
一种句袋注意力远程监督关系抽取方法
2022-09-06 13:17张水晶陈建峡吴歆韵
计算机应用与软件 2022年8期
张水晶 陈建峡 吴歆韵
(湖北工业大学计算机学院 湖北 武汉 430068)
0 引 言
随着人工智能技术在社会各个领域中的广泛应用,利用信息抽取技术对课程教学资料进行关键信息抽取从而构建课程学习的知识图谱,是当前课程信息化建设的研究热点。其中,关系抽取是信息抽取技术的重要环节,它是指对文本信息建模自动抽取出实体对之间的语义关系,提取出有效的语义知识,是知识图谱构建中极为关键的部分[1]。
近年来,深度学习的发展为实体关系抽取任务提供了有力的支持,根据数据集标注量级的差异,深度学习的实体关系抽取任务分为有监督和远程监督两类[2]。有监督的学习方法能够抽取有效的实体关系,其准确率和召回率都很不错,但是这类方法对标注数据十分依赖,而标记数据耗时耗力。文献[3]提出了远程监督(Distant Supervision)的思想,即如果两个实体并含某种关系,则涉及这两个实体的所有句子都表示该关系,可以自动生成训练关系提取模型的数据。
基于深度学习的远程监督方法主要是改进的CNN、RNN、LSTM等网络结构[4-5],如PCNN与多示例学习的融合方法[6]、PCNN与注意力机制的融合方法[7]等。文献[8]提出基于句子层的注意力机制和实体描述,降低了噪声问题并且获得了不同句子中的语义信息。文献[9]提出词语注意力机制的关系抽取模型,可以在降噪的同时提高关系抽取的准确性。Fan等[10]通过矩阵分解补全方法解决稀疏及噪声的问题。2019年,Craven等[11]提出弱监督机器学习思想抽取蛋白质与基因之间的关系。但是,远程监督方法容易带来多实例多标签问题,若知识库不完备,更会带来知识库缺失的噪声问题。同时,对于特定领域的实体关系抽取,这些研究方法还需要解决领域知识库的构建问题。
面对课程教学领域的知识点关系抽取问题,本文研发了基于句袋注意力的远程监督关系抽取模型DSRE-SBA(Distant Supervised Relation Extraction Model based on Sentence Bags Attention),利用统计学、深度学习方法抽取课程知识点的关键词,通过领域实体优化得到知识点实体,用基于远程监督的袋内袋间注意力机制[12],对得到的大量训练数据降噪,然后将降噪过的数据送入基于实体注意的Bi_LSTM(Bidirectional LSTM Networks with Entity-aware Attention using Latent Entity Typing)[13]进行关系抽取。
1 远程监督关系抽取简介
如图1所示,基于远程监督的实体关系抽取的基本步骤分为:1) 启发式匹配;2) 特征提取;3) 训练分类器[14]。

图1 基于远程监督的实体关系抽取流程
1) 启发式匹配。启发式匹配的假设条件为:如果知识库中的某两个实体具有某一种关系,则包含这两个实体的所有句子都可以表达这种关系[3]。通过该假设条件,知识库与文本集之间建立联系,并生成标注好的训练数据。
2) 特征提取。特征提取现有的方法主要是基于特征方法和神经网络方法。基于特征方法的方法使用外部的NLP工具来提取特征。神经网络方法主要分为CNN和RNN。目前较为常用的是基于CNN优化的PCNN网络。
3) 训练分类器。通过特征提取获取训练数据的特征表示。特征数据作为分类器的输入,对分类器的中的参数进行训练。通常使用Softmax层作为分类器进行输出。
基于远程监督的关系抽取结果往往含有大量的噪声,主要包含三个方面:多实例问题、多标签问题以及知识库缺失问题。多实例问题是某些标签语句并没有表达实体之间的标签关系。多标签问题则是指知识库中的多个关系标签可能出现在同一个实体对里面。知识库缺失问题是指一个句子中的实体对呈现了某种关系但是在知识库中并不存在,因此被打上NA标签。
2 DSRE-SBA关系抽取模型
本文研发了基于句袋注意力的远程监督关系抽取模型DSRE-SBA,主要思想是:用远程监督的思想从课程知识库匹配外部朴素文本,形成大量带有噪声的训练数据,通过词向量与位置向量构造句子特征,利用袋内袋间注意力机制降低错误标签的权重来对数据进行降噪。降噪后的数据通过词向量与自注意力机制构造文本特征,捕捉到上下文语义信息,输入到Bi_LSTM模型,训练关系抽取器。最终用训练好的模型进行课程知识点关系抽取。DSRE-SBA关系抽取模型包括五个部分:数据获取、课程知识实体抽取、构建大量训练数据、数据降噪、关系抽取。模型原理如图2所示。

