
基于CPD算法与笔段权重的楷体字笔画提取研究
2022-09-06 13:17刘相聪李壮峰
计算机应用与软件 2022年8期
刘相聪 李壮峰 姜 杰 李 艺
(南京师范大学教育科学学院 江苏 南京 210023)
0 引 言
本文关注汉字笔画骨架提取的问题。以常见汉字图片为例,所谓笔画骨架提取,首先要在剥离出汉字整体骨架的基础上,将每一个笔画的骨架分解出来并使之与每个笔画一一对应。所谓骨架,针对汉字图片而言,一般指汉字笔画与运笔方向相垂直的切面(线)上的中间点所连成的线,骨架可以保留笔画的部分形态信息,可以作为判断汉字是否正确的依据。
已有对于汉字正确与否的自动判断大部分都是依赖于汉字笔画信息的,如洪洋[1]提出的基于结构描述的汉字书写正确性自动化判断方法,韩青[2]在此基础上所提出的基于模板匹配的手写汉字正确性判断方法,主要通过量化汉字笔画形态、长度、位置等信息从而进行正确性判断。Sun等[3]提出一种基于结构的相干点漂移算法进行笔画的匹配,其核心思想是利用结构信息,将全局点和局部点注册结合起来,改进原相干点漂移算法(CPD算法)。首先针对给出的两组点集利用带局部算子的CPD算法(CPDLO算法)进行对齐,随后将目标点集分成几个子集,并将CPDLO算法应用于每个子集,最后执行上述两个过程,直到收敛。研究者提到由于关键点的匹配失败对于整字结构提取可能造成严重影响,简单地用正确率来评估是不合理的,因此在该研究中采用四个等级计算综合得分,针对四种实验字体提取结果进行评估,最终结果显示该算法明显优于CPD算法。但是该研究对于映射错误的信息没有提及,提取效果也较难评估,对于提取错误的修正也未提及。Lin等[4]首先提取出汉字的骨架,根据一定的规则找出汉字笔画的端点、连接点和分叉点,然后根据每个分叉点所连接的笔画方向建立一个笔画关系图,应用一个双向连接规则进行笔画提取。该方法的原理是以分叉点为界,对笔段进行拆分与组合,不能处理类似“口”这样封闭的、不存在三叉点的笔画拆分。该方法对工整简单字体的笔画提取效果较好,研究中采用了10个学生书写的共3 039个汉字进行实验,将错误种类分为三类,其中结构性错误有127个汉字,三叉点不能识别错误有24个汉字,断裂错误有31个汉字,共识别错误182个汉字,提取成功率为94%。但是由于该方法无法识别三叉点,因此对于复杂汉字以及不同字体的笔画提取还有待研究和推进。
本文基于汉字骨架结合一致点漂移算法(CPD 算法)与关键点笔段的划分等方法,提出一种基于骨架的硬笔汉字的笔画提取方法。要提取汉字笔画,必须确定笔画提取的字集。本文首先获取合理的实验图片字集,对其进行降噪、二值化等优化后提取出映射所需要的汉字骨架;毛刺是汉字骨架中常见的问题,因此本文继续优化汉字骨架,去除骨架中的毛刺;进行CPD映射需要模板点集与数据点集两组样本。明确模板点集的选择后将两组点集输入CPD算法进行映射,这种简单的映射结果并不理想;分析原因后,进一步提出基于笔段权重的优化提取方案。最终分析笔画提取的实验结果,总结得出本算法提取效率优于CPD算法,能够有效提取大部分硬笔汉字笔画。本文算法主要思路如图1所示。

