器-解码器网络(U-Net)对气旋和反气旋进行了识别,但没有对语义信息和特征进行充分的利用,缺乏对检测到的涡旋大小等特征进行定量分析。
本工作基于深度学习方法,结合先进的语义分割理论,提出了一个海洋多目标涡旋检测的深度模型,该模型能够有效提取并利用涡旋的语义信息和特征,充分捕捉边缘信息,有效地实现多目标涡旋检测,最后,将本文提出的方法与传统方法进行了对比实验,实验结果表明,本工作的方法性能更优。
1 数据
大量高质量数据是深度学习模型成功训练的重要基础,尽管有学者已经创建了海洋涡旋数据集,但是其中的大多数没有公开发布,相关研究人员无法直接使用,在一定程度上限制了该领域的发展。因此,本研究工作使用哥白尼海洋环境监测服务中心(CMEMS)最新发布的海表面高度卫星遥感数据产品,该产品由Data Unification and Altimeter Combination System(DUACS)多任务融合高度计数据处理系统处理发布,将Jason-3、Sentinel-3A、HY-2A 等运行中的卫星探测的海表面高度(sea surface height,SSH)数据加以集成,再使用最优插值方法计算获得,来自多卫星高度计的融合数据具有很高的时间和空间分辨率,可以为海洋涡旋检测任务提供近实时的卫星遥感数据。
本研究海域为热带西北太平洋海域(0°~32°N、109°E~141°E),包括中国南海及其东部海域(如图1所示)。本研究使用了从2000年1月1日至2021年3月5日的7 735张每日海表面高度图像。
本工作所设计的深度学习算法除了需要给定海表面高度图像外,还需要给定对应的标签图像,然而数据集没有直接给出,因此本工作采用经典的涡旋检测(Py-eddy-tracker,PET)算法[16]来创建标签图像数据,该数据与海表面高度图像共同构成本工作的数据集:其中训练集由前20年的数据构成,共包含7 306张海洋表面高度图像及标签图像;测试集包含2020年1月1日至2021年3月5日的429张海洋表面高度图像及标签图像。图像的空间分辨率为0.25°×0.25°,大小为128像素×128像素,每张图像均为单通道图像。在形成数据集时,为了减少异常数据对结果的影响,对标签图像数据进行了预处理:对于陆地及岛屿区域,将其对应的像素值替换为类别像素值0,对于气旋区域,将其标准像素值替换为类别像素值1,对于反气旋区域,将其标准像素值替换为类别像素值2。由于海洋涡旋是缓慢动态移动的,单个涡旋可以存活几周至几个月[17-18],因此不需要进行数据增强(如向训练集中添加裁剪、旋转后的数据图像)。
2 基于深度卷积神经网络的多目标海洋涡旋检测模型
为了能够更好地提取多个涡旋的特征,以及更高效地融合不同尺度的特征,从而获得更好的涡旋检测效果,本工作基于深度学习方法建立了一个基于深度卷积神经网络的多目标海洋涡旋检测模型。模型的具体结构如图2所示。
该模型由编码和解码两个部分组成[19],其中编码部分主要进行涡旋特征的提取及融合,包含改进后的密集卷积块,以及跨层融合到下采样操作的整个过程;解码部分使用转置卷积进行上采样操作,直到最终检测出涡旋。
2.1 编码部分
本工作所提出的海洋涡旋检测模型的编码部分,是基于改进的密集卷积模块的特征提取器。提取输入的海表面高度图像的涡旋特征后,再通过跨层融合将全部特征融合起来。通过以上操作,不仅能提取到丰富的涡旋特征,还能将不同层次的语义特征和边界细节特征融合起来,捕获到图像更多的全局和局部信息。
