
基于机器学习的C4 烯烃收率的回归分析
2022-10-21 14:02范晓东张亚萍冯睿哲王勇皓
科学技术创新 2022年30期
范晓东*,张亚萍,冯睿哲,王 硕,王勇皓
(1.吉林化工学院 理学院,吉林 吉林 132022;2.吉林化工学院 信息与控制工程学院,吉林 吉林 132022)
C4 烯烃作为一种重要的化工原料,它被广泛的应用于医药和化工产品的生产。采用乙醇制备C4 烯烃具有巨大的经济效益和应用前景,近年来受到了国内外的广泛关注[1]。在制备过程中,温度和催化剂组合对C4 烯烃收率将产生影响。现研究如何选择温度和催化剂组合,使得在其它实验条件不变的情况下C4 烯烃收率尽可能高。随机森林是一类重要的机器学习算法,也是一类集成学习算法[2-3],被广泛应用于回归和分类问题[4-5],但基于随机森林的C4 烯烃收率的回归分析的研究还未见报道,本研究选取催化剂组合和温度为特征变量,建立基于随机森林的回归模型来预测不同催化剂组合和温度下的C4 烯烃收率。
1 随机森林回归模型

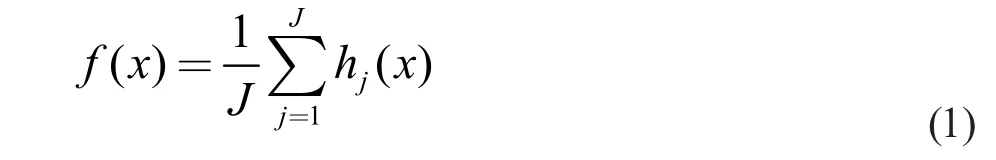
1.1 决策树
随机森林中使用的树是基于二叉递归分割树,这些树对每个变量进行二叉分割的方法,并对预测空间进行分割。树的根结点由整个的预测空间构成,没有被分割的结点被称为终端结点,它们最终形成了对整个预测空间的分割。每个非终端结点被分成两个子结点,即左结点和右结点。决策树的算法见文献[6]第8章。
1.2 随机森林算法
设D= {(x1,y1), …,(x N,yN)}表示训练数据,其中xi= (xi1,xi2, … ,xip)T。对于j= 1,2, …,J:
1.2.1 从D 中选取容量为N 的自助抽样样本Dj。
1.2.2 使用自助抽样样本Dj做为训练数据,使用二叉递归分割拟合一棵决策树。