图1 笔画提取逻辑
1 实验字集获取与图像预处理
1.1 实验字集获取
本文提出笔画提取算法后进行实验验证,合理选取实验字集、高效获取高质量字集图片是十分重要的。本文对于三种字体进行了映射实验,由于采取了楷体字为模板,此处将主要以楷体字为例进行阐述。
1.1.1实验字集选择
在进行笔画提取之前,需要一个实验字集来评估笔画提取的成功率,实验字集选取的合理性决定了对于笔画提取成功率评估的有效性。实验字集的合理性应当包含以下两个方面:
(1) 实验字体最好是笔画较细的字体。笔画细的情况下,提取到的汉字骨架质量更高,毛刺较短,容易去除,便于突出关注本研究工作的重点。
(2) 选择的实验字集应当尽量包含所有的汉字笔画和汉字结构;汉字笔画数应该由少到多;适当覆盖不同字体,如此使实验结果更具普遍意义。
根据以上要求,本研究选取了40个字的实验字集及26个备用汉字,涵盖了28种基本笔画,9种汉字结构。备用汉字主要是为了避免实验字集图像预处理效果较差时以作替换使用,本研究中并未出现此种情况;部分备用汉字结构较为清晰,作为研究图片具有较好的表现特征,其中部分研究图像来源于备用汉字的实验过程。将这40个实验汉字列入表1。

表1 实验字集选择

续表1
由于汉字使用中左右结构与上下结构汉字较多,因此字集中选取左右结构与上下结构的汉字较多。本文将字集按照笔画数量和结构复杂程度分为三个数量相似部分,方便在后续实验中对比统计实验结果。
(1) 汉字笔画0~5画且结构简单为简单汉字,共有12个汉字:卜、乃、女、队、风、六、内、专、打、饥、甩、四。
(2) 汉字笔画6~10画且结构复杂程度中等为一般汉字,共有15个汉字:级、设、众、还、国、果、画、昏、彪、树、思、弯、高、竞、圆。
(3) 汉字笔画11画及以上且结构较为复杂的为复杂汉字,共有13个汉字:淋、爽、斌、鼎、猴、晶、森、媛、鹌、熬、癌、翼、霭。
这样做是由于CPD算法是一种空间分布概率上的统计,当汉字字形更为复杂时,空间点集密度的上升,本文猜测汉字字形的复杂程度会对映射结果或许会造成一定的影响,通过对三个复杂程度汉字实验结果的统计对比,能够体现出字形的复杂程度与笔画提取成功率是否存在着一定联系。
为了使实验字集更具普遍性,本文在楷体字的基础上还选择了其余两种较为常见且汉字形态差异较大的字体宋体、幼圆进行实验,这三种字体采用计算机常用字库中的楷体、宋体、幼圆体。三种字体笔画较细、笔画形态结构清晰、各自风格明显,有助于结果的统计分析,如图2所示。本文将主要以楷体为例进行阐述。

图2 楷体、宋体与幼圆的“霭”字
1.1.2实验环境与数据获取
本文主要通过脱机方式获取形态规范的硬笔汉字字集:脱机在本研究中是指通过图片的方式采集规范硬笔汉字的所有信息,规范符合国家汉字规范要求,并形态清晰、笔画分明的汉字。
本研究对设备并无特殊要求,主要使用了搭载Windows 10系统的离线计算机为实验设备,基于eclipse使用Java进行算法编写。
本研究将目标聚焦于基于汉字骨架的笔画提取工作,为了获取高质量的实验字集,本研究中在系统中添加所需字体后,利用Photoshop CC统一生成400×400像素且分辨率为96 dpi的黑白汉字图片。这样生成的图片尽可能地避免了图像品质、光照等无关因素对于映射造成的影响。本研究中共生成了楷体、宋体、幼圆三种字体的汉字,汉字大小都为60点,每个汉字生成为独立的JPG文件。
1.2 图像预处理
尽管通过软件生成了高质量的黑白图片,但是由于研究最终需要的是汉字骨架图片,因此还需要对字集进行处理使其达到实验要求。
1.2.1图像二值化
尽管实验生成了高质量的黑白图片,但是由于像素变动和存储形式等还不能直接进行使用。为了方便数据处理,将点集信息存在二维数组中,0代表白色,1代表黑色。本研究采用区域动态灰度阈值法[5]进行图片的二值化。首先将图片进行分区,每个区域所设定灰度值阈值,该区域内大于该阈值的点设为黑色,反之设为白色。在图片质量难以控制时,该方法二值化成功率较高。
本研究中采用了资源质量较高的黑白图片,因此二值化过程较为简单,肉眼几乎难以看出差别。但是图片若不经过二值化可能会产生点集丢失的情况,因此进行二值化操作是必要的。图3中左边为二值化之前汉字笔画图片,右边为二值化后效果图,边界较为模糊处二值化效果较为明显。

