
基于数据仓库的论文推荐方法研究
2022-12-06 08:49汪贻杰沙梦钒周建平
现代矿业 2022年11期
汪贻杰 沙梦钒 赵 鹏 周建平
(1.安徽工业大学计算机科学与技术学院;2.中钢集团马鞍山矿山研究总院股份有限公司)
矿业类期刊文献不仅凝练了重要的行业知识,更是矿山知识类网站的一个重要组成部分。在期刊文献内,一篇论文包含很多专业信息,如论文的标题、摘要、关键词、正文和作者等,如何根据这些专业信息实现高效快速的论文推荐是目前矿山知识类网站面临的一个重要课题[1]。
对于文本推荐和数据仓库技术在知识类相关领域的应用,在行业内有着广泛关注与研究。在基于论文数据分析的专家推荐方法、装置、设备及存储介质中,孙圣力等[2]提出了基于文本相似度、贡献率及复合影响因子算出的各论文作者的推荐分数并进行推荐,但未考虑到在大规模论文数据下的专家推荐方法计算时间长且新的推荐存在的冷启动问题。在基于Spark的电影推荐系统中,朱本瑞[3]实现了对电影数据的Spark离线推荐和Spark Streaming的实时推荐,并将结果存储到Redis、Elasticsearch、MongoDB中,但未考虑将中间临时计算结果保存到Hive中,以节省中间临时计算时间。
通过深入系统的研究,提出了基于数据仓库实现的离线计算论文推荐方法。首先由维度建模搭建一个数据仓库,设立论文推荐主题库;然后,将论文特征数据集分词预处理后加载到HDFS中,在HDFS中使用Hive计算推荐结果,将结果保存在论文推荐主题库中;最后,在前端矿山知识类网站中实现可视化展示。
1 数据仓库设计
1.1 数据仓库体系
在设计中,数据仓库体系主要分成原始数据层、明细数据层、数据汇总层、应用数据层4层。在分层体系中,原始数据层用于存储预处理的数据集;明细数据层用于将原始数据层的结构化和半结构化数据转换并清洗维度缺项,转换为结构化数据;数据汇总层用于对明细数据层提取特征构造维度-权重矩阵;应用数据层用于聚合维度权重矩阵在主题表中,并用于指标统计、计算及数据挖掘等。该数据仓库分层体系结构的目的在于将数据量巨大的原始论文,通过数据仓库分层架构思想,将数据存储在不同分层中,将结果数据与中间数据分开,减少跨层调用。同时,将计算过程中产生的中间临时计算保存在数据仓库中,极大地减少了重复计算。
1.2 分析主题设计
数据仓库模型设计是面向主题的,因此在设计数据仓库维度模型前要先确定分析主题[4]。分析主题的选择是根据业务的实际需求分析而定的,且根据主题相关的分析结果可为相关人员或用户提供决策支持[5]。在此选择其中的论文为主题进行分析介绍。一篇论文主要包含标题、摘要、关键词、正文、作者等,本文主要围绕论文特征维度对论文进行数据分析,设计构建数据仓库论文推荐主题库。
1.3 维度表设计
