
基于深度神经网络优化网络学习的社会创业研究
2022-11-25 04:38吴嘉鑫
现代计算机 2022年17期
吴嘉鑫
(新南威尔士大学创业创新系,澳洲 悉尼 2052)
0 引言
创业创新实践因新兴技术的驱动而产生了重大变化,越来越多的创业创新研究开始基于数字化的背景下[1]。但在中国情境下,对于现代计算机科学与创业创新实践结合的研究还处于发展阶段,尤其是对社会企业的研究,国内学者更多关注于数字化下的农民工返乡创业、弱势群体创业以及使命漂移等普遍社会问题[2],而忽略了对于学校内部信息化创新这一重要社会问题。然而学校对于培养人才,积蓄社会创业创新力量有着本质的影响,因此,更高效的师生网络学习系统能更长远地提高学生能力,对培养高质量创业创新人才有着重要意义[3]。基于此,本研究将利用深度神经网络去提高师生网络学习,从而实现对学校的社会贡献。
近几年,深度神经网络在计算机视觉和自然语言处理等多个领域都表现出了最先进的性能。最新的研究表明[4],深度神经网络可以深入处理数据,并且深度神经网络可能具有更大的容量并实现更高的精度。然而,一个具有许多参数的深度网络在训练和测试时都需要大量的计算,由于对计算资源的要求很高,所以很难应用于实际场景。这个问题促使人们对神经网络的压缩进行研究。
Hinton等[5]首先提出了知识提炼(KD)这个概念,他们使用教师网络的软化输出,将信息转化为小型学生网络。通过这种教学程序,小网络可以学习大网络如何以压缩的形式研究给定任务。Romero等[6]介绍了FitNet,它不仅使用教师网络的最终输出,而且还使用教师网络的中间隐藏层值来训练学生网络。通过使用这些中间层,可以改善学生网络的性能。与Fit-Net不同的是,Zagoruyko等[7]提出了注意力迁移(Attention Transfer)的方法去转移完整的注意力图。最近,Yim等[8]使用FSP矩阵将知识从教师网络转移到学生网络。FSP矩阵是由两层的特征之间的内积计算出来的,包括如何“解决问题”的知识。
更值得关注的是,Zeiler等[9]介绍了一种可视化技术,让人们了解中间特征层的功能。它揭示了这些特征远远不是随机的、无法解释的模式。相反,它们显示了许多直观的理想属性,如构成性、增加的不变性和类别的区分。以前与特征相关的知识转移工作只关注整个特征图。例如,FitNet直接计算特征图的二级损耗[6];AT转移特征的摘要[7];不同层次的特征图的内积得到转移[8]。而所有这些方法都忽略了特征之间的关系。所以在Zeiler等[9]的启发下,我们发现不应该只关注特征图的值,而应该更加关注特征之间的关系。
因此,为了在这些特征之间传递知识,我们引入了流形学习。流形学习将数据集视为高维空间中非线性流形的嵌入。它的目的是将位于高维空间的非线性流形上的数据集进行低维参数化。流形学习已经成功地应用于许多领域,如人脸识别等。它包含几种方法,如Isomap[10],
Locally Linear Embedding(LLE)[11],Laplacian Eigenmaps(LE)[12]和Local Preserving projection(LPP)[13]。局部保留投影(LPP)是一种流形学习方法,它保留了样本的局部关系[13]。本文利用“局部保留投影”的思想,将教师网络的知识转移到学生网络。