图3 二值化效果对比图
1.2.2整字骨架提取
汉字的骨架中包含了进行笔画提取与汉字正确性判断所需要的必要信息,且其形态简单,便于计算机处理。通过骨架点集与模板点集进行映射从而提取到汉字的笔画信息。硬笔书法作品单字图像骨架一般是对字形的细化,现有的细化算法已经非常成熟,本研究使用了常用且效果比较好的索引表法[6]。
本研究中采用的字集图片笔画较细、图片质量较高、笔画清晰,因此细化效果较好,图4所示为汉字细化效果图。

图4 “霭”字细化效果
与图片质量无关的是细化算法由于自身的问题会产生许多毛刺:楷体字笔画较为圆润,产生毛刺较少,但在顿笔处不可避免地产生了少量毛刺,尽管楷体细化中毛刺产生较少,但是毛刺的存在仍旧会对映射造成影响。
1.2.3去除毛刺
在硬笔汉字字体中,汉字笔画较细,所以不会生成特别长的毛刺导致混淆笔画的整体形态。短毛刺只需要使用阈值法[7-8]进行去除。硬笔汉字毛刺较短一般不会大于笔画宽度,因此可以对阈值法进行改进,根据笔画的宽度设置一个阈值,小于该阈值的毛刺进行剔除。细化过程产生的毛刺远小于最短笔画长度,因此将阈值扩大为1.5倍笔画宽度。
此处需要说明的是:本次实验中三种字体细化产生的毛刺现象各有不同,其中幼圆字体在细化后因为笔画圆滑且笔画较细,因此不会产生毛刺,不需要进行去除毛刺;楷体细化会产生少量毛刺;宋体毛刺较为严重,后两种需要进行去除毛刺。实验字集中“淋”“专”“级”三个字毛刺去除不彻底,毛刺去除成功率为92.5%,“鹌”“画”二字因字形或笔画粘连问题会有细微畸变,但是可以认定去除成功,如图5所示。
图5 细化后细微畸形的汉字骨架去除毛刺
图6所示为楷体“霭”字去除毛刺的效果。至此实验字集处理完成,基本达到了继续推进工作的预期效果,后续即进行笔画提取。

