
建立国家数字经济创新发展试验区对企业价值影响研究
——基于PSM-DID模型的统计分析
2022-11-29 02:38李振亮杨瑛莹
中小企业管理与科技 2022年18期
李振亮,杨瑛莹
(1.台州学院,浙江 台州 318000;2.杭州市疾病预防控制中心,杭州 310021)
1 引言
2019年10月20日,国家发展和改革委员会、中央网信办宣布正式启动建设国家数字经济创新发展试验区(以下简称“试验区”)。在联合刊发的《国家数字经济创新发展试验区实施方案》(以下简称《实施方案》)中,首次公布了包括河北省(雄安新区)、浙江省、福建省、广东省、重庆市、四川省在内的6 个试点省市。从宏观层面来看,“试验区”的建立旨在形成一系列可操作、能复制的典型做法,加强对于数字未知领域的探索。从微观层面来看,“试验区”的建立旨在为企业数字化转型提供政策支持,实现企业高质量发展。因此,“试验区”的设立能否实现预期目标,促进企业高质量发展,实现企业价值提升,是值得探讨的话题之一。近年来,针对“试验区”的相关研究主要有韩骞、王子晨[1]采用灰色关联度分析法,以浙江省、福建省、广东省和四川省四座“试验区”为研究对象,从研发投入强度、研发经费内部支出、研发人员全时当量、本地技术合同金额四大方面与数字经济发展进行关联评价,总结出把握新风口、探索新治理、建设新设施、开发新场景等“四新”做法来提升“试验区”的引领作用,进一步壮大数字经济。李志起、张灵[2]分别对六省市在“试验区”建设中的探索路径以及存在的问题不足进行深入剖析,并在此基础上提出相应的改进措施。徐滢[3]基于大数据分析方法研究六个“试验区”在数字经济相关方面的先进做法,为天津创建新“试验区”提供经验借鉴。覃剑[4]从“试验区”的建设进展、面临的主要挑战以及探索方向三个方面对“试验区”进行综合论述。