图2 DSRE-SBA模型框架
2.1 课程知识实体抽取
本文采用开源中文分词工具Jieba进行分词,并且利用NLPIR中文停用词表,加入计算机主题类词汇构造自己的分词词典。然后,使用TF-IDF算法、TextRank算法和Word2vec词聚类对已经分词的文本进行课程知识实体关键词抽取。
2.1.1TF-IDF算法
TF-IDF作为一种统计方法,用于评估一个文档或语料库中单词的重要性[15]。虽然文档中每个单词的重要性与该单词出现在文档中的次数成正比,但是与单词在语料库中出现的频率成反比。TF(Term Frequency)即词频表示某个单词在文档中出现的频率。其计算公式为:
(1)
式中:m表示该单词在某篇文档中出现的次数;n表示文本包含的总次数。
IDF(Inverse Document Frequency)表示逆文档频率,是衡量单词普遍性的标准。一个词语越常见,其IDF值就越大。其计算公式为:
(2)
式中:N表示语料库中的文件总数;M表示包含该词语的文件数目。最后,计算TF与IDF的乘积:
TF_IDF=TF×IDF
(3)
2.1.2TextRank算法
TextRank算法是一种来源于PageRank算法的图形化文本排序算法[16]。TextRank将文本划分为若干组成单词或句子单元来建立图形模型,通过投票机制对文本的重要部分进行排序。只有单个文档自己的信息才能用于提取和抽象关键字。TextRank可以表示为有向加权图G=(V,E),V是点集,E是边集。对于给定点Vi,权值得分定义为:
(4)
式中:In(Vi)是指向Vi的一组点的集合;Out(Vj)是节点Vj指向的所有节点的集合;d是阻尼系数,范围从0到1;Wji表示节点Vj到Vi的边权重。
2.1.3Word2vec词聚类算法
Word2vec模型采用一个三层的神经网络,分为输入层、隐藏层和输出层。通过训练大规模的语料数据,将训练文本中的词映射到一个n维空间,并使用一个低维的、稠密的词向量来表示词语,使用向量距离来计算词之间相似度,该模型可以很好地提取词语的语义信息,语义接近的词在向量空间具有相似的向量表达[17]。其误差平方和准则函数计算如式(5)所示。
(5)
式中:E表示样本空间中所有数据点到聚类中的平方误差的总和;p表示数据对象;Ci表示第i个类簇;mi表示第i个类簇的平均值。
Word2Vec词聚类文本关键词抽取方法的主要思路是对于用词向量表示的文本词语,通过K-Means算法对文章中的词进行聚类,选择聚类中心作为文章的一个主要关键词,计算其他词与聚类中心的距离即相似度,选择topN个距离聚类中心最近的词作为文本关键词,而这个词间相似度可用Word2Vec生成的向量计算得到。
2.2 PCNN特征提取
本文采用PCNNs的神经网络结构自动学习文本特征,代替复杂的人工构造特征和特征处理流程。图3是PCNN的模型框架图。

