
基于集成学习的山区中小流域滑坡易发区早期识别优化试验
2022-11-28 11:53刘海知包红军宋巧云狄靖月
工程科学与技术 2022年6期
刘海知,徐 辉*,包红军,鲁 恒,宋巧云,狄靖月,王 蒙,曹 爽
(1.国家气象中心,北京 100081;2.中国气象局–河海大学水文气象研究联合实验室,北京 100081;3.四川大学 水利水电学院,四川 成都 610065;4.四川大学 水力学与山区河流开发保护国家重点实验室,四川 成都 610065)
滑坡是中国西部山区的一种典型自然灾害,汶川大地震后的破碎山体、岩体经过长时间风化作用形成的大量潜在固体物源在重力侵蚀和水力坡面侵蚀的共同作用下被带入沟道,成为山洪水沙灾害的主要泥沙补给[1]。目前,山洪水沙灾害的防治主要关注洪水的影响,忽视了洪水和泥沙的共同作用[2–4],滑坡作为山洪水沙耦合运动的重要物源基础,其易发区的识别是山洪水沙灾害预报预警和风险评估的重要前提[5–8]。近年来,随着遥感数据处理技术的升级和计算机科学的快速发展,基于卫星遥感的滑坡信息提取已经成为流域尺度滑坡易发性早期识别的主要方法。宿方睿等[9]采用面向对象分类法并结合目视解译提高了遥感影像滑坡解译的成功率。Xu等[10]基于地震触发的滑坡数据改进了滑坡体积的估算方法。黄润秋等[11]根据高分辨率卫星影像数据目视解译出6 877个地质灾害点。此外,人工智能和模糊数学领域的技术方法也被更多地应用于样本数量少、影像光谱信息匮乏区域的灾害易发性识别研究[12–15]。张帅等[16]利用区域生长算法和形态学实现了黄土高原巴谢河流域未解译典型滑坡的识别。Ding等[17]提出基于纹理变化检测和卷积神经网络的滑坡自动识别方法。Huang等[18]使用汶川地震后60个流域的实测泥石流体积数据集开发混合机器学习模型。张群等[19]采用了3种方案建立了BP神经网络模型预测滑坡体积。目前,大多数滑坡易发性早期识别工作对于非滑坡单元的选取及数据样本的构建过程仍较为主观,也未将固体物源作为主要影响因子。本文从分区算法和影响因子的角度对山区小流域的滑坡易发性识别方法进行优化试验,评估单体算法和融合算法对于滑坡易发区的识别效果,并比较考虑物源因子前后的滑坡易发性分区结果。
1 研究区域与方法
1.1 研究区域概况和数据来源
寿溪河流域位于四川省阿坝藏族羌族自治州汶川县内,属于川西多雨中心区。流域集水面积约554 km2,地理位置在东经103°02′04″~103°26′56″,北纬30°47′42″~31°02′19″,海拔895~4 952 m。流域内地形复杂、沟谷纵横,是典型的山区流域。流域内降水年内分配不均,大部分集中于6—9月,且多为短时强降水,滑坡点主要分布于河谷两岸区域,如图1所示。
