
线性树模型的Sporadic任务多核调度方法研究
2022-09-09 13:33黄姝娟李天森马志昊肖锋
西北工业大学学报 2022年4期
黄姝娟, 李天森, 马志昊, 肖锋
(西安工业大学 计算机科学与工程学院, 陕西 西安 710021)
片上多核处理器任务调度方法中,研究者早期考虑的是基于由Liu 和Layland[1]提出的相互独立的实时周期任务模型[2-10],随着研究的深入,又开始研究执行时间可以随着关键级别变化而变化的混合关键任务模型[11-13]和具有制约关系以及带有周期性的DAG任务模型[14-19]。这些模型对应的调度算法大都是基于RM(rate-monotonous)算法和GEDF(global earliest deadline first)以及PEDF(partitioned earliest deadline first)算法。如文献[2,4-5]和文献[3,6-7]针对相互独立的实时周期任务,分别对RM算法及GEDF算法进行分析并提出新的调度算法。文献[8]针对PEDF中的划分算法,提出一种改进的基于幂函数划分的EDF算法。文献[9-10]则是结合PEDF和GEDF各自优点,提出了旨在允许部分任务迁移的semi-partitioned调度算法。文献[11]将PEDF改进的semi-partitioned算法应用在混合关键模型中。文献[13]则是将周期性的DAG图放在混合关键模型中讨论。文献[14-16]在GEDF算法下讨论DAG图的调度。文献[17]则提出一种PEDF-omp的调度算法,旨在解决类似DAG图模型的OpenMP并行执行。文献[18]在big.LITTLE体系结构下研究不同类型周期任务的动态分区调度方法。文献[19]则针对既考虑周期性又考虑依赖关系的实时周期性任务,提出基于可延迟时间越短越优先(PLTSF,probably lag time shortest first)的调度方法。
上述所有任务模型中都有一个前提假设,就是所有周期任务均为固定周期。而在实际情况中,有些任务的周期是可以进行调整的。因此本文则针对周期可变的Sporadic任务,提出相应的task模型、job模型以及fragment模型,将实时周期任务划分为不同层数节点,根据每个节点的实时性、周期性以及节点之间的层次关系进行相应的线性树模型转化,并根据具有时间迁移特性的job以及可变周期的任务调整某些层节点的位置,使得尽可能多的节点成为处理器上能够满足时限的执行节点。实验表明,上述调度方法与PEDF、GEDF、RMFF(RM first fit)算法比较起来,在延迟时间、系统利用率、上下文切换次数、系统抢占次数、时限丢失率方面都较优。
