
基于门控循环单元的链路质量预测
2022-11-28 11:53刘琳岚肖庭忠牛明晓
工程科学与技术 2022年6期
刘琳岚,肖庭忠,舒 坚,牛明晓
(1.南昌航空大学 信息工程学院,江西 南昌 330063;2.南昌航空大学 软件学院,江西 南昌 330063)
无线传感器网络(wireless sensor network,WSN)是一种由大量具有感知能力和通信能力的微型节点部署在感知区域形成的网络[1],在环境监测[2]、智能交通[3]、智能家具[4]等领域广泛应用。通过预测链路质量,选择高质量链路进行数据传输,可以减少数据丢失和数据重传次数,提高网络的吞吐量[5–6],因此,链路质量预测具有重要意义。
链路质量预测的方法主要包括:基于链路特性的方法、基于概率估计的方法和基于机器学习的方法[7]。基于链路特性的方法主要采用接收信号强度指标(received signal strength indication,RSSI)、链路质量指标(link quality indicator,LQI)或信噪比(signal noise ratio,SNR)等物理层参数预测链路质量,这些参数可以直接获取,不需额外的计算,能耗低,但这些参数均依赖于节点,而硬件本身存在校准误差,且忽略了分组丢失,易产生高估链路质量的问题。基于概率估计的方法通过发送大量探测包,接收端计算包接收率(packet reception rate,PRR)等信息来预测链路质量[8],但是该方法需要发送大量探测包,不仅增加了额外的通信开销,且对链路状况的反应不够灵敏。
基于机器学习的链路质量预测方法主要通过将链路质量预测问题转化为时序预测问题,利用机器学习或深度学习的方法挖掘训练样本的特征,深入学习模型输入与输出之间的潜在关系,利用得到的模型对下一时刻的链路质量进行预测。Liu等[9]提出4C (Foresee),将LQI和PRR输入逻辑回归模型,预测下一时刻的PRR,然而该方法的预测准确率并不高;Liu等[10]提出一种预测大波动链路质量的方法,命名为WNN_LQP(wavelet neural network based link quality prediction),该方法利用过渡区链路质量指标的高分辨率以及小波神经网络的学习能力预测下一时刻的链路质量,然而对于相对较小的波动,该模型无法进行准确预测;Xue等[11]提出一种基于随机向量函数链的链路质量预测方法(link quality prediction based on random vector functional link,RVFL_LQP),选择SNR为链路质量参数,利用随机向量函数链建立时变序列和随机序列方差,对SNR的概率保证区间边界进行预测,但在真实应用中该结果无法快速反映链路是否可用;Xu等[12]提出一种基于循环神经网络(recurrent neural network,RNN)的链路质量预测方法(recurrent neural network based link quality prediction,RNN_LQP),降低了预测误差,但RNN内部结构复杂、训练周期长,且易出现梯度消失、梯度爆炸等问题[13],导致RNN_LQP模型复杂度高,模型效果不稳定。