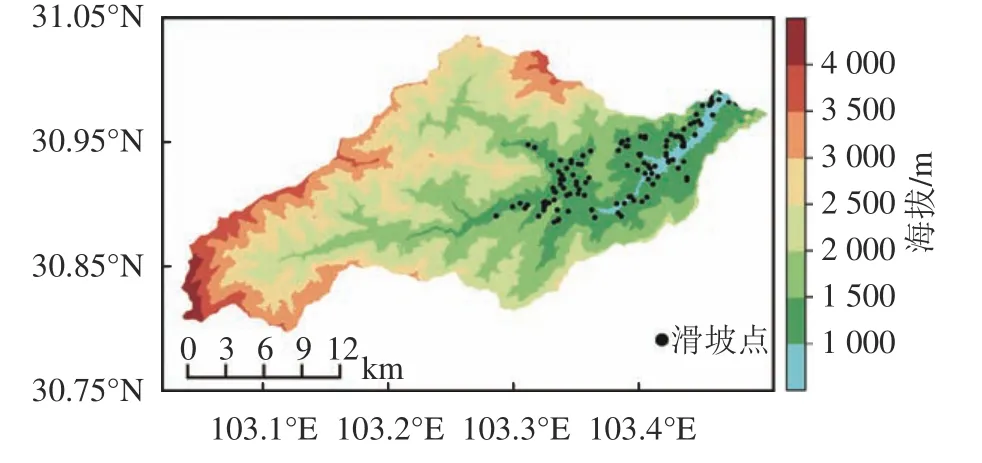
图1 研究区及滑坡分布Fig.1 Research area and landslides distribution
滑坡信息主要通过对遥感影像中的地物特征进行提取而获得,遥感影像采用斯波特(Satellite Pour l’Observation de la Terre,SPOT)7号卫星全色遥感影像图。影响滑坡发生的环境因子很多,考虑到易发区早期识别优化算法在更大范围的适用性,选取应用范围较广的环境因子对研究区域滑坡易发性进行分析。针对滑坡易发性的大量研究中,常将地形因子、地质因子、土壤因子、土地利用、植被覆盖及水文环境作为主要评价因子[20]。本文将坡度、坡向、地形曲率、地形粗糙度作为地形因子,将地层岩性和距断层距离作为地质因子,将土壤类型作为土壤因子,将土地利用类型作为土地利用因子,将归一化植被指数作为植被覆盖因子,将汛期降水量作为水文环境因子。数字高程模型(digital elevation model,DEM)选用对地观测卫星(advanced land observing satellite,ALOS)相控阵型L波段合成孔径雷达采集的DEM数据,来源于美国国家航空航天局(National Aeronautics and Space Administration,NASA)官方网站;坡度、坡向、地形曲率及地面粗糙度数据基于DEM空间分析生成;土地利用数据、土壤类型数据、植被覆盖数据来源于中国科学院资源环境科学与数据中心;地层岩性和断层数据来源于91卫图助手软件地质图;降水数据采用的是国家气象信息中心研发的中国区域高时空分辨率多源融合降水近实时实况分析产品(China Meteorological Administration Multisource Precipitation Analysis System,CMPAS),该产品可为山区小流域等自动观测站分布密度极小的区域提供精细化降水实况数据。以上数据来源与精度见表1。

表1 数据来源与精度Tab.1 Data source and resolution
1.2 主要方法
1)频率比算法
统计方法在滑坡易发区识别中应用最为广泛,基于统计方法对环境因子进行分析时多采用频率比(式(1))对环境因子进行属性划分,故从训练样本集中获取滑坡易发性与基础环境因子之间的关系:
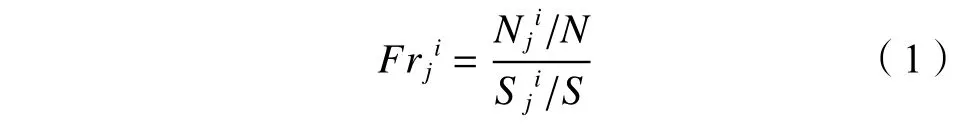
2)易发度分类算法