本文将深度网络的输入视为高维空间的流形,因为特征可以很好地表示输入,并具有许多直观的特性[9]。因此,我们认为从深度网络中提取的隐藏层的特征是位于输入流形上的重要点。对于同样的输入,利用“局部保留投影”的思想,从教师网络和学生网络中提取的特征应该位于相似的流形上,为此我们引入了一种新的LPP损失,以确保教师和学生网络之间特征的局部相似性,并在此基础上将教师网络和学生网络的特征之间的关系知识进行了转移。
本论文的贡献如下:①提供了一个关于知识转移问题的新观点,并提出了一种新的网络压缩方法;②通过实验表明,本文方法在几个数据集上提供了明显的改进;③研究表明,本文方法可以与其他知识转移方法相结合,并达到最佳性能。
1 理论基础与文献回顾
1.1 知识转移
深度神经网络在计算机视觉任务中表现良好。深度神经网络的能力通常取决于网络的深度和宽度。然而,一个具有许多参数的深度网络很难在应用中使用,因为它需要大量的计算资源。学生网络的参数很少,Hinton等[5]首创的知识转移(Knowledge Transfer)旨在通过依赖从强大的教师网络中借用的知识来改善学生网络的训练。它使用教师网络最终输出的软化版本,称为软化目标,将信息传授给一个小网络。通过这个程序,学生网络可以从教师网络中学习并达到更好的准确性。Romero等[6]介绍了FitNet,将宽而浅的网络压缩为薄和深的网络。
FitNet不仅使用软化的输出,还使用教师网络的中间隐藏层值来训练学生网络。在第一阶段,FitNet与教师网络和学生网络的隐藏层输出相匹配;在第二阶段,它使用软化的输出(知识提炼KD)来匹配最终输出。通过匹配隐藏层,学生网络可以从教师网络学习额外的信息。Zagoruyko等[7]提出了注意力迁移(Attention Transfer,AT)。与FitNet不同的是,AT传输的是隐藏层的全部激活,而注意力图则是全部激活的总结。Yim等[8]使用的FSP矩阵包含了网络的解决过程的信息。通过匹配学生网络和教师网络之间的FSP矩阵,学生网络可以从教师网络学习如何“解决问题”。
1.2 流形学习
Isomap[10]是一种流形学习算法,它通过返回点之间的距离近似于最短路径距离的嵌入,保留了输入集的几何特征。局部线性嵌入(LLE)[11]试图通过将每个输入点重建为其邻居的加权组合来局部表示流形。拉普拉斯特征图(LE)[12]建立了一个包含数据集的邻域信息的图。利用图的拉普拉斯概念,LE计算出数据集的低维表示,在某种意义上最佳地保留了本地邻域信息。局部保留投影(LPP)[13]则是通过解决一个变分问题来制作线性投影图,该投影图以最佳方式保留了数据集的邻域结构。
2 研究方法
2.1 目标
本文方法旨在将教师网络中的特征关系转移到学生网络中。对于一个输入图像x,教师网络计算输入并在中间层获得特征。最后,网络结合这些特征得到输出。在其他学者的研究里,知识提炼(KD)[5]是通过匹配教师和学生网络进行软输出;FitNet[6]是通过二级损失(L2 loss)直接匹配特征图;AT[7]转移注意力图。然而所有这些方法都忽略了特征之间的关系。因此,本文认为特征是流形的重要点,它代表了输入图像。对于相同的输入图像,学生和教师网络应该提取类似的特征。因此,他们的流形中的特征应该是相似的。本文方法使用局部保留损失(LPP loss)来衡量他们的特征图之间的相似性。
2.2 局部保留投影(LPP)
