
基于TextRNN 与TextCNN 的情感分类对比研究
2022-10-21 14:01付甜甜刘海忠
科学技术创新 2022年30期
付甜甜,刘海忠*
(兰州交通大学 数理学院,甘肃 兰州 730070)
引言
情感分类是根据人们对特定的对象或实体发布的观点、意见、态度等进行信息提取的计算性研究过程[1],属于文本分类的子问题。情感分类在舆情分析方面、产品及服务方面,能够辅助网络环境的监控和产品服务的改进。情感分类的研究方法主要有基于情感词典的方法、基于机器学习的方法和基于深度学习的方法[2]。由于情感词典和机器学习需要构建词典和庞大的特征工程,因而深度学习算法在情感分类中变得十分流行。
深度学习算法以低维连续的词向量来表示文本,解决了数据稀疏问题和特征构建的复杂问题。Moraes等[3]对支持向量机SVM和人工神经网络ANN 进行了文档分类的对比实验,结果表明ANN 的分类准确率比SVM要高。Kim[4]提出了使用文本卷积神经网络(Text Convolutional Neural Networks,TextCNN) 进行句子级情感分类,发现TextCNN 能够快速高效地完成文本分类任务。Liu 等[5]基于文本循环神经网络(Text Recurrent Neural Network,TextRNN)提出三种不同的信息共享机制来对文本数据进行建模。梁军等[6]讨论了在中文微博情感分类任务上使用深度学习算法的可行性。同时情感分类算法也在通过对预训练模型微调或融入注意力机制等方式[7]进行改进,而情感分类的融合算法大多建立在CNN,RNN 等模型上。主层算法的选择一定要依照任务特点和数据特征来构建,本研究对比CNN 和RNN 两个典型算法的表现来为主体算法的选用提供参考。
1 模型介绍
1.1 TextRNN
TextRNN 是用RNN 来处理文本分类问题。RNN能够顺序地读取文本序列数据,具有一定的记忆能力。本研究RNN 模型选用双向长短时记忆网络BiLSTM来进行实验。LSTM是RNN 的变体,它通过控制遗忘门、输入门和输出门三个门结构及细胞单元状态来控制数据信息的加工,可以避免梯度消失问题。BiLSTM拥有更大的感受野,双向提取语义关联信息以获得高层特征表示。在建模时,一组向量分别作为正向和反向LSTM的输入:
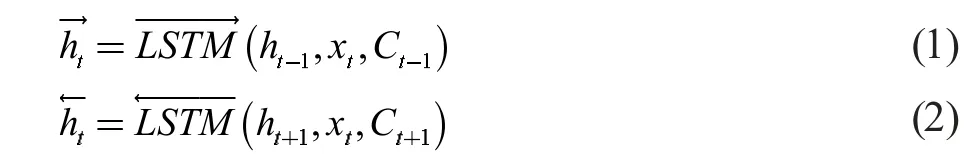
连接正反方向LSTM处理后的序列输出,BiLSTM在t 时刻的输出则表示为:

TextRNN 模型结构见图1,单词先通过嵌入层转化为特征词向量,然后使用BiLSTM 对序列张量进行信息提取。将BiLSTM 的最初时间步和最后时间步的隐藏单元连结,作为特征序列的表征传输到全连接层再进行分类。

图1 TextRNN 结构
1.2 TextCNN
CNN 提取特征信息时可以把文本数据理解为一维图像,卷积核在文本表示矩阵上上下滑动来进行特征提取。句子向量化得到矩阵V(wi),采用Fk=k*d 维卷积核与其进行卷积计算

ci表示经过一次卷积计算得到的局部特征值,滑动一轮后得到一个完整的局部特征向量C。为了降低向量维度,卷积后还要进行池化操作。
TextCNN 模型结构见图2,先将单个文本序列输入转换为词向量矩阵输出,然后定义多个尺度的卷积核,分别执行卷积操作。在所有输出通道上执行时序最大池化,将所有池化后的特征向量汇聚连结为新的特征向量,最后放入全连接层进行分类。
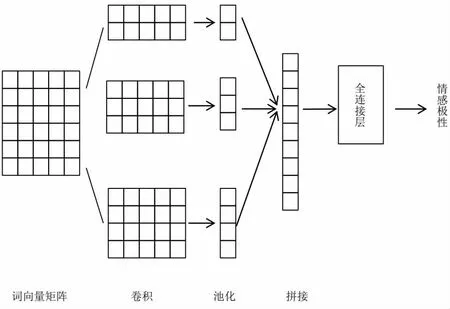
图2 TextCNN 结构
2 数据说明及处理
本研究实验使用IMDB 数据集,包含来自互联网电影数据库的50 000 条评论数据,情感类别为positive 和negative,按照1:1 划分为训练集与测试集。首先对数据中的标点符号和无用字符进行清洗,随后进行分词操作并过滤掉出现频率少于5 次的单词,然后创建一个属于训练集的词典。由于评论长短不一,通过截断和填充将每条评论的长度都控制在500 个单词,分词后进行向量化。使用斯坦福的Glove 预训练词向量来做嵌入,包含了400 000 个单词的嵌入向量,在训练期间不更新词向量。
3 实验与分析
3.1 参数设置
TextRNN 是一个具有一层嵌入层、两层隐藏层和一层全连接层的双向神经网络。隐藏单元数设为100,学习率设为0.01,batch_size 为64,epoch 为5。
TextCNN 使用两个嵌入层,其中一个是可训练权重,另一个是固定权重;三个卷积层,卷积核大小分别为[3,4,5],每个卷积核的数量为100,通道数为100,步长为1,使用RELU 激活函数;池化层采用时序最大池化,后面接上全连接层。dropout 设置为0.5,学习率设为0.001,batch_size 为64 ,epoch 为5。
3.2 机器学习对比模型
利用机器学习的逻辑回归模型LR、支持向量机模型SVM 和朴素贝叶斯模型NB 对实验数据进行分类,结果见表1。本研究实验均采用分类准确率来评估分类效果。可以看出在IMDB 数据集上三个算法的测试结果并不是很理想,其中SVM的分类准确率只有51.12%,LR 和NB 可以达到75%左右。