具体地,将海表面高度图像输入后,首先进行涡旋特征提取,主要通过基于卷积操作的密集模块完成,具体操作如图3所示。
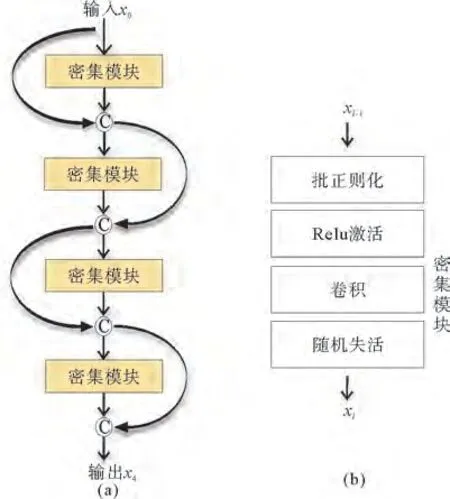
图3 密集模块简图Fig.3 Sketch of the dense module
每个密集模块包含如图3(b)所示的四个层,用来提取输入图像的特征,其原理如下:

其中,H为批正则化、激活、卷积、随机失活等非线性操作,x l为第l层的输出特征图。从输入图像开始,通过第l层密集模块的操作H(·)生成含有k层的输出特征图x l。
密集模块的非线性操作H中,最重要的是卷积操作,其原理如下:
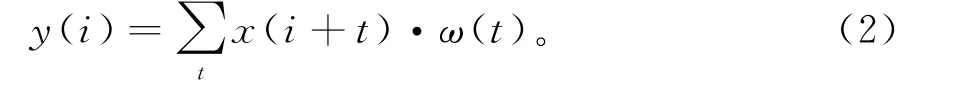
其中,y(i)为输出特征图第i个像素点位置的特征值,ω(t)为卷积核,t为卷积核的长度,x(·)为输入特征图相应区域的特征值。
利用上述过程,对输入图像进行特征提取并生成特征图,之后引入跨层融合来减少卷积过程中的信息丢失,如图3(a)所示。
在下采样中,对密集模块的输入特征图x l-1和输出特征图x l进行级联操作,级联后再进行最大池化操作,使得每个区域内的最大特征得以保留,参数减少,其原理为:

其中,Win,Wout分别表示特征图宽度的输入值和输出值;Hin,Hout分别表示特征图高度的输入和输出值;Cin,Cout分别表示通道数的输入值和输出值;S为步长,K为卷积核的大小。
经过上述特征提取、特征融合及下采样操作,得到的特征图中含有丰富的语义信息,特别是在特征融合过程中,每一层都将之前所有层的输入进行融合,再传递给之后的所有层,这样的跨层融合结构具有众多的优势,尤其是提高了特征的重用,每一层都可以得到前面各层的特征信息,参数的重用率更高,各层的有效特征全部进行了融合,可以充分利用涡旋的细节特征以及空间特征。
本工作输入SSH 图像大小为128×128,采用2×2最大池化,选取k=12,输入图像经过特征提取、特征图融合及下采样操作后,模型的编码工作全部完成,得到了充分提取、高度融合的海洋涡旋特征图,为解码工作提供了丰富的特征信息,有助于获得更加精准的涡旋检测结果。
2.2 解码部分
当全部特征提取及融合完成后,解码部分负责将融合后的特征图还原到输入分辨率大小,逐步还原后经交叉熵损失Soft Max分类,得出海洋涡旋检测的具体结果。首先进行特征图尺寸的恢复,也就是将编码部分得到的特征图经解码操作变成输入图像原始尺寸大小。然后进行编码解码操作,编码部分通过构建下采样路径来获得特征图,解码部分则是一个相反的过程,通过构建一个上采样路径来使提取到的特征图逐步恢复空间分辨率,主要由上采样操作(转置卷积或反卷积操作)和跳过连接组成。下采样和上采样的主要操作如图4所示。

图4 下采样和上采样过程Fig.4 Downsampling and upsampling process
当编码部分完成特征提取后,上采样操作开始工作,并且和对应的跳过连接进行通道上的融合,以此增强特征图的空间分辨率,形成新的输入。由于下采样过程中的池化操作会在一定程度上损失有效特征信息,引入跳过连接则能保留原来大量的信息,可改善特征提取到上采样操作过程中的信息丢失,这对于海洋涡旋检测任务来说十分必要。