采用机器学习的方法能够有效地挖掘出训练样本的特征,相比基于链路特性的方法和基于概率估计的方法,具有更高的准确性和稳定性,是目前WSN链路质量预测的主流方法,因此本文使用机器学习的方法进行链路质量预测研究。
GRU作为RNN的一种变体,在时序问题建模方面比其他机器学习方法更有优势[14],且已被证明在时序预测问题上具有更好的预测效果[15]。现有研究中,Abdel–Nasser等[16]将GRU应用于无线社交网络中的链路质量预测中,并取得不错的效果。
因此,本文提出一种基于门控循环单元(gate recurrent unit,GRU)的链路质量预测方法,具体可分为3个步骤:首先,采用Gap Statistic算法优化的K-means++聚类算法,自适应地划分链路质量等级,避免由于人为选定临界点带来的误差干扰,获得更加贴近真实的链路质量样本标签。其次,采用CatBoost构建链路质量评估模型,对当前时刻的链路质量进行评估。最后,采用GRU构建链路质量预测模型,将评估模型的结果作为输入,借助GRU在时序问题上的优势提取链路质量等级的时序信息,采用支持向量回归机(support vector regression,SVR)预测得到下一时刻链路质量等级,提高链路质量预测的准确率。
1 链路质量等级划分
本文采用Gap Statistic算法[17]优化的K-means++算法[18]对PRR进行聚类,划分链路质量等级,获得链路质量样本标签。
1.1 Gap Statistic算法
Gap Statistic算法以样本集的统计规律为基础,通过间隙统计量刻画样本观察值和参考分布下期望值之间的差异,得到最佳聚类数。本文采用Gap Statistic算法确定聚类数目,具体过程描述如下:
1)对于任意两个PRR样本pm和pm′,计算它们之间的距离dmm′:
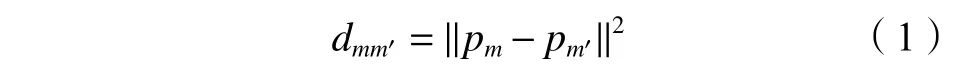
式中:m=1,2,···,N;m′=1,2,···,N;m≠m′;N为PRR样本数。
2)假设将PRR样本集分为K类{C1,C2,···,Ck,···,CK} ,计算第k类中样本距离总和Dk:
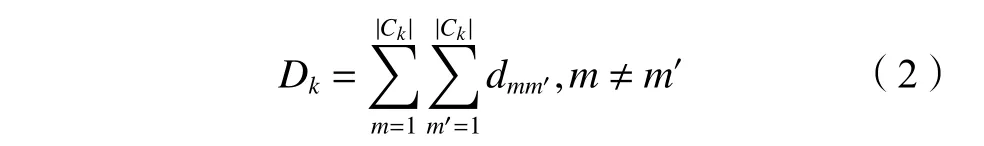
式中, |Ck|为 第k类样本数目。
计算所有类的样本距离的平均和WK:
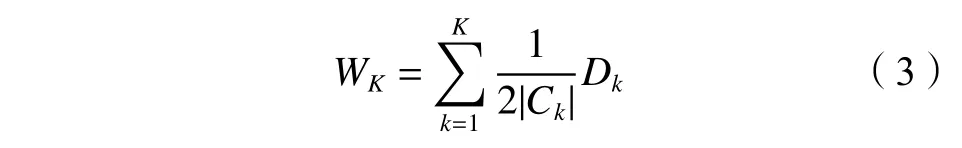
3)对WK取对数,并与使用蒙特卡洛模拟对数的期望进行比较,如式(4)所示:
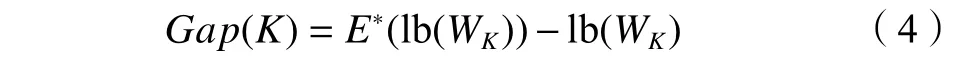