图3 PCNN模型框架
2.2.1向量表示
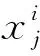
2.2.2卷积层
通过卷积层,可以提取句中的每个局部特征,并且把所有的特征融合到一起,从而实现全局的预测。卷积值是权重向量w和输入向量之间的运算,假设滤波器的窗口为l,则w∈Rm(m=l×d)。给定S为序列{q1,q2,…,qs},其中qi∈Rd。一般来说,qi:j指的是qi与qj的串联。一个滤波器的第j个部分可表示为:
cj=wqj-w+1:j
(6)
索引j的取值范围从1到s+w-1。
捕获不同特征的能力通常需要在卷积中使用多个滤波器(或特征映射)。假设使用n个滤波器(W={w1,w2,…,wn}),卷积运算可以表示为:
cij=wiqj-w+1:j1≤i≤n
(7)
卷积的结果是一个矩阵C={c1,c2,…,cn}∈Rn×(s+w-1)。图3显示了在一次卷积中用3个不同的滤波器的例子。
2.2.3分段最大池化
由于语句的长度会随着不同的表达方式会发生变化,PCNN神经网络利用最大池化层,使得抽取到的特征与句子长度无关。输入句可以根据两个选定的实体分为三个部分,它将返回每个段中的最大值,而不是单个最大值。如图3所示,由实体1和实体2将每个卷积滤波器ci的输出分成三段{ci1,ci2,ci3}。分段最大池化过程可表示为:
pij=max(cij) 1≤i≤n,1≤j≤3
(8)
对于每个卷积滤波器的输出,可以得到一个三维向量pi={pi1,pi2,pi3}。然后把所有的向量p1:n连接起来,应用双曲切线非线性函数,如式(9)所示。
g=tanh(p1:n)
(9)
式中:g∈R3n。最后,为了计算每个关系的置信度,特征向量g被输入到Softmax分类器中。
2.3 句袋注意力模型
句袋注意力模型SBA(Sentence Bags Attention)将远程监督提供的训练数据分为多个袋组,每个袋组包含带有相同关系标签的多个袋子,每个句袋(bag)包含一个实体对共现的所有句子[19]。使用基于相似度的袋间注意模块,通过对袋加权计算来表示袋组。使用一种基于关系感知的方式计算每个袋中句子的权重来表示一个袋,初期将其中嘈杂的句子设置为较小的权重。

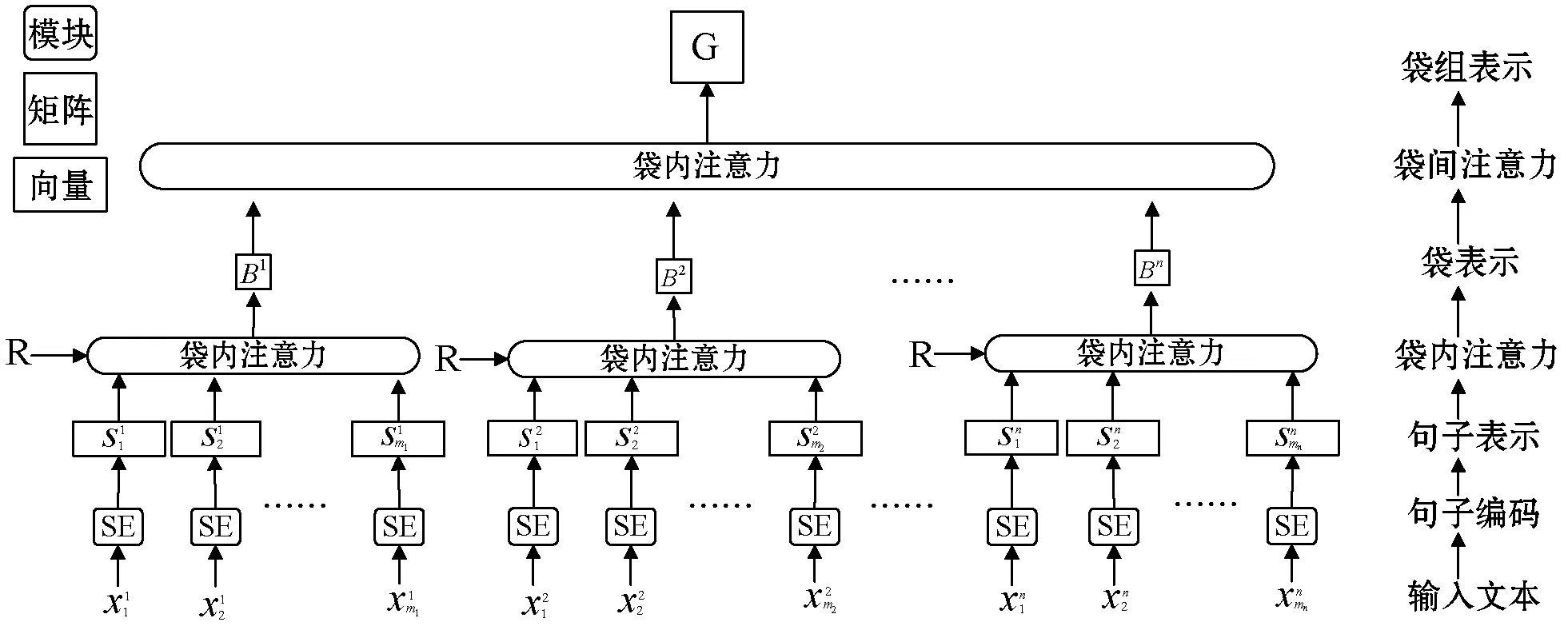
图4 句袋注意力模型框架
2.3.1袋内注意力
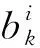
(10)

