
短文本聚合在元器件供方匹配中的应用与研究
2022-08-02 01:44魏自强班元郎王文玺
计算机技术与发展 2022年7期
魏自强,班元郎,徐 伟,王文玺
(贵州航天计量测试技术研究所,贵州 贵阳 550009)
0 引 言
工业化和信息化的深度融合,信息技术在军工企业产业链中的应用越来越广。简洁的短文本,已然成为适应人们快速高效工作的信息载体[1]。例如元器件供方简称就常作为供方名称的短文本替代出现航天各个业务系统中。由于航天元器件信息来源于ERP、TDM等多个平台,其中元器件的厂商名称即供方名称是定义唯一一个元器件的标准之一。但各系统的供方定义标准不同、不同人员对供方数据的理解不同导致同一条供方数据出现多条不同的记录。最终导致在采购流程中,不同业务部门所提交的采购单中同一元器件供方信息数据出现不一致的情况。因此,在采购流程中,对供方数据和合格供方目录进行匹配是必要步骤之一。
供方数据和合格供方目录都是短文本数据。供方数据匹配可以看作是文本匹配问题。在对现有的Jaro-Winkler算法以及Levenshtein(编辑距离)算法进行测试后,发现这两个算法在供方匹配应用中有各自的优势,但都不能很好地满足供方匹配需求。该文根据供方数据的特征,将Jaro-Winkler算法与Levenshtein(编辑距离)算法进行结合与改进。改进的算法结合了两种算法的优势,在计算元器件供方名称与合格供方目录的相似度时,提高了匹配的准确率,满足了供方匹配应用的需求。
1 研究现状
1.1 短文本聚合模型
加入短文本聚合模型的定义(1到2句话)在短文本聚合模型中,采用相似度算法对文本进行相似度匹配。计算两个字符串相似度算法主要可分三类[2]:基于字面、基于语义、基于统计关联的相似度算法。基于字面的相似度算法有编辑距离的方法和相同字或词的方法,代表性的有Jaro-Winkler[3-4]、Levenshtein[5-6]算法、最长公共子串算法[LCS][7-8]、余弦相似度算法[9]。文献[10]通过计算前后非相邻字符间的交换操作,改进了编辑距离算法,实现了编辑操作的最小化。
1.2 Jaro-Winkler算法
Jaro-Winkler算法是用来计算2个字符串的相似度,由Jaro改进而来。该算法适合计算两个较短的字符序列的相似度,运算结果在0到1范围内。0表示完全不匹配,1表示完全匹配[11],运算的值越大表示相似度越高。
(1)Jaro算法。
(1)
其中,|s1|和|s2|分别为字符串s1和s2的字符串长度,m为匹配字符串个数,t为换位数目。
(2)匹配窗口MW(matching window)计算公式:
(2)
其中,|s1|和|s2|分别为s1和s2的字符串长度,当字符串s1中的一个字符在字符串s2中,但位置不同,需要换位操作时,如果这2个字符的距离小于等于MW,则表示这两个字符为匹配字符。统计所有能匹配的字符的所有换位操作数,记为tj,则换位的字符数目t,记为:
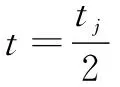
(3)
(3)Jaro-Winkler计算公式。
Jaro-Winkler算法的相似度计算公式为:
dw=dj+(lp(1-dj))
(4)
式中,p范围为(0~0.25),默认值为0.1;l是字符串s1和s2的前缀部分匹配长度。
1.3 Levenshtein(编辑距离)算法
编辑距离于1965年被提出[12],编辑距离[13]是由原字符串S转换成目标字符串T最少需要进行的编辑操作次数。编辑操作包含3种操作,分别是字符的替换、添加、删除,这3种操作次数的总和记为这2个字符串的编辑距离。编辑距离越小,相似度越高。
设字符串S=s1s2…sm,T=t1t2…tn,建立S和T的(m+1)×(n+1)阶匹配关系矩阵LD:
