
基于深度估计与自我运动联合优化的三维重建
2022-10-11 12:33田方正高永彬方志军
传感器与微系统 2022年10期
田方正, 高永彬, 方志军, 顾 佳
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引 言
稠密的三维重建是安全的机器人导航、增强现实(AR)等任务的首选。多年来,很多学者在不同的领域研究定位和三维重建的工作。OpenMVG[1]开发了完整的系统,应用局部细化来恢复更好的局部重建质量。从运动恢复结构(structure from motion,SFM)和即时定位与地图构建(simultaneous localization and mapping,SLAM)被广泛用于从图像获得三维重建[2]。DTAM(dense tracking and mapping in real-time)[3]和REMODE[4]通常通过优化深度值来创建密集场景。随着卷积神经网络(convolutional neural networks,CNN)的出现,计算机视觉理解的性能大大提高。CNNSLAM[5]利用CNN预测单目图像深度,并将其输入大规模直接单眼SLAM(LSD-SLAM)中实现稠密重建。CodeSLAM[6]利用CNN框架,并结合图像几何信息实现了单目相机的稠密SLAM。
目前,基于RGB-D的重建只能保持颜色分辨率等于所用深度传感器的分辨率,这限制了生成重建的精度和真实性。如文献[7]所示,基于几何的系统在图像梯度区域或者边缘上表现最佳,但在纹理较低的内部区域表现极差,而基于学习的系统通常在内部点上表现得相当好,但会模糊对象的边缘。
本文提出了基于深度估计与自我运动联合优化的三维重建。首次增加了RGB图像的特征图作为网络的输入,并且创新性地提出了轮廓损失函数,同时设计了特征损失函数来联合优化深度估计和自我运动。在TUM RGB-D[8]、ICL-NUIM[9]数据集上,明显地提高了深度图的质量、定位结果以及三维重建的效果。
1 算法原理
1.1 系统架构
基于深度估计与自我运动联合优化的三维重建总体架构如图1所示。整个算法由3个神经网络组成,DepthNet用于预测当前帧RGB1的稠密深度Pred。PoseNet分为4个子网络,以RGB1和RGB2与它们的3个不同级别的特征图作为输入,预测当前帧RGB1和附近帧RGB2的相对位姿。VGGNet[10]不参与模型的学习,仅使用预训练的权重提取图像特征。由于在室内场景中,有大量带有深度标记的样本。因此,采用监督的方式训练网络,使用原始的深度图与预测深度图之间的差作为损失约束,加速网络的收敛。使用当前帧RGB1和重建的当前帧RGB1′的光度误差、轮廓误差以及它们的3个特征误差纠正预测的深度图的结果,同时优化当前帧与附近帧的相对位姿。最后,在DepthNet和PoseNet训练完成的基础上,通过预测关键帧的稠密深度图与位姿进行三维重建。

图1 系统架构示意
1.2 DepthNet和VGGNet
DepthNet以原始分辨率的RGB图像作为网络的输入。网络的输出为与输入分辨率一致的预测稠密深度图。这种高分辨率的稠密深度预测保证了后期三维重建的质量。
DepthNet网络架构采用了经典的V形结构。如图2所示,整个网络使用3×3(反)卷积,批量归一化(batch normalization,BN)和带参数的非线性激活函数(parametric rectified linear unit,PReLU)来提取特征。BN将各层的数据分布强制转换为正态分布,使得网络的收敛速度加快。PReLU是带有参数的非线性激活单元,用来非线性激活标准化数据。最终通过1×1卷积滤波器产生一个与网络输入具有相同分辨率的预测稠密深度图。
VGGNet不参与模型的学习,仅使用预训练的权重为DepthNet和PoseNet提供用于训练或者网络输入的RGB图像的特征图。