LPP[13]是一种流形学习方法。它的目的是找到一个能最佳地保留数据集的邻域结构的映射。假设给定一个集合{x1,x2,…,xm∈Rn},而y1,y2,…,ym是一个目标地图集合,那么LPP的标准是选择一个好的地图,即最小化以下函数:
在合适的条件约束下,如果相邻的点xi和xj被映射得很远,那么选择Wij的目标函数会产生严重的惩罚。因此,最小化可以确保当xi和xj接近时,那么yi和yj也是接近的。
2.3 局部保留损耗(LPP loss)
LPP[13]是一种保存样本局部关系的流形学习方法。本文引入局部保留方法去保持教师网络和学生网络的流形相似性,具体来说,让FS∈Rh×w×m表示由选定的匹配层生成的学生网络的特征图和{f1S,f2S,…,f mS∈Rh×w}表 示特征图的特征,其中h,w和m代表高度、宽度 和 通 道 数。分 别 来 说,FT∈Rh'×w'×m和{f1T,f2T,…,f mT∈Rh'×w'}表示特征图和教师网络中选定层的特征。其基本思想是保留教师网络中的特征与学生网络中的特征一样的局部关系。为了实现这一目标,本文定义了以下的局部保留损失:
其中,参数αi,j描述了由教师网络的选定层产生的特征之间的局部关系。定义αi,j的方式如下:
N(i)表示第i个特征f iT的k个最近的邻居特征与δ是标准化常数。WS表示学生网络的权重,L(W,x)表示标准交叉熵损失。那么可以定义以下总损失:
2.4 局部保留损耗(LPP loss)的反向传播
Llpp相对于f iS的梯度计算如下:
两个网络的权重是通过Llpp的导数反向传播来微调的:
3 实验与讨论
在两个数据集CIFAR-10和CIFAR-100[14]上评估本文方法。在所有的实验设置中,使用Resnet-34[4]作为教师网络,Resnet-18作为学生网络。我们稍微修改了网络的结构以适应数据集。CIFAR-10和CIFAR-100数据集包括50K训练图像和10K测试图像,分别有10个和100个类别。对于数据增强,我们在训练中从零填充的40×40图像中随机抽取32×32的裁剪或其翻转一下。对于教师网络,本文使用了在ImageNet LSVRC 2012中预训练的模型[15],并采用随机梯度下降法(SGD)对网络进行优化,迷你批次大小为256。SGD的权重衰减为105,动量为0.9。对网络进行了130次历时训练。初始学习率被设置为0.05,然后在10、60、90和105个历时中分别除以10。将本文方法与KD[5]、FitNet[6]和AT[7]进行比较。将ResNet转移的知识(KD)温度提高到4,并按照Hinton的研究方法使用α=0.9。对于FitNet,在第一阶段,我们训练了90个历时,学习率最初为1e-4;然后,在10和60个历时中,它被改为1e-5。对于注意力迁移(AT),按照Zagoruyko的研究方法,将λ值设置为103除以注意力图中的元素数和匹配层的批量大小。对于本文得LPP损失,我们将λ值设置为10除以特征图中的元素数、匹配层的批处理量和通道数,并将k(近邻数)的数量设置为5。对于以上所有的方法,本文对教师网络和学生网络的第二卷积组的输出进行匹配。实验结果见表1。包括KD、FitNet和LPP在内的所有的方法都比原始学生网络的错误率低。KD[5]使用软化标签来提高学生网络的准确性。Fitnet[6]不仅使用了像KD那样的软化输出,还使用了教师网络的中间隐藏层值来训练学生网络,并取得了比KD更高的准确性。本文方法,即LPP,在两个数据集中与知识提炼(KD+LPP)相结合时,显示出对学生网络的明显改善,并取得了比KD和FitNet更高的准确性。