维度表是描述分析主题的角度,选择分析的维度要能从数据源中直接得到,且有利于对所选主题的分析。采用星型模型设计的维度表主要由事实表和维度表组成,每个维度表都有一个维度值作为主键,所有这些维度表的主键结合成事实表的主键。在维度表的建立过程中,维度值必须唯一,且每个维度代表对一个分析主题不同角度的描述[6]。根据分析主题、论文推荐主题库的设计,这里建立了标题、摘要、关键词3个维度。
这些维度表中的数据是由原始数据层和明细数据层加载到汇总数据层,并在DWS中存储。在DWS层中,通过对加载数据中标题、摘要、关键词等特征元素提取,并分别构造维度-权重矩阵得到分析主题的3个维度。以标题-论文权重矩阵t_p为例,对于t_p矩阵的每个元素f pt表示标题标签t在论文p中的权重,计算公式为
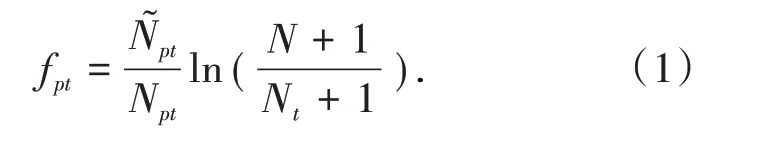
式中,N͂pt为论文p中包含标题标签t的个数,N pt为论文p中的标题标签数;N为总的论文数;而Nt是包含标题t的论文数量。
通过构造出的标题维度-权重矩阵、关键词维度-权重矩阵、摘要维度-权重矩阵,对论文主题进行3个不同角度的分析,对论文主题进行更精确的描述。
1.4 相似度计算
通过论文主题下的多个特征维度的聚合和汇总,完成对主题下的指标计算。这里计算的指标是论文推荐主题库下论文数据之间的相似度,通过计算不同论文对象标签间的相似度,并对不同文本部分的标签进行加权后得到总的论文对象间的相似度。主题库主题中所有论文数据对象都进行相似度计算,汇总得到相似度推荐指标。计算中,特征维度间的相似度采用的是余弦相似度,计算公式如式(2)。pi、p j表示不同的向量元素,p()i、p(j)表示向量pi、pj的分量。p()i、p(j)2个向量分量的点积除以pi、pj2个向量的模长,得到了pi、pj2个向量的余弦相似度sin(pi、pj),余弦相似度值越大,则表示2个向量的相似度越高。

2 推荐方法设计
2.1 整体推荐方法流程
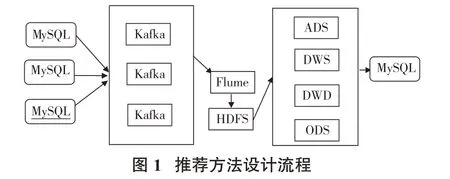
期刊论文数据仓库流程设计见图1,步骤如下。
(1)数据预处理。从MySQL数据库的数据源中获取数据表中的数据,对获取的数据进行分词预处理,将分完词的数据发送到Kafka集群中的Paper主题中。
(2)数据存储。使用Flume的Sink配置Kafka_File_HDFS的脚本配置文件,将Kafka的Paper主题中的数据采集到HDFS中存储,存储过程中按照采集的日期进行分区。
(3)数据处理和计算。对存储在HDFS中的预处理论文特征数据采用ETL加载到数据仓库的论文推荐主题库中,按照数据仓库论文推荐主题库结构设计进行分层处理,在ODS层存储论文分词特征数据集,将ODS层中按行拆分格式化并将关键词为空的数据清洗过滤掉后,转换成标题元素、摘要元素、关键词元素3张特征数据表存入DWD层,并在DWD层将元素转换为(单词,词频),为构造维度表做准备。在数据服务层DWS中加载DWD表中特征数据表,构造为3张维度表。在ADS应用层将DWS层不同维度-权重矩阵表进行聚合,得到论文特征主题表。采用Spark对应用层论文特征主题表中的数据计算相似度指标,并将指标结果存入论文推荐主题库应用层推荐表中。