滑坡的易发性问题在一定程度上可以表示为分类问题,即在环境因子构成的空间中对样本集进行分类,获取易发性与环境因子之间的关系,进而将这种关系从环境因子空间映射到地理空间,实现对滑坡易发性的识别与分区,并为每个空间单元标记易发性等级。集成学习是一种将多个弱分类器合成单个强分类器以提高分类准确率和泛化能力的技术框架。随机森林(Random Forests,RF)是基于Bagging集成学习的代表性算法,以决策树(Decision Tree,DT)作为基评估器,通过随机抽样对多个决策树进行集成并利用多数投票机制进行预测。单个决策树的准确率越高,随机森林的准确率也会越高。其核心思想是,从原始样本中有放回地多次取样,每次取样形成一个训练集及其对应决策树,生成的所有决策树对新的数据进行分类预测。自适应增强(adaptive boosting,AdaBoost)是Boosting集成学习的代表算法,通过在迭代过程中对训练失败的样本赋予较大的权值来获得较好的预测函数序列,采用投票方式对分类问题进行预测,即样本的分类由各分类器权值决定,其核心思想是,基于原始训练集训练一个基学习器,根据基学习器的分类结果对训练样本分布进行调整,对基学习器分类错误的训练样本在后续训练中赋予更大的权值,利用调整后的样本分布训练下一个基学习器,直至学习器数目达到某一定值后将所有基学习器进行加权结合。RF和AdaBoost的主要区别体现在分类器,RF的分类器是并行训练,即分类器可以同时训练数据,得出结果后再确定权重并综合为最终分类器;AdaBoost的分类器是先后训练,后一轮分类器运用的数据会受到上一轮分类器的影响。本文采用这两种集成学习分类算法对研究区域的滑坡易发性等级进行分类。
3)负样本聚类算法
训练样本中只包含滑坡样本会使算法模型高估滑坡易发度,合理选用非滑坡样本可以有效约束滑坡高易发区的过度扩张,对滑坡易发性等级的分类结果合理性有重要影响[21–23]。常用的负样本挑选方法包括随机挑选法和专家经验法,其中:随机挑选法缺乏理论依据,往往误差较大;专家经验法太过于依赖专家个人主观经验,不同专家所分析的结果存在较大差异。基于同类样本在环境因子特征空间中相对接近的原则[24–27],负样本可以在与滑坡样本的环境特征差别较大的单元中筛选。聚类算法不需要数据标签及其他先验知识,主要通过输入样本的相似程度进行归类处理[28]。K-Means作为最常用的聚类算法,其核心思路是,在确定K个初始类簇中心点的初始条件下,将每个点分到距离其最近的类簇中心点代表的类簇中,根据类簇中所有点重新计算该类簇中心点(平均值),再迭代进行分配点和更新类簇中心点步骤,直至类簇中心点变化小到指定程度或迭代过程达到指定次数。基于聚类算法模型的易发性结果可以大致反映研究区内的滑坡易发区,在高易发区以外的区域随机选取非滑坡点以保证负样本的准确性。
4)滑坡解译