综合现有文献可以看出,更多的文献侧重于对于“试验区”自身建设的思考和研究,而针对“试验区”对上市企业价值的影响评估还较为鲜见。为弥补相关研究空白,本文主要贡献在于:第一,在研究方法方面,以“试验区”的设立作为准自然实验,借助双重差分倾向得分匹配计量方法来探究“试验区”的设立对上市公司价值影响机制,丰富了相关课题研究方法。第二,在研究视角方面,不同于“试验区”的建设对国家宏观层面数字经济的研究,本文从企业微观层面探究对上市公司价值的影响,为投资者进行相关企业投资提供数据参考。
2 研究设计
2.1 数据来源
本文数据来源于CSMAR,并选取2017 至2021年中国沪深A 股上市企业面板数据作为研究样本,并对原始数据进行如下处理[5]:①剔除研究期中ST 以及ST*企业数据和其他重要信息有所缺失的样本数据;②剔除金融、保险类等特殊行业公司数据;③为防止奇异值的干扰,将所得数据统一采取上下1%的Winsorize 处理。
2.2 计量模型
双重差分法(DID)是将研究对象分为受政策影响和不受政策影响的两个组别,以两个组别的平均变化之差来剔除个体固有差异,最终判断政策所带来的影响。考虑到在进行DID 模型处理过程中存在选择性偏误和自我选择效应,需要在DID 分析之前对所选数据进行倾向得分匹配(PSM)处理。PSM 处理模型是两个组别的研究对象进行得分匹配,来寻找与受政策影响组别中可观测特征最接近的研究对象。
结合上述两个模型的特点,本文建立如下PSM-DID 回归模型[6]:
其中,TobinQ 表示被解释变量,i 和t 分别表示企业和年份;Zjit代表每一个控制变量,ε 是随机扰动项。Treated 和Year 为两个虚拟变量,Treated=1 和Treated=0 分别表示纳入“试验区”所在的六省市上市企业和未纳入“试验区”所在的省市上市企业。Year=1 和Year=0 分别是表示《实施方案》发布之后的2019 至2021年以及《实施方案》发布之前的2017 与2018年。
2.3 变量定义
2.3.1 被解释变量
本文的被解释变量是企业价值,并采用托宾Q 值来作为被解释变量的代理变量。
2.3.2 解释变量
核心解释变量为Treated 和Year 两个虚拟变量的交互乘积项(Treated×Year),如表1 所示。其中表示政策效应所产生的净影响。
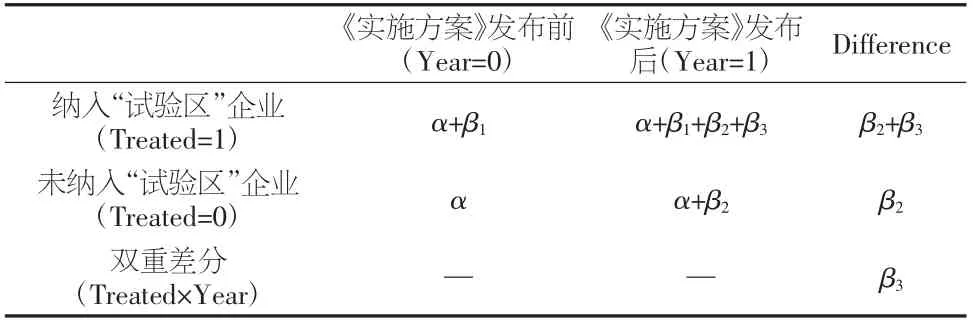
表1 模型中参数变化表
2.3.3 控制变量
为了防止其他变量对企业价值产生影响,本文借鉴了毛建辉、张蕊和管超[7]的研究,选择速动比率、产权比率、净利润增长率、固定资产周转率、资产报酬率5 个财务指标分别代表研究模型中的控制变量。
所有变量具体如表2 所示。
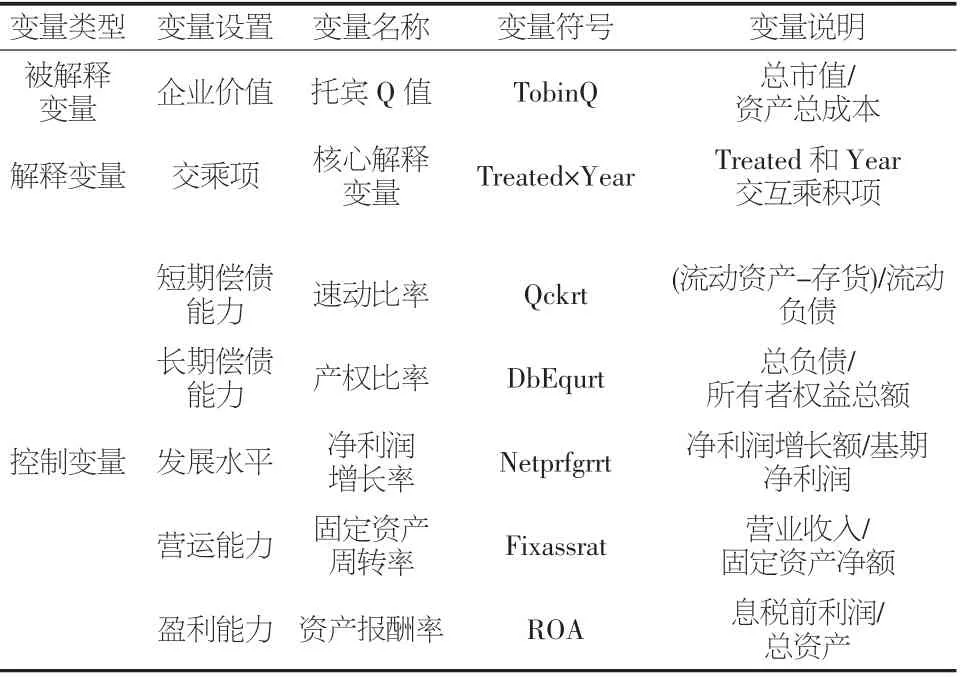
表2 变量说明
3 实证分析
3.1 描述性统计分析
表3 是变量描述性统计以及变量分组描述性统计结果。从表中可以看出:企业净利润增长率和固定资产周转率的标准差分别约为3.693 和26.846,说明各家上市企业中存在较大差异。
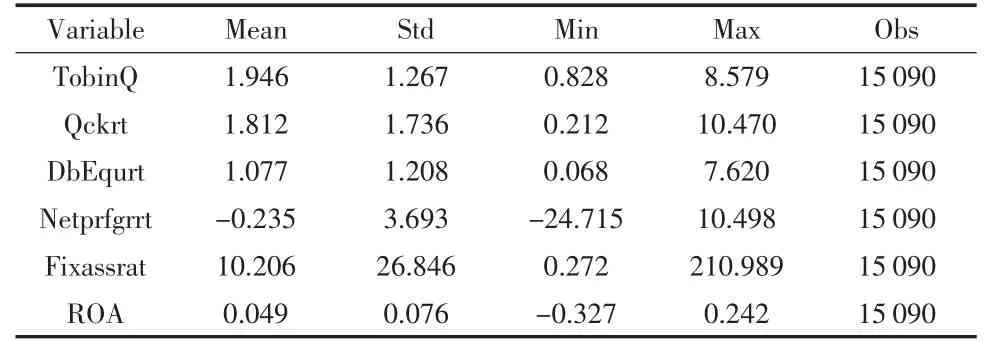
表3 变量描述性统计分析
3.2 倾向得分匹配处理
为了能降低选择性偏差和自我选择效应,更好地满足相同变化趋势的假定,本文将采用倾向得分匹配法对协变量做选择。匹配结果如表4 所示。
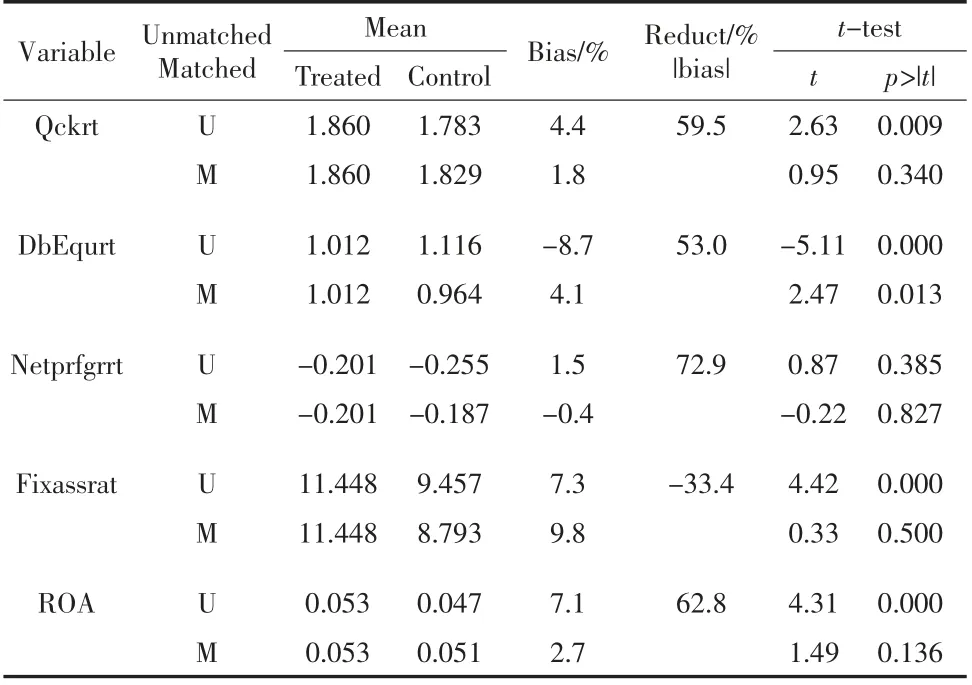