表1 机器学习模型准确率
3.3 对比模型说明
LSTM:含双层隐藏状态的单向网络,其余参数设置与TextRNN 相同。
TextCNN_1:由卷积核大小为3*3 的3 个同类型卷积核构成,其余设置与TextCNN 完全相同。
TextCNN_2:由卷积核大小为4*4 的3 个同类型卷积核构成。
TextCNN_3:由卷积核大小为5*5 的3 个同类型卷积核构成。
3.4 实验结果与分析
与机器学习相比,深度学习算法不仅特征构建更为简单,分类准确率也会有大幅提升。下面结合表格数据来进行详细分析。在预训练词向量维度分别为50和100 时,各模型分类准确率见表2。
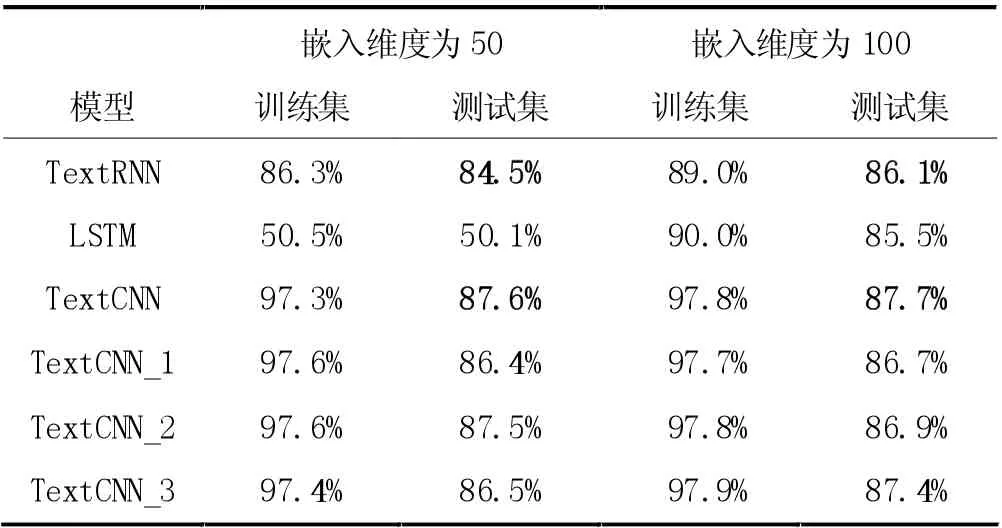
表2 各算法分类准确率
当词嵌入维度为50 时,TextRNN 在测试集上的分类准确率为84.5%,而LSTM只有50.1%。TextCNN的分类准确率为87.6%,比TextRNN 高出3.1%。使用同类型卷积核的三个TextCNN 模型分类准确率分别为86.4%、87.5%、86.5%,结果相差不大,但准确率都要比RNN 高。
在词嵌入维度为100 时,发生显著变化的是LSTM,分类准确率提升了35.4%,达到了85.5%,而TextRNN 的分类准确率达到了86.1%,比单向算法的准确率高0.6%。TextCNN 的准确率达到87.7%,较三个使用同类型卷积核的TextCNN 要高一些,同样CNN的整体表现结果比RNN 要好。
实验结果表明,当词嵌入维度从50 维增加到100维时,所有模型在训练集和测试集的准确率都有所上升,说明嵌入维度是影响分类结果的一个重要因素。同时TextRNN、TextCNN 的分类结果比机器学习的最好结果高出10%左右。
4 结论
本研究在介绍TextRNN 与TextCNN 模型的基础上,分别对文本进行特征提取及分类。在本研究所使用的数据集上,TextCNN 拥有更高的分类准确率和稳健性,TextRNN 采用双向提取时表现结果也不错。结合各自的特点来讲,由于TextCNN 通过多尺度的卷积核组合进行特征提取,比起使用同类型卷积核的提取限制,对局部特征的提取更为精准细致。而RNN 更擅长处理长序列数据,获取更大范围的上下文信息。情感分类任务进行算法选择时,短文本可以选取多尺度卷积核组合的TextCNN,长文本选择双向提取的TextRNN 会取得相对较高的准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