特征图还原完成后,最后一步就是使用Soft Max分类得到海洋气旋(类别1)、反气旋(类别2)和背景(类别0)3类的概率,即每个类别的最终结果。
本工作所用的训练样本为{(x(i),y(i))},i=1,…,n,类标签为y(i)∈{0,1,2},使用Soft Max函数计算样本属于每个类别的概率:
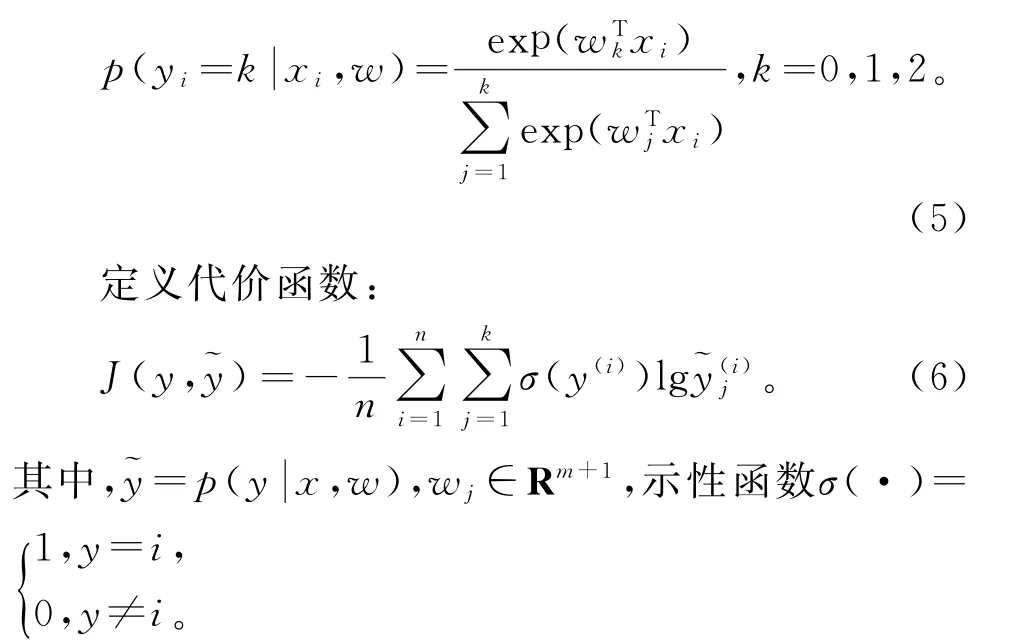
通过梯度下降法求得损失函数极小化后的权重系数w,最大概率~y对应的类别即x的分类类别,即得到每个像素所对应的涡旋类别。
解码部分以编码部分的输出特征图x16作为输入,经过上述3次上采样操作及通道融合后,特征图大小变为输入海表面高度图像大小128×128,再经过Soft Max分类后,输出海洋涡旋检测的结果,即得到分割图像。至此,解码工作全部完成,也获得整个海洋涡旋检测结果。
3 模型训练设置
3.1 模型损失函数与优化
深度学习多分类任务通常采用交叉熵函数作为损失函数进行训练,针对海洋涡旋检测任务的正负样本不均衡的特点,本工作使用改进的加权骰子系数作为损失函数,加速网络的训练。
骰子系数通常用来度量两个样本之间的相似度,一般定义为

其中,Dice i(i=1,2,3)分别表示气旋、反气旋和背景的系数,w i(i=1,2,3)则分别表示三者对应的权重。
3.2 模型超参数设置
在本工作采用的数据集中,训练集包括的训练样本有7 306张图片,验证集包括的验证样本有471张图片。由于数据样本量充足并且排除参数设置的影响,本文模型以及其他对比模型的参数设置完全相同,采用Adam 优化器,训练批次epoch 设置为50,学习率设置为0.001,训练的批数batch size设置为6。为了避免过拟合现象的产生,采用了归一化层和神经元保留比例为80%的Dropout层。模型的整个训练过程需要7 h左右,同样实验条件下,本工作模型训练集的精度达到94%,比Eddy Net算法精度提高了4个百分点,在验证阶段相对于其他模型也表现出更好的性能。
4 实验结果
为了检验本工作提出方法的涡旋检测效果,在上述数据集上,对不同的方法Eddy Net、PET 和本工作的方法进行了对比性实验,检测结果如图5所示(图中红绿色块分别代表反气旋涡和气旋涡):

图5 不同检测方法结果对比Fig.5 Comparison of the results of different testing methods
从图5可以看出,本工作方法的结果与PET 方法更为相似,因为本工作的模型是由其结果训练的,但是与Eddy Net方法相比,本工作的方法检测到了更多的涡旋,尤其是对于边缘区域小而模糊的涡旋,也能精确地捕捉到这些信息和特征。
由于受专家经验及筛选条件严格的限制,传统方法的漏检率较高,而人工智能的方法由于能够检测到更小的涡旋,因此比传统方法检测到的涡旋数量更多。图6为2020年1月1日至2021年3月5日南海及其附近海域这两种方法检测到的海洋涡旋数量比较。在此期间,Eddy Net 算法共检测到49 752个海洋涡旋,本算法共检测到68 726个海洋涡旋,并且本算法检测到的气旋和反气旋的数量均比Eddy Net算法检测到的多(见表1),两个结果之间的单日最大差为64。