表4 匹配变量平衡性检验
从表中可以看出:相比匹配前,匹配后的所有协变量的差异均出现了一定程度的下降。在T 检验结果中,匹配后除了产权比率在10%显著性水平下拒绝控制组和处理组有差异这一原假设,其余变量均不拒绝,这说明变量个体特征差异缩小,选择性偏差进一步降低。
更直观地如图1 所示,匹配后的变量标准化偏差大多在0 附近,说明匹配后变量个体差异特征得到进一步下降,此次PSM 处理是有效的。
3.3 双重差分回归分析
在PSM 匹配处理后,进一步对新样本进行DID 回归分析。如表5 所示,表5 中第2 列至第6 列表示逐步加入协变量的回归结果。结果显示:在逐步加入控制变量中,交互项Treated×Year 的回归系数均为正,并在5%显著性水平下显著。表明“试验区”的设立会对上市企业价值产生正向影响。
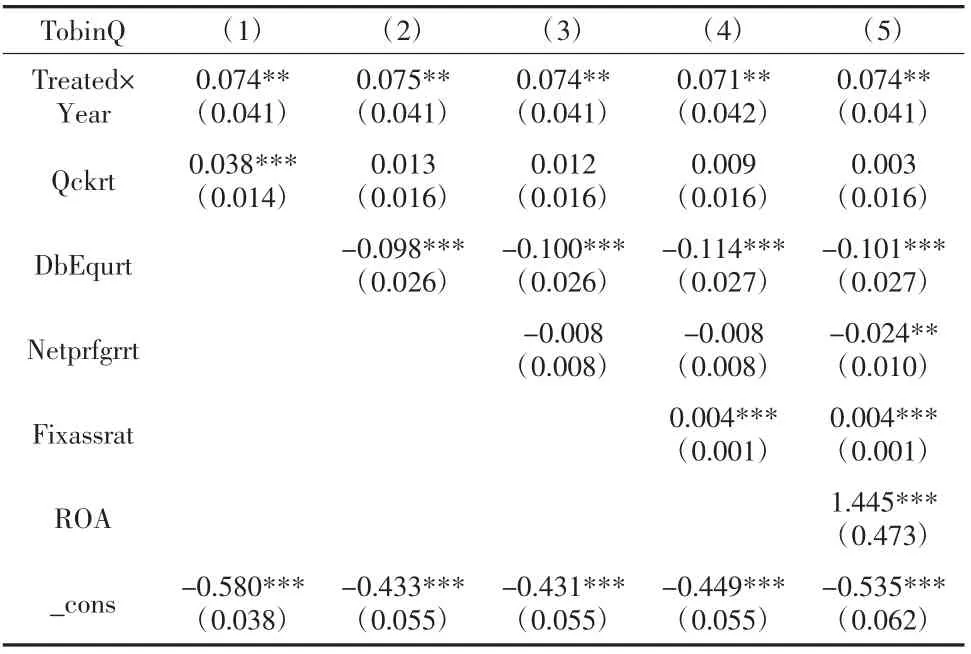
表5 PSM-DID 检验结果
3.4 稳健性检验
安慰剂检验具体操作是将“试验区”设立时间人为提前一年和延后一年,若交互项系数结果仍显著为正,说明企业价值波动并非是“试验区”设立所带来的,原结果不稳健。反之,原实验结果稳健。具体安慰剂检验结果如表6 所示。
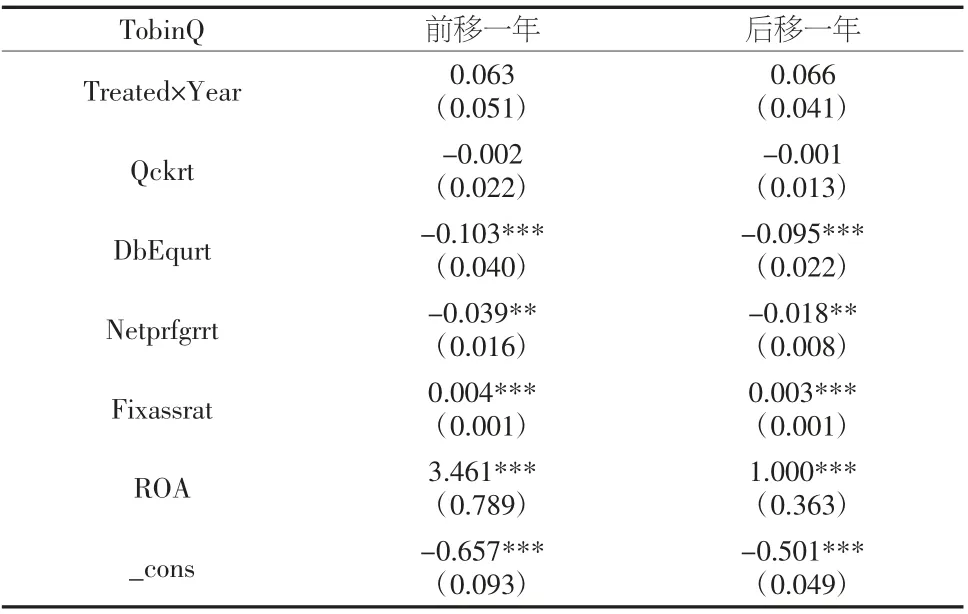
表6 PSM-DID 检验(安慰剂检验)
从表6 可以看出:在逐步加入协变量过程中,交互项系数均不显著。说明”试验区”设立时间无论前移一年还是后移一年不能对上市企业价值产生显著影响。表7 给出匹配过程中均值差异显著性检验。从表7 中可以看出,除了固定资产周转率匹配后的均值在1%显著性水平下存在显著差异外,其余变量匹配后均不存在显著性差异,证明该匹配结果有效。
