
基于SSA-SVM的营养健康信息文本分类研究
2023-06-15 01:22刘蕾田鑫宇朱大洲
计算机时代 2023年6期
刘蕾 田鑫宇 朱大洲

摘要: 为了能够快速、便捷地提取互联网中有关食物营养健康相关信息,针对传统文本分类算法的不足,利用麻雀搜索算法(SSA)良好的尋优能力对支持向量机(SVM)的最优参数组合进行搜索,提出一种基于SSA-SVM的文本分类方法。对SSA-SVM模型在不同的数据集中的分类效果进行了试验研究,结果表明,SSA全局寻优性能稳定,可有效降低SVM参数选取对系统泛化能力和分类精度的影响,SSA-SVM模型在营养健康文本分类中准确率可达到83.8%,对食物营养健康信息挖掘研究具有一定的参考价值。
关键词: 营养健康; 文本分类; 支持向量机; 麻雀搜索算法
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2023)06-82-05
Research on text classification of nutrition and health information based on SSA-SVM
Liu Lei1, Tian Xinyu1, Zhu Dazhou1,2
(1. Heilongjiang Bayi Agricultural University, Daqing, Heilongjiang 163319, China;
2. Institute of Food and Nutrition Development, Ministry of Agriculture and Rural Affairs)
Abstract: In order to extract the information about food nutrition and health from the Internet quickly and conveniently, and to address the shortcomings of traditional text classification algorithms, we use the optimizing ability of SSA to search the optimal parameter combination of SVM, and propose a text classification method based on SSA-SVM. The experimental study on the classification effect of SSA-SVM model in different datasets shows that the SSA global optimization performance is stable, which can effectively reduce the influence of SVM parameter selection on the generalization ability and classification accuracy of the system. The accuracy of SSA-SVM model in nutrition and health text classification can reach 83.8%, This method has certain reference value for food nutrition and health information mining research.
Key words: nutrition and health; text classification; support vector machine (SVM); sparrow search algorithm (SSA)
0 引言
随着生活水平的不断提高,大众的需求已逐渐由吃得饱向吃得营养、吃得健康转变,对食物营养健康科普的关注度也不断提高。经调查发现,一方面互联网中关于食物营养健康的知识存在差异,大众发表的见解也各不相同;另一方面随着信息技术的快速发展,食物营养健康方面的文本数据也呈指数级迅速增长。上述状况必然导致利用互联网搜寻食物营养健康科普文本并提取有价值的信息变得越来越困难。
快速整理原始科普信息、挖掘文本内在价值,对帮助个体和群体获得营养健康知识有重要导向性作用。因此构建相关科普舆情监测系统,以主题爬取的形式获得有关文本信息,再采用数据处理方法将具有相同特征的文本信息划分到事先确定的文本类别中,有助于大众便捷地阅读、检索、管理文本信息。