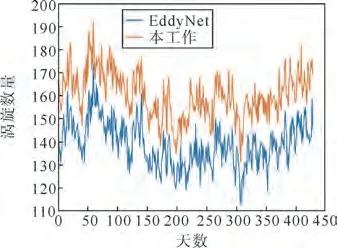
图6 两种方法检测出的2020年1月1日至2021年3月5日的海洋涡旋数量对比Fig.6 Comparison of the number of ocean eddies detections by the two methods during Jan 1st,2020 and Mar 5th,2021
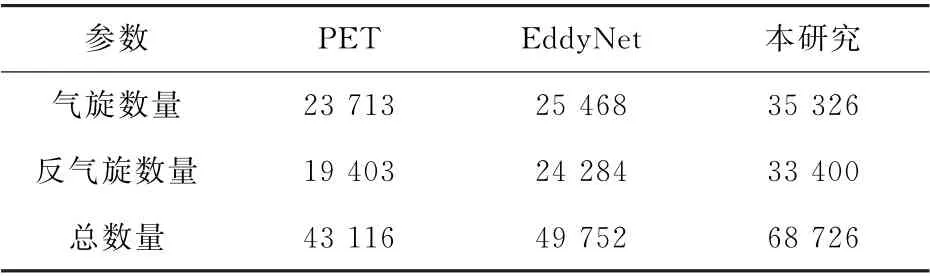
表1 不同方法检测到的海洋涡旋数量统计Table 1 Statistics on the number of ocean eddies detected by different methods
本方法加强了对特征的重用,提高了特征的利用效率,因而能够获取涡旋的更多细节特征,尤其是对于检测区域边缘特征的利用更加高效,因此能够准确区分开相隔较近的多个涡旋,如图7所示,Eddy-Net算法和本方法在对气旋检测结果的对比中,本方法检测效果更加接近真实情况,如图7(c)地转流图所示,尤其是对于相隔较近的两个涡旋的检测,本方法能够更好地将其分离和检测出来。衡量海洋涡旋检测性能的另一个指标就是半径大小,因此本工作对比了所检测海域的涡旋半径大小,如表2所示,这是两种方法对涡旋半径进行了5次计算并求得平均值的结果,本工作所提出的方法检测到的涡旋平均半径和最大半径都更大,而最小半径更小,这同样也验证了本工作方法具备检测到更小涡旋的能力。
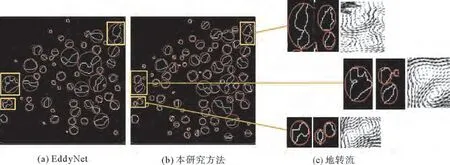
图7 不同检测方法结果对比Fig.7 Comparison of the results of different testing methods
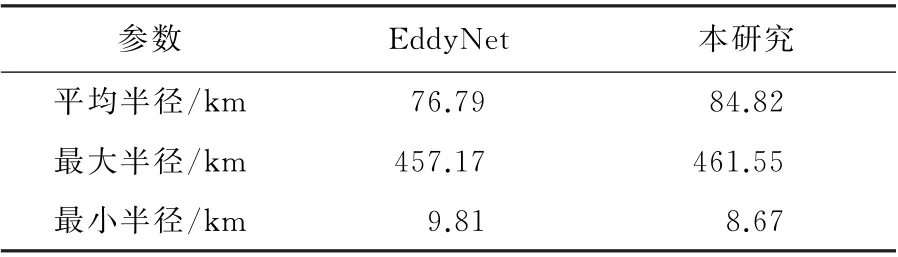
表2 不同方法检测到的海洋涡旋半径统计Table 2 Statistics on the radius of ocean eddies detected by different methods
5 结 语
本工作所提出的海洋多目标涡旋检测算法能够捕捉到多涡旋的丰富细节特征,融合了深层次的语义信息,适合海洋多涡旋检测任务。同时,本工作利用2000 年至2020 年的海表面高度图像数据和PET 算法提取的涡旋信息标签作为训练数据,2020年1月1日至2021年3月5日的429张海洋表面高度图像作为测试数据,对本方法与传统算法PET以及Eddy Net算法进行了比较,结果表明,本算法能够检测到更多的海洋涡旋,特别是对于小尺度边缘涡旋的捕捉,效果更优。因此,本工作所提出的方法更适合海洋多目标涡旋检测。
猜你喜欢
装备制造技术(2022年6期)2022-10-02
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年7期)2022-08-06
中国海洋大学学报(自然科学版)(2022年6期)2022-06-03
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
琴童(2017年7期)2017-07-31
小学科学(2017年5期)2017-05-26
国外科技新书评介(2009年1期)2009-03-10