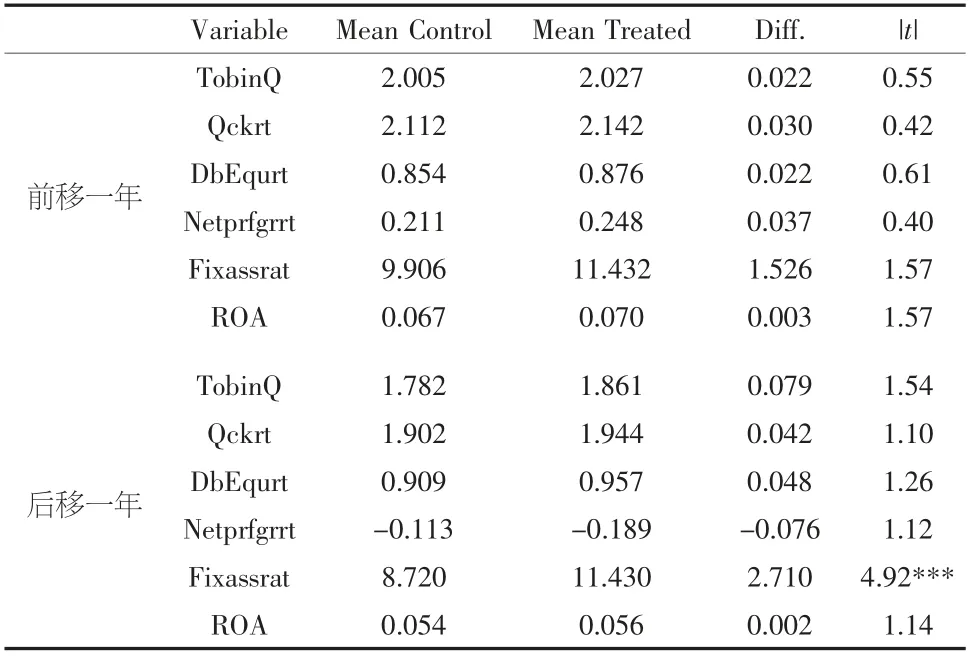
表7 PSM-DID 匹配变量均值差异显著性检验(安慰剂检验)
4 结论与建议
本文基于PSM-DID 模型,以2017 至2021年“试验区”的上市企业相关数据作为实验组,非“试验区”的相关企业数据作为对照组,研究试验区设立对企业价值所产生的影响。研究表明:国家数字经济创新发展试验区的设立促进了企业价值的提升。基于该研究发现,本文提出如下三点建议:第一,在政府政策制定层面上看,《实施方案》的颁发为企业数字化转型提供政策支持,促进企业价值提升。基于该政策所带来的正面影响,政策制定者可考虑适当扩大试点范围,进一步加强引导数字经济与实体经济的深层次融合。第二,在企业发展机遇层面上看,政策覆盖中的企业应该把握机遇,强化数字思维,发挥先发优势,积极探索数字经济发展新动能,为上市企业数字化转型规划提供新思路。第三,在投资者投资层面上看,“试验区”的设立给企业发展产生正面效应,投资者在选择投资对象时可将受政策影响的相关行业和企业纳入正向考核指标,扩大投资回报机率。
猜你喜欢
浙江人大(2022年4期)2022-04-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
魅力中国(2021年51期)2021-11-28
小学生学习指导(高年级)(2021年4期)2021-04-29
中国外汇(2019年18期)2019-11-25
电子制作(2019年24期)2019-02-23
中国知识产权(2018年12期)2018-12-29
名人传记·财富人物(2016年9期)2016-11-10
名人传记·财富人物(2016年9期)2016-11-10
大社会(2016年6期)2016-05-04