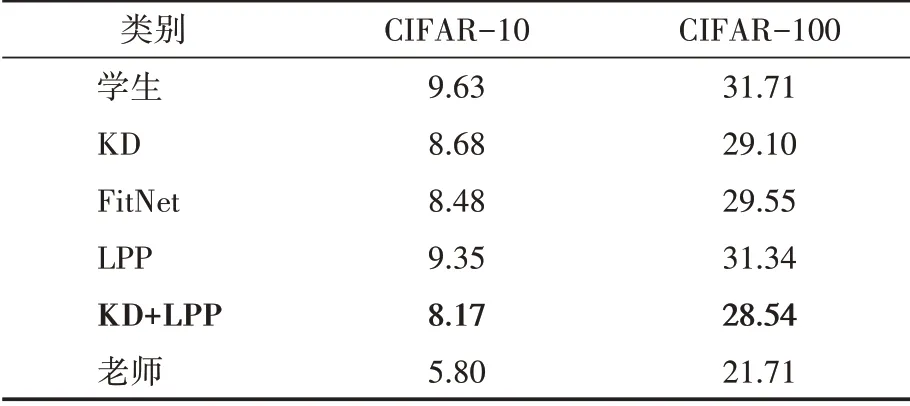
表1 不同转移方法出错率的CIFAR结果
注意力迁移(AT)是一种知识提炼方法,它取得了比KD和FitNet更高的准确性。表2显示了本文方法和AT的结果。对于AT,按照Zagoruyko的规定,λ值被设定为103除以注意力图中的元素数和匹配层的批处理大小。为了保证识别精度的公平比较,我们在教师网络和学生网络的第二卷积组之间转移相同的AT和LPP的损失。当单独使用AT损失和LPP损失时,LPP损失实现了更高的准确性。当把AT和LPP损失与KD结合起来时,AT损失实现了更高的准确性。在所有的方法中,AT+LPP+KD的组合达到了最好的性能。
如表2所示,本文的LPP方法在知识提炼方面有了显著的改进。具体来说,提高了学生网络的性能约1.46%和3.17%,并分别减少了15%和10%的相对误差。在与AT相结合的情况下,学生网络的性能提高了2.01%和3.72%,相对误差分别降低了21%和12%。结果表明,本文方法成功地优化了教师网络特征之间的关系。尽管FitNet[6]与完全激活的功能图相比,AT[7]转移了完整的注意力图,但忽略了特征之间的关系。本文方法考虑了特征之间的关系,忽略了注意力图的具体值。因此,我们将LPP损耗与AT损耗相结合,在所有方法中获得了最高的精度。
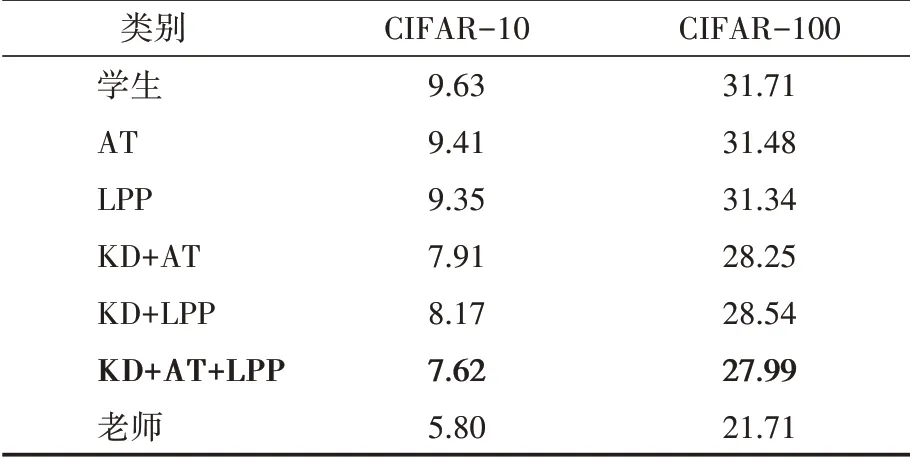
表2 LPP和AT的CIFAR结果
4 结语
本文提出了一种新的知识转移损耗(LPP loss),将其作为一个流形学习问题。我们将深度神经网络提取的特征视为流形中的导入点,可以代表输入图像,通过使用所提出的局部保留损失,学生网络可以在教师网络中学习特征的流形结构。本文在CIFAR-10和CIFAR-100中验证了该方法的有效性。结果表明,本文方法在知识提炼方面有明显的改进。通过将LPP损失与现有方法相结合,使得所提出的方法优于最先进的知识转移方法。
本研究为现代计算机知识与管理学科创业创新研究的交叉融合做出了贡献,拓宽了对于社会企业创业研究的边界和方向,给出了社会企业去实现社会价值时不仅仅局限于慈善、社会企业责任等方面,还可以考虑为国家教育做出贡献的新思路。同时,本研究也展现了现代计算机知识对于实现社会价值,提高教育效能的巨大潜力。未来的研究方向可以考虑尝试通过新的网络学习系统去减少管理学科收集问卷的复杂度,提高效率,从而实现进一步的社会价值。
猜你喜欢
山花(2022年5期)2022-05-12
中华书画家(2021年12期)2022-01-06
厦门大学学报(自然科学版)(2021年1期)2021-02-02
散文诗(2020年1期)2020-07-20
小天使·二年级语数英综合(2019年10期)2019-11-08
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
科技风(2018年1期)2018-05-14
东方艺术·国画(2016年3期)2017-02-08
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