式中,E∗(lb(WK)) 为 使用蒙特卡洛模拟得到的lb(WK)的期望。
4)取使式(5)成立的最小值K为PRR样本集的最佳聚类数目。
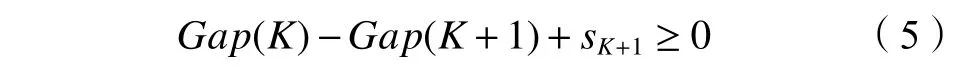
式中,sK+1为修正后的标准差,其表达式为:
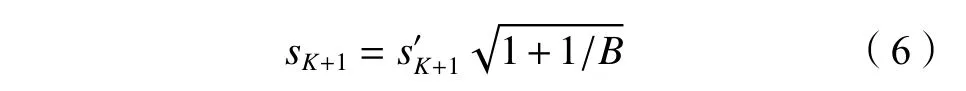
1.2 改进的K-means++算法
K-means算法实现简单,聚类效果好,非常容易部署实施,在机器视觉、地质统计学等领域得到成功的应用[19]。K-means算法需要提前给出聚类数目K,但在不同的数据集中K的取值很难确定[20],由于随机选择K个样本点作为聚类中心,不同的初始聚类中心可能导致不同的聚类结果[21]。与K-means算法不同,K-means++算法在选取聚类中心时,尽量使聚类中心互相离得远,可减小聚类结果的波动。
本文采用Gap Statistic算法确定聚类数目K,再采用K-means++算法划分链路质量等级,具体过程如下:
1) 采用Gap Statistic算法确定K。
2) 从PRR样本集中随机选择一个样本点作为第一个初始化聚类中心。
3) 计算PRR样本与它最近聚类中心的欧式距离D(pm):
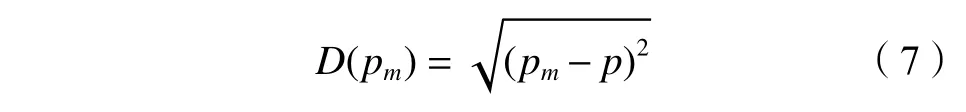
式中,p为 距离pm最近的聚类中心。
4) 计算样本被选为下一个聚类中心的概率Q(pm),如式(8)所示,并使用轮盘法选出下一个聚类中心。

5) 重复步骤3)和4),直到选出K个聚类中心。
6) 将每个样本点归类到离它最近聚类中心所属的类。
7) 重新计算每个聚类内PRR的均值,将其定为新的聚类中心。
8) 重复步骤6)和7),直至聚类中心不再变化。
9) 得到每个样本xi的 链路质量等级yi。
2 链路质量评估
以链路质量参数作为输入,第1节得到的链路质量等级作为输出,采用CatBoost构建链路质量评估模型,主要包括评估样本的构建、样本预处理及评估模型的构建。
2.1 评估样本的构建
本文选取RSSI均值、LQI均值和SNR均值为链路质量参数,采用链路质量等级评价链路质量。链路质量样本集为:
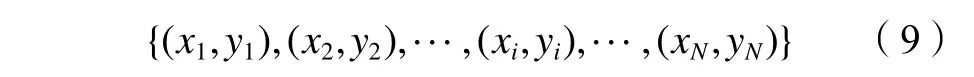
式中:xi=(),其中,为样本xi的RSSI均值,为样本xi的LQI均值,为样本xi的SNR均值;yi为样本xi的链路质量等级;N为样本数。
2.2 样本的预处理
由于传感器节点在收发信息时会受到多径效应、信道、温湿度或障碍物等的干扰,收集到的数据存在缺失值,本文计算缺失值样本在一个发送周期内的均值,采用均值填充法对样本进行预处理。
2.3 基于CatBoost的链路质量评估模型的构建
CatBoost 是由Yandex的研究人员和工程师开发的基于梯度提升决策树(gradient boosting decision tree,GBDT)的机器学习模型[22],采用排序提升算法替换GBDT中的梯度估计方法[23],能够减少GBDT算法中因梯度偏差和预测偏移而导致的过拟合问题,有着更好的泛化能力[24]。
