
空气质量数据的校准研究
2022-10-21 14:01崔亚
科学技术创新 2022年30期
崔 亚
(西安职业技术学院 基础课教学部,陕西 西安 710077)
引言
随着大气污染越来越严重,需利用国控点和自建点对“两尘四气”的浓度进行实时监测。考虑到国控点数据较为准确,但国控点的布控较少,数据发布时间滞后较长且花费较大,而自建点花费小,能实时网格化监控,但数据不准确。本研究对国控点数据和自建点数据进行探索性数据分析;对两个监测点数据造成差异的因素进行分析;根据国控点数据建立相关的数学模型,并对自建点数据进行校准。
1 模型假设
(1) 假设国控点的数据为标准值,不受天气等因素干扰。(2) 假设自建点对温度、湿度、风速、气压、降水的检测值相对标准。(3) 假设自建点的数据没有异常值。
2 数据分析[1]
为了对自建点数据与国控点数据进行探索性数据分析,本研究将自建点数据与国控点数据进行了预处理,用MATLAB 软件编程得到了数据行数一样的两个表,分别为自建点数据表和国控点数据表。
2.1 描述统计量分析
利用SPSS 软件分别对了国控点数据、自建点数据进行描述统计量[2]见图1 和图2,其中统计数据有效值为3 954,每项的最高点和最低点对应数据的最大值和最小值;标记*为数据的均值;箱型的上边和下边对应均值±标准差/2 的值。

图1 国控点数据统计量
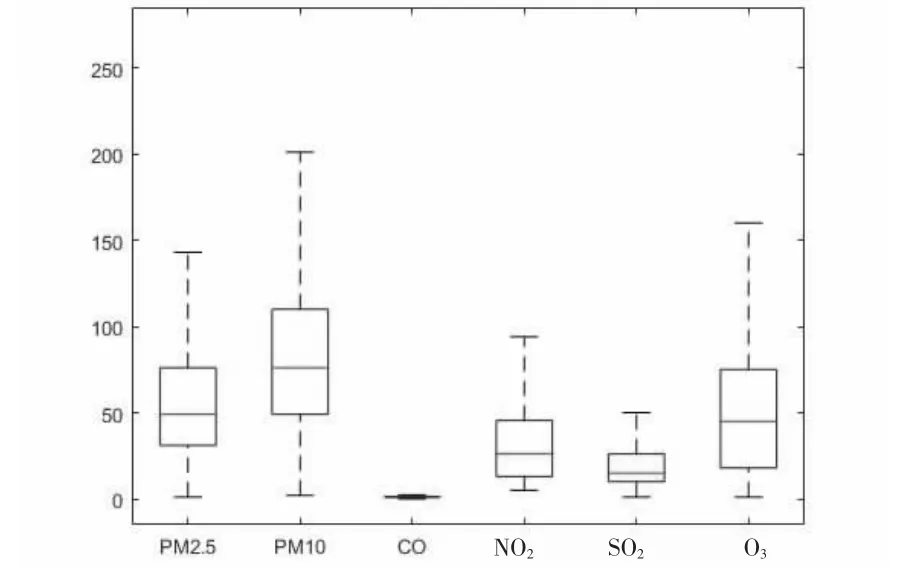
图2 自控点数据统计量

表1 双因素线性回归模型与全因素线性回归模型统计结果汇总
根据SPSS 的描述性数据统计,在统计数据有效值为3954 且国控点数据与自建点数据均同时测得的情况下对“两尘四气”分别对比分析,得到如下结论:自建点的PM2.5,PM10,CO,NO2的方差均大于国控点的PM2.5,PM10,CO,NO2的方差,自建点的SO2,O3的方差均小于国控点的PM2.5,PM10,NO2的方差。由此可知自建点除SO2和O3的离散程度小于国控点,其余的离散程度均大于国控点[3],因此自建点的SO2和O3具有一定的可靠性。
2.2 配对样本T 检测[4]
分别对自测点数据(Z)与国控点(G)数据进行配对样本T 检测。根据SPSS 软件配对样本T 检测得:自建点PM2.5 与国控点PM2.5 的数据量为3 954,两者之间的相关系数为0.871,相关系数的估计标准差为0;自建点PM10 与国控点PM10 的数据量为3 954,两者之间的相关系数为0.628,相关系数的估计标准差为0;自建点CO 与国控点CO 数据量为3 954,两者之间的相关系数为0.325,相关系数的估计标准差为0;自建点NO2与国控点NO2数据量为3 954,两者之间的相关系数为0.381,相关系数的估计标准差为0;自建点SO2与国控点SO2的数据量为3 954,两者之间的相关系数为0.041,相关系数的估计标准差为0.01;自建点O3与国控点O3的数据量为3 954,两者之间的相关系数为0.4,相关系数的估计标准差为0。
我们发现,自测点PM2.5 和PM10 与国控点PM2.5和PM10 强相关(相关系数大于0.5),除SO2所有数据都不是正态分布,是存在显著性差异的[5]。
2.3 回归性分析[6]