图2 DepthNet网络架构
1.3 PoseNet
PoseNet共分为4个子网络。如图1所示,将当前帧RGB1和附近帧RGB2作为第1个子网络的输入。VGGNet分别提取RGB1和RGB2的3组不同级别的特征图。3组不同的特征图分别作为其他3个子网络的输入。
PoseNet输出6自由度相对姿势[R|t]。其网络架构如图1所示。每个子网络共3层,以从RGB或者特征图像中提取更多特征。位姿网络先对RGB或者特征图在通道上进行叠加,然后叠加后的图像进行卷积操作提取特征。PoseNet采用ReLU作为激活函数。在输出阶段,融合4个子网络最终的特征图,再经过2次卷积得到[R|t]。
1.4 损失函数
系统需要训练DepthNet和PoseNet两个网络模型。在训练期间,使用深度损失加速DepthNet模型的收敛速度。使用当前帧RGB1和重建的当前帧RGB1′的光度误差、轮廓误差以及它们的三个特征误差纠正预测深度图的结果,同时优化当前帧与附近帧的相对位姿。
深度损失:在深度网络模型的训练期间,使用原始深度约束预测出来的稠密深度图。具体而言,如果预测的深度图在原始深度图对应的位置有数据,那么对这两个数据之间的差异进行惩罚。深度损失定义为
(1)
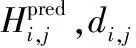
图像重构:给定相对变换[R|t]和当前深度预测Hpred,可以将附近帧RGB2反向扭曲到当前帧RGB1上。具体来说,通过式(2)可以建立起RGB2与RGB1任何像素对应的投影关系
u2=K[R|t]spredK-1u1
(2)
式中spred为预测的稠密深度图在RGB1像素坐标u1下对应的深度值,K为相机内参,[R|t]为两帧之间的变换矩阵,u2为RGB2对象对应的坐标位置。通过式(2)的对应关系,利用双线性采样将RGB2合成为RGB1视角下的RGB1′图像
RGB1′=C(RGB2,[R|t],Hpred)
(3)
式中C为RGB2与RGB1像素对应的投影函数。
光度损失:光度损失的目的是使当前帧RGB1与重建的当前帧RGB1′之间的像素级差异最小化,从而迫使网络预测更精确的稠密深度以及位姿。其定义为
Lphoto=∑s∈S‖I1-I′1‖1
(4)
式中S为图像的尺度,I1和I′1为图像RGB1与RGB1′在像素点s上的颜色强度。
轮廓损失:为了提高深度估计在边缘处预测的准确性,提出了轮廓损失,目的是加大对轮廓处的惩罚。轮廓使用基本梯度获取,其定义为
g=(f⊕b)-(f⊖b)
(5)
式中g为基本梯度图像,f为原始图像,b为结构元素,⊕为膨胀操作,⊖为腐蚀操作。
RGB图像与其轮廓的结果如图3所示。将RGB1和RGB1′提取的轮廓图像直接相减,来加大对边缘处的惩罚力度。轮廓损失定义为
Lcontour=‖I1C-I′1C‖1
(6)
式中I1C和I′1C为图像RGB1与RGB1′在各自轮廓上的强度。

