
基于客户分类的海量数据动态路由存储策略研究
2023-06-15 05:29刘文华
计算机时代 2023年6期
刘文华
摘 要: 电商行业的海量数据存储,多采用以客户为切分键进行分库分表的策略,但由于大客户和普通客户数据体量差距巨大,往往会导致数据在各库表中分布严重不均。本文基于分布式数据库存储,设计了区分大客户和普通客户的分库分表策略、能够及时识别客户数据变化的实时数据监控,以及基于客户分类动态选择存储策略的动态路由组件,可有效保障数据的均匀分布。
关键词: 客户分类; 海量数据; 分库分表; 动态路由策略; 实时数据监控
中图分类号:TP311.1 文献标识码:A 文章编号:1006-8228(2023)06-07-04
Dynamic routing storage strategy of mass data based on account classification
Liu Wenhua
(Beijing Wuzi University, Beijing 100000, China)
Abstract: The mass data storage in e-commerce and other industries mostly adopts the strategy of taking the account as the sharding key to divide databases and tables. However, due to the huge gap in the data volume between key account and ordinary account, the distribution of data in each database and table is often seriously uneven. Based on distributed database storage, a customized strategy of divide databases and tables for key account and ordinary account is designed. The real-time data monitoring can identify account data changes in time, and the dynamic routing component can dynamically select storage strategy based on account classification. It can effectively ensure the uniform distribution of data.
Key words: account classification; mass data; divide databases and tables; dynamic routing strategy; real-time data monitoring
0 引言
随着互联网各项技术的日臻成熟,物流体系逐步完善,电商行业快速发展。线上支付方式呈多样性,网上交易量与日俱增,一些头部电商平台的日均交易量已至千万量级,随之而来,每天产生的各类业务数据也呈指数级增长,如订单、支付、物流、营销等海量业务数据日均数据增量已达到百亿量级。如此海量数据通过传统的单机数据庫存储,从存储性能和存储容量上显然都已无法满足要求。
分布式数据库[1,2],利用其多节点数据分片存储的方式,突破了单机服务器容量和吞吐量的限制,配以合理的分库分表策略、数据存储路由策略,则可满足海量数据高效存储的使用场景。
数据存储路由策略,一般以客户编号为切分键,基于库表数量进行取模计算,以定位数据存储的库表位置,使数据能均匀的分散存储至各库表之中。这种方案是以每个客户产生的数据量相差不大为前提的,但实际场景中往往存在一些大客户,其产生的业务数据量远远大于普通客户,这种情况下,会出现大客户海量数据存储于个别库表之中,导致数据库数据分布严重不均,个别库表数据量巨大(亿量级),严重影响数据库的性能、吞吐量和磁盘利用率。
1 存储策略
由于客户业务并非一成不变,随着自身业务的发展,很可能会在普通客户和大客户之间来回转换,通过设计客户日增业务数据监控任务,来识别客户身份转换,动态调整数据路由策略,设计数据路由策略组件,支持实时动态切换路由策略,以便及时有效应对客户身份变化。
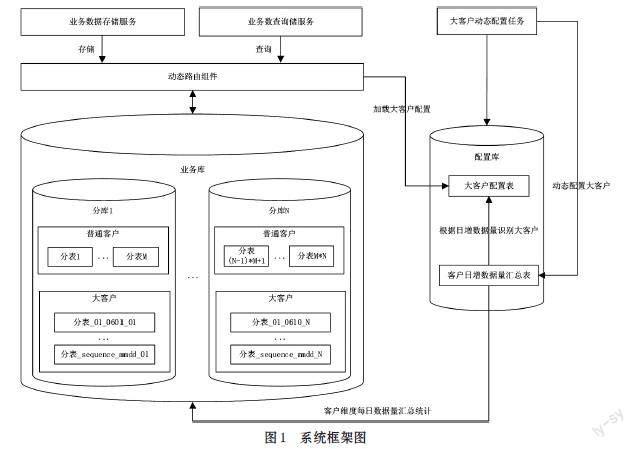
