
基于神经网络优化算法的降水量预测研究
2023-06-04 08:40李建磊付世豪宋金繁
黑龙江科学 2023年8期
李建磊,付世豪,宋金繁
(华北水利水电大学,郑州 450046)
0 引言
降水量预测是对未来某地区降水做出科学的判断或预见,根据当地的自然气候,如气温、气压、湿度等,应用科学方法,对降水的可能性或降水量做出客观描述,是令管理部门提前做出决策、编制计划及进行有效处理的重要依据。
近些年,神经网络预测方法备受关注。反向传播(Back Propagation,BP)神经网络算法具有任意复杂的模式分类能力和卓越的多维函数映射能力。BP算法的实质是采用梯度下降法来计算网络误差函数的最小值。但若目标函数很复杂,则会出现锯齿形现象,导致BP算法收敛速度慢。BP算法是一种局部搜索最优解的优化方法,有可能会使算法陷入局部最优解,也会发生过拟合现象,即预测能力达到一定程度再进行训练,随着训练能力的提高,预测能力反而下降。遗传算法(Genetic Algorithm,GA)是一种进化算法,具有良好的容错性和一定程度的自适应自组织能力,使用概率机制进行迭代,具有一定的随机性,还拥有良好的学习识别功能等,所以遗传算法作为一种具有高度并行、随机、自适应的搜索算法,是一种全局搜索最优解的方法,可扩展性强,易与BP算法结合,故使用遗传算法优化的BP算法可解决学习速度慢、易陷入局部最优等问题。
1 BP神经网络预测模型
BP神经网络有两个步骤,即信号的正向传播和误差的反向传播,并在误差反向传播过程中不断优化权值于阈值,得到最优参数,保存网络。BP算法的实质是采用梯度下降法沿着误差函数的负梯度方向修改权值和阈值,从而获得最合适的结果[1]。以下是建立BP网络模型的步骤:
1)设置模型输入输出样本、创建网络。

3)输入训练样本与预测样本,对数据进行预处理。输入样本:X=(x1,x2,…,xn)T,期望输出:d=(d1,d2,…,dn)T。对数据使用MATLAB自带的mapminmax函数进行归一化处理。Mapminmax的数学公式:
(1)
其中,xmin、xmax分别为映射前的矩阵每一行的最小值和最大值;ymin、ymax分别为映射到的新矩阵每一行的最小值和最大值。
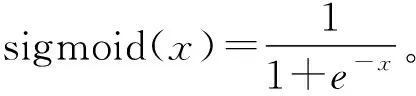

