
计算机视觉技术应用研究综述
2022-10-14 06:54王锦凯宋锡瑾
计算机时代 2022年10期
王锦凯,宋锡瑾
(1.阿里巴巴(杭州),浙江 杭州 310023;2.浙江大学)
0 引言
计算机视觉(Computer Vision,CV)是进入二十一世纪之后非常活跃的研究方向,随着图像采集设备的不断推陈出新,视觉信息生产的爆炸式增长,机器算力的不断提升,以及深度神经网络模型的提出,视觉领域的图像处理技术日新月异,所适用的领域场景在不断拓宽,新的问题在被不断定义。
传统的图像采集设备如摄像机,监控探头,主要采集可见光波段的信息,形成图像或者视频记录下来,其携带起来比较笨重,采集范围很有限。现如今各种移动设备和专业仪器的加入,采集的信息已经拓广至各电磁波波段,而由此也促使信息呈爆炸式增长,为计算机视觉领域算法的训练提供了大量的可用样本,大大降低了获取数据的难度和成本。
另一方面,GPU(Graphics Processing Unit,图形处理器)的引入,为深度学习和并行计算插上了强有力的翅膀。以往的纯CPU 计算,在面对诸如矩阵运算,像素块卷积时,只能线性的一个接一个执行加减乘除,极大地限制了吞吐速度,而GPU 在诞生伊始,为了符合图像和视频的处理场景条件,设计上需要并行处理各个像素点或者像素块的数学计算,因此天然带有了上千上万个算术逻辑单元(Arithmetic Logic Unit,ALU),对于处理互不相关独立的数学计算非常方便,也大大加速了深度学习在计算和推理过程中经常出现的矩阵运算。
由于数据和算力的充足,进入二十一世纪以后,之前几乎被人抛弃的神经网络模型被再次提及,进化为更大型更多层的深度神经网络,因深度学习的泛化能力强,需要的先验知识少,同时又能很好地利用目前大量的数据,成为了到现在为止占据主导的算法。
本文接下来着重于阐述当前计算机视觉在几个领域的应用场景,并提出一些可能的拓展,对未来的边界予以展望。
1 研究进展
计算机视觉目前主流的任务有四类:分类(Classification),检测(Detection),识别(Identification),分割(Segmentation)。分类,即对一幅图片进行一个整体的划分,研究者关注在一个图片中占主要部分的物体的类别。分类的范围是图片的粒度,常见的公开数据集比如ImageNet,MNIST 都是以这样的方式进行分类,再用于后续的训练和测试。检测,则是对图像中物体进行几何定位,以包围框(BoundingBox)的形式,把它框定出来,用于后续的识别。识别则是准确地判断出这个物体是什么或者是什么意思,最典型的比如人脸的重识别(Re-Identification),行人的重识别等。最后是分割,其目的比检测更进一步,在像素级别对图像本身进行区分,划分出像素来自于不同的物体,以分割为基础,后续做AR/VR 互动的时候,可以让真实世界准确的与虚拟世界进行交互,模拟现实世界的物理特性。
在深度神经网络被大范围应用之前,计算机视觉面临的最重要的门槛就是特征工程。顾名思义,需要找到合适的特征来对你的研究对象进行表征(比如经典的Scale-invariant feature transform,SIFT 和Histogram of Oriented Gradient,HOG),好的特征需要对研究对象有足够的了解才能够获得,比如早期的人脸识别,相关研究者通过提取出人脸上一些关键的部位和比例构成一个特征向量,并以此来训练一组或者多组分类器,最终可以得到一个比较理想的人脸识别。但是在寻找合适的特征,组合合适的分类器过程当中需要大量的试错,也需要实验的人有很丰富的经验,因此这种做法很难推广到其他各个领域,每个领域都需要很多专业知识来对特征进行选取,无疑需要很高的人力成本和时间成本。