LD(m+1)×(n+1)={dij}(0≤i (5) 按公式(6)初始填充矩阵LD: (6) 其中, (7) 矩阵LD,右下角元素dm,n即为字符串S和字符串T之间的Levenshtein距离,也叫编辑距离,记为ld。 根据编辑距离ld,定义字符串S和T的相似度为[14]: (8) 式中,Sim为最终的相似度计算结果。越相似的2个字符串,Sim的值将越大。 供方数据主要来源于贵州航天计量测试技术研究所的ERP、TDM等系统。在对多源数据进行汇集后,发现同一供方的名称数据有大量不一致的情况。 在航天元器件数据中,元器件供方名称和合格供方名称存在不一致问题,典型特征如下: (1)合格供方名称和元器件供方名称,存在全称和简称情况。例如“中国电子科技集团有限公司第四十九研究所”和“中电四十九所”,“天水天光半导体有限责任公司”和“天水天光”。 (2)合格供方名称和元器件供方名称,存在总公司和子公司信息。例如“易讯科技股份有限公司”和“易讯科技股份有限公司哈尔滨分公司”,“中国航天科工集团有限公司”和“中国航天科工集团第二研究院”。 (3)合格供方名称和元器件供方名称,一个可以区分类别词、一个没有,例如“施耐德电气有限公司”和“施耐德”。 (4)合格供方名称和元器件供方名称相似但不是同一家公司。例如“中国航天科工集团有限公司”和“中国航天科技集团有限公司”。 (5)合格供方名称和元器件供方名称相似,但类别词不同。例如“深圳海瑞达电子有限公司”和“深圳海瑞达时频设备有限公司”。 (6)合格供方名称和元器件供方名称字面很相似,但顺序不一致。例如“联创电子有限公司”和“创联电子有限公司”。 前三种情形为正例,名称有差异,但是应该匹配成功。后三种情况为反例,名称相似,但不应该匹配成功。 Jaro-Winkler算法中缺乏对相同字符在原字符串中的间隔问题的考虑[14],因此对相对相似的两个名称不能够有效地拒绝匹配,对于前缀部分相同的两字符,Jaro-Winkler匹配效果相对比较好。因此Jaro-Winkler算法对特征(4)中的名称很相似的不同公司,错误的匹配成功;对特征(6)中公司名称明显错位,但依然匹配成正例。 Levenshtein算法对2个字符串的长度、位序等相对比较敏感,因此对相似的反例能较准确匹配,而对长度差异相对较大的正例易出现匹配错误。因此Levenshtein算法对特征(4)到(6)的反例,容易匹配正确;因为全称和简称、总公司和子公司字符串的长度差异大,因此容易对特征(1)到(3)的正例拒绝匹配。 由于Jaro-Winkler算法能对前缀部分相同的字符串加分,因此Jaro-Winkler相似度算法对正例匹配效果比较好,但对字符位序、对相同字符之间的间隔没有处理,所以对反例的匹配效果并不好。而Levenshtein算法考虑了字符串的长度、位序等情况。因此,考虑通过引入调整阈值及系数融合Jaro-Winkler和Levenshtein算法,以提高整体的匹配正确率,计算公式如下: ana=∂dw+βsim (∂+β=1) (9) 其中,dw为Jaro-Winkle算法计算的距离,sin为Levenshtein算法计算的相似度。 采购单中的元器件数据来源于不同系统,而不同系统中的元器件供方名称的字段长度、类型存在不一致的问题。在对供方名称进行处理时,先对数据进行清洗能有效提高匹配正确率。数据清洗的对象主要是相似的记录、异常值等。以建立供方名称映射表方式,在不改变原始数据的情况下对供方名称进行清洗。映射表部分数据如表1所示。 表1 供方名称映射表部分数据 在匹配供方数据时,供方名称中的部分后缀文本属于冗余数据,如有限公司、研究院等。这些冗余数据在匹配过程中会影响匹配的准确率。