在十九世纪五十年代,Luhn等人首次提出了文本分类的方法。经过国内外专家学者近60年的探索研究,文本分类的理论逐渐成熟,并形成了多种分类算法[1]。当前,K-邻近算法、决策树算法、朴素贝叶斯算法、SVM算法是常用的主要分类算法。
邱宁佳等提出将特征项的权值融合到朴素贝叶斯公式中构造加权朴素贝叶斯分类[2];黄超等提出一种基于分组中心向量的KNN算法,在降低计算复杂度的同时,提升了算法的分类性能[3];段友祥等提出了基于主动学习的SVM评论内容分类方法[4];葛晓伟等提出一种基于字符卷积神经网络CNN与支持向量机SVM的模型用于中文护理不良事件文本分类[5];郭超磊等提出一种基于模拟退火优化SVM的文本分类方法[6];贾宏云等将支持向量机应用于藏文文本分类的研究中[7];王岩等提出了一种用果蝇优化算法获取SVM参数的FOA-SVM分类方法[8]。
文献分析结果显示,朴素贝叶斯分类法在执行速度快、算法简单、分类准确率高的情况下,其特点是特征项间的独立。单一的假定会使分类的结果不理想。基于KNN的分类算法分类精度高、稳定性好,适合于分类领域的交叉和重叠的样本集。然而在样本不均衡、样本容量大的情况下,样本的分类误差较大。基于SVM的文本分类算法具有参数少、速度快等优点,分类效果显著,有效地减少高维空间问题的求解,并具有很好的泛化性能。基于此,本文针对食物营养健康中文文本提出一种基于 SVM的文本分类方法。
通过对支持向量机的分析,得出了支持向量机分类时,核函数和处罚参数的好坏对分类准确率有很大的影响。因此,寻找最优核函数参数和惩罚参数是该方法应用于工程实践的重点和难点。
为优化支持向量机的参数选择,本文引进了业界最新提出的麻雀搜索算法(SSA),在此基础上,提出了一种基于麻雀搜索算法的方法来优化SVM的核参数,进一步以支持向量机模型为基础,设计了一种基于SSA-SVM的食物营养健康信息文本分类方法。通过与其他算法构建的分类器结果比较,证明了本文提出的方法是可行的。
1 相关原理
1.1 支持向量机SVM
SVM是一种常用的文本分类方法,该方法是以统计学为基础,其数学模型定义为在特征空间上的间隔最大的线性分类器[10]。支持向量机的基本思想是通过构造最佳超平面来使不同样本的隔离边界达到平面间隔的最大,从而达到分类的目的。
假设给定一个数据样本集为A={(x1,y1),(x2,y2),…,(xi,yi)},y∈{-1,1}},其中,xi表示特征向量集合,yi表示样本类别。
对于线性分类问题,SVM构造的超平面可以通过如下分类函数表示:
[wtx+b=0] ⑴
其中,w代表超平面的一个法向量;b为偏移向量。
目标函数为:
[minw22s.t.yiwTxi+b≥1, i=1,2,…,n] ⑵
通过拉格朗日对偶性变换,将文本分类的原始变量转换为对偶变量,通过求解对偶问题进而得到原始问题的最优解。对偶问题更有利于问题的求解。变换后的最优分类函数如下:
[fx=signinaiyixi,x+b] ⑶
其中,αi代表拉格朗日乘子。
对于非线性分类问题,在原始空间为有限维的前提下利用核函数总能找到一个高维特征空间,要对待分类的样本特征向量从低维空间到高维空间的矢量映射,建立了一个超平面的文本计算分类,使原本的非线性分类问题转化为线性分类问题。为了提高SVM的分类性能,在建模过程中引入松弛因子ξi,,构建软间隔分类器。因此,凸二次规划的对偶问题转化为求二次优化问题:
[minω,δ=12ω2+Ci=1nδi]
[s.t.yiωφxi+b≥1-δi] ⑷
[δ≥0, i=1,2,…,n]
其中,C为惩罚因子。
为了简化计算,通過加入拉格朗日乘子αi将式⑷转化为式⑸求解,且0≤αi≤C。
[maxi=1nαi-12i=1nαiαjyiyjxi?xj] ⑸
通过计算得到最优分类函数:
[fx=signi=1nαiyikxi,xj+b] ⑹
其中,k(xi,xj)表示核函数。
1.2 麻雀搜索算法SSA
麻雀搜索算法SSA是薛建凯在2020年提出的一种基于麻雀种群的觅食行为和反捕食行为的新型群体智能优化算法[11]。
麻雀在捕食行为中分为发现者、加入者和警戒者三类,分别负责提供觅食方向、寻找食物来源和警戒。因此,SSA的实现思路是由发现者、加入者和警戒者在每代种群的位置更新,逐渐地发现能量最大的食物位置,也就是最优解。发现者、加入者和警戒者的位置更新分别按式⑺~式⑼进行。
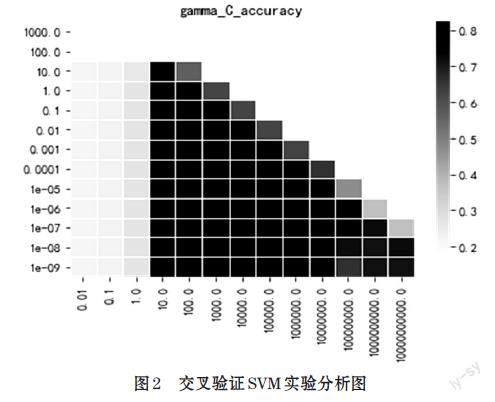
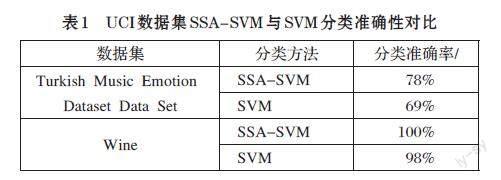
发现者的位置更新模型如公式⑺所示。