深度卷积神经网络(Convolutional Neural Networks,CNN)的引入为研究者们打开了新的大门,虽然CNN的概念早在上世纪八十年代就有被提及,但是浅层的CNN 的效果并不如前面提到的特征工程+分类器的方式。直到数据和算力的具备才使得深层的CNN 成为可能。现今,业界的主流骨干架构(Backbone)以CNN 为主,算法工程师们通过对经典骨干架构改造和调优,可以快速适配业务,将模型迁移到自身的垂域上去。而开发工程师则尝试从整个模型的训练,测试,推理等各个阶段进行加速,继续降本提效。
2021 年,谷歌将之前自然语言处理领域(Natural Language Processing,NLP)比较火热的Transformer(变形模型)引入到计算机视觉领域,其核心是注意力模型。在该领域,研究者们致力于寻找词与词之间的联系,给定一组输入的词汇,可以找到与其有强关联的词汇输出,使得机器可以更好地理解人类的语义。而将这个技术引入到视觉领域之后,将一幅图像,切割为多个方块,每个方块有其自有的位置信息保留,然后一并输入到Transformer 的架构中进行训练。在这个过程当中,把这样的一个个图块,看作了一个个单词输入,而其输出亦可以是一个单词或者是一组单词,不管什么样的训练任务,最终都能抽象为一些“词”的输入,得到另一些“词”的输出。因为在NLP 领域取得的成功,以及在CV 领域的许多任务中取得了不亚于甚至超过CNN框架的准确率,Transformer目前大有取代CNN成为新的行业标杆的趋势,正吸引着越来越多的研究者进行探索。
2 技术领域应用
2.1 视频分析领域
随着5G时代的来临,人们获取信息的主要方式已经从文字和图像过渡到视频和语音,其携带的信息量成倍的提升,为了能够更好地存储,管理以及使用这些海量视频,视频分析成为一个必备的手段。视频分析主要是通过计算机视觉的技术手段,将视频当中的内容进行分析,转换成一些结构化,半结构化的信息。这些信息会更有利于使用数据库进行存储,同时帮助计算机像人类一样去理解一个视频。
一般常见的视频分析流程如图1所示,首先,对一个视频进行解封装和解码,得到逐帧的图像。之后对得到的帧进行下采样,这样做的原因,一方面是视频当中图像的变化,一般不足以快到只持续几帧,目前通过网络传输的视频的帧率在20fps 到30fps,适当地采样不会影响算法精度;另一方面,通过下采样,也能提升系统的处理吞吐速度,节省成本。之后视觉算法会对帧图像进行诸如分类,检测,识别,分割等任务的执行,这里主要看实际应用的需求场景以及所预计的计算成本,收益如何。
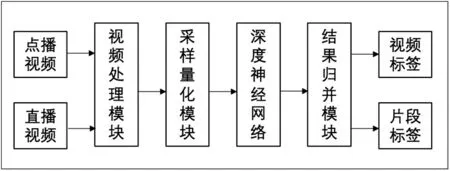
图1 视频分析的常见流程
经过视频分析得到的结果主要分成两部分:整个视频级维度的部分和片段(clip)维度的部分。视频级维度一般是一整个视频给出一个或者几个概括性的分类的结果,称之为标签,如“体育-足球”、“影视剧-故事剧”。标签的存在,帮助分析者对视频有整体的把握,实际应用场景下可以通过视频标签做后续的视频归档,视频推荐甚至简单的检索。片段维度的视频分析结果则复杂一些,每个片段结果由起止时间戳和分析结果构成,最常见的如人脸的标签,一般需要分析出一个人脸何时出现在视频的什么位置,这个人是谁,置信度有多少,如果无法在底库中命中已知的人脸,也可以在整个视频中标记出来为陌生脸X,以便进行后续的更新。再比如现在流行的直播带货视频,需要分析出每个商品出现的时间段,以及展示的是什么样的商品。有了这样的信息,便于研究者更精准的了解视频的内容,也可以很方便的进行视频片段的划分和精准投放,必要时也可以进行敏感人物,敏感场景的过滤删减。这对于当前的各个视频内容生产平台而言,是很必要的手段。