通过以上数据分析,发现自建点数据与国控点数据存在着一定的差异性,接下来对造成差异性的因素进行回归性分析[7]。
由表2 可知:模型PM2.5、PM10 和SO2的R 值大,说明拟合优度大,用双因素线性回归模型拟合更好。模型CO、NO2、O3的R 值大,说明拟合优度大[8],用全因素线性回归模型拟合更好。

表2 多元性线性回归模型系数汇总表
3 模型的建立[9]
我们分别以国控点的 PM2.5、PM10、CO、NO2、SO2、O3作为因变量,以自建点的全部变量作为自变量,通过以上分析,我们建立如下的多元线性回归模型:
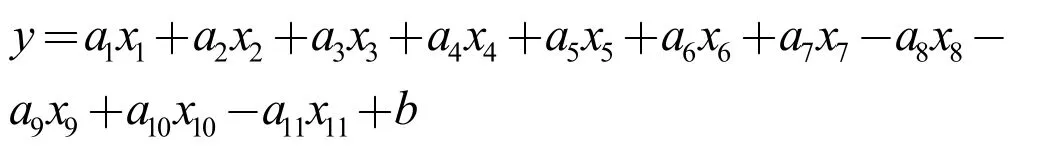
式中y 为因变量,xi为自变量,ai为系数,b 为常数。
选用了国控数据与自建数据中2/3 数据,利用SPSS 得出多元线性回归模型[10]。
依据以上模型系数汇总表,可以分别得出PM2.5、PM10、CO、NO2、SO2、O3的线性回归模型[10],汇总如下:PM2.5 模型:PM2.5 = 0.729x1 + 0.022x2 + 3.946x3+ 0.106x4 + 0.010x5 + 0.041x6 + 0.720x7 - 0.090x8 -0.043x9 + 0.233x10 - 0.260x11 + 98.224 ;PM10 模型:PM10 = 0.807x1 + 0.050x2 + 43.970x3 + 0.303x4 +0.057x5 + 0.059x6 - 3.094x7 - 0.269x8 - 0.101x9 +0.103x10 - 0.966x11 + 326.699 ;CO 模 型:CO =0.014x1 - 0.004x2 + 0.700x3 + 0.001x4 - 0.174x7 -0.005x8 + 0.011x10 + 0.001x11 + 5.127 ;NO2模型:NO2= 0.552x1 - 0.228x2 - 24.337x3 + 0.475x4 +0.079x5 - 0.110x6 - 14.319x7 - 0.093x8 - 0.045x9 -0.957x10 - 0.462x11 + 164.083 ;SO2模 型:SO2=0.076x1 - 0.056x2 + 65.467x3 - 0.154x4 - 0.107x5 +0.226x6 - 1.894x7 + 0.028x8 + 0.030x9 + 0.456x10 +0.012x11 - 44.861 ;O3模型:O3= 0.260x1 - 0.134x2 -59.467x3 - 0.330x4 + 0.129x5 + 0.185x6 + 17.902x7 +0.226x8 + 0.010x9 + 1.897x10 - 0.285x11 - 159.526。
4 模型的验证
为了验证上述模型的准确性,选取国控点数据与自建点数据的后1/3 数据作为样本来检验[11-12],得出检验结果。下面通过一些例子介绍一下检验数据的校准结果。