1 实时可变周期任务模型
1.1 task模型
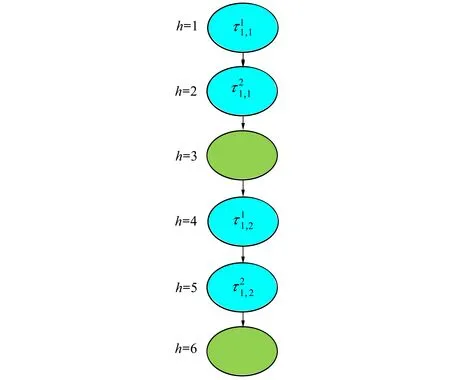
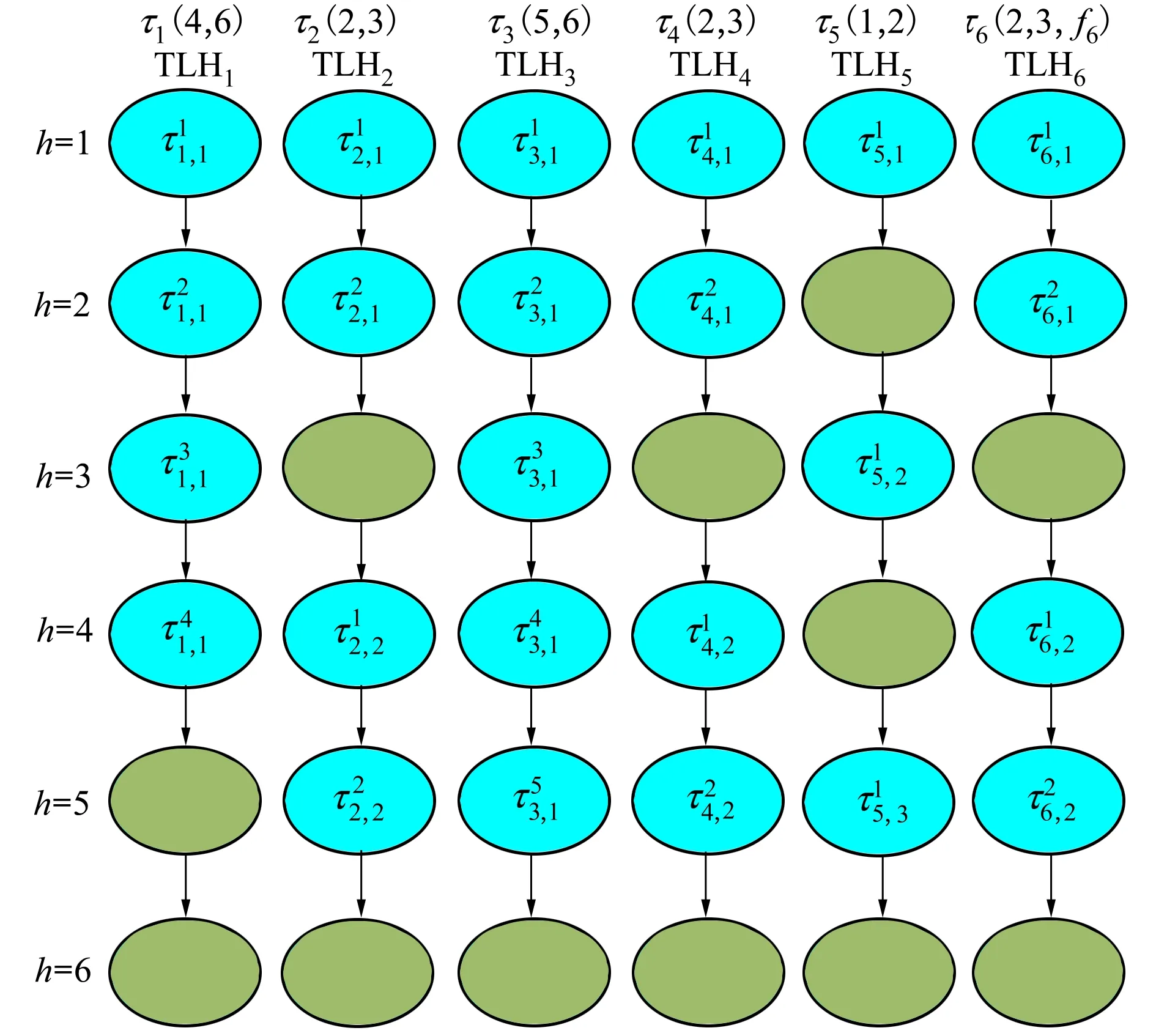
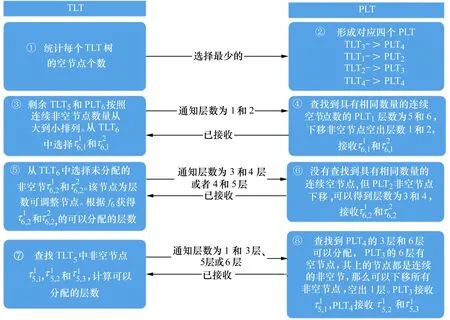
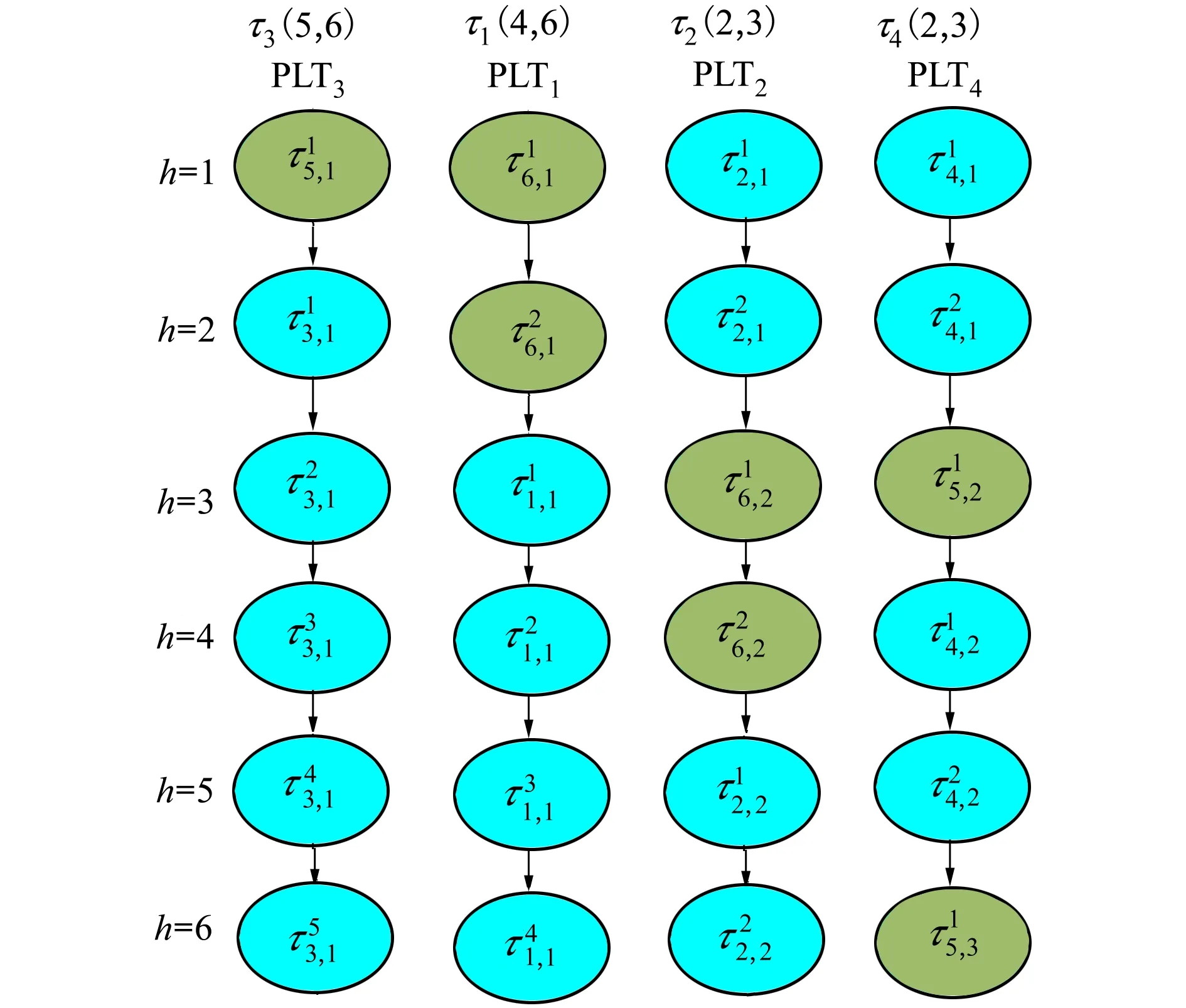
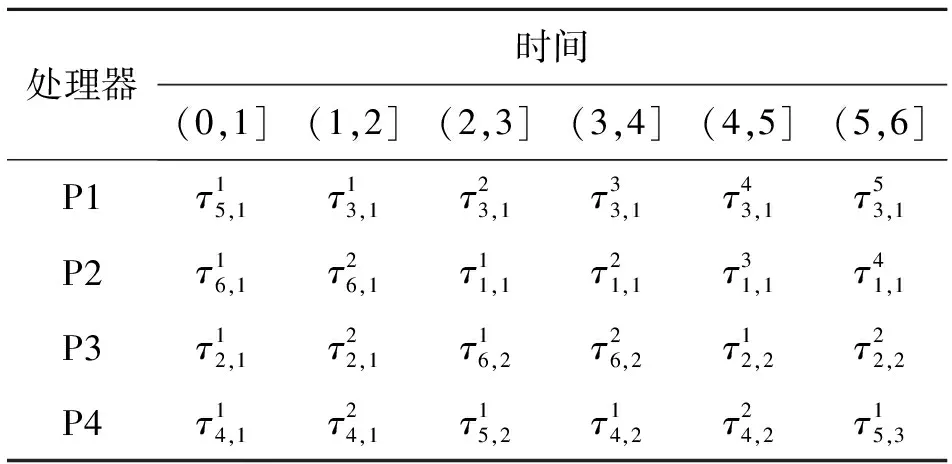
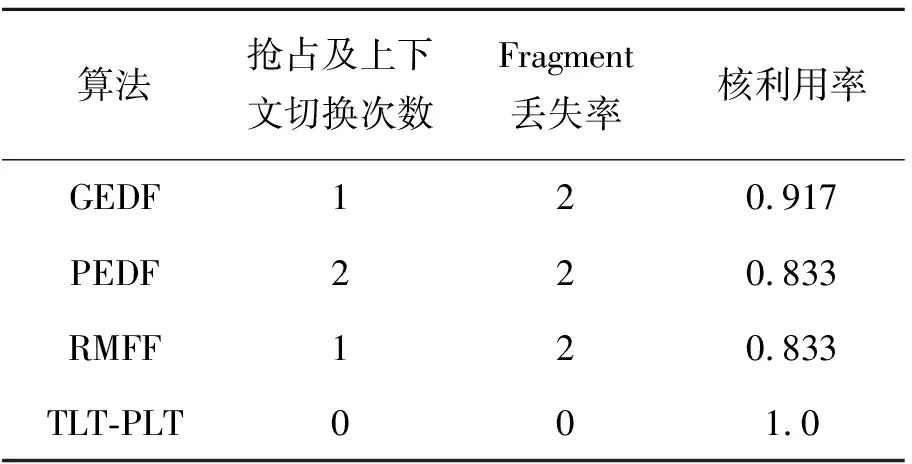
假设一个实时系统τ由n个实时周期性任务组成,记为τ={τ1,τ2,…τn}。每个实时周期任务都包含5个参数,即τi(ri,ei,pi,di,fi)(1≤i≤n)。其中ri表示发布时刻(release time),即处理器核可以执行该任务的时刻。ei表示任务τi最坏情况下的执行时间(worst-case execution time,WCET)。pi是τi的最长周期;di表示时限(deadline),要求ei≤di≤pi。如果di=pi,称该系统为隐含时限的系统(implicit deadline system),将其任务称为隐含时限任务。如果di 在一个实时周期任务系统中,所有任务在同一个时刻发布它们的第一个job,将其称为同步系统,否则称为异步系统。τi的第j(j≥1)次执行称为第j个job,用τi,j(ri,j,ei,j,di,j,si,j)表示,其中ri,j为τi,j的最早可以开始执行的时间且ri,j=ri+(j-1)pi-si,j,di,j为τi,j的绝对时限且di,j=ri+(j-1)pi+di,如果di=pi则di,j=ri+j×pi;ei,j为τi,j的执行时间且ei,j=ei。si,j=fi(j)表示τi,j允许提前发布的时间片数量,如果si,j=0,则表示不可以提前发布。 根据树定义Tree=(root,R),root为根节点,R为树中各节点之间的层次关系,由树的特性可以知道树中的每个节点都有层次,根为第一层,根的孩子为第二层。若某个节点在第h层其孩子就在第h+1层,树的深度为树中节点的最大层次。