图6 “霭”字去除毛刺效果
2 基于骨架点集映射与笔段权重的笔画提取
2.1 骨架点集与模板点集映射
点集映射是图形图像学领域所研究的问题,其中的点匹配问题是当前研究的一个热点。点集映射就是对两组具有空间位置相关性的点集A和B,求二者的映射关系,使样本点集与模板点集在映射之后能够建立起对应关系,从而获得对样本点集的认识。本研究中骨架点集与模板点集的匹配与对应就属于点匹配的问题,通过将骨架点集与标准汉字骨架模板点集建立一一对应的关系,从而确定骨架点集中的点属于哪一笔画。一致性点漂移算法(CPD 算法)[9]是点集配准的主要算法。通过给定一个模板点集在另一个相关点集中寻找对应的点。若将这种对应关系用概率来进行描述,就能够获得一个较为合适的点集配准结果。因此本文使用一个概率值来描述这个对应关系:对应关系愈强的点对应概率越接近于1,反之则接近于0。当问题涉及到概率时,必须对于概率模型进行选择:如果针对一个点与一个点的对应关系,可以使用正态分布(高斯分布)来描述,那个当存在多个点时,恰好可以使用混合高斯模型(Gaussian Mixture Model,GMM)来进行描述。CPD算法正是采用GMM来求解这个关系。
2.1.1点集匹配优化与现存方法的不足
由上文可知,模板点集与数据点集的映射是一种位置上的概率关系,如果数据点集的位置确定,这种映射就是确定的。由于汉字笔画具有的连续性,某一段笔画点集的映射后笔画归属基本相同,因此我们可以通过减少部分同类点的映射从而提升算法效率。通过等距去点的方法,本文每隔三个点取一个数据点,这样不会改变笔画形态而且进行映射的数据点数量变为原始点集的1/4,从而大幅度提升算法的执行效率。[5]
尽管优化后映射速度能够提升,由于汉字形态不同引起的点集数量不同、交接或临近处点集位置相近等原因,CPD算法会有较多失准的情况出现。且汉字是有字体之分的,不同字体形态略有不同。一方面,即使待映射样本和模板为同样字体,映射效果也未能尽如人意,若为不同字体,直观上看,效果应该更差。即输入不同字体样本点集与输入同种字体模板点集时,由于形态的相异或相近,两种映射效果的差异就会较大。文献[10]提出的面向矢量字形的汉字笔画自动提取方法中,将数据点集、模板点集以及模板点集的笔画归属关系输入优化后的CPD算法获取数据点集的笔画归属关系,随后对于字形轮廓进行闭合。在该方法中对于CPD算法做了局部优化来提升映射效果,但是并未提及映射失准时如何进一步处理。本文在点集映射中只输入模板点集与样本点集,在映射结束后再赋予数据点集笔画归属关系,从而在映射失准时更加方便进行修正。
2.1.2模板点集获得与基于CPD的直接映射
根据CPD算法的原理可以知道,要进行实验字集的笔画提取,首先需要一套模板字集进行映射。本文采用了书法家在电子设备上书写的楷体汉字作为映射的模板,书写完成的模板字以可扩展标记语言(XML:Extensible Markup Language)的形式进行存储,该文件中包含了汉字笔画的笔画归属、点集坐标及时间信息。[11]重点是,模板是待提取笔画骨架与该汉字笔画建立一一对应关系的依据。在映射过程中,起作用的是模板字的点集坐标与点集的笔画归属信息,因此本文只读取模板字的点集坐标与笔画归属进行储存,以备研究使用。
一般而言,映射后便可获得样本点集与模板点集间的对应关系,逻辑上可以将模板点集的笔画归属赋予与其对应的样本数据点,从而使每个数据点获得笔画归属。如图7的局部放大图所示,图中A、B两点已经形成了映射关系,这时将模板点A的笔画归属赋予B点,使得数据点B获得与A相同的笔画归属。
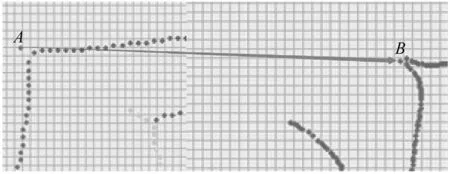
图7 映射局部放大图
本文使用了CPD算法直接进行映射,表2展示了三种字体的映射结果。

表2 CPD算法映射结果
根据统计结果可以看出,直接使用CPD算法进行映射的成功率偏低,即使形态相近的楷体字也会有点集映射关系发生漂移。图8为直接使用CPD算法映射后所出现问题的效果图。