总的说来,视频分析能力已经成为视频网站,各大媒体和档案资料部门不可或缺的管理手段,视频分析能力的质量和效率,直接决定了其下游提供的各种服务能力和响应速度。在一个万物信息化的时代,以此为根据,越来越多的个性化分析能力必将成为这个细分领域不可缺少的能力。而随着生产和采集设备的多样化,视频分析结合多种多样的信息输入来提高其准确率和精度也将成为一个热门话题。
2.2 安防监控领域
安全领域是一个老生常谈的话题,而随着科技的不断进步,现阶段对安防提出了响应更快捷,处理更智能化的要求。
以校园安防为例,除了传统的摄像头布控和人工监控之外,AI技术的引入可以大大降低人力投入的成本,同时提高识别的效率和准确率,图2展示了当前智能安防系统的常见结构体系。校园安防首先需要对校园的全体师生和员工们进行人脸采集和分类标识,形成人脸底库。在日常的监控当中,部署在校园内外的各处的摄像头可以对出现的活体人脸进行检测,同时识别到是否有陌生人进入到校园附近的范围,并根据事先设定的阈值进行报警。陌生人脸经由老师或者学生辨认,可以加入到人脸底库成为可信人物或者上报到公安机关。在这个过程中,主要是使用各种目标重识别技术,如人脸重识别,行人重识别等。
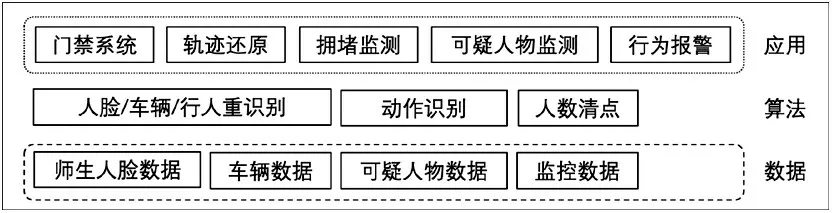
图2 智能安防的常见结构体系
通过对多个摄像头的数据综合,可以还原目标在校园内外的行动轨迹,便于对校园突发事件进行还原。此外,行为识别、拥堵检测也是常见的处理技术。行为识别,利用时间和空间上的数据可以检测出一些常见的行为,如走路,跑步,摔倒,打架,抽烟等,便于安保人员和有关领导快速掌握关键视频段落。而拥堵检测,可以对框定范围内的区域进行人头数清点,一旦满足一定的预设阈值,则会进行拥堵报警,便于安保人员进行提前到场进行人流疏散。
可以说校园安防是一个计算机视觉处理技术综合应用的典型场景,除了应用于校园,诸如公司园区,工厂厂区等也正在尝试接入这种新型的管理方式。视觉处理的算法技术应对这些场景,一般只需要进行简便的参数调优,配置以相应的底库数据,以及和摄像头位置信息的互相配合,就可以达到比较好的效果。这使得大规模的推广智能安防落地成为了可能,同时日常采集到的大量视频和图片数据,则可以反哺背后的算法模型,不断提升其精度和准确率。各类园区有其实际的环境特性和工程部署难度,也需要技术人员在这个过程中不断积累经验,快速应对。
2.3 遥感影像领域
近年来,遥感卫星数量不断增长,在中国,每年有超过30颗的遥感卫星发射升空,这些遥感卫星被广泛用于气象,物种资源,测绘等领域,给相关研究人员带来了海量的多波段数据。另一方面,随着无人机更多的民用化,商用化,大量的低空飞行器也为人们带来了粒度更细,分辨率更高的地面视频和图像。丰富的影像数据和不断发展的计算机视觉技术叠加,催生出了新一代的遥感+AI视觉技术。