树T深度为H用layer(T)=H表示;节点Pi所处的层次为h用layer(Pi)=h来表示。 假定一棵树型结构,除了叶子节点外,所有父节点都只有一个孩子节点,这种树称为线性树LT(line tree)。 LT具有如下特征: 1) 树中第h层的节点数用Number(h)来表示。显然Number(h)=1。 2) 由于每层只有一个节点,则该线性树上所有节点的个数等于该线性树的层数。 3) 节点之间具有一定的时间顺序关系。 线性树满足树的基本特征即在任意一棵树中: 1) 有且仅有一个特定的称为根的节点; 2) 当n>1时,其余节点可分为n个互不相交的有限集合T1,T2,…,Tn,其中每一个集合本身又是一棵树,并且称为根的子树。 定义1PLT(processor line tree)模型是由处理器核数M和所有任务周期的最小公倍数D决定的M棵线性树组成的森林,记为F=(M,D)。其中M为线性树的个数,D为其中任何一个线性树的深度,可以看出这M个线性树的深度都是D。 定义2TLT(task line tree)模型是由任务数量N和任务周期最小公倍数D决定的N棵线性树组成的森林,记为F=(N,D)。其中N为线性树的个数,D为其中任何一个线性树的深度,可以看出这N个线性树的深度都是D。 图1 τ1(2,3,f1)在[0,6)时间段的TLT模型 可以看出,如果第一个job的τ1,1允许周期缩短,则缩短的时间片f1(1)≤3-2=1,即τ1,1与τ1,2之间的空节点层数。另外,空节点层以上的节点也可以下移至空节点层处,不影响该节点按时完成。 同样,PLT模型中线性树的节点也是处理器核上准备执行任务job的时间片段fragments,由于与TLT模型线性树的数量不同,通常情况下,M 将2个公式联立起来得 得证。 推论1任何一个时刻t都能唯一对应于TLT模型的某一层。 证明根据推论1,在TLT模型中,任何时刻都可以对应其中一个层,那么某个h层也可以对应其中某一个fragment的发布时刻,但由于该fragment所在的job提前发布至h′层,则该h层如果不为空节点层必然存在 h≤h′+ei-1 (3) 式中,k=1,根据定理及公式(3) 考虑一个任务系统Γ={τ1,τ2,…,τN}有N个任务要分配到M个处理器上,该系统具有TLT模型和PLT模型分别简单记为TLTΓ={TLT1,TLT2,…,TLTN}和PLTΓ={PLT1,PLT2,…,PLTM}。