(11)

(12)
式中:rk是关系嵌入矩阵R2的第k行。最后,袋bi的表示在图4中组成了矩阵Bi∈Rh×3dc。
2.3.2袋间注意力
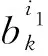
(13)
式中:gk是图中矩阵G∈Rh×3dc的第k行,k是关系索引,βik构成注意力权矩阵β∈Rn×h。每个βik被定义为:
(14)
式中:γik描述了袋bi与第k个关系的置信度。
在自我注意算法[20]的启发下,利用向量本身计算一组向量的注意权重,根据袋子本身的向量表示计算袋子的权重。γik被定义为:
(15)
其中相似性函数是一个简单的点积,被定义为:
(16)
然后,通过gk和关系嵌入向量rk来计算将袋组g被分为关系k的得分ok。
(17)
式中:dk是一个偏置项。最后,利用一个Softmax函数得到袋组g被归类为第k类关系的概率。
(18)
式(12)和式(17)所用的关系嵌入矩阵R是相同的。另外,在袋表示Bi中使用Dropout方法以防止过度拟合。
2.4 基于实体感知关注的Bi_LSTM
本文采用了基于实体感知关注的EA-Bi_LSTM(Bidirectional LSTM Networks with Entity-aware Attention)模型对课程知识点进行关系分类,该模型是文献[13]提出的端到端递归神经模型,它结合了一种具有潜在实体类型(Latent Entity Typing)的实体感知注意机制。基于实体感知的注意力使模型集中在最重要的语义信息上,EA-Bi_LSTM模型框架如图5所示。

图5 EA-Bi_LSTM框架
实体感知注意的三个特征包含:(1) Bi_LSTM的隐层状态H={h1,h2,…,hn}。(2) 相对位置特征。(3) 具有LET的实体特征。如式(19)-式(21)所示。
(19)
(20)
(21)
1) Bi_LSTM的隐层状态。对应于实体对的位置,Bi_LSTM的隐层状态是表示实体的高级特征,用hei∈R2dh表示,其中ei表示实体的索引。
2) 相对位置特征。位置感知注意被作为更有效地使用相对位置特征的一种方法[21]。它是一种注意力机制的变体,它在计算注意力时不仅使用了Bi_LSTM的输出,而且也使用了相对位置特征。

3) 具有潜在类型的实体特征LET。由于实体对是解决关系分类任务的有力提示,所以单是实体的类型就可以推断出近似关系。因此将实体对及其类型加入注意机制,能够有效地训练一个句子中实体对和其他词语间的关系。由于没有给出标注类型,通过潜在类型聚类(一种通过问答对排序方法得到文本主题的方法)来得到LET[22]。基于注意机制,LET通过加权K个潜在类型向量来构造实体类型的表示。数学公式如下:
(22)
(23)
式中:ci是第i个潜在类型向量,K是潜在实体类型的数量。
综上,实体特征是通过Bi_LSTM隐藏状态、相应的实体位置和实体对的类型来构造的。经过实体特征的线性变换,它们与Bi_LSTM层的表示相加,如式(19)所示。并且句子z的表示由式(19)-式(21)得到。
3 通用数据实验结果与分析
本文选取了部分远程监督纽约时报(NYT)数据集,从中选取了包含13种关系的5 000条数据,通过本文的句袋注意力模型进行降噪,然后将降噪后的数据集送入CNN、Attention-Bi_LSTM和Attention-Bi_LSTM+LET等3种关系抽取模型进行比较,采用k-折交叉验证方法对模型进行调优,表1是不同模型在NYT数据集上的F1值。
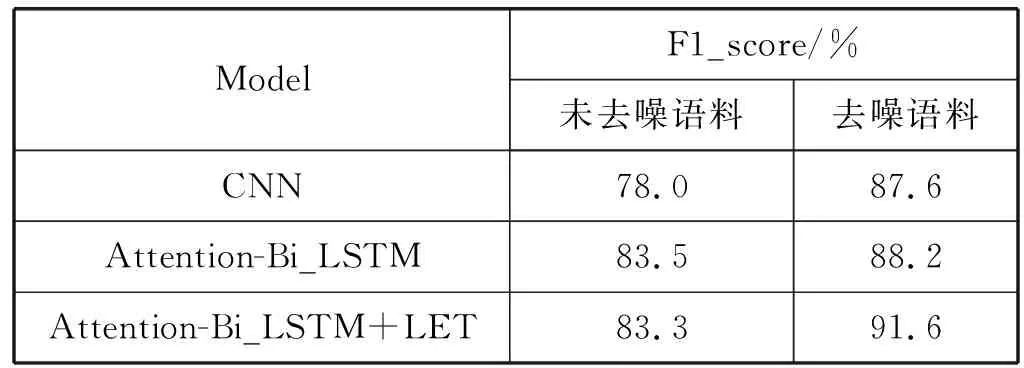
表1 不同模型的F1值
由表1可知:
1) 本文将未去噪语料与去噪后语料的训练结果进行对比,句袋注意力机制起到了一定降噪作用,去噪后的训练关系抽取模型抽取效果更好。
2) Attention-Bi_LSTM+LET(即本文介绍的EA-Bi_LSTM)效果最好,说明融合实体特征方法确实起到了一定效果。
4 课程数据实验结果与分析
本节将对实体抽取和关系抽取进行相关实验,以验证“大数据处理技术”课程知识点关系抽取模型的有效性。实验环境主要采用了Ubuntu 16.04.6,LTS 4.15.0- 45-generic, GNU/Linux,PyCharm3.6,开发语言是Python。
4.1 数据来源与评估标准
本文收集了与大数据处理课程有关的电子教案、电子书籍、课程大纲等课程资料。并将对应的课程资料转变成文本格式,对中文文本进行分句处理,得到11 026条数据。为了下一步自动抽取关键词,需要对这一万条数据进行分词及去停用词处理。本文使用NLPIR中文停用词表,包含了1 208个停用词。并加入计算机主题类词汇构造自己的分词词典,采用开源中分分词工具Jieba进行分词。原始数据如表2所示。