通过建立停用词表,可减少冗余数据对匹配准确率造成的干扰。在匹配供方时,去除供方和合格供方名称中的停用词,可有效提升匹配的正确率。通过对供方数据的分析与梳理,构建了停用词表。停用词表部分数据如表2所示。 表2 停用词表部分数据 续表2 首先对TDM、ERP等系统数据进行抽取,在将供方数据汇集到数据仓库过程中,对相似的、异常的供方名称值进行标记,形成供方名称映射表。采购部门用户导入采购单,系统对采购单进行分解,提取供方数据。然后系统对供方和合格供方数据按照供方名称映射表进行清洗。清洗完成后对供方和合格供方数据进行停用词处理。处理停用词后,利用改进的算法对供方和合格供方进行匹配。最后利用堆排序,对每个供方选择出匹配度最高的5个合格供方,供专业人员对其进行判断,如图1所示。 图1 合格供方匹配过程 在进行供方匹配时,需要针对供方名称和合格供方名称按照相似度算法计算相似度,然后将结果与一个选择设定的相似度阈值进行比较,如果大于阈值,则认为该供方为合格供方,否则,判定为不合格供方。文献[1]对Jaro-Winkle和Levenshtein的最优阈值进行了分析,其中Jaro-Winkle的最优阈值为0.709,其精确率为85.9%,Levenshtein的最优阈值为0.662,其精确率约为62.2%。因此设定改进算法的阈值为Jaro-Winkle的最优阈值和Levenshtein的最优阈值的平均值0.68。 为了确定∂与β的值,随机从供方数据集中抽取三组数据,每组数据有100条数据,计算每组数据在不同∂与β值情况下的相似度。调整∂的步长为0.1,0<∂<1,∂+β=1。当∂=0.6,β=0.4时供方最高相似度多数在0.6至0.8之间,如图2所示。 图2 相似度-阈值曲线 对三组数据精确率进行判断,其中第一组数据中62个正例58个匹配正确,38个反例28个拒绝匹配;其中第二组数据中66个正例60个匹配正确,34个反例28个拒绝匹配;其中第三组数据中58个正例51个匹配正确,42个反例34个拒绝匹配;三组平均精确率为86.3%。因此改进的算法阈值设定为0.68,系数设定为∂=0.6,β=0.4时,精确率略高于Jaro-Winkle算法,如表3所示。 表3 改进算法的匹配情况 在业务系统中测试合格供方匹配功能,结果如图3所示。用户导入的采购单中有500条随机选取供方数据。导入完毕后系统自动进行匹配工作,匹配结果正确率相对较高。因此,改进的算法能够很好地完成合格供方匹配。 图3 合格供方匹配 建立供方名称清洗表、停用词表,基于Jaro-Winkler算法并对其改进,改进后算法能很好地实现供方名称和合格供方名称的匹配,实现批量合格供方匹配的自动化,能极大地提高匹配效率,有助于航天元器件的采购工作,有效保证航天元器件的可靠性。2 改进Jaro-Winkler算法
2.1 供方数据特征
2.2 算法改进
3 改进算法在航天元器件合格供方中的应用
3.1 供方名称清洗及映射

3.2 建立停用词字典


3.3 合格供方匹配过程

3.4 阈值及系数的确定
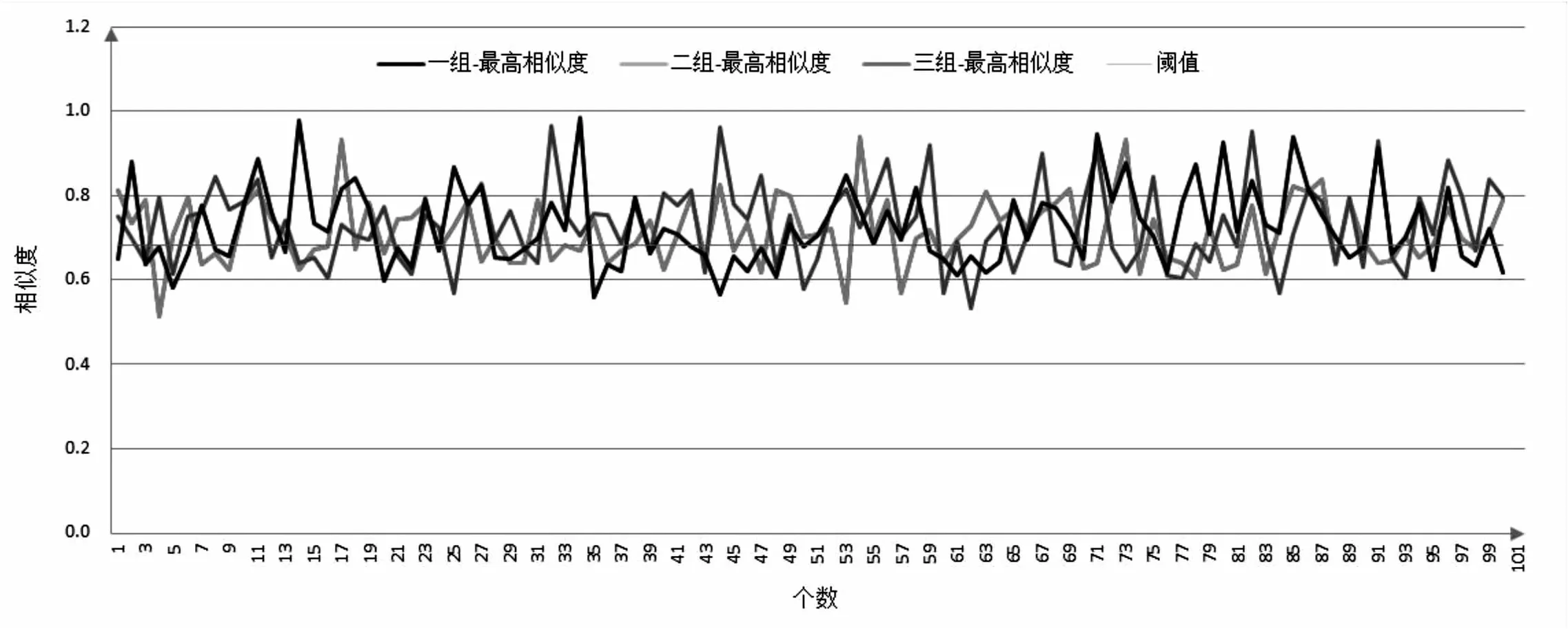

3.5 合格供方匹配结果分析
4 结束语
猜你喜欢
航天工业管理(2022年4期)2022-05-21
导弹与航天运载技术(2022年2期)2022-05-09
航天制造技术(2022年1期)2022-03-07
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
数字技术与应用(2017年3期)2017-05-17
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
中国信息技术教育(2015年21期)2015-09-10