所有任务的job被划分为不同的fragment分布在TLTΓ的不同节点上,然后根据一定的指派算法被指派在PLTΓ这M棵PLT树节点上。其中所有PLTp(1≤p≤M)均为一棵深度为D的树,这里D为所有任务周期的最小公倍数,D=[p1,p2,…,pn](D>1),PLTΓ中的一棵PLT树就对应一个处理器核调度的一个顺序。 图2 实例对应的TLT模型 以该实例来说明TLT模型与PLT模型之间的转化方法,如图3所示。 图3 实例中TLT模型与PLT模型之间的转化方法 得到PLT的结果如图4所示。 图4 转化为PLT的最终结果 (x=1,…,k),如果系统在允许范围内,则该节点为可提前发布时间节点。 定义4在指派算法S下,定义一个层次分配函数为hs(x),该函数表示fragmentsx被指派在哪个层,定义Is(x)表示指派在哪棵线性树上。如果没有被指派则这两个函数值均为0。 在指派算法S下,如果一个任务Ti在公共周期内发布的所有τi,j的所有fragments都被指派到LT树上,且都时限满足,那么该任务在S下可调度,如果系统内所有任务都可调度,那么该系统在S下可调度。 本文根据PLT空节点层和TLT需要迁移的节点层的情况实现TLT向PLT的转化算法。 算法:TLT-PLT转化算法 Input: Enter TLT Set N: The number of tasks M: The number of processors Output: Header Pointer of PLT 1:i=1; 2: Whilei≤Mdo /*Select minimum quantity empty layer number of LT from TLT into PLT*/ 3:j=findMiniEmptyLayer(TLT); 4: Trans(j,TLT,PLT); 5:Delete(j,TLT);/*Delete the LT from TLT set*/ 6:i=i+1; 7: end While /*count the node layer number before every empty layer for every LT in TLT */ 8: Count(TLT, nodeLayerTLT); 9: Count-emptyLayer(PLT, emptyLayerPLT);/ *count the empty