图8 “饥”字映射结果
可以看到由于CPD算法本身的问题,小部分点集映射失准的问题较为常见,如图8中“饥”字所示:笔画映射后点集有轻微漂移,映射错误点数较少。尽管只在一个笔画段中占很小的一部分,但是提取的笔画依旧没有实际意义。总结部分实验数据后发现,映射结果中往往是有小部分点集映射失准,但是一个笔画段大部分的点集匹配是正确的。正如上文所提到的,本文映射后再赋予的笔画归属具有一定的修正空间。从而进一步采用了权重的思想,采用笔段中映射频率最高的点作为当前笔段的笔画代码能够有效纠偏,这种思想认为一个笔画段中所占比重比例最高的点所对应的笔画也应当是本段所对应的笔画。获取到本笔画段的归属信息后,将本段中所有的点集归属进行修正,使其对应正确的笔画。这种基于笔段中数据点权重的修正方式首先需要进行笔段划分,下文将介绍本研究中映射与笔段权重结合的方法。
2.2 映射结果与笔段权重结合
映射与笔段权重结合核心思想是,在一个笔段中,每个点对应了一个笔画,大部分的点映射正确,对应了正确的笔画;寻找这个笔段中映射为相同笔画最多点的笔画归属作为本笔段所有点的对应笔画,将其他小部分点的对应笔画全部修正为本笔段中占权重最高的点所对应的笔画。部分方法如下:
for (int j=0; j num=partList.get(i).get(j).num; pointnum[Qsort[CPDpart[num]] - 1]++; } 此处主要是为了将映射后的点集与笔画对应关系进行转存,获取到点与笔画对应清晰的逻辑关系,其中partList中存储了笔段信息,pointnum[i]中存储了每个笔段中笔画编码为i的点集数量。 for (int k=0; k if (pointnum[k]>max) { max=pointnum[k]; maxStroke[i]=k;} } 在获取到每个点映射到的笔画后,接下来需要找出当前笔段中笔画出现频率最高的笔画代码进行存储,将其存储于maxStroke[]。 将合成算法主要逻辑概述如下: (1) 读取笔画段; (2) 记录该笔段中笔画归属不同的点的数量; (3) 选取对应关系最多的笔画作为本段的正确笔画; (4) 将错误的对应关系修正为当前笔段对应的笔画; (5) 遍历所有笔画段,重复执行以上操作。 经过以上的逻辑,能够将所有笔段内的点集按照权重进行归一,获取更加有效的映射结果。 笔段划分是指在已经获取笔画骨架的基础之上,对汉字骨架按照端点、交点和接点为界限进行分段。[5]进行笔段划分的目的是为了更好地优化汉字骨架点集与模板点集进行映射后的结果。此处分段方法主要依据八临域是否存在相邻像素点,当中心点的八临域中存在像素点,我们就可以认为它是连续的笔画。再通过关键点将其分段,就能够得到笔段。在研究初期采用交接点与端点为关键点进行笔段的划分,方法如下: 2.3.1获取关键点 对于汉字骨架点集进行遍历,获取端点、交点、接点三种类型的关键点同时将八临域内点的数量进行标记。关键点分别具有以下特征:端点八临域内只存在一个黑色像素点(标记为1的点);交接点八临域内黑色像素点为3~4个。而其余普通点八临域内均存在2个黑色像素点,因此将普通点标记为2,交接点标记为3或4。最后将获取到的关键点存储于队列List中。 2.3.2依据关键点分段 从List队列中取出第一个关键点,以取出的点为中心点,按照顺时针顺序扫描该点的八临域,将其八临域内遇到的第一个未读取过的普通点A作为蔓延方向,将其存入笔段数据结构Part中,将该普通点A标记为已读。再将点A作为中心点,扫描其八临域内下一个普通点。 其中主要涉及了对关键点的标识,利用不同的标识判断关键点的种类,并验证是否能够遍历: while (null !=(tempoint=FindNext(arrcopy, m, n))) { if(Check2Go(arrcopy, tempoint.x, tempoint.y)) { part.add(tempoint); arrcopy[tempoint.x][tempoint.y]=5;} } 其中FindNext()方法用以查找一个可遍历的方向点,Check2Go检查是否为新遍历点,若是则加入笔段part,并将其标记。如此循环往复,直到遇到下一个关键点时,即可认定获取了一个笔段Part,将这个笔段存入数据结构笔段组Parts中。 2.3.3完成分段 遍历关键点队列中所有的点,重复2.3.2节中一步分段的过程,将所有关键点读取完成,此时笔段组Parts中存放了该汉字中所有的笔画段信息。此时硬笔字骨架分段已经完成。将不同段进行标记显示,所得到的结果如图9所示。 图9 “代”字分段结果 2.3.4第一次分段映射结果 在实验中发现,运用以上分段的方法能够解决一部分的分段问题,并成功结合映射,但是依然有许多笔画段无法划分,从而导致映射结果结合笔画段后笔画提取错误。表3展示了利用交叉点分段后进行实验的结果。 