本文提出基于CatBoost的链路质量评估模型(link quality estimation based on CatBoost,CatBoost_LQE),其中,排序提升算法描述如下:
1)对训练集中 τ个样本对进行随机排列,将序列标记为 ψ。
2)对于每一个样本对 (xi,yi),初始化该样本对的模型Mi。
3)对于每一轮迭代:
①计算样本xi的无偏度梯度估计:
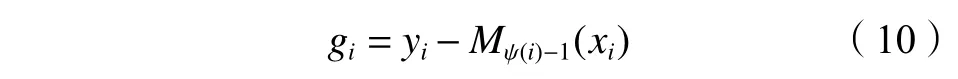
②对于每一个样本对 (xi,yi),使用该样本对在序列 ψ之前的训练集 (xj,gj):ψ(j)≤i训练下一个分类回归树 ∆M,将其更新到模型中,如式(11)所示:
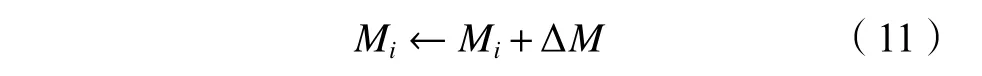
4)迭代完成,输出Mτ即为最终模型。
设第e−1 轮迭代得到的学习器为Fe−1(·),计算Fe−1(·) 的梯度ge−1(xi,yi):
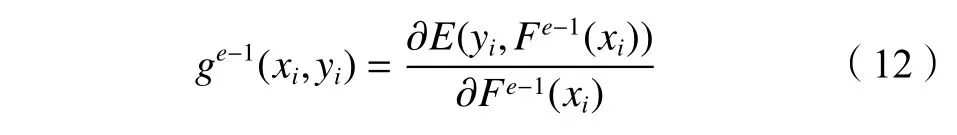
式中,E(yi,Fe−1(xi))为Fe−1(·)的损失。
将第e−1轮的负梯度作为残差,传递到第e轮,找到一个新的弱学习器he(·), 使损失值最小,he(·)表达式如下:
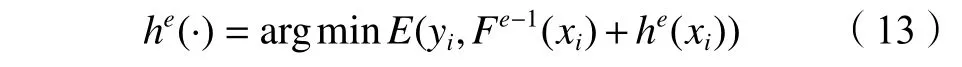
得到最终的强学习器Fe(·):
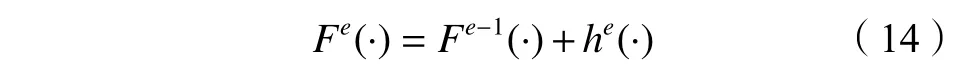
3 链路质量预测
根据链路质量在短期内表现出强时间相关性的特点,本文采用CatBoost_LQE得到的链路质量等级时间序列作为输入,采用滑动窗口法确定输入序列的长度,进而构建基于GRU的链路质量预测模型。
3.1 预测样本的构建
采用CatBoost_LQE对历史链路质量样本进行评估,得到链路质量等级值序列 {l1,l2,···,li,···,ln},其中,li为第i个时刻链路质量等级值,n为样本数。使用大小为w的时间窗口构建时序样本集:
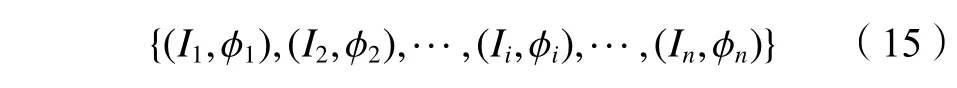
式中:链路质量等级时间序列Ii={li,li+1,···,li+w−1};ϕi=li+w,ϕi作为标签值。
展会注重与行业协会紧密合作,浙江省环保机械行业协会、宜兴市环保产业协会等多家与主办方长期合作的行业协会将为展会带来更多优质的污水处理设备厂商新面孔。浙江省大型环境工程公司、浙江海拓环境技术有限公司、浙江四通环境工程有限公司、浙江弘润机械制造有限公司、浙江爱迪曼水科技有限公司等早已确定集体出展,向专业观众展示最新处理技术和解决方案。
滑动时间窗口的大小影响模型的预测结果。如果时间序列过短,就会导致历史信息学习的缺失;反之,如果时间序列太长,则会增加模型的复杂度,甚至使预测效果变差。本文通过实验确定时间窗口大小。