[Xt+1i,j=Xti,j?exp-iα?itermaxR2 其中,α∈(0,1],t为迭代数;itermax代表最大的迭代次数;Xi,j表示第i个麻雀在第j维中的位置信息;R2和ST分别表示预警值和安全值;Q为服从正态分布的随机数;L表示个1×d的矩阵。 加入者的位置更新模型如公式⑻所示。 [Xt+1i,j=Q?expXworst-Xti,ji2i>n/2Xt+1p+Xti,j-Xt+1p?A+?L otherwise] ⑻ 其中,Xp,Xworst分别代表目前发现者所占据的最好位置和最差的位置;A代表一个1×d的矩阵,矩阵中每个元素随机的分配为1或-1,且A+=AT(AAT)-1。当i>n/2时, i个适应度值较低的加入者没有获得食物,为了获取更多食物能量,它们必须飞到其他地方寻找食物。 警戒者位置更新模型如公式⑼所示。 [Xt+1i,j=Xtbest+βXti,j-Xtbestfi>fgXti,j+KXti,j-Xtworstfi-fw+εfi=fg] ⑼ 其中,K∈[-1,1],Xbest代表当前全局最优位置;β为步长的控制参数;fi是目前麻雀个体的适应度值;fg、fw分别代表当前全局最优和最差的适应度值。在式⑼中增加最小的常数ε,以防止分母为零。 2 SVM用于营养健康信息提取的局限性分析 由相关原理可知,支持向量机有两个主要参数C与γ。C表示惩罚因子,C值越高,则出现错误的容错率越低,易于发生过度拟合;反之,C值越低,误差容错率越高,易于发生欠拟合。C值太高或太低都会导致模型的泛化能力下降。γ是选择RBF函数选定kernel后的一个参数。随着γ的增大,支持向量减少;相反,较低的γ代表更多的支持向量。支持向量的数量对训练与预测的速度有很大的影响。同时,RBF的宽幅也会影响到支持向量对应的高斯作用范围,从而影响其泛化性能。如果γ值过大则σ会很小,则会导致仅对支持向量样本附近产生作用,而对未知样本分类效果差;若γ太低,则会导致平滑效应过强,从而降低精确度。 从以上的分析可以看出,惩罚因子C和参数γ的选择对于支持向量机的分类效果有很大影响。本文选择科普舆情监测系统中获得的营养健康信息中的中文文本作为本论文验证数据集,其中包括儿童营养、免疫功能、冠心病、心血管疾病、科学膳食、糖尿病饮食、老年营养、营养价值、营养吸收、营养安全、食品营养成分、高血压、高血脂症共13类。在此基础上,将样本数据按照一定的比例劃分为训练数据集和测试数据集,并针对RBF核中惩罚因子C和参数γ来检验支持向量机的分类效果。 当参数γ取值为1时,选取C的值为0.1和10,对SVM的分类准确率进行验证。 由图1实验结果可以看出,对于营养健康的13类文本数据集参数取值对其性能影响较大,定点取值并不能够全面概括验证。所以,本文采取交叉验证方法对SVM进行局限性分析。 图2代表采用五折交叉验证生成的SVM实验结果。通过观察可以发现,若γ的取值过大,支持向量的辐射范围就极小;相反,若γ的取值过小,其辐射范围将变得极大。对于较为适中的γ值,C取值较大或较小时具有类似良好的效果,因此,在同等工况下选择相对小的C值更有利于节省内存和时间。 从实验结果可知,在营养健康文本数据集下,惩罚因子和核函数参数的不同,SVM分类准确性相差较大。这表明,参数的取值大小会直接影响SVM模型的分类准确度,想要获得最优的SVM文本分类模型,需要找到最优的参数组合。 3 SSA寻最优解的模型构建与实现 本文提出了基于麻雀搜索算法SSA的最优解实现过程,具体示意图如图3所示。 Step1 初始化SSA中的控制参数。设置麻雀种群的规模为20,麻雀种群最大迭代次数为100,上边界与下边界区间为[0.01,100],发现者、加入者、警戒者的比例为0.7、0.3、0.2。 Step2 将计算错误率设为适应度函数,错误率越小,则结果越优。计算适应度值,并排序。 Step3 利用式⑶更新发现者位置。 Step4 利用式⑷更新加入者位置。 Step5 利用式⑸更新警戒者位置。 Step6 计算出适应度值,并对麻雀的位置进行更新。 Step7 停止条件是否满足,满足时退出,输出的最优结果是两个参数的最优解;若未满足则重复Step2~Step6。 为了检验SSA算法的优化性能,本文采用了UCI标准数据集和搜狗实验室5种文本数据集,进行模拟训练和验证,验证算法本身的可行性,再对营养健康文本数据进行分析。 两个标准数据集样本数分别为400、178。将本文提出的麻雀搜索算法优化SVM方法(SSA-SVM)与基础SVM进行对比验证,SSA分别得到两组数据的最优参数为[8.0691,0.0312]、[1.3360,1.6003]。由表1可知,SSA-SVM方法在wine数据集中准确率可达到100%,证明SSA具有良好的全局搜索能力。 选取搜狗实验室财经、健康、教育、旅游、文化共5类1500个文本数据集,分别采用SVM、SSA-SVM、K-邻近算法(K-Nearest Neighbor)、朴素贝叶斯(Naive Bayesian)四种分类算法进行实验研究。