目视解译作为最传统、最直接、最精确的松散堆积物识别方法,需要基于松散堆积物的解译要素建立解译标志,通过综合分析获取松散堆积物边界、滑动方向及影响范围等信息。本文根据滑坡遥感影像特征(光谱、形状、纹理),结合DEM和实地调查数据,通过目视解译手段获取寿溪河流域内滑坡物源区域,直接解译标志为:形状呈马蹄形、簸箕形、弧形或不规则形;纹理粗糙,起伏不平,地表有坑洼时,可能存在斑点状影纹;色调呈灰色、灰白色,当周围地形较稳定时,颜色较暗,当周围植被较为茂密时,颜色较周围物体差异明显,随植被恢复则会出现不均匀绿色;边界明显可见,前部有滑舌伸入沟谷或河道。由于滑坡深度获取困难,本文利用Simonett[29]建立的滑坡体积–面积幂律关系对小型滑坡体积进行估算,如式(2)所示:
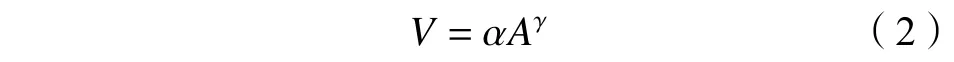
式中,V为滑坡体积,A为滑坡面积,α、γ为系数。上述估算公式已应用于多个滑坡研究案例[30–32]。大型滑坡的体积估算需要引入更多与滑坡体积相关的因子,如式(3)所示:
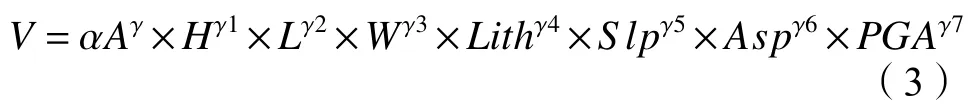
式中,V为滑坡体积,A为滑坡面积,H为高,L为长,W为宽,Lith为岩性,Slp为坡度,PGA为峰值地动加速度,Asp为坡向,α、γ1~γ7为系数。本文目视解译最大的滑坡面积为30 413 m2,不属于大型滑坡,因此采用式(2)估算松散堆积物体积。
1.3 数据处理
不同渠道获取的数据表达形式存在差异,即使同为栅格数据,空间分辨率也因卫星搭载的传感器不同而不同,驱动易发性分区算法之前需要对数据进行预处理。在提取滑坡发生的核心位置时,将滑坡面数据与DEM数据叠加,以滑面内DEM最大值所在区域为滑坡发生源区。由于地形因子、土壤因子、土地覆盖和植被覆盖为栅格数据,汛期降水为格点数据,需要建立统一坐标系和分辨率的栅格格式专题图层。为保证所有栅格数据具有相同属性,处理过程中以ALOS DEM数据为参考,对各环境因子进行属性统一操作:通过坐标系转换和数据重采样操作将不同坐标系和空间分辨率的图像统一到与参考图像相同的地理坐标系(GCS_WGS_1984)和空间分辨率(12.5 m×12.5 m)。按照栅格数量接近原则将所有环境因子进行区间划分,具备自然分类属性的环境因子按照自然情况进行分级。利用GIS平台的空间相交和属性查询功能,根据滑坡地理位置的矢量点要素提取环境因子数据,得出不同等级环境因子的空间分布及数量,构建易发性早期识别算法的基础数据集。
由于流域内滑坡样本数量相对较少,将其影响因子数据集用于算法训练时可能损失部分特征或趋势。K–Fold交叉验证是一种评估有限数据样本的机器学习算法模型的重采样方法,可以扩大样本数量及降低过拟合概率。此处,将训练集分为10组大小相等的互斥子集(K=10),依次轮换10次进行试验。样本集按0.8和0.2的比例分为训练集和测试集,通过数据清洗去除无效值。影响因子以1维向量形式作为输入项,输出滑坡易发性等级。