6)计算网络误差。当网络误差达到预设值或学习次数大于设定的最大次数,则结束训练;否则,选取下一个训练样本和对应的期望输出,返回到3),进入下一轮学习。
7)网络训练结束后,对预测样本进行预测并输出预测值。
2 基于GA优化的BP神经网络预测模型
遗传算法的作用是优化BP神经网络的初始权值与阈值,是一个不断修正阈值与权值的过程,经过训练,可使误差越来越小[2-4]。训练后,再对网络进行测试。以下是基于遗传算法优化的BP神经网络预测模型实现:
1)输入神经网络初始样本数据并对其进行预处理。
2)种群初始化。
编码。对每个个体使用实数编码,将其编码为一个实数串,由输入层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值、输出层阈值4个部分构成遗传算法的染色体,每个染色体长度为:
S=m×h+h+n×h+n
(2)
其中,m、h及n分别为输入层节点数、隐藏层节点数及输出层节点数。
种群规模。种群规模若是过大,会造成资源浪费且难以收敛;种群规模若是过小,遗传算子会产生随机误差,即模式采样误差,会妨碍小群体中有效模式的传播,从而造成收敛于局部极小点。一般情况下,种群规模通常取20~200。
进化代数。进化代数不宜过大,过大会增加时间消耗,通常选取100~1 000。
3)将BP神经网络训练得到的误差作为适应度值,即评价函数确定为期望值与预测值的绝对误差函数。
(3)
其中,k是系数,d、o分别为期望输出与预测输出。
4)确定遗传算法的选择操作、交叉操作、变异操作方法的选取。评价函数、选择操作、交叉操作及变异操作方法的选取分别为绝对误差函数、轮盘赌法、实数交叉及随机变异。
设定交叉概率与变异概率。
交叉概率。交叉概率过大,随机性增加,会造成最优个体的丢失,还会导致不必要的时间浪费;交叉概率过小,不能有效更新种群,还会阻碍算法搜索。一般选为0.2~1.0。
变异概率。变异概率越大,变异操作被执行的次数越多。较好的变异概率产生的新生代摒弃父代的不良基因,能完整保存信息。若变异概率过大,则可能造成种群已有的优良模式被破坏;若变异概率过小,又会使种群的进化速度降低。通常取值为0.001~0.1。
遗传算法参数设定:种群规模为20~200,进化代数为100~1 000,交叉概率为0.2~1.0,变异概率为0.01~0.1。