表3 第一次分段后提取结果 通过实验数据可以发现,笔画提取的成功率相较于CPD算法直接映射的结果有了一定的提升,提取成功率相对较高,基本可以面向应用。但是分段中有一类问题较为突出,由于部分笔画相对圆滑且连贯,不具备分叉等特性,因此无法被识别,从而导致了无法分段,严重的还会影响最终的提取结果。图10所示为无法分段的示例与其导致的映射错误。 图10 “饥”字分段与映射结果 可以看到图中由于分段不彻底的原因,右边几字两笔被识别为一笔。在汉字中由于某些字字形圆滑,笔画没有较刚性的拐点,所以仅仅依赖分叉点与始末点无法分段,导致提取错误。由此可见分段算法并不完善。通过观察发现,这些未能分段的笔画大部分在拐点处未能识别。在之前研究关键点的思路上,本文加入了拐点的判断与分割来完善分段算法。 2.4.1最大距离法求拐点 上文提出的笔段划分方法针对棱角分明、具有交接点的字体适应性较好,但是针对部分交接点或端点不突出的汉字字体适应性较差。通过观察总结发现,针对拐点的位置进行分段,可以解决第一次分段中产生的问题。通过拐点进行划分笔段,其中一个代表性的方法是最大距离法提取拐点[12]。其思路是:对于存在一个拐点的笔画,连接该笔画的起点和终点作为直线,寻找本笔画上距离该直线距离最远的一个点,该点作为此笔画的拐点 。但是该方法存在一定问题:(1) 对于轻微变向的笔画识别敏感,对部分不需要分段的笔画进行分段;(2) 只能处理单拐点笔划,不能处理多拐点笔划,也不能判断笔划上拐点的个数。 2.4.2拐点分段优化 针对前文提到的最大距离法求拐点所存在的问题,本文对最大距离设定一个阈值,当拐点到笔画起末点连线的距离大于该阈值再进行笔段划分。同时优化最大距离法算法,输入所有分段后,检测并对于存在多个拐点的笔段进行迭代分割,直到该笔段中检测不到拐点,其核心过程在于检测最大距离点:partList中存储了某笔段中所有点集,dth为设定阈值,ds为当前点与遍历起点之间的距离,maxPdis与maxp分别存储了最大距离与最大距离点,当检测到最大距离点时进行赋值或者更新最大距离点。 for (int j=0; j p=partList.get(i).get(j); double ds=Math.abs(a*p.x+b*p.y+c)/Math.sqrt(a*a+b*b); if (ds>dth) { if(maxPdis==0){ maxp=partList.get(i).get(j); maxPdis=ds;} else if(ds>maxPdis){ maxp=partList.get(i).get(j); maxPdis=ds;} }} 识别到最大距离点后,对于第一次分段结果进行二次分段: for (int n=0; n if(partList.get(m).get(n) != maxp){ part.add(partList.get(m).get(n));} else{ part.add(partList.get(m).get(n)); if (part.size() != 0){ tempPartList.add(part); part=new ArrayList } } 以最大距离点为分界点,前半部分将相同的点复制存储,在拐点出进行分割,剩下的点作为一段新段。在所有分段结束后,递归调用自身,重新检测是否需要再次分段。 可以将算法逻辑简要概述如下: (1) 将第一次关键点分段结果Parts[]输入第二次拐点分段算法。 (2) 获取第一个笔段Part进行遍历,使用最大距离法判断是否存在拐点,并记录最大距离点P。 (3) 若最大距离大于阈值,则认为该笔画中存在拐点,以最大距离点进行笔段分割。 (4) 将P点前后进行分段,将这两段存入临时分段组TempParts[]。 (5) 将临时分段组TempParts[]再次输入二次分段算法,进行检测分段。 (6) 直到所有笔段中不再存在拐点,将最终的临时分段组返回原程序,获取拐点分段结果。 (7) 将笔段组Parts[]中所有分段二次分段结果进行合并,重新存入笔段组Parts[]。 该优化后方法能够有效识别第一次交叉点分段后未能分段的笔画,最大距离法中的阈值的设定与具体分段结果相关,当遇到拐点不明显的字体时可以适当降低阈值设定,尽可能多进行分段。由于映射结果与笔段进行结合,因此对于部分笔段划分宽容度相对较高,阈值设定相对灵活,部分汉字可能会多分割出1到2段,对于最终映射结果基本没有影响。实际分段结果如图11所示。 图11 “昏”字二次分段效果 为验证本文算法的有效性,对选取的楷体字集进行一系列实验。根据汉字的结构,笔画的覆盖度,汉字的复杂程度等因素选取了40个字的实验汉字字集。采用同一种专家书写的楷体字作为映射的模板字集。对于笔画提取成功的标准设定为:实验字中的每个笔画都能够形态清晰地与其他笔画进行分辨。根据设定的标准对汉字笔画进行提取,结果统计如表4所示。 