(4)数据展示。将应用层的推荐结果采用Spark读取Hive写入MySQL的方式把推荐结果写入到MySQL数据库中,在矿山知识服务平台的前端网站采用Web API服务的形式调用数据库中数据。当用户在线搜索论文时,数据库中相关推荐论文将会推荐给用户。
2.2 加权相似度算法
对于推荐指标计算,传统的基于文本的相似度计算方法一般都单一统计文本的关键词,未考虑到关键特征文本权值的影响。而关键特征文本往往也是用户最为看重的,在采用多维度特征融合的离线推荐计算中,使用加权的余弦相似度算法对关键特征维度赋予更高的权重。如算法伪码所示,a表示标题元素维度特征相似度,b表示关键词元素维度特征相似度,c表示摘要元素维度特征相似度,d表示论文所述的文献类别特征相似度。将输入的ob ject和pa per对象的特征相似度a、b、c的权重因子分别设置为0.3,0.55和0.15,d为权重修正因子,根据2个论文对象文献类别维度的相似度计算,结果在0.01≤d≤0.1。由此计算出core为多特征维度融合加权下的论文相似度。在初步的过滤中,core值大于0.1且属于前50的结果会被保留,再次过滤中,core值大于0.3或前15的结果会被保留并进行推荐。推荐结果入库汇总保存在ADS层论文推荐表中。
算法为SVM加权余弦相似度算法,输入从ADS层读取表ads_paper,存入paper_list;输出对paper_list进行广播,声明为bd_paper_list。

2.3 评价指标
在试验结果的评价方面,采用准确率、召回率和F1值进行分类评价,计算公式如下

式中,TP表示指标结果符合匹配的数据条数;F P表示指标结果推荐中不符合匹配的数据条数;FN表示指标结果中符合匹配未被推荐的数据条数[7];precision准确率表示分类器正确识别文本的一个统计测量;recall召回率指的是检索出的相关文档数和库中所有相关文档数的比率[8];F1值是衡量分类器分类准确性的标准,是准确率和召回率的加权平均,F1最大值为1,最小值为0。
3 过程与结果
3.1 试验环境
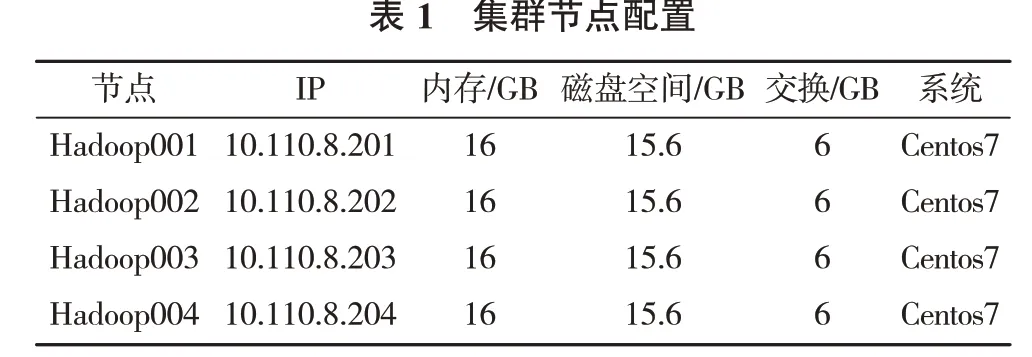
该试验使用了4台虚拟服务器构建集群节点,配置见表1。其中Hadoop001是Hadoop集群和Spark集群的主节点,Hadoop002-Hadoop004为spark的从属节点,运行slave进程。Zookeeper集群运行在Hadoop002-Hadoop004 3个节点,Kafka集群运行在Hadoop001-Hadoop004节点,Hive、Flume运行在Hadoop001节点,这4台主机都为Hadoop的数据节点。本次集群环境试验中Hadoop的版本为3.1.4,Spark的版本为3.0.0,MySQL版本为5.1.3,Zookeeper版本为3.6.2,Kafka版本为2.11.0,Flume版本为1.7.0,Hive版本为3.0.0。
?