(1) 以2019 年3 月24 日20 时为例,校准前数据PM2.5:88,PM10:121,CO:1.16,NO2:45,SO2:19,O3:108,校准后数据PM2.5:87,PM10:121,CO:1.3,NO2:52,SO2:23,O3:77;(2) 以2019 年3 月24 日22 时为例,校准前数据PM2.5:81,PM10:123,CO:1.19,NO2:53,SO2:19,O3:88,校准后数据PM2.5:89,PM10:121,CO:1.4,NO2:53,SO2:19,O3:75;(3) 以2019 年3 月25 日2 时为例,校准前数据PM2.5:86,PM10:116,CO:1.22,NO:30,SO2:24,O3:87,校准后数据PM2.5:90,PM10:113,CO:1.3,NO2:38,SO2:14,O3:84;(4) 以2019 年3 月25 日3 时为例,校准前数据PM2.5:88,PM10:110,CO:1.27,NO2:23,SO2:21,O3:91,校准后数据PM2.5:88,PM10:109,CO:1.4,NO2:40,SO2:15,O3:77。
通过SPSS 将检验数据结果与国控点的数据进行相关性分析[13]得出:每个数据的Pearson 均大于0.5,说明该模型算的结果误差很小[14],该多元线性回归模型具有一定可靠性。
5 模型的求解
通过上述模型的验证,得出所建模型的可靠性和准确性,故将自建点中的数据分别带到我们建立的模型中,用EXCEL 软件计算出自建点校准后的数据[15]。下面以部分计算数据结果为例进行介绍。
(1) 以2018 年11 月14 日10:02 时为例,自建点 原 数 据PM2.5:50,PM10:98,CO:0.8,NO2:62,SO2:15,O3:46,校准后数据PM2.5:43,PM10:83,CO:0.6,NO2:65,SO2:35,O3:33;(2) 以2018 年11 月14 日10:10 时为例,自建点原数据PM2.5:49,PM10:94,CO:0.7,NO2:59,SO2:15,O3:50,校准后数据PM2.5:42,PM10:75,CO:0.4,NO2:53,SO2:20,O3:58;(3) 以2018 年11 月14 日10:24 时为例,自建点原数据PM2.5:48,PM10:93,CO:0.7,NO2:57,SO2:15,O3:54,校 准 后 数 据PM2.5:42,PM10:74,CO:0.4,NO2:47,SO2:18,O3:66;(4) 以2018 年11 月14 日10:42 时为例,自建点原数据PM2.5:42,PM10:85,CO:0.7,NO2:55,SO2:15,O3:57,校准后数据PM2.5:38,PM10:76,CO:0.6,NO2:57,SO2:28,O3:56。
该模型较准确的对国控点数据与自建点数据所产生的差异进行了分析和校准;模型相对简单,便于计算;该模型还可直接用于以后时间自建点对空气质量采集数据的研究。
猜你喜欢
电脑爱好者(2020年19期)2020-10-20
数学学习与研究(2018年14期)2018-10-29
软件导刊(2018年3期)2018-03-26
初中生世界·九年级(2017年10期)2017-11-08
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
电脑知识与技术(2016年7期)2016-05-19
科技与创新(2014年11期)2014-08-21
中学数学杂志(初中版)(2014年1期)2014-02-28