1.4 评价指标
滑坡易发性识别结果包含以下4种类型:真阳性(true postive,TP),即被预测为滑坡点的实际滑坡样本数量;真阴性(true negative,TN),即被预测为非滑坡点的实际非滑坡样本数量;假阳性(false positive,FP),即被预测为滑坡点的实际非滑坡样本数量;假阴性(false negative,FN),即被预测为非滑坡点的实际滑坡样本数量。根据易发性识别结果类型计算模型的以下指标:召回率(recall,REC),即实际滑坡样本中被预测为滑坡点的比例;虚警率(false alarm,FA),即实际非滑坡样本中被预测为滑坡点的比例;准确率(accuracy, ACC),即预测正确的样本占总样本的比例。计算公式分别如式(4)~(6)所示:
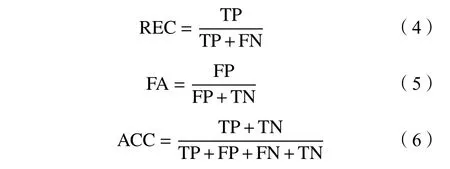
受试者工作特征曲线(receiver operating characteristic curve,ROC)是反映敏感性和特异性连续变量的综合指标,ROC下方面积(area under the curve,AUC)可评价模型的泛化能力,可通过该评价指标对滑坡易发性分区结果进行评价。
2 结果分析
研究区域影响因子各等级空间分布如图2所示。根据已有的滑坡点位置信息计算影响因子各等级频率比并替换影响因子初始值,影响因子最大频率比见表2。

图2 研究区域影响因子空间分布Fig.2 Spatial distribution of influence factors in research area
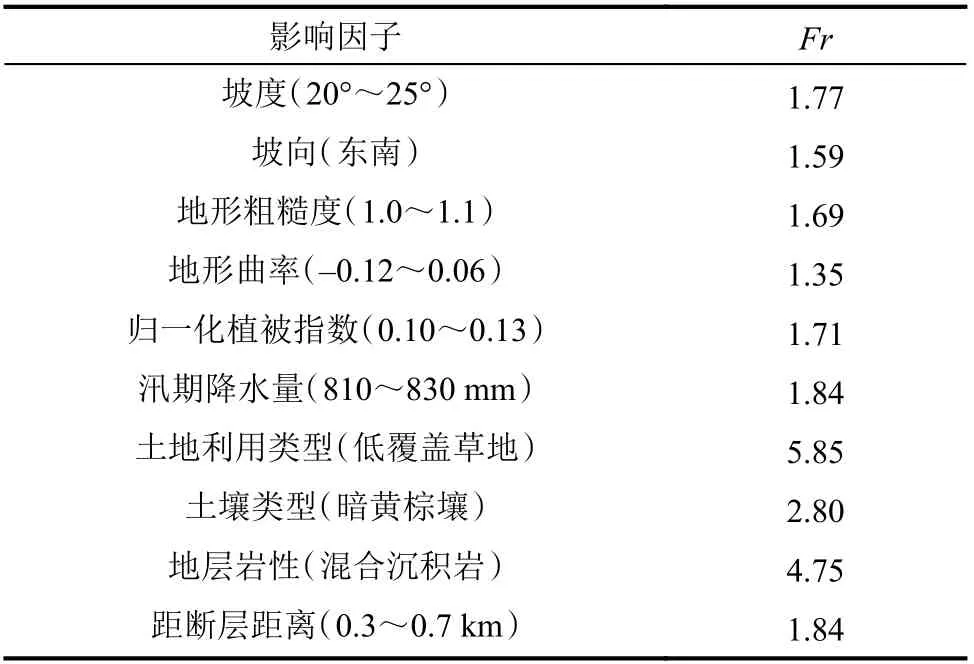
表2 影响因子最大频率比Tab.2 Max frequency ratios of influence factors
将研究区域影响因子频率比空间分布进行叠加,并以1维向量形式作为K-means聚类算法输入项,通过10折交叉验证进行训练,输出基于影响因子频率比的滑坡易发性聚类结果,如图3所示。将易发性聚类结果分为5个等级:低易发区[1,2]、较低易发区[3,4]、中易发区[5,6]、较高易发区[7,8]、高易发区[9,10]。其中,高易发区的覆盖率为6.7%,较高易发区的覆盖率为8.2%,较高和高易发区的滑坡点比例为61.7%。
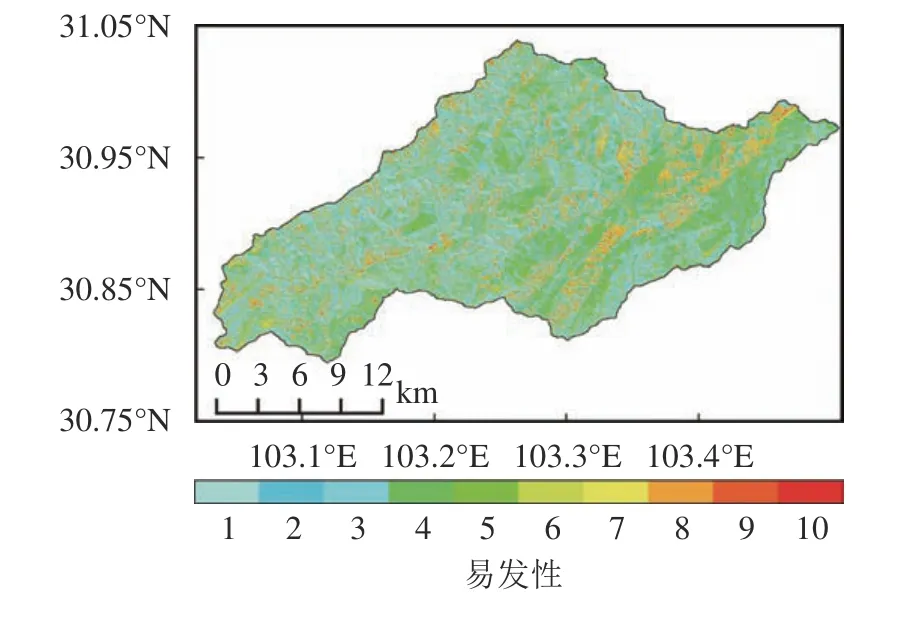
图3 基于K-Means聚类算法的寿溪河流域滑坡易发性分布Fig.3 Distribution of landslides susceptibility in Shouxi river basin based on K-Means clustering algorithm