(1) 对于每个结点都从所有观测变量开始。
(2) 对每个没有分裂的结点都递归地重复下面的步骤,直至停止规则被满足:a.从可用的p 个预测变量随机选择m 个预测变量;b.关于第i 步中的m 个预测变量的所有的二叉分裂中选择最好的二叉分裂;c.使用第二步中的分裂方法把这个结点分裂为两个子结点。
对于一个新的结点x,公式(1)中f(x)预测值为
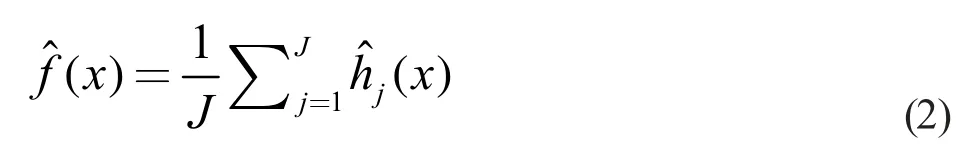
2 三次样条回归模型
本研究采用三次样条回归模型来拟合乙醇转化率与温度之间的关系,拟合C4 烯烃的选择性与温度之间的关系,假设乙醇转化率与温度可以由下列含有k 个节点的三次回归样条表示:
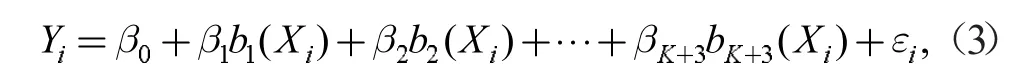
式中,Yi,Xi分别为乙醇的转化率和温度,b1(Xi),b2(Xi), …,bK+3(Xi)为样条基函数,β0, β1, β2, …,βK+3为回归系数,为误差项[6]。同理假设C4 烯烃的选择性与温度可以由下列含有k 个节点的三次回归样条表示
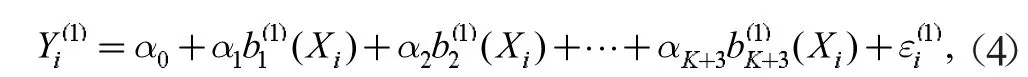
3 数据集介绍及插补
数据集来源于2021 年9 月全国大学生数据建模竞赛B 题,整理后数据集包含催化剂组合、温度和C4烯烃收率,其中催化剂组合包括SiO2的质量(mg)、Co的质量(mg)、HAP 的质量(mg)、乙醇加入速率(ml/min)和装料方式。本研究基于随机森林的方法建立C4 烯烃收率关于不同催化剂组合和温度的回归模型,然而,我们发现预测准确率偏低,因此对数据集进行了插补。在每种催化剂组合和装料方式下分别基于三次样条回归模型(3)和(4)建立乙醇转化率和C4 烯烃收率关于温度的样条回归模型,在本研究中采用在数据区域的均匀分布的方法选择3 个内结点,分别为25%,50%,75%分位数作为结点的位置,样条回归采用R 软件包splines 中的lm()函数进行拟合。