为解决大客户和普通客户数据量不均衡所产生的数据存储问题,本文主要从分库分表[3,4]策略设计、大客户动态识别,以及数据监控设计和动态路由组件设计三方面进行阐述,整体系统框架图如图1所示。
1.1 分库分表策略设计
分库分表策略的设计,主要针对大客户和普通客户,制定不同的分库分表策略。
1.1.1 普通客户
设计原则:普通客户每日产生的业务数据量差异较小,则以客户为切分键进行分库分表设计,数据将均匀分散存储至数据库各库表之中。
分库分表规则:
分库数量:N个数据库
分表数量:M*N(每个数据库M张表)
所在库表计算方式:
所在分表=(Hash(客户编号)%(M*N))+1
所在分库=(Hash(客户编号)%(M*N)/M)+1
1.1.2 大客户
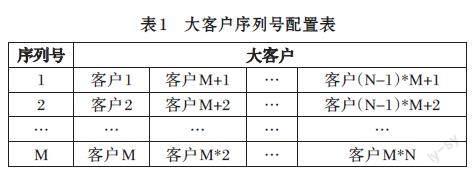
设计原则:大客户每日产生的业务数据量庞大,可能达日增百万量级,则设计为每日一张表存储当日产生的数据,存储一年数据,则共需创建366张表,平均分布于全量分库当中。每年同一日期的数据,存储在同一张表中,表可重复使用。考虑到大客户数量多时,即使每日一张表,也可能会达到千万甚至是上亿量级,因此设计N套分表,每套为366张,共计N*366张表。将客户平均分配到N个分组中,使各分表得以充分利用,数据可以均匀分配至数据库各库表之中。
分库分表规则:
分库数量:N个数据库
分表数量:M(套)*366
1.2 大客户动态识别及数据监控设计
大客户动态识别及数据监控[5]设计主要为及时识别出大客户和普通客户身份的转换,从而动态调整数据路由策略,及时应对客户身份变化。
大客户定义标准:连续M日,每日新增业务数据量>N万
每日定时任务,查询业务数据库,以客户维度汇总统计前一日该客户产生的业务数据量,统计数据存储至客户日增数据统计表(表2)。
1.3 动态路由组件设计
动态路由组件可根据客户分类动态地选择数据存储策略,结合大客户动态识别及数据监控功能,可做到及时有效应对客户身份变化。
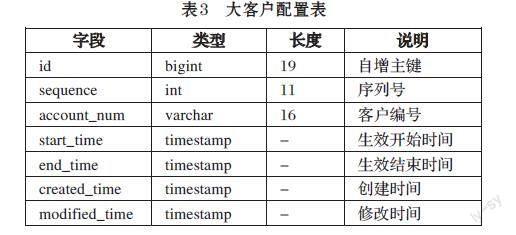
动态加载大客户配置信息,即将监控系统识别出的大客户信息,动态加载至系统内存当中,以便当查询路由时,可以及时高效的读取使用。主要包含如下两种加载方式:
⑴ 启动加载
动态路由组件启动时,查询大客户配置信息,并加载至内存当中。
⑵ 定时加载
动态路由组件启动后,启动定时任务,定时查询大客户配置信息,并加载至内存当中。
动态路由,即执行数据库操作时,根据配置信息,动态选择定位数据库表的策略,以便准确定位数据所在库表信息,主要流程如下。
⑴ 判断查询客户是否在大客户配置信息中。
⑵ 如果在大客户配置信息中且查询时间条件在生效时间范围内,则根据大客户路由策略定位所在库表。
⑶ 如果不满足条件⑵,则根据普通客户路由策略定位所在库表。
2 结论
本文针对高并发海量数据[6]存储场景,由于大客户数据量大,导致数据存储分布不均,从而影响数据库整体性能、吞吐量和磁盘利用率的问题,提出了一种高效可行的解决方案,并完整详细阐述了该方案的理论依据和技术架构。设计了适用于大客户和普通客户各自的分库分表规则,解决了不区分客户分类统一分库分表策略带来的数据倾斜问题。设计了客户数据监控策略,通过监控客户业务数据的发展变化,能够及时识别客户身份的变化,辅助动态路由组件及时动态的调整路由策略。设计了动态路由组件,可以根据不同的客户分类,选择合适的路由策略,并实现了动态加载功能,可以准确及时的加载更新客户配置和路由配置的变更。本方案普遍适用于存在海量数据存储,且不同客户分类业务数据量差异较大的场景,希望能给有类似场景的开发者,提供一些借鉴思路。
参考文献(References):
[1] 刘晓光.基于MySQL的分布式SQL数据库的设计与实现[D].
硕士,中国科学院大学(工程管理与信息技术学院),2016
[2] 乔洪宇.分布式数据库中间件驱动模块的设计与实现[D].
碩士,哈尔滨工业大学,2014
[3] 沈佳杰,卢修文,向望,等.分布式存储系统读写一致性算法
性能优化研究综述[J].计算机工程与科学,2022,44(4):571-583
[4] 王凌晖,解云月,周美华.Hadoop分布式存储架构的性能
分析[J].现代电子技术,2018,41(18):92-95
[5] 孙超,肖文名,曾乐,等.海量监视数据云存储服务模型的设计
与实现[J].武汉大学学报(信息科学版),2020,45(7):1099-1106
[6] 李韬睿,徐超,胡龙舟,等.基于云计算技术的海量信息分布式
存储研究[J].微型电脑应用,2022,38(10):90-93