3.2 基于GRU的链路质量预测
本文利用GRU能够很好地处理和预测序列数据的优点,构建链路质量预测模型GRU_LQP(link quality prediction based on gate recurrent unit),如图1所示。
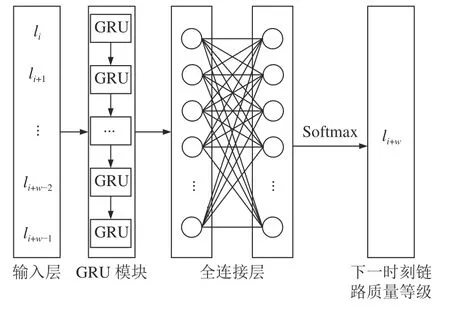
图1 GRU_LQP的结构Fig.1 Structure of GRU_LQP
由图1可知:GRU_LQP包括输入层、GRU模块层、全连接层和输出层。输入链路质量等级时间序列{li,li+1,···,li+w−1},通过GRU模块中的GRU单元学习输入序列之间的时序关系,通过全连接层集成链路质量等级时序特征。为了增强链路质量预测模型的泛化性,在全连接层中加入Dropout操作,设置其缩放权重为0.5[25]。选用Softmax函数映射得到下一时刻各等级的概率,实现链路质量预测。
GRU模块使用多个GRU单元的堆叠实现对输入链路质量等级时间序列的学习,GRU单元的结构如图2所示。图2中,ht−1为 前个GRU的隐藏层输出,lt为本轮GRU输入的链路质量等级, σ为Sigmoid函数,zt和rt分别为GRU的更新门和重置门,为经过更新的中间状态,ht为本轮GRU的隐藏层输出。
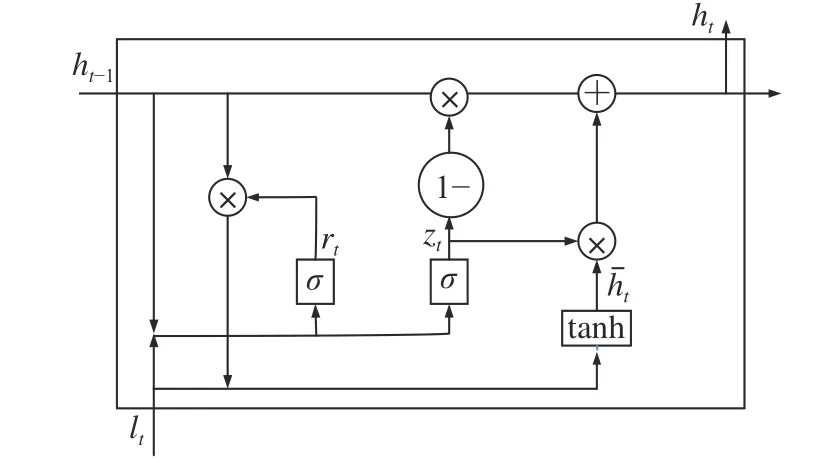
图2 GRU的结构Fig.2 Structure of GRU
GRU主要通过两个门控对链路质量等级信息进行更新,更新门zt用于控制前一个状态中链路质量等级信息被代入到当前状态的程度,更新门的值越接近1,说明代入了更多前一个状态的链路质量等级信息。重置门rt控制前一状态有多少链路质量等级信息被写入到当前的候选集上,重置门越小,前一状态的链路质量等级信息被写入得越少。通过Sigmoid 函数将数据变换到0~1之间,并结合乘法操作可以实现对输入链路质量等级信息及历史链路质量等级信息的选择性重置。
GRU的计算过程如式(16)~(19)所示:
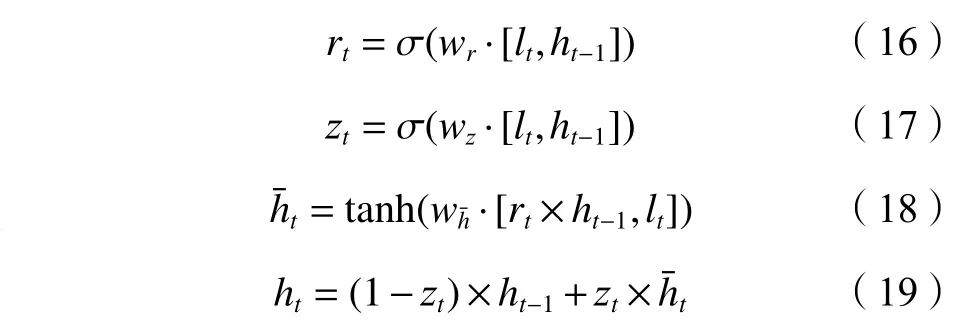
式(16)~(19)中,wr为重置门的权重,wz为更新门的权重,wh¯为中间状态的权重。
本文使用随机梯度下降法优化权重参数wr、wz、wh¯,学习率取经验值0.01。
3.3 预测模型的优化
为了进一步提高链路质量预测的准确率,本文采用SVR作为链路质量等级预测器,优化GRU_LQP,构建了GRU_SVR(link quality prediction based on gate recurrent unit and support vector regression)链路质量预测模型,如图3所示。
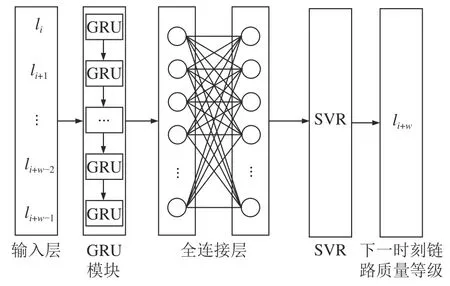