表2 样本示例
本文主要采用精度-召回率(PR)曲线、精度与召回率的调和平均值F1(F1_score)、准确率(Accuracy),以及ROC曲线下的面积AUC(Area Under Curve)作为评价指标,来评估提出的方法是否有效。
4.2 领域知识实体抽取
知识领域的实体与普通的实体抽取(如抽取人名、地名、机构名等)并不相同,在教育领域,一篇文章想要传达的知识即文章的主要内容与主题。而文本关键词表达了文档主题性和关键性的内容,是文档内容理解的最小单位。因此本文采取关键词提取方法获取专业领域实体。
4.2.1关键词抽取
本文使用TF-IDF、TextRank、Word2vec词聚类对分好词的文本进行关键词抽取,表3是三种方法大数据课程教材关键词抽取的准确率结果。

表3 TF-IDF、TextRank、Word2vec准确率对比
根据表3的实验结果,TF-IDF与TextRank算法在关键词抽取阈值改变时,准确率并没有太大改变,而Word2vec词聚类算法随着抽取关键词数阈值减小,准确率逐渐上升,这与词算法的聚类特性有关。TF-IDF考虑了词频,TextRank考虑了词之间的关系,Word2vec词聚类考虑了词的语义,三种算法各有所长,所以本文结合三种方法的结果进行知识实体抽取。关键词抽取部分实验结果如表4所示。

表4 关键词抽取结果示例
4.2.2领域实体优化
以上算法得到的关键词确实有不少是“大数据处理”课程的核心概念,例如“hadoop”“分布式”“数据流”“集群”“雅虎问题”等等。但本文使用的获取关键词方法都是无监督方法,难免会出现领域知识抽取不准确的情况。因此,需要人为删除和修正这些提取出来的领域关键术语。人工优化实体部分实验结果如表5所示。

表5 人工优化实体示例
4.2.3领域实体扩充
由于获取到的数据集有限,因此抽取到的知识实体也有限,所以需要对实体集进行扩充来保证知识体系的完整性。本文在wiki语料中加入大数据处理技术的相关教案、书籍等文本资料,作为Word2vec的训练集训练,最终得到684 721个维度为400的词向量。并将之前获取的实体输入模型进行相似度词语的计算,得到6 869个中文词汇与2 731个英文词汇,再进行新一轮的人工优化。中文和英文实体扩展部分的实体分别如表6和表7所示。

表6 中文实体扩展结果示例

表7 英文实体扩展结果示例
4.3 领域知识关系抽取
根据知识之间的特性,本文定义了实体之间的6种关系:描述关系、前导后继关系、包含关系、等价关系、相关关系、NA。然后根据6种关系构建小型知识库,并用远程监督结合袋内袋间注意力机制进行降噪,最后通过Bi_LSTM训练关系抽取器。表8是6种关系示例。