3.2 数据集
试验采用了203867条论文数据作为数据集。
3.3 试验结果及分析
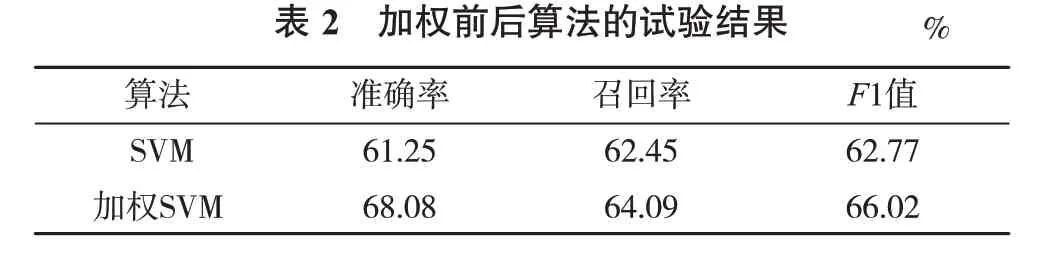
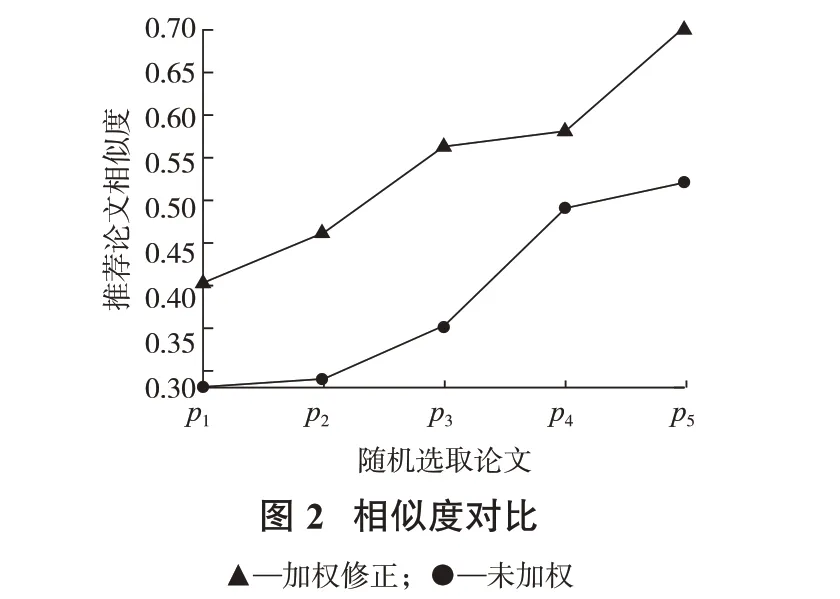
为验证SVM加权余弦相似度算法的有效性,本文与未加权的余弦相似度方法进行对比。对试验数据集分别采用2种算法计算相似度。由表2可知,加权后准确率提高了约6%,F1值提升了约3%,无论是准确率、召回率、F1值,改进后的算法指标都明显优于原始算法。再随机选取5篇搜索论文,统计推荐论文在2种算法下的相似度值计算结果(图2)。图2结果显示,采用维度融合加权后,推荐结果相似度有显著提升,降低了非核心特征维度-摘要维度的权重影响,提升了关键特征维度-关键词维度的权重影响,使推荐结果更突出核心关键词的文本价值作用,推荐结果也更符合预期。
?
4 结语
(1)随着期刊融媒体发展和知识服务需求的不断提高,为用户提供论文推荐服务的精准度成为关键指标。为此,设计并实现了融合矿业期刊论文数据和数据仓库技术的离线期刊论文推荐方法。本研究方法在数据仓库维度建模的基础上,利用维度融合加权算法综合对期刊论文数据进行离线计算并进行在线推荐,当用户搜索论文时,能根据用户所需快速准确地提供相关文献推荐,提高用户的使用黏性。目前,该数据仓库模型已上线应用,为论文的相关推荐工作提供技术支持。
(2)该研究方法在后期工作中会将论文其他相关部分纳入论文推荐的分析维度中,同时将引入SparkStreaming、Flink等实时在线计算引擎,实现对搜索论文的实时在线推荐。
猜你喜欢
当代陕西(2022年4期)2022-04-19
电子乐园·下旬刊(2021年3期)2021-02-08
当代陕西(2020年17期)2020-10-28
中华诗词(2019年7期)2019-11-25
自然资源信息化(2019年4期)2019-03-29
人大建设(2018年5期)2018-08-16
山东工业技术(2016年15期)2016-12-01
灯与照明(2016年4期)2016-06-05
应用科技(2015年5期)2015-12-09
中国教育信息化(2015年10期)2015-08-23