5) 对进化的数据(适应度)进行检验。如果达到预期目标则停止进化,如果未达到目标值且进化没有结束,则重新计算种群的适应度,从中选出最优个体。
6) 将遗传算法得到的最优权值与阈值赋予BP神经网络,再进行训练学习,达到要求后输出预测值[5-8]。GA-BP神经网络流程如图1所示。
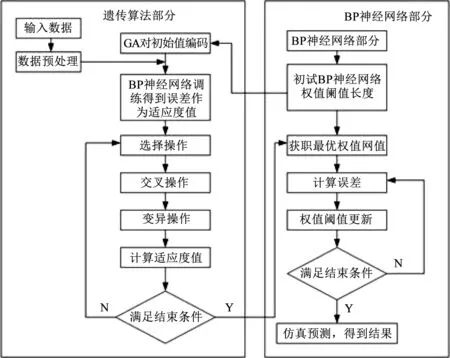
图1 GA-BP预测模型流程图Fig.1 Flow chart of GA-BP prediction model
3 实例分析
3.1 实验数据
实验数据来源于河南安阳、南阳、商丘、信阳1953年8月—2013年12月的月降水量数据。根据风速、气压、气温、气压、湿度等因素进行降水量预测。用于训练的样本是1953—2013年的降水量数据,共有725组数据,选取1953年8月—2010年12月的数据作为训练样本,2011年1月—2013年12月的数据为预测样本,应用BP神经网络和基于遗传算法优化的BP神经网络两种算法对36个月的降雨量进行预测。
3.2 遗传算法优化的BP神经网络实验
为了使遗传算法达到最好的效果,进行实验寻求遗传算法最佳的参数设置。BP神经网络的设置为模型参数保持不变,以3个定量、1个变量的定量分析法进行实验。因为遗传算法本身具有一定的随机性,所以并不能准确地说哪个参数一定是最好的,只能找出一个大概的范围,具体应用时可稍作调整。迭代次数选取50次进行预测实验,实验结果见表1。
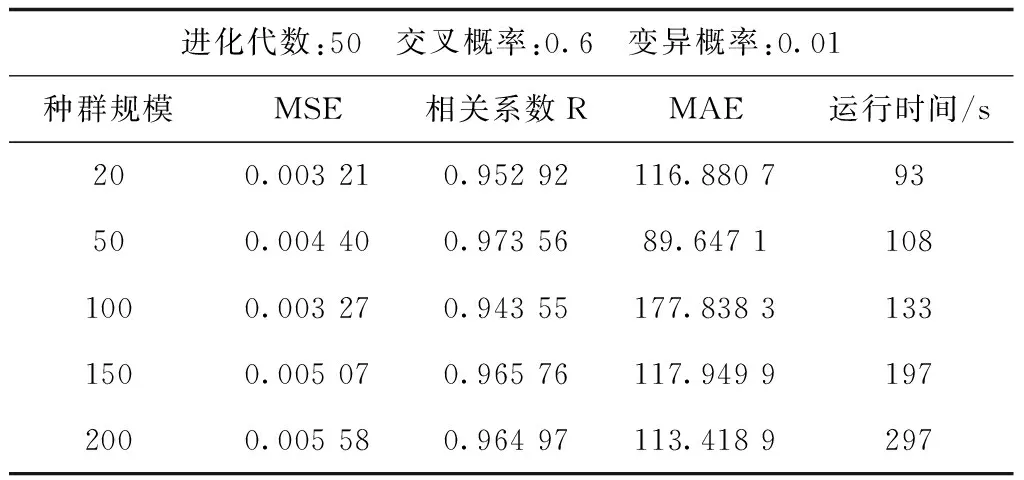
表1 各最佳种群规模实验结果Tab.1 Experimental results of optimal population size
从结果来看,种群规模为50时,模型精度与拟合程度最高,虽然比种群规模为20、100时的最小MSE要高出0.001 2左右,但是相关系数比种群规模为20、100时的相关系数要高且平均绝对误差要小。种群规模为100时,运行时间比种群规模为50时的运行时间要多出30 s左右。综合来看,种群规模数选为50即可。
确定种群规模数后,需进一步确定交叉概率,实验结果见表2。
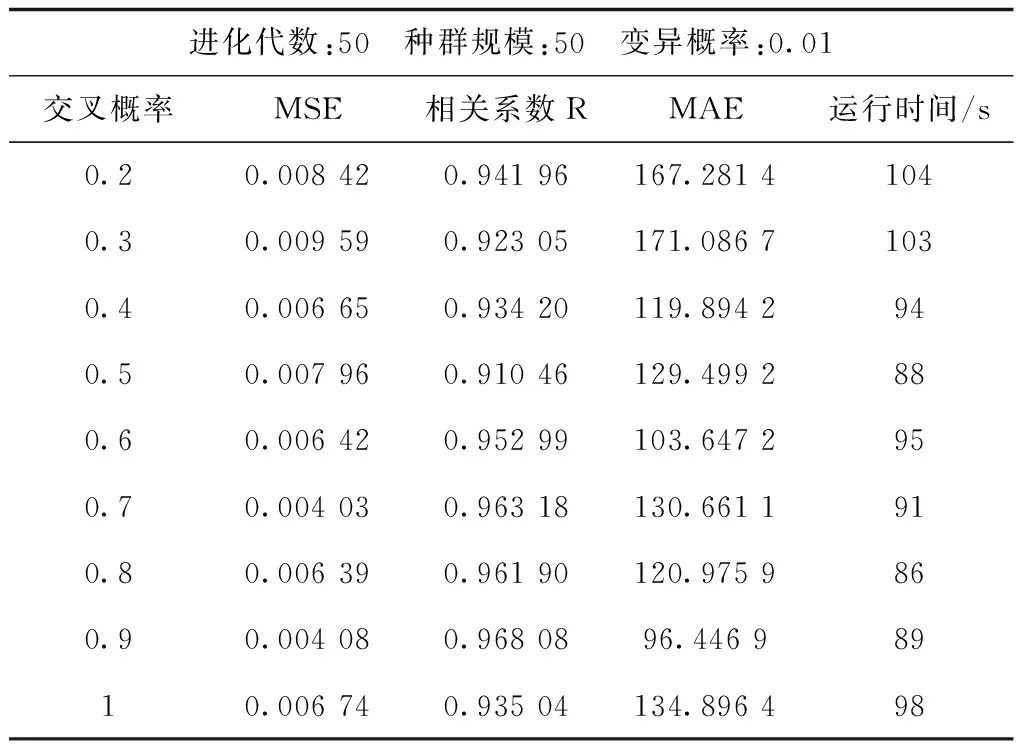