layer for every LT in PLT*/ 10: While TLT set is not NULL do /*Select the maximum number of the nodeLayerTLT equal or smaller than the number of emptyLayerPLT */ 11: flag=FindSame(nodeLayerTLT, emptyLayerPLT) 12: if(flag!=-1 && Layer is equal) /*move the node layer of LT in TLT into the empty layer of PLT*/ 13: Trans(flag, nodeLayerTLT, emptyLayerPLT, TLT, PLT); /*move the node layer of LT in PLT to the same empty Layer */ 14: else if (flag!=-1&&Layer is not equal) 15: Move(emptyLayerPLT, PLT); 16: Trans(flag, nodeLayerTLT, emptyLayerPLT, TLT, PLT) 17: else if(advancedPermitted(flag, function)) 18: Advance(flag, TLT);/*count the advanced function if the node is permitted advanced */ 19: else 20: FragmentMiss (flag, TLT);/*put the LT node into the fragment miss set*/ 21: end if 22: Delete(flag, TLT); 23: end While 上述算法核心思想如下: 首先,从TLT中找出M个空节点层数较少的LT转移到PLT中,并从TLT中删除这些节点。 其次,计算TLT中每个LT的空节点层数之前的连续节点数,计算PLT中连续空节点层数的数量。 最后,从大到小在TLT中找出连续节点层数与PLT中连续空节点数层数相同的PLT树,如果匹配则直接将这些节点与对应的PLT中的空节点层进行交换,并删除TLT中交换过的节点;如果没有匹配的则将PLT中的节点进行层数下移至数量相同的空节点层,再进行交换并删除TLT中交换过的节点;如果找不到对应的层数,或者TLT中无法再通过下移空节点层来匹配TLT中的节点层则将剩余节点放置到fragment丢失集合中。 