表4 楷体脱机笔画提取结果 由结果可知,40个样本字中,成功提取39个,成功率达97.5%。与之前两次实验结果进行对比发现算法成功率提升明显,基本能够达到实验预期。对于提取错误原因的统计如表5所示。 表5 提取失败原因统计 结果显示,笔画提取失败的主要原因是映射失败,而映射失败的主要原因为字体形态有所差异,空间位置分布不定等原因。分析结果发现,楷体字的成功率较高,此处猜测是由于使用了楷体模板字进行映射楷体字时成功率会相对较高,为验证该猜想,接着采用了三种形态有所差异楷体字测试进一步验证猜测。 经过分析以上的实验结果,本文猜测可能因为模板字是楷体字的原因,楷体字的提取成功率较高,因此又选取了文鼎特颜楷(颜楷)、方正苏新诗柳楷简体(柳楷)、方正北魏楷书(北魏楷书)三种不同风格的楷体字进行实验,这三种字体形态与计算机常用的楷体有一定差异。如图12所示,从左到右,从上到下分别为标准楷体、颜楷、柳楷、北魏楷书。 图12 “霭”字四种楷书效果图 与之前的实验采用相同实验字集与模板字集。实验结果如表6所示。 表6 三种楷体字提取结果 由结果可知,120个样本字中,成功提取107个,综合成功率达89.17%,可以看出本次实验中对于楷体字的笔画提取效果较为显著,一定程度上可以验证之前的猜想,由于模板字选定为楷体字,因此对于楷体字的提取效果更为显著。对于提取错误原因的统计如表7所示。 表7 提取失败原因统计 结果显示,虽然大部分错误还是由于映射错误导致的,但是分段的问题也有所上升,这是由于选取的三种测试字体相对接近于软笔模板,笔画相对较粗,细化分段可能会有细微的问题产生。其中颜真卿体由于笔画圆润,风格突出,因此提取错误相较于其他两者更多,但是这并不影响楷体整体提取成功率相对较高的实验结果。 在此次实验中发现:柳楷的提取成功率较低,观察发现其形态与标准的计算机楷体字差异较大。 为了检验字形差异对于映射的影响,本文还选择了宋体、幼圆两种字体进一步分析其映射结果。结果如表8所示。 表8 脱机笔画提取结果 可以看出,使用楷体作为映射模板时,其他字体的笔画提取成功率明显偏低,不足以面向应用。首先从图像的来源与字体大小来看,二者均与楷体字实验中参数相同,因此可以排除图像质量的原因;其次从字形上来看,宋体字顿笔极多,因而产生的毛刺也较多,去除毛刺后字形显得相对僵硬,笔画位置也不尽相似,幼圆笔画极其圆滑,细化不会产生毛刺,但是字形较为夸张、空间分布较散,与楷体字形相距甚远,在不明确时序的情况下,分割难度较大。因此二者提取率低主要是由于模板字与实验字字形差异较大的原因。 汉字具有其特殊性,不同汉字字形差异较大,笔画数量越多的汉字其笔画分布也会更加密集,汉字也就更加复杂。由于本算法是基于平面点集位置概率意义上的计算与调整,汉字复杂程度越高,笔画数量相对应会增加,汉字点集密度也会有所提升,研究者猜测或许在一定程度上会影响映射的结果与分段的效果,为了探究字形复杂程度对于算法的影响,对于前文中提到的不同复杂程度的汉字提取结果进行了统计,观察实验结果中成功率,汇总如表9所示。 表9 汉字复杂程度与提取成功占比 结果可见,汉字错误样本总数为35个,其中简单汉字错误6个,成功率为82.9%,一般汉字错误15个,成功率57.1%,复杂汉字错误14个,成功率60%,由此可知,汉字字形的复杂程度作为单一因素几乎不对映射造成影响。简单汉字笔画较少因此成功率较高,但是一般汉字与复杂汉字字形差异较大,且笔画数目差异大,错误率相似,因此不能认为单纯的汉字复杂程度对于映射造成影响。在实际映射中,汉字的复杂度不会对于结果造成决定性影响,但是也会有所作用。 通过分析数据可以总结出,针对楷体字模板进行的楷体字笔画提取成功率已经能够达到面向应用的程度,可以进行不同楷体字的笔画进行提取,对软笔字体也具有一定的适应性。与此同时研究者发现该算法在针对模板字与待提取字字体不同时,成功率会相应降低,距离面向应用还有发展的空间,尤其是面对字体形态差异较大的字体,复杂汉字的出错率更高。因此对于不同字体而言,具有较大的提升空间,可以采用不同模板字来提取不同字体的方法来提升算法的成功率。本研究中也还有许多工作亟待改善,例如交畸变修复、毛刺去除等等。 在实际应用中,本研究对于汉字计算的各项研究给出了一定的支持,例如在汉字的正确性判断中,汉字的笔画骨架是必要的,图13展示部分提取效果图。 图13 楷体字笔画提取效果图(左侧为模板,右侧为提取效果) 本文提出了一种基于点集匹配与笔段权重的脱机汉字笔画提取方法,对脱机多种硬笔字体汉字的识别效果有了较大的提高,逻辑简单易懂,执行速度快,需要一套标准模板字作为标准,笔画提取的效率较高。但是与此同时,脱机硬笔汉字笔画提取是一个极具挑战性的工作,很多方面还亟待完善。要真正达到较高的准确率,点集映射的方法与划分笔段方法都具有较大的提升空间。2.3 交接端点划分笔段与映射