图3 RGB图像与其轮廓
特征损失:使用VGGNet提取RGB1与的3个不同级别的特征图,如图1所示,通过特征误差解决RGB图像易受光线影响的问题。特征损失的具体定义为
(7)
式中S为特征图的集合,f1和f′1为图像RGB1与RGB1′在第s个特征图上的特征值。
整个自我监督框架的最终损失函数包括4项
L=α1Ldepth+α2Lphoto+α3Lcontour+α4Lfeature
(8)
式中α1,α2,α3,α4为超参数。根据经验,最终将超参数分别设为0.8, 0.6, 0.6, 0.6。
1.5 三维重建
为了保证三维重建的分辨率、灵活性和适应性,使用Surfel的方法进行重建。本文利用第一帧图像及预测的稠密深度图初始化Surfel,构建并维护覆盖可见表面的无序集。每个Surfel有7个属性。其数学形式为S=[p,n,c,w,r,t,i],p为3个自由度的位置变量,n为3个自由度的法线变量,c为颜色强度,w为置信度,r为用于近邻搜索的半径,t用于检测临时异常值或动态对象,i为观察Surfel的最后一个帧。
在给定当前相机姿态估计[R|t]的情况下,可以利用曲面之间的相对位姿将局部曲面的位置和法线变换为当前帧。其融合如式(9)所示
(9)
式中 脚标b为之前建好的Surfel,l为局部Surfel。
2 实验与分析
2.1 数据集与实验环境
数据集:使用SUN RGB—D[11]数据集对网络进行训练,该数据集包含1万幅经过优化的RGB-D图像。使用TUM RGB-D[8]和ICL-NUIM[9]两个公共基准数据集的序列进行测试。
实施细节:本文在Pytorch中实施了训练框架。以图像原始分辨率作为网络的输入,批量大小为4,在单块NVIDIA TITAN X上进行训练。总共设置3个级别的特征图计算特征损失,每个级别的尺寸是上一个级别的50 %。使用零均值高斯随机初始化网络权重,采用Adam进行网络优化,学习率设为10-4,采用学习率衰减法,每2轮迭代学习率降低50 %。总共训练50轮。
2.2 实验结果与分析
采用文献[12]中使用的相同序列进行评估,并与他们报告的结果进行比较。根据文献[12]的评估方式,使用正确深度百分比(percentage of correct depth,PCD)和绝对轨迹误差(absolute track error,ATE)作为室内数据集的评估标准。PCD定义为绝对误差小于真实深度10%的深度预测百分比。ATE是一个公认的评估摄像机轨迹质量的指标,它被定义为估计的和真实摄像机轨迹之间的均方根误差。
数据集PCD的比较结果如表1所示。除了ICL/Living2序列以外,在所有的序列中都取得了显著的进步。这表明了本文的方法可以提升网络的性能。此外,可以看出,基于学习的方法比纯几何系统(REMODE[4])有明显的优势,这表明了基于学习的方法在稠密三维重建中的作用。
室内数据集ATE的比较结果如表2所示。可以看出,所提方法总体上优于其他方法。这主要取决于使用RGB图像以及特征图作为PoseNet的输入。同时,基于特征的损失在联合优化深度与位姿的时候,起到了重要的作用。
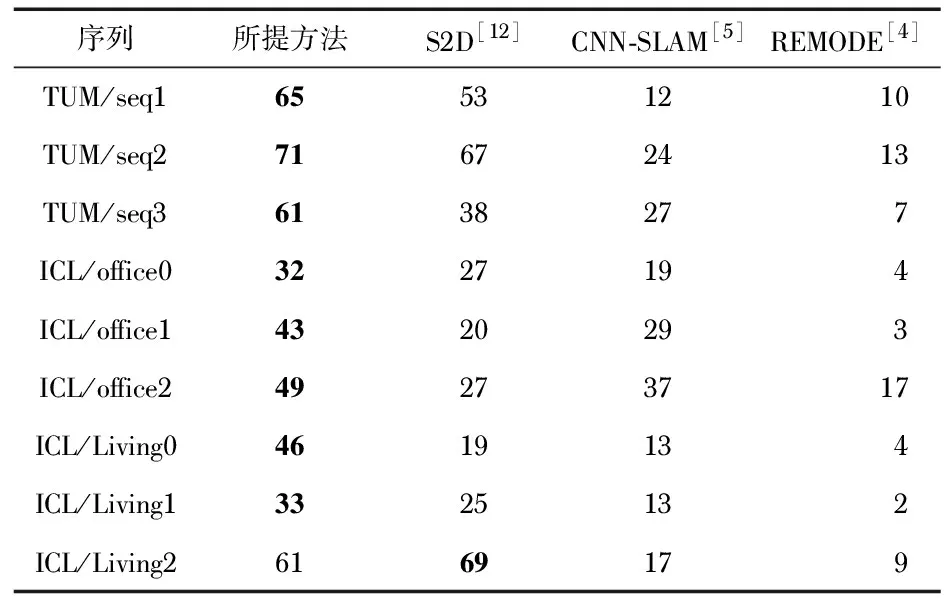
表1 TUM RGB-D和ICL-NUIM数据集PCD比较

表2 TUM RGB-D和ICL-NUIM数据集的绝对轨迹误差 m
图4中显示了TUM RGB-D数据集部分图片深度图的定性结果。通过定性的结果来看,预测的深度图像还具有更清晰的对象边界;同时所提的方法克服了玻璃等一些特殊物体对深度相机的影响。

图4 TUM RGB-D数据集部分图片的深度图对比结果
此外进行了单张图片的重建,以直观地评估所提方法。如图5所示,所提方法的重建分辨率更高,可以实现对黑色物体(电脑屏幕),以及玻璃的重建。

图5 TUM RGB-D单张RGB图像三维重建结果
为了进一步证明所提方法的有效性,对TUM RGB-D部分图片进行三维重建。如图6所示,所提方法可以对室内进行有效的重建。

图6 TUM RGB-D部分场景三维重建结果
3 结 论
针对室内稠密三维重建的问题,提出了基于深度估计与自我运动联合优化的三维重建。创新性地提出了轮廓损失,设计了特征图的损失。实验结果表明:所提方法在TUM RGB-D,ICL-NUIM数据集上,明显地提高了深度图的质量、定位结果以及三维重建的效果。
猜你喜欢
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
时代英语·高一(2019年5期)2019-09-03
山东工业技术(2019年16期)2019-07-19
科技资讯(2016年25期)2016-12-27
科学与财富(2016年29期)2016-12-27
中国文化遗产(2016年5期)2016-12-14
电脑知识与技术(2016年20期)2016-08-19
大灰狼(2009年7期)2009-08-26
舒适广告(2008年9期)2008-09-22