下面就是利用TLT-PLT转化算法的整体方案。 2.2节的实例在GEDF、PEDF、RMFF以及TLT-PLT 4种调度算法的处理器分配结果如表1~4所示,在6个时间片内的性能统计如表5所示。 表1 实例在GEDF调度算法下的运行结果 表2 实例在PEDF调度算法下的运行结果 表3 实例在RMFFF调度算法下的运行结果 表4 实例在TLT-PLT调度算法下的运行结果 表5 实例在6个时间片内4种算法下的性能比较 本文的仿真实验平台是在4核 Intel core(TM)2 Quad CPU 2.66 GHz内存为3.4G的硬件环境下运行Ubuntu Linux10.04 2.6.33-29实时内核,采用Codeblocks-v10.05 编写仿真测试程序。在实验设计时,选择了处理器核数M与N个任务总利用率之间3种不同的关系:「Usum⎤>m,「Usum⎤=m,「Usum⎤ 上下文切换和抢占次数。通过计算不同任务job之间上下文切换次数以及job的fragment被打断情况的计数来统计抢占次数,说明不同算法的额外开销。开销太大则耗时多,任务响应时间长。 核利用率。 在算法分配过程中如果PLT模型中线性树有空节点层,则说明核在该层处于空闲状态,为了描述核利用情况定义核利用率为该核对应的线性树的非空节点个数与树深度的比值。该比值是PLT模型对核利用情况的一个反映。该值越大说明该模型和调度方法对核的利用越充分。 Fragment丢失率。由于PLT模型中的工作在调度过程中存在时限不满足情况,为了考察时限不满足严重程度定义fragment丢失率为fragment丢失时限节点的数量总和与所有fragments数量总和的比值。 根据以上的评价指标,对可并行执行的工作分别采用GEDF算法、PEDF算法、RMFF算法以及TLT-PLT 转化算法进行调度,在500个时间片内对系统的上下文切换次数以及抢占次数、核利用率以及fragment丢失率进行了统计。 图5展示了在3种情况下,每种情况随机输入10组数据得出的上下文切换次数和抢占次数的平均值。从图5中可以看出在负载量较大情况下,TLT-PLT算法的上下文切换及抢占次数明显小于GEDF、PEDF和RMFF算法,而在负载量小的情况下对比不是很明显,因此本文仅针对负载量较大的情况,3种算法的核总利用率和fragment丢失率的情况分别如图6和图7所示。 