表2 各交叉概率实验结果Tab.2 Experimental results of cross probability
算法的运行时间并没有相差太多,观察它们的相关系数发现,交叉概率在0.6~0.9的数据拟合度都到达了0.96左右,运行时间最高相差了11 s,但交叉概率为0.9时,最小MSE和平均绝对误差MAE较低,以此推测交叉概率选在0.9附近即可。
为了确定变异概率,选取变异概率为0.001、0.005、0.01、0.05、0.1进行实验,实验结果见表3。
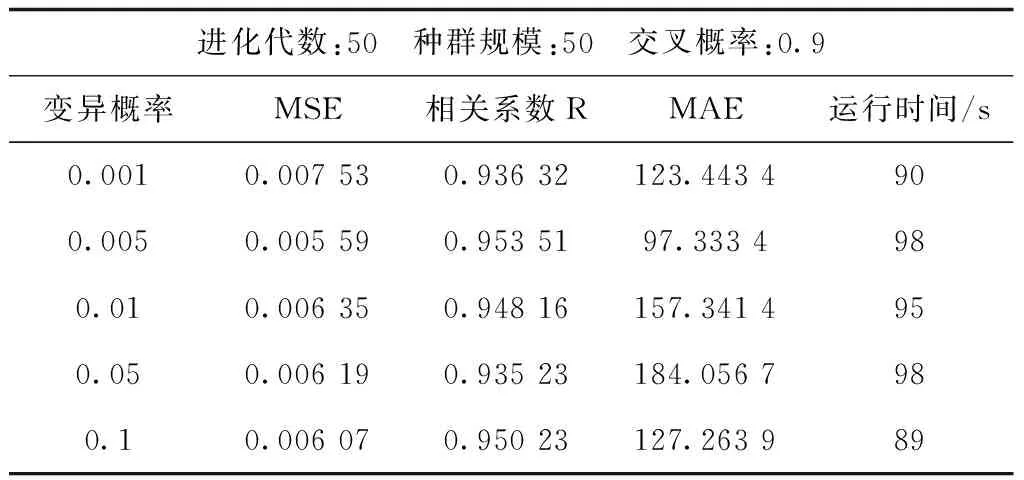
表3 各变异概率实验结果Tab.3 Experimental results of mutation probability
从表3可以看出,变异概率为0.005与0.1时,相关系数仅差0.003 28,说明拟合能力很接近,不过虽然变异概率为0.1时的运行时间相比于变异概率为0.005时的运行时间少了9 s,但最小MSE与平均绝对误差MAE都是变异概率为0.05时的更小,故而变异概率取0.005左右即可。
由表4可知,迭代次数为100时,相关系数最大、最小MSE与平均绝对误差MAE最小。迭代次数为200时,虽然比迭代次数为100时的各项指标差一点,但是运行时间却长很多。故而迭代次数选取100次即可。
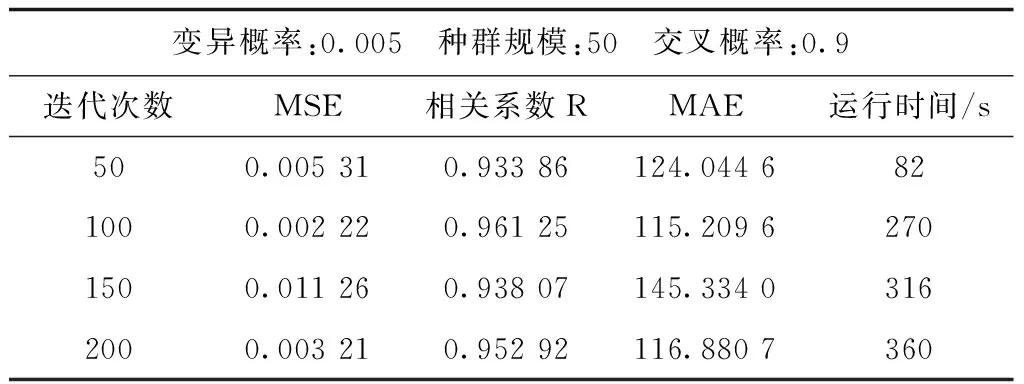
表4 各迭代次数实验结果Tab.4 Experimental results of each iteration
4 结果分析
为了比较未优化的BP神经网络预测模型与遗传算法优化后的BP神经网络预测模型在精度与拟合程度方面的差距,做出两种模型对河南安阳、南阳、商丘、信阳4个站点采用BP神经网络预测模型与GA-BP神经网络预测模型进行降水量预测的预测结果与误差对比图,如图2所示。
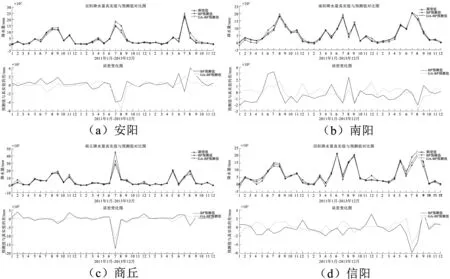
图2 GA-BP与BP预测模型对比Fig.2 Comparison of GA-BP and BP prediction models