2.4 拐点识别与笔段划分

3 实验结果
3.1 楷体字笔画提取结果分析


3.2 不同楷体字实验提取结果分析



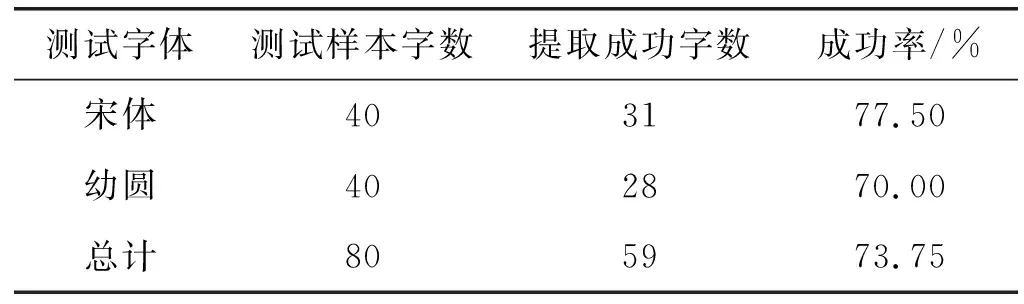
3.3 其他字体笔画提取实验分析
3.4 字形复杂程度结果分析

3.5 应用价值与研究前景展望

4 结 语
猜你喜欢
山西教育·招考(2021年8期)2021-12-17语数外学习·高中版上旬(2020年5期)2020-09-10环球市场信息导报(2018年29期)2018-10-16小天使·二年级语数英综合(2018年10期)2018-10-15伴侣(2018年6期)2018-06-27新高考·高三数学(2017年4期)2017-07-10理科考试研究·高中(2016年10期)2017-01-17建筑工程技术与设计(2015年20期)2015-10-21时代英语·高三(2014年5期)2014-08-26小学阅读指南·低年级版(2009年2期)2009-03-30