核利用率效果如图6所示。结果显示出采用TLT-PLT算法的核利用率效果和GEDF基本接近且速度快,而比PEDF和RMFF要好得多。原因是GEDF是允许任务迁移且由最近时限来决定优先级,效率高迁移开销大;而PEDF是不允许任务迁移利用率较低;RMFF通过利用率进行首次适应匹配,也不允许迁移,利用率也比较低。而TLT-PLT算法结合三者的优点,即允许部分任务迁移又利用LT的空闲节点进行节点空闲节点自适应匹配,且通过调整发布时间可以快速使得任务被调度,因此效率较高。 从图7中可以看出任务的fragment丢失率随着时间的持续而增长,但TLT-PLT增长的趋势较低。分析原因发现由于GEDF算法和RMFF以及PEDF算法优先级是根据自身的参数(时限和利用率)来决定的,并没有综合考虑任务的实际执行情况,GEDF由于迁移频繁而导致有些任务来不及执行就放弃了,PEDF和RMFF算法不能根据时间灵活迁移导致很多任务无法及时执行。而TLT-PLT算法从一开始就利用最小公倍数分时间段考虑任务在实际执行过程中出现的迁移情况以及fragment是否能满足的问题,并通过调整发布时间使得fragment尽量减少丢失,所以得到最好的效果。 图5 3种情况下上下文切换 图6 4种算法核利用 图7 固定时间片下4种算法 和抢占次数测试 率增长情况 的fragment丢失率 随着多核技术在嵌入式领域的快速发展,围绕片上多处理器实时调度问题进行了大量的研究工作,所提出的调度模型和调度算法大都只针对任务模型。本文从线性树模型出发,根据Sporadic任务周期可变的情况,建立实时周期任务的task模型、job模型以及fragment模型,提出实时周期任务在多核处理器上的TLT模型和PLT模型和相应的转化算法,不仅维持了系统利用率和减少时限丢失情况,而且还使得切换次数和抢占次数降到比较低的水平。文章首先描述了TLT任务模型和PLT模型,接着说明了该模型的相关性质和相关定理,随后定义了延迟因子以及相应的转化算法。仿真实验表明所采用的TLT-PLT转化算法不但比PEDF、GEDF、RMFF算法在核利用率以及时限丢失率方面都较优而且还减少了抢占次数和上下文切换次数。1.2 job模型
1.3 fragment模型
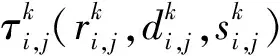