从低易发区中随机挑选与滑坡样本等量的非滑坡样本,将滑坡点(正样本)和非滑坡点(负样本)影响因子频率比数据集作为RF分类算法和AdaBoost分类算法的输入项,通过交叉验证进行训练,输出两类集成学习分类算法的滑坡易发性等级,如图4所示。

图4 基于融合算法的寿溪河流域滑坡易发性分布Fig.4 Distribution of landslides susceptibility in Shouxi river basin based on fusion algorithm
融合算法(K-Means–RF、K-Means–AdaBoost)输出的高易发区覆盖率相对于单体聚类算法分别提高9.3%、12.1%。在对测试样本集的分类效果评估中,将分类结果为较高易发性或高易发性的样本表示为滑坡点,其余分类结果表示为非滑坡点。两类融合算法的评估结果见表3。
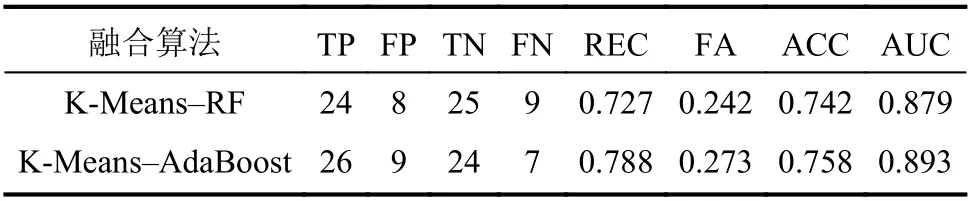
表3 融合算法评估结果Tab.3 Fusion algorithm evaluation results
由表3可知:K-Means–RF融合算法的易发性等级分类结果中,24例滑坡样本被预测为滑坡点(TP),9例滑坡样本被预测为非滑坡点(FN),25例非滑坡样本被预测为非滑坡点(TN),8例非滑坡样本被预测为滑坡点(FP);分类正确的滑坡样本占实际滑坡样本测试集的72.7%(REC为0.727),分类正确的非滑坡样本占实际非滑坡样本测试集的75.8%(FA为0.242),分类准确率为0.742。K-Means–AdaBoost融合算法的易发性等级分类结果中,26例滑坡样本被预测为滑坡点(TP),7例滑坡样本被预测为非滑坡点(FN),24例非滑坡样本被预测为非滑坡点(TN),9例非滑坡样本被预测为滑坡点(FP);分类正确的滑坡样本占实际滑坡样本测试集的78.8%(REC为0.788),分类正确的非滑坡样本占实际非滑坡样本测试集的72.7%(FA为0.273),分类准确率为0.758。KMeans–AdaBoost融合算法的准确率略高于KMeans–RF融合算法,K-Means–AdaBoost对于滑坡点的预测效果更优,FN的数量比K-Means–RF融合算法少2例;K-Means–RF算法对于非滑坡点的预测效果更优,FP的数量比K-Means–AdaBoost融合算法少1例。两类融合算法的泛化能力较为接近,KMeans–AdaBoost、K-Means–RF算法AUC分别为0.893、0.879。
将物源因子作为滑坡易发性分区影响因子,在保留原有影响因子的基础上,增加物源频率比作为融合算法的输入项。