图3 GRU_SVR的结构Fig.3 Structure of GRU_SVR
GRU_SVR的参数设置如表1所示。

表1 GRU_SVR参数Tab.1 Parameters of GRU_SVR
3.4 模型评价
本文采用均方误差(mean square error,MSE)评价预测结果,MSE的计算式为:
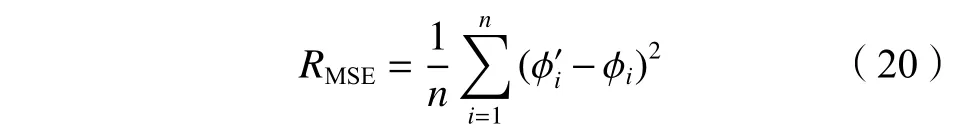
式中, ϕi为样本中输入链路质量等级时间序列的标签,为预测值。MSE值越小则表明预测模型预测误差越小,性能越好。
4 实验设计与结果分析
在3个真实场景中进行实验,通过与同类模型对比验证本文模型的有效性。
4.1 实验设计
分别在实验室、走廊及停车场布置传感器节点,如图4所示。实验室场景中,无线设备及人员的走动等对链路质量造成影响;走廊场景中,节点产生的串扰及人员的走动等对链路质量造成影响;停车场场景中,车辆出入及车载设备等对链路质量造成影响。

图4 实验场景Fig.4 Experimental scenarios
实验在南昌航空大学物联网实验室开发的WSN链路质量测试平台(wireless sensor networks link quality testbed,WSN–LQT)[25]上进行,连续3天收集RSSI、LQI、SNR、PRR等链路质量数据,将预处理后的链路质量样本集以7∶3的比例划分为评估模型的训练集和测试集,根据评估结果构建链路质量等级时序样本集,并以7∶3的比例划分为预测模型的训练集和测试集。WSN–LQT中参数设置如表2所示。

表2 WSN–LQT参数Tab.2 Parameters of WSN–LQT
4.2 主要实验参数确定
1)聚类数目
采用Gap Statistic算法确定聚类数目K,采用Kmeans++聚类算法对PRR聚类,得到链路质量等级。设Γ=Gap(K)−Gap(K+1)+sK+1,3个实验场景中不同K值对应的Γ 值如图5所示。
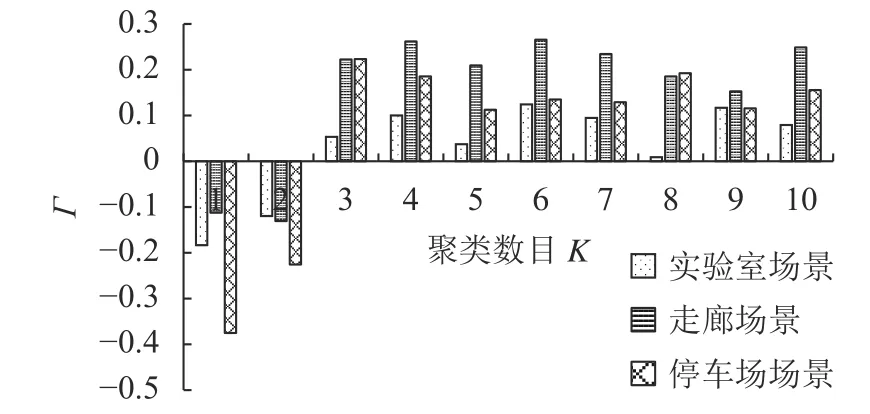
图5 不同K值对应的 Γ值Fig.5 Values of Γ corresponding to different K values
由图5可知,3个实验场景中,使式(5)成立的K值均为3。因此,将实验室、走廊及停车场3个实验场景的PRR均划分为3个链路质量等级,其中,第1等级的链路为链路质量差的链路,第2等级的链路为链路质量中等的链路,第3等级的链路为链路质量好的链路。
2)评估模型的参数
CatBoost_LQE评估模型的参数主要有:学习率lr、L2正则参数l2_leaf_reg、树的深度depth、决策树最大的数量iterations。为了提高CatBoost_LQE的评估准确率,本文采用网格搜索法对上述参数寻优,结果如表3所示。
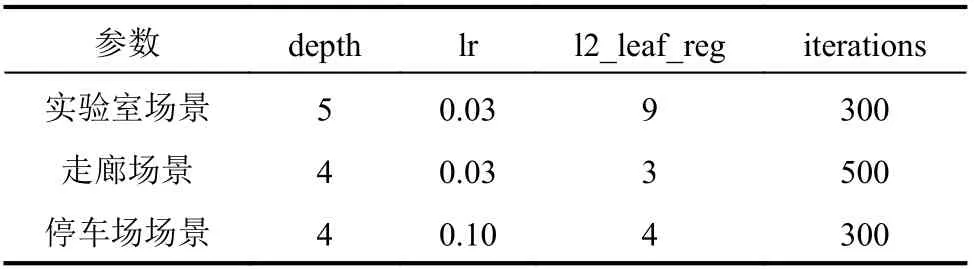