可以看出,经过遗传算法优化后的BP神经网络的预测值要更加靠近真实值,说明GA-BP神经网络预测模型确实比未优化的BP神经网络预测模型精度更高。从误差对比图中可以看出,GA-BP神经网络模型与未优化的BP神经网络模型相比,误差更小一些,不过也有个别月份预测的降水量误差值甚至比未优化的神经网络模型还要大,所以需要进一步分析,给出各地区使用两种预测模型进行预测后的平均绝对误差MAE、最小MSE、均方根误差RMSE及相关系数R,如表5所示。
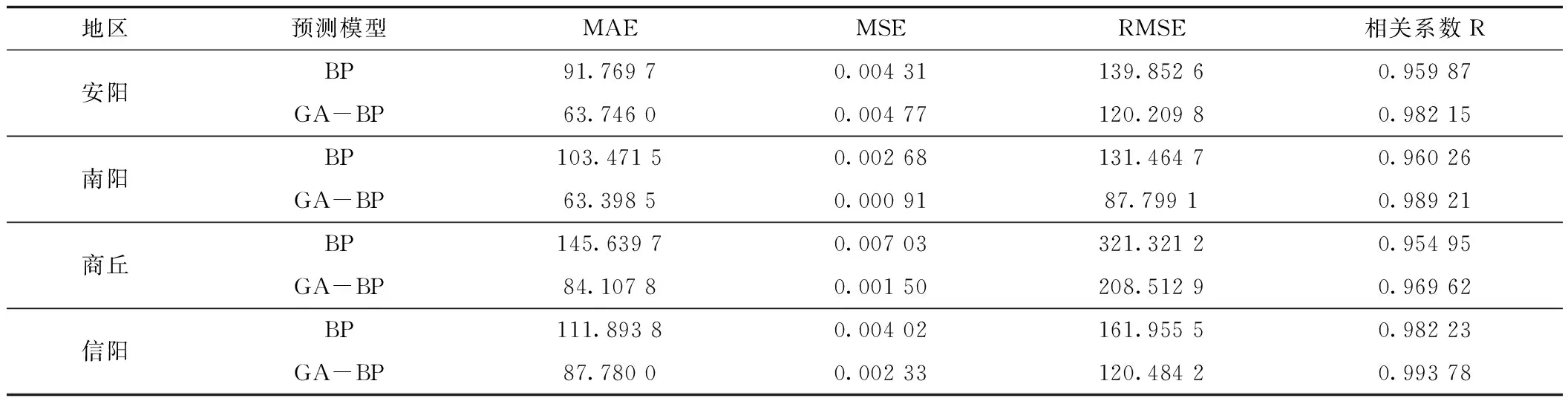
表5 GA-BP与BP预测模型误差Tab.5 Error of GA-BP and BP prediction model
根据表5可以看出,安阳、南阳、商丘、信阳等地应用遗传算法优化后的BP神经网络模型预测的降水量平均绝对误差MAE要比BP神经网络模型平均小了38.435 6,均方根误差RMSE平均小了54.397,相关系数平均提升了0.193 6。南阳市GA-BP模型预测的降水量最小MSE比BP模型的最小MSE小了0.001 778,这几乎是BP模型的一半,而商丘市两个模型的最小MSE相差了0.005 523 3,也就是说BP模型的最小MSE是GA-BP模型最小MSE的4.68倍,且商丘市GA-BP模型预测的降水量MAE、RMSE分别比BP模型小了61.531 9、112.808 3,几乎小了一半。由此得出,GA-BP神经网络模型相对于BP神经网络模型,精度确实提高了不少。
5 结论
将遗传算法算法与BP算法有机融合, 大大提高了模型预测精度,不过某些月份降水量预测误差值却比未优化的BP预测模型误差更大,说明遗传算法优化后的BP神经网络从全局来看确实比BP神经网络预测模型精度高,但是从局部来看,遗传算法优化后的BP神经网络还不是很理想[9-10]。
猜你喜欢
今日农业(2022年15期)2022-09-20
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
红土地(2018年7期)2018-09-26
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
智能系统学报(2015年4期)2015-12-27
百科知识(2015年18期)2015-09-10
当代畜禽养殖业(2014年10期)2014-02-27