表8 关系示例
4.3.1远程监督关系抽取实验
本文运用远程监督的思想,首先将实体抽取得到的实体进行人工标注关系,得到718条三元组知识库,将此知识库与10 728条非结构化文本自动对齐,得到25 520条标注数据。表9是远程监督对齐朴素文本的部分处理结果。

表9 远程监督处理结果示例
4.3.2句袋注意力机制降噪实验
本文使用句袋注意力机对远程监督得到的数据进行降噪处理。实验参数设置如表10所示。

表10 句袋模型参数设置
本文对比了远程监督降噪模型的几个例子,表11是不同模型的AUC值。其中CNN和PCNN分别表示在句子编码器中使用CNN或分段CNN,ATT-BL表示文献[23]提出的袋内注意方法,ATT-RA表示关系感知袋内注意方法,而BAG-ATT表示袋间注意力方法。

表11 不同模型的AUC值
从表11可以看出:
1) 使用了ATTRA注意力机制模型的AUC值高于使用了ATTBL注意力机制的模型,这是因为ATTRA方法使用所有关系嵌入来计算袋内注意权重。
2) 使用了BAG-ATT模型的AUC值高于没有使用BAG-ATT的模型,说明计算袋与袋之间的相似度策略起到了一定的效果。
3) 其中用PCNN构造句子特征的AUC值明显高于CNN,这是因为PCNN能够提取句子中两个实体间的结构信息。
为了呈现更直观的效果,图6对比了PR曲线,从图6中可以看出,PCNN_ATTRA与PCNN_ATTRA_BAGATT曲线基本在其他曲线上方,说明袋内袋间注意力方法优于Lin等提出的袋内注意力方法。