实验结果如表2,SSA-SVM准确率达到92.9%,最优参数为[69.3802,0.0100]明显高于其他几种分类方法。SSA能搜索到理想的最优参数,使本文提出的方法在文本分类中得到较为理想的分类性能。 4 基于SSA-SVM的营养健康文本信息分类与应用 本节构建了基于麻雀搜索算法优化支持向量机的方法(SSA-SVM),用于营养健康文本数据的分类,其实现过程如图4所示。 以下为基于SSA-SVM的归于营养健康文本分类具体实现步骤。 Step1 建立食物营养健康主题相关文本数据集,通过建设的科普舆情系统爬取相关文本。 Step2 在文本数据中,采用了去停用词、分词、特征选择和权重计算等方法。 Step3 选取训练集和测试集。按照8:2比例将数据划分为两部分,一部分为训练集,另一部分为测试集。 Step4 对SVM和SSA中的控制参数做初始化,包括麻雀种群规模、最大迭代次数、发现者、加入者和警戒者比例。 Step5 对训练文本数据进行分类,将分类错误率设为适应度函数值,错误率越小,则结果越优。 Step6 所有麻雀种群进行位置更新排序。 Step7 判断满足条件,满足条件则输出寻找的最优结果为最高准确率值,和两个参数的最优值,建立SSA优化的SVM食物营养文本分类算法。 本文选择科普舆情监测系统中获得的营养健康中文文本数据作为验证数据集,选取13类文本作为测试样本。为了展示SSA-SVM分类模型与其他几种常用文本分类算法的分类性能对比,我们给出表3。 从表2、表3可以看出,不同数据集对分类性能有较大的影响,同时也体现出食物营养健康相关的文本具有较强的专业性。图5更能直观的说明在食物营养健康的13类文本中,SSA-SVM分类模型在每种类别中分类效果相对平稳,仅在营养价值与营养吸收两类中准确率偏低,剩余类别的准确率均高于其他算法。相比常见的几种算法,在整体的分类中,SSA-SVM分类模型各项评估指标明显高于其他算法,经过SSA寻得最优参数[68.8512,0.0100],准确率为83.8%,比基础的SVM准确率提高近13%,SSA-SVM分类模型体现出较强的泛化能力。 5 结束语 本研究以主题爬虫搜集的中文文本数据为数据源,提出了基于SSA优化SVM参数的方法,通过构建分类模型,用于筛选出食物营养健康领域的科普文本信息,并与文本分类中常用的机器学习模型如朴素贝叶斯、K-邻近算法等进行对比分析。 实验结果表明,SSA具有稳定的全局寻优性能,能有效解决SVM寻找最优参数问题。与其他分类方法相比,SSA-SVM模型具有分类准确率高、泛化能力强等优点,表现出更好的分类效果。 参考文献(References): [1] Vinod Kumar Chauhan,Kalpana Dahiya,Anuj Sharma. Problem formulations and solvers in linear SVM: a review[J]. Artificial Intelligence Review,2019,52(2) [2] 邱宁佳,贺金彪,薛丽娇,等.融合语义特征的加权朴素贝叶斯 分类算法[J].计算机工程与设计,2020,41(9):2523-2529 [3] 黄超,陈军华.基于改进K最近邻算法的中文文本分类[J].上 海师范大学学报(自然科学版),2019,48(1):96-101 [4] 段友祥,张晓天.基于主动学习的SVM评论内容分类算法的 研究[J].计算机与数字工程,2022,50(3):608-612 [5] 葛晓伟,李凯霞,程铭.基于CNN-SVM的护理不良事件文本 分类研究[J].计算机工程与科学,2020,42(1):161-166 [6] 郭超磊,陈军华.基于SA-SVM的中文文本分类研究[J]. 计算机应用与软件,2019,36(3):277-281 [7] 贾宏云,群诺,苏慧婧,等.基于SVM藏文文本分类的研究与 实现[J].电子技術与软件工程,2018(9):144-146 [8] 王岩,张波,薛博.基于FOA-SVM的中文文本分类方法研究[J]. 四川大学学报(自然科学版),2016,53(4):759-763 [9] 王杨,许闪闪,李昌,等.基于支持向量机的中文极短文本分类 模型[J].计算机应用研究,2020,37(2):347-350 [10] 于敏.基于机器学习的文本分类方法研究[D].硕士,江南 大学,2021 [11] 薛建凯.一种新型的群智能优化技术的研究与应用[D]. 硕士,东华大学,2020
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国水运(2016年11期)2017-01-04
电子技术与软件工程(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