图1 给出了利用三次样条回归得到的在催化剂组合A1 下乙醇转化率关于温度的图像。图2 至图4 分别给出了利用三次样条回归得到的在催化剂组合A1 至A3 下C4烯烃的选择性关于温度的图像。在其它催化剂组合下利用三次样条回归模型也得到了乙醇转化率关于温度的图像和C4 烯烃的选择性关于温度的图像。从图像可知,在其他条件保持不变的前提下,随着温度升高乙醇转化率呈上升趋势。但并非所有催化剂组合下均满足随着温度升高C4 烯烃转化率均呈上升趋势。例如A1、A3 两组随着温度升高,C4 烯烃选择性呈先上升后下降趋势,对于其它催化剂组合下随着温度不断上升,C4 烯烃选择性均呈上升趋势。进而,在每种催化剂组合和装料方式下分别预测温度为260℃、290℃、310℃和340℃的乙醇转化率和C4 烯烃选择性,通过计算乙醇转化率乘以C4 烯烃的选择性得到C4 烯烃的收率。我们把这些数据补充到原有数据集中,最后得到的数据集包含207 条数据,部分数据见表1。
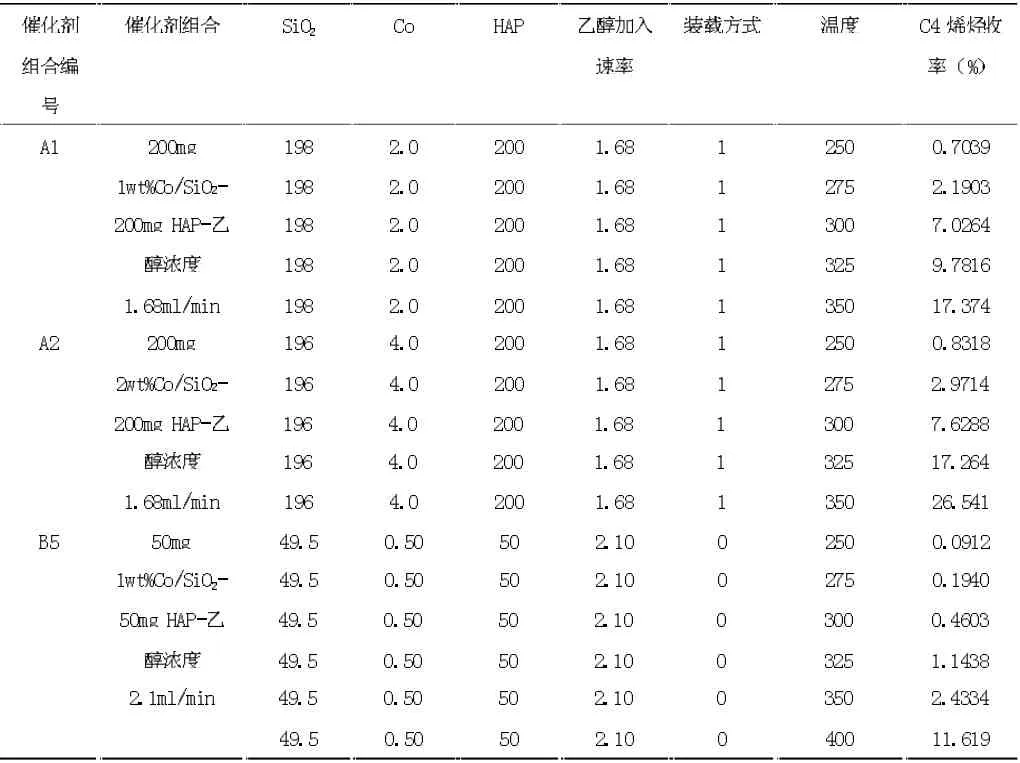
表1 C4 烯烃的收率数据

图1 催化剂组合A1 下乙醇转化率关于温度的图像
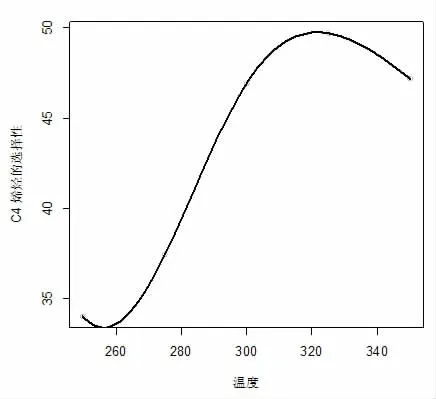
图2 催化剂组合A1 下C4 烯烃的选择性关于温度的图像
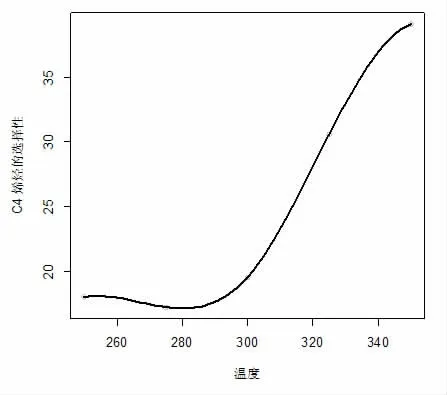
图3 催化剂组合A2 下乙醇转化率关于温度的图像
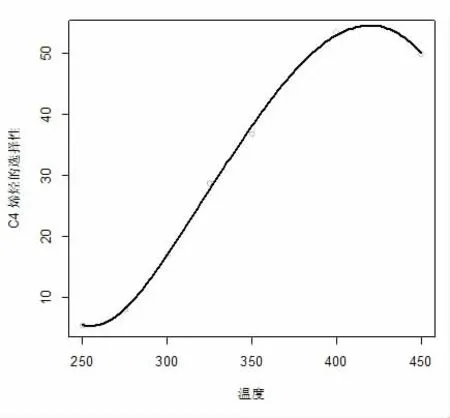
图4 催化剂组合A3 下C4 烯烃的选择性关于温度的图像
4 结果与分析