图6 不同模型的PR曲线
4.3.3关系抽取实验
将远程监督数据输入句袋注意力模型,得到每个句子对应6种关系的得分。为了避免受到知识库缺失噪声的影响,去除了NA关系标签的句子;为了消除多实例、多标签问题噪声,去除了除NA关系以外的五种关系的对应得分都较小的句子。筛选出约4 000条标注数据,其中各个关系在数据中的占比如表12所示。
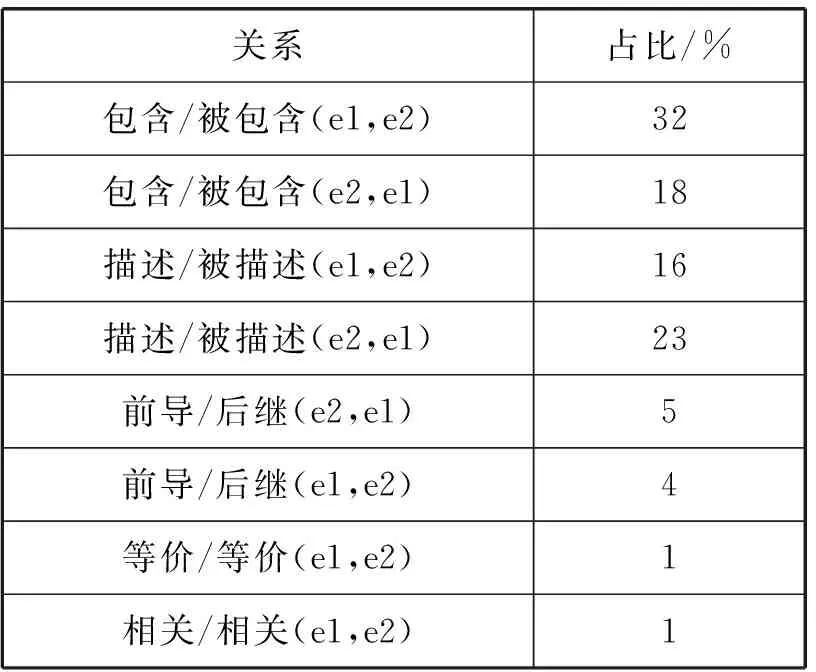
表12 数据关系比例
本文使用基于实体感知关注的Bi_LSTM模型进行关系抽取,对标注数据进行预处理,送入关系抽取模型进行训练,采用k-折交叉验证方法对模型进行调优,实验参数设置如表13所示。
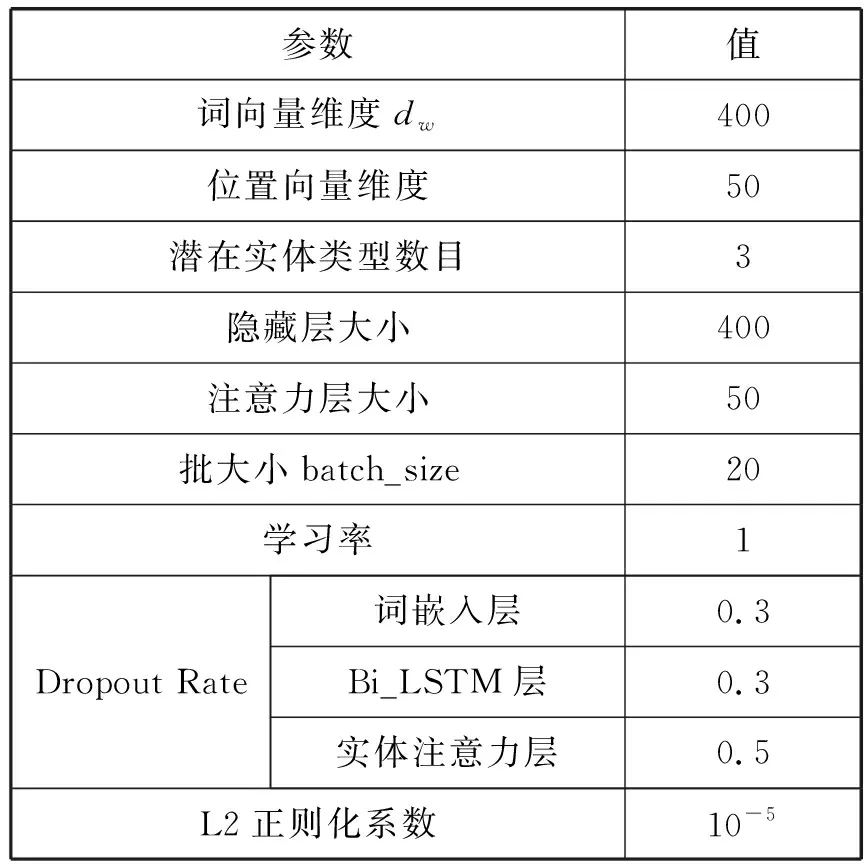
表13 EA-Bi-LSTM模型参数设置
不同模型的F1的实验结果如表14所示,可以看出,在“大数据处理技术”课程数据集上,句袋注意力机制仍取得了一定效果,且Attention-Bi_LSTM+LET模型仍表现最佳。

表14 不同模型的F1值
4.4 课程知识图谱展示
将关系抽取结果整理成<实体-关系-实体>三元组,进行可视化展示。首先将三元组按照关系类别存储于csv文件,然后导入neo4j中,按照关系类别和实体进行展示。
4.4.1知识点关系查询
通过等价关系查询,可以了解到在大数据处理技术中同一个概念的不同叫法;通过描述关系查询,可以了解到某个知识点的特性;通过包含关系查询,可以了解某个知识的结构;通过前导后继关系查询,可以了解在大数据处理技术中数据的流向或对象构建的先后;通过相关关系查询,可以了解到某个实体的功能或和其他实体的相关联性。查询结果如图7-图11所示。