根据目视解译标志,结合现场调查结果,得到松散堆积物源144处,面积总和为1 344 060 m2,平均面积为9 333.75 m2,最大面积约为30 413 m2;面积大于20 000 m2的松散堆积物数量和面积总和分别为19个、625 316 m2,面积小于5 000 m2的松散堆积物数量和面积总和分别为47个、136 488 m2。总体来看,面积较大(>20 000 m2)的松散堆积物数量和面积总和分别占总数和总面积的13.19%、46.52%;面积较小(<10 000 m2)的松散堆积物数量和面积总和分别占总数和总面积的65.28%、35.13%;研究区多以分散型小面积滑坡物源区为主。由于土层暴露,滑坡体色调较浅且不均匀,与周围地物有较明显分界线;滑坡体颜色较周围植被更呈亮黄色或亮白色,稀疏灌木或草地使滑坡体呈现出零星的淡绿色;滑坡体边缘与植被和路段分隔清晰,典型滑坡体的现场调查情况及其解译标志如图5所示。

图5 典型滑坡现场调查及遥感影像Fig.5 Typical landslide site survey and remote sensing image
根据式(2)估算各处松散堆积物体积,由于缺少滑坡体的现场测量条件,选用其他研究在汶川地区实测得到的面积和体积数据建立幂律关系[10,31,33–35],得出体积和面积相关性方程为:
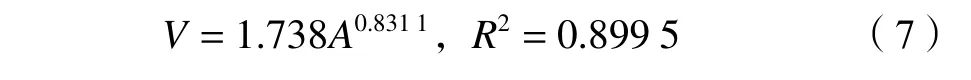
对松散堆积物体积进行均匀间隔采样后的空间分布如图6所示,最大体积为9 245.28 m3。根据中国地质调查局公布的《滑坡防治工程勘察规范》(GB/T 32864—2016)中关于滑坡体积的分类标准可知,研究区滑坡类别均属于小型滑坡。
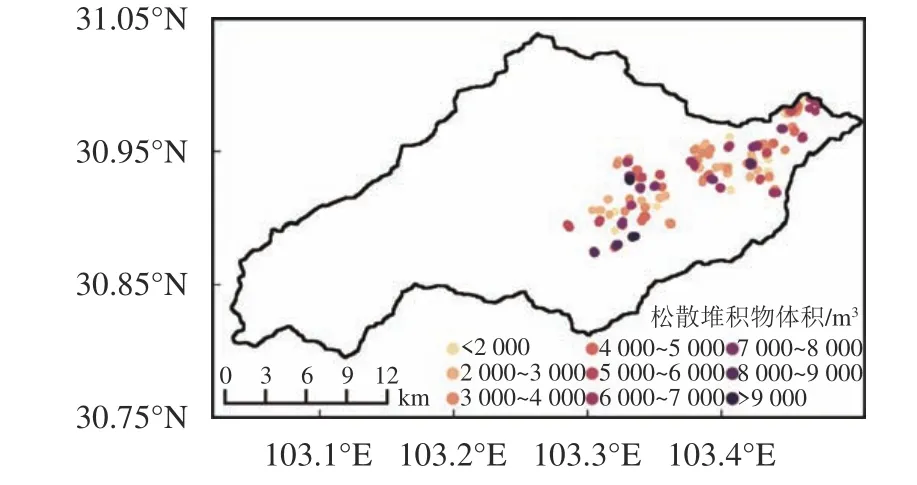
图6 松散堆积物体积Fig.6 Volume of loose deposita
考虑物源因子后的两类融合算法输出的滑坡易发性分区如图7所示。由图7可知:K-Means–RF、KMeans–AdaBoost融合算法输出的高易发区覆盖率相对于未考虑物源因子时分别提高14.2%、17.7%。考虑物源因子后对测试样本集的分类效果评估结果见表4。K-Means–RF融合算法的易发性等级分类结果中:28例滑坡样本被预测为滑坡点(TP),5例滑坡样本被预测为非滑坡点(FN),分类正确的滑坡样本占实际滑坡样本测试集的84.8%,REC为0.848;25例非滑坡样本被预测为非滑坡点(TN),6例非滑坡样本被预测为滑坡点(FP),分类正确的非滑坡样本占实际非滑坡样本测试集的75.8%,FA为0.242,分类准确率为0.803。K-Means–AdaBoost融合算法的易发性等级分类结果中:30例滑坡样本被预测为滑坡点(TP),3例滑坡样本被预测为非滑坡点(FN),分类正确的滑坡样本占实际滑坡样本测试集的90.9%,REC为0.909;24例非滑坡样本被预测为非滑坡点(TN),9例非滑坡样本被预测为滑坡点(FP),分类正确的非滑坡样本占非滑坡样本测试集的72.7%,FA为0.273,分类准确率为0.818。考虑物源条件的两类融合算法的FN数量都减少4例,对于滑坡点的预测效果相较于未考虑物源条件时更优,准确率有一定提升。