我们将上面的数据集随机分为一个训练集和一个测试集,采用R 软件包randomForest 来实现随机森林算法。选取=3个变量和500 棵决策树来建立随机森林,此时,足以提供良好的预测性能,得到测试的均方误差为10.7275,方差的解释性达到85.57%。我们利用得到的随机森林模型进行预测,通过尝试不同的催化剂和温度的组合,得到催化剂组合为A3 和温度为400℃时的预测结果达到最高值,此时C4 烯烃收率为34.795%。表2 给出了特征变量重要性的两个测度,其中%IncMSE 表示基于当前给定变量被排除在模型的时候预测袋外样本的准确性的平均的减小量。IncNodePurity 衡量由此变量导致的分裂点使得节点不纯度所减小的总量。图5 列出了各变量的重要性,结果表明,在所有的变量中温度、SiO2含量和HAP 的含量是目前最重要的三个变量。
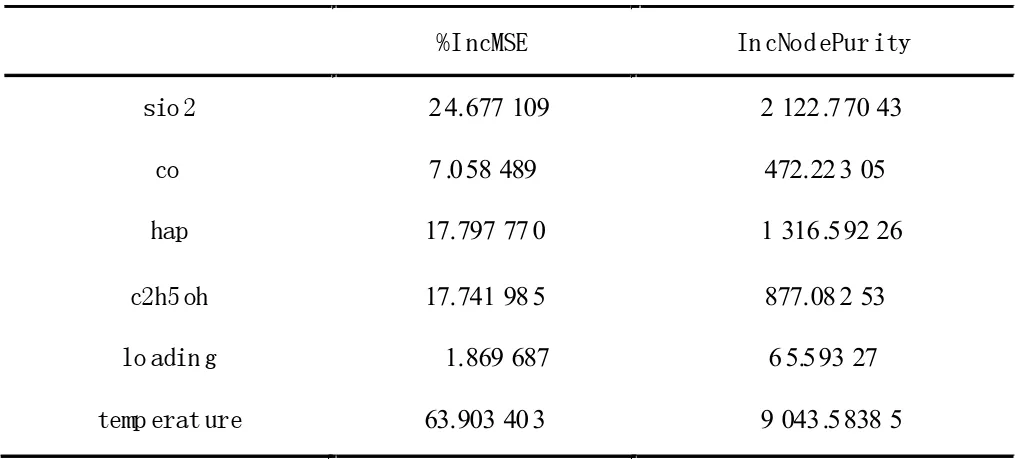
表2 变量重要性
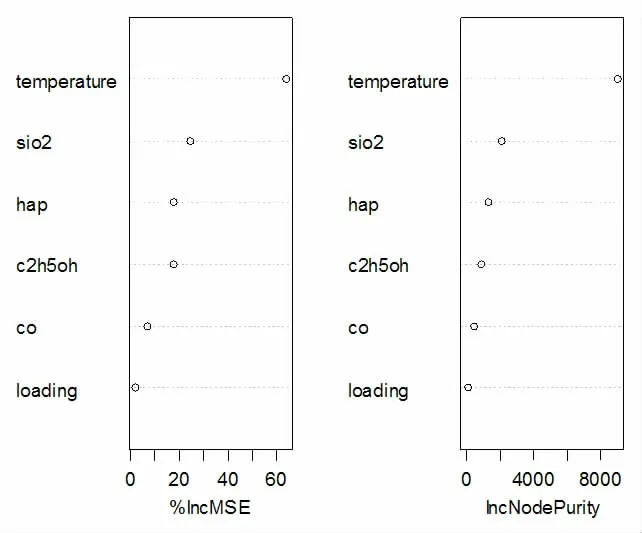
图3 变量重要性排序
5 结论
通过选取温度和催化剂组合为预测变量,C4 烯烃收率为响应变量,建立了基于随机森林的回归模型,得到测试的均方误差为10.727 5,方差的解释性达到85.57%,模型的预测效果较好。当催化剂组合为A3 和温度为400 度时预测结果达到最高值,此时,C4烯烃收率为34.795%。从随机森林模型特征变量的重要性可以看出,温度、SiO2含量、HAP 含量这几个变量的重要性更靠前,因此,在研究C4 烯烃收率时排名靠前的变量应该作为重点关注的变量。
猜你喜欢
炼油与化工(2022年4期)2022-10-10
科学家(2022年4期)2022-05-10
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
中国医药科学(2016年9期)2016-07-25