图7 概念等价关系查询
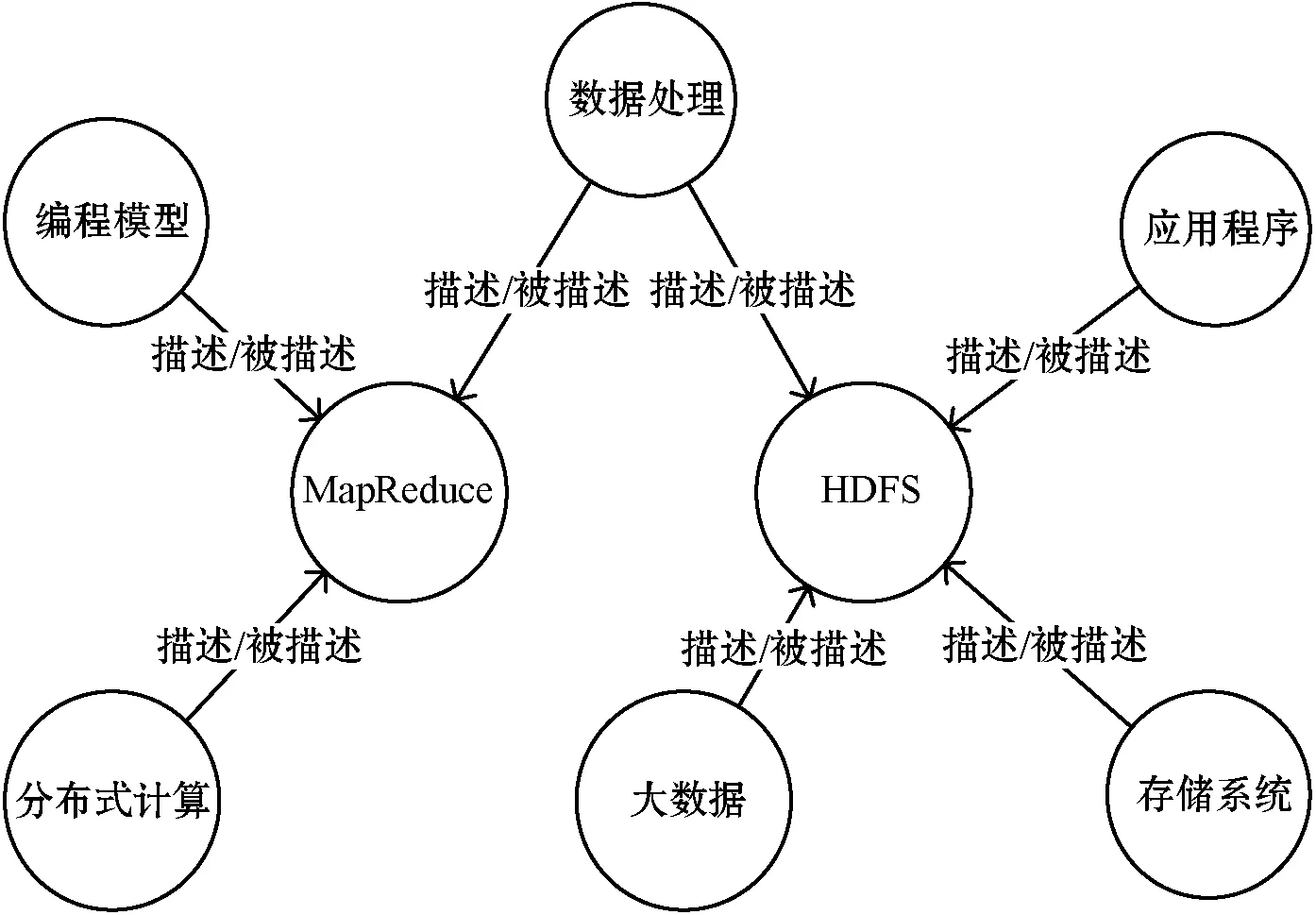
图8 概念描述关系查询

图9 知识点包含关系查询

图10 知识点前导后继关系查询

图11 知识点相关关系查询
4.4.2课程知识实体查询
当以实体为关键字查询时,可以得到关于该实体的拓展信息,从而更加全面地了解某个知识点。如MapReduce的拓展信息,拓展查询可视化部分结果展示如图12所示。

图12 课程知识点实体查询
5 结 语
本文以“大数据技术”课程为例研发了知识点关系抽取的模型。对于任何课程,都免不了要做特征工程,比如关键词抽取中的人工矫正部分,同时,在知识点关系抽取中要根据课程的不同特点定义其知识点之间的关系。除此以外,本文提出的方法对其他课程的知识图谱自动化构建具有通用性。
实验结果证明,课程知识点的关系抽取在没有充足训练集的情况下,需要人工构造大量特征,但通过远程监督方法,构造“大数据处理”课程知识点关系抽取的训练数据,并通过句袋注意力机制降噪,然后通过EA-Bi_LSTM训练关系抽取模型,在F1值上达到了88.1%的效果,此方法减少了人工的参与,能够较好平衡人工与自动构建的关系。
另外,本文只在一定程度上去除了多实例多标签问题的噪声,如何采用有效的方式来解决远程监督的知识库缺失问题,是下一步关系抽取研究的重点。
猜你喜欢
中国中医药信息杂志(2022年6期)2022-06-27
智能计算机与应用(2022年6期)2022-06-23
现代妇女(2022年5期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
现代出版(2014年6期)2014-03-20
航空知识(2000年4期)2000-06-07