图7 考虑物源因子的融合算法的寿溪河流域滑坡易发性分布Fig.7 Distribution of landslides in Shouxi river basin based on fusion algorithm considering slump masssources factor
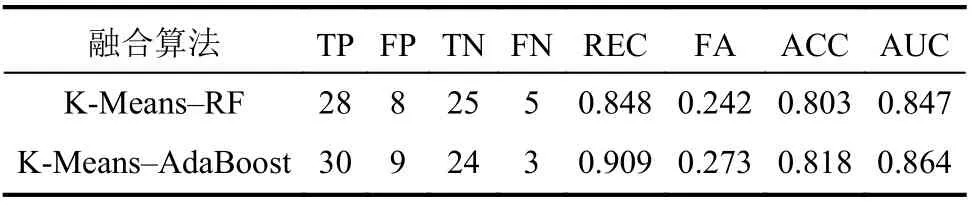
表4 考虑物源因子的融合算法评估结果Tab.4 Fusion algorithm evaluation results considering loose deposita factor
3 结论与讨论
滑坡易发区早期识别是山洪水沙灾害易发性识别的基础,本文从分区算法和影响因子两个方面对山区中小流域滑坡易发性识别方法进行了优化试验。得出以下结论:
1)基于聚类–分类融合算法的山区中小流域滑坡易发性分区结果的高易发区覆盖率相较于单体聚类算法明显提高,K-Means–RF、K-Means–Ada-Boost融合算法的易发性分区中的高易发区覆盖率分别提高9.3%和12.1%。
2)两类融合算法的易发性分区准确率和泛化能力比较接近,K-Means–AdaBoost融合算法对于滑坡点的预测效果更优,K-Means–RF算法对于非滑坡点的预测效果更优。
3)考虑物源因子后的K-Means–RF、K-Means–AdaBoost融合算法输出的高易发区覆盖率相对于未考虑物源因子时分别提高14.2%、17.7%,两类融合算法REC提高12.1%。
从实际业务出发,滑坡的早期识别对于漏警的容错率远小于虚警,基于集成学习的分类算法模型在训练过程中确保高(低)召回率(漏报率)是前提,即着重于对滑坡样本的滤取,这会在一定程度上造成部分非滑坡样本被预测为滑坡样本。综合上述原因,K-Means–AdaBoost算法的实际业务应用潜力高于K-Means–RF算法。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
河北地质(2021年1期)2021-07-21
四川地质学报(2021年1期)2021-06-15
今日农业(2021年1期)2021-03-19
水土保持研究(2020年1期)2020-04-27
安徽农学通报(2018年12期)2018-09-18
中国科技纵横(2018年7期)2018-05-22
中国公路(2017年18期)2018-01-23