遥感影像的常见分析任务包含但不限于地物分类,变化检测,路网提取等。地物分类,是对图像上的物体进行分类,比如楼房,道路,水域,耕田等。虽然是一个分类问题,本质上是一个视觉里的分割任务,最终输出的结果是对遥感影像里的各种语义进行着色,凸显其边界和范围。有了地面物体的信息之后,既可以在时序上对比前后两次的遥感影像,进行变化检测。也可以在空间上进行路网,水网信息的提取,获得一个城市的“脉络图”。变化检测可以被用于检测季节的变化,自然灾害带来的变化,如洪涝,暴雪,地震等,以及人为带来的变化,比如城市发展建设,退耕还林等。而路网,水网的信息提取则为把控地理空间上的信息提供了有力的帮助,通过对遥感影像的分析,可以大范围,快速高效地进行路网提取,再进行从影像到地理坐标系的映射,最终可将其纳入到地图系统当中用于导航和提供基于地理信息的服务。
以上介绍的一些任务主要集中在可见光波段,而事实上,遥感卫星所提供的数据,覆盖了从整个可见光波段,再到近红外,短波红外以及热红外波段,这些波段的数据,同样拓展了更多地物分类的场景以及语义,也使得计算机视觉技术加持的遥感影像分析可以被运用到气象预报,极端自然灾害监测,森林火险预警,资源勘探等各种领域,这降低了处理海量数据的人工参与成本,同时提高了处理能力和响应速度,并能获得不俗的准确率和召回率。
2.4 其他领域
诸如此类的视觉应用领域还有许多,常见的有医疗领域根据核磁、CT、B 超影像的早期症状诊断;工厂流水线上根据图像识别来判断工件的质量,清点工件的数量;农业领域通过视觉的方式无接触的获取植物当前生长状况。限于篇幅此处不一一展开陈述。可以说一般只要拥有足够的规范数据和一个符合视觉任务的目标定义,都可以让计算机视觉技术一展身手。
3 结束语
本文主要介绍了当前的计算机视觉图像处理技术在视频分析,安防监控以及遥感影像分析等几个领域的应用场景。对于其带来的降低人工处理分析成本,同时提高处理效率的能力给予了肯定,也探讨了其可能的边界拓展并展望了其在未来的价值。
可以说,目前的计算机视觉发展重点已经从基础能力的构建逐渐过渡到细分垂直领域的探索了,虽然近年来有像Google 提出的Transformer 模型逐渐进入到视觉领域,但是就目前看来,其本身的提升效果和幅度依然不够明显,泛化效果不如卷积神经网络,性价比在工业界还达不到让大家为此去重新设计底层部署逻辑与推理加速框架的地步。另一方面,计算机视觉本身的能力越来越成为一个基础的模块被集成在某个领域的大系统当中去发挥具体的作用,由于理论和工程能力的不断成熟,其应用门槛也在不断降低,正逐渐成为一个普惠的技术存在。
正因为如此,当下研究的方向如果单纯从提高模型的准确率和召回率的角度出发,实际的应用价值比较低,也难以很快大范围地推广。更多时候带来最终表现提升的往往是大量优质的数据和处理数据的方式方法。作为一门偏技术性的学科,拥有一些工程和实践思维在目前来说更为重要,从降低使用成本,提升训练和推理的效率,提高泛化能力,降低应用门槛和操作难度等这些角度去定义问题将更有实际意义。接下来的应用研究方向,将是朝着更便捷的部署,更快的响应速度,更广阔的适用范围,更灵活的自定义配置去落地实施。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
小学科学(学生版)(2021年7期)2021-07-28
作文小学中年级(2020年6期)2020-07-24
科技传播(2019年22期)2020-01-14
青年生活(2019年23期)2019-09-10
消费导刊(2017年20期)2018-01-03
中共南宁市委党校学报(2015年4期)2015-02-28
衡阳师范学院学报(2015年3期)2015-02-10
自然资源遥感(2014年3期)2014-02-27
中国音乐教育(2014年7期)2014-02-06