表3 CatBoost_LQE的参数值Tab.3 Parameter values of CatBoost_LQE
3)滑动时间窗口的大小
本文通过对比不同时间窗口下GRU_SVR的MSE,选择合适的时间窗口大小。3个场景中,不同的时间窗口下GRU_SVR的MSE结果如图6所示。
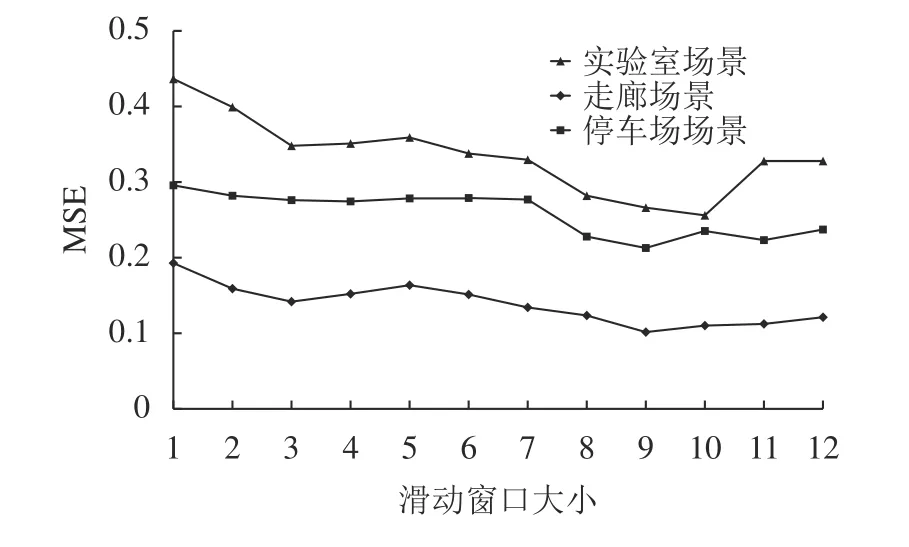
图6 GRU_SVR的MSE Fig.6 MSE of GRU_SVR
由图6可知,滑动时间窗口大小影响预测模型的准确率。在实验室场景中,滑动时间窗口大小为10时,MSE值最小。在停车场和走廊场景中,滑动时间窗口大小为9时,MSE值最小。因此,实验室、走廊及停车场场景中,滑动时间窗口的大小分别设置为10、9、9。
4.3 模型的验证
为验证GRU_SVR预测模型的有效性,与GRU_LQP、4C[9]、WNN_LQP[10]、RFVL_LQP[11]及RNN_LQP[12]预测模型进行对比,结果如图7所示。

图7 不同预测模型的MSE值Fig.7 MSE values of different prediction models
由图7可知:实验室场景中,干扰较多,链路质量整体较差,GRU_SVR的均方误差最小。走廊实验场景中,链路的干扰较少,链路质量整体较好,GRU_SVR的均方误差也是最小的。可见,与GRU_LQP、4C、WNN_LQP、RFVL_LQP及RNN_LQP预测模型相比,本文提出的GRU_SVR预测模型无论是在链路质量较差还是较好的环境中,均有更好的预测准确率。
5 结 论
本文提出一种基于GRU的链路质量预测方法。首先,采用基于Gap Statistic算法优化的K-means++算法划分链路质量等级,获得样本标签;然后,选择RSSI、LQI、SNR作为输入,基于CatBoost构建链路质量评估模型,评估当前时刻的链路质量,在不同场景中使用网格搜索法优化评估模型的参数;最后,采用GRU学习链路质量等级序列的时序信息,采用SVR预测下一时刻的链路质量等级。在真实世界中,部署节点并收集数据进行实验,结果表明相比于其他模型,本文所提模型具有更低的预测误差。下一步将致力于解决链路质量数据不平衡给链路质量预测带来的影响,进一步提高链路质量预测的准确率。
猜你喜欢
移动通信(2021年5期)2021-10-25
中学生数理化·高一版(2021年2期)2021-03-19
空间科学学报(2020年3期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
知识经济·中国直销(2018年8期)2018-08-23
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
互联网天地(2016年1期)2016-05-04
中国老区建设(2016年1期)2016-02-28
智能系统学报(2015年4期)2015-12-27