2 TLT和PLT模型
2.1 相关定义
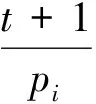
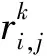
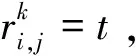
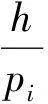
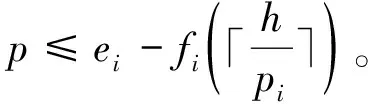
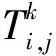
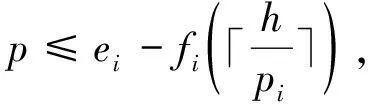
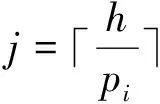
2.2 实时系统的TLT模型和PLT模型
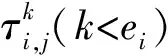
3 延迟因子及TLT-PLT转化方法
3.1 延迟因子确定
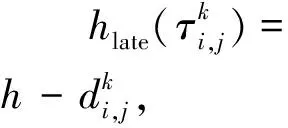
3.2 TLT-PLT转化算法
3.3 处理器预分配算法
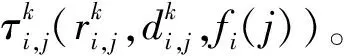
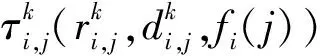
3.4 应用实例处理器分配结果

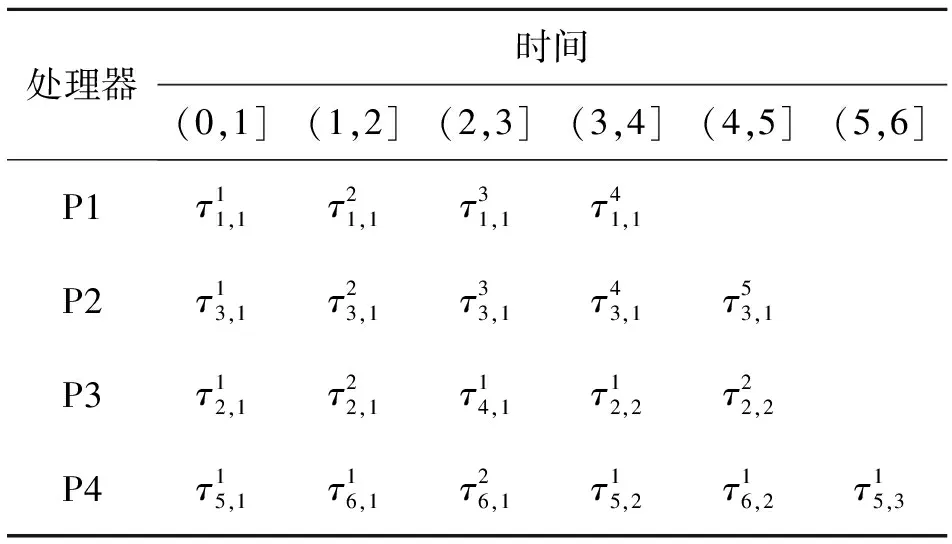
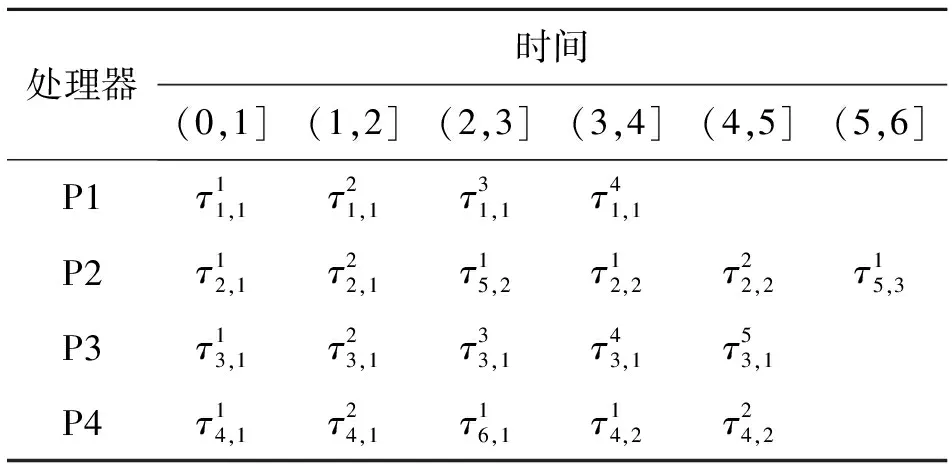
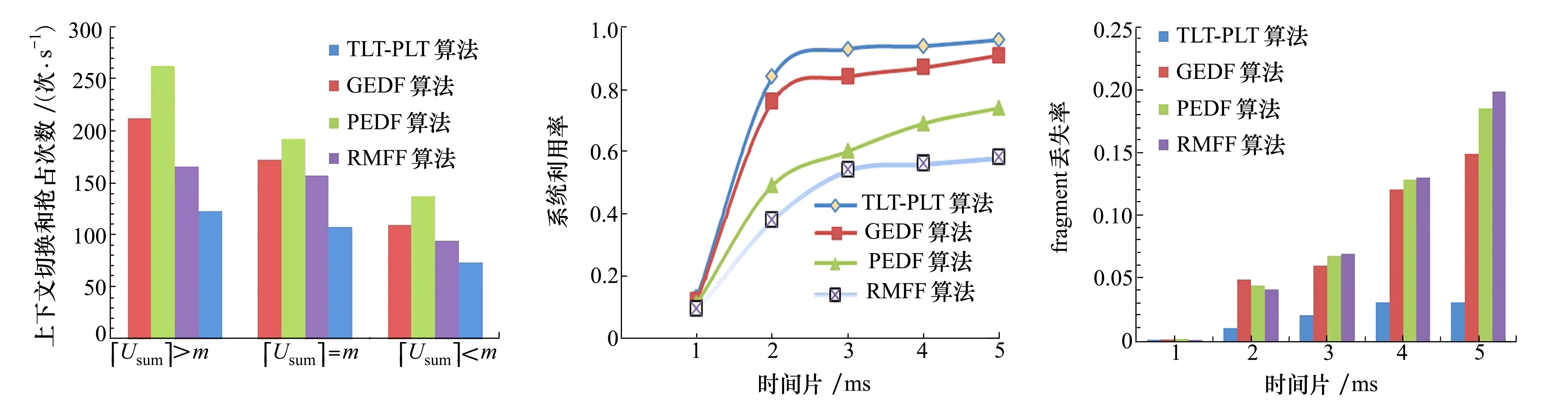
4 实验及结果分析
5 结 论
猜你喜欢
矿山安全信息(2022年11期)2022-11-26读与写·教育教学版(2019年9期)2019-10-30智族GQ(2019年7期)2019-08-26中学生数理化(高中版.高考理化)(2019年6期)2019-06-22妇女生活(2018年7期)2018-07-14卷宗(2018年14期)2018-06-29小资CHIC!ELEGANCE(2018年8期)2018-04-03智富时代(2018年1期)2018-03-26智富时代(2018年1期)2018-03-26山海经(2015年18期)2015-04-19
