
基于细节还原卷积神经网络的压缩视频质量增强技术研究
2023-07-06 04:35李子晗邵笑张佩云
南京信息工程大学学报 2023年3期
关键词:深度学习
李子晗 邵笑 张佩云


摘要 视频编码技术有效地解决了原始视频数据量过大的问题,但压缩效率的提升会使视频质量下降.为了提高压缩视频的视觉质量,本文提出了一种基于细节还原卷积神经网络(Detail Recovery Convolutional Neural Network,DRCNN)的视频质量增强方法,该方法由一个主去噪分支和一个细节补偿分支组成.为了有效地提取和消除压缩失真,在主去噪分支中提出了一个多尺度失真特征提取块(Multi-scale Distortion Feature Extraction Block,MDFEB),使其更加关注压缩视频中的失真区域,并提高DRCNN的失真特征学习能力.此外,为了丰富压缩视频中的细节,本文提出了细节补偿分支:首先采用预训练的50层残差网络组成的内容特征提取器,提供丰富的内容特征,如突出的物体、形状、细节等;然后通过设计的细节响应块(Detail Response Block,DRB)从内容特征中有效地提取细节特征.大量的实验结果表明,与4种有代表性的方法相比,本文所提出的DRCNN实现了最佳的压缩视频质量增强性能.关键词 视频质量增强;深度学习;视频后处理;多尺度特征提取
中图分类号TP391.4
文献标志码A
0 引言
视频编码技术[1]有效地压缩了视频数据.然而,当视频以低比特率编码时,压缩后的视频会出现许多失真,如基于块结构编码引起的块伪影和变换编码引起的振铃伪影.这些压缩失真可能会严重影响压缩视频的体验质量(Quality of Experience,QoE).因此,为了有效地提高压缩视频的质量,特别是在低比特率下编码的视频,研究一种先进的视频质量增强方法是非常重要的.在过去的几十年里,许多传统的质量增强方法[2-8]被提出来消除压缩视频的失真,这些方法可以分为环路滤波和后处理.环路滤波类方法[2-5]用于编码中增强重建帧的质量,但是受限于编解码端的复杂度,环路滤波的增强性能并不令人满意.因此,后处理质量增强方法[6-8]被用在编码后,来进一步增强压缩视频的质量.然而,这些传统方法识别和消除失真的能力是不够的,许多压缩伪影仍然保留在压缩视频中.最近,深度学习方法[9-19]在压缩视频增强领域取得了巨大成功.Dai等[9]考虑到视频编码中的可变编码块大小不一,在已有深度学习方法的基础上,使用两种不同大小的滤波器组合并提出了一种基于可变滤波器的残差学习卷积神经网络(Variable-filter-size Residue-learning Convolutional Neural Network,VRCNN)的环路滤波方法.Yang等[10]提出一種用于压缩视频增强的多帧质量增强方法,通过将高质量帧和目标帧融合后送入网络中,低质量帧可以被邻近的高质量帧增强.接着Guan等[11]更新了多帧方法中的高质量帧搜寻器,并增加网络的深度,实现了更好的增强性能增益.Zhang等[12]提出一种用于高效视频编码的环路滤波的残差公路卷积神经网络(Residual Highway Convolutional Neural Network,RHCNN),文中提出的公路单元可以使原始信息传送到网络深层中,大大改善了RHCNN的性能.Yang等[13]提出一种质量增强卷积神经网络(Quality Enhancement Convolutional Neural Network,QECNN),它使用两个独立的网络分别学习帧内和帧间的失真特征.Zhang等[14]基于残差学习提出一个全新的网络结构作为新一代视频编码的后处理方法.Zheng等[15]采用一种新的收敛机制,自适应地融合不同网络的增强结果,同时保留了平坦 区域和丰富的纹理.Ding等[16]设计了一种基于块的时间空间质量增强方法,并采用时空注意融合模块来融合不同特征,取得了很好的多帧质量增强效果.Meng等[17]提出一种多帧引导注意力网络,通过融合运动信息、时间信息和块划分图,在高比特率下和运动场景下取得了很好的效果.考虑到屏幕内容视频中存在大量的颜色相似区域,Huang等[18]提出基于跨帧信息融合的多帧信息交叉融合屏幕内容质量增强网络.Luo等[19]提出一种渐进式的多帧质量增强方法,由粗到细融合了视频的时间空间信息.现有方法可以很好地去除压缩损失,但是当压缩视频以高码率编码时,视频中的压缩伪影将会减少,细节增多,均不能很好地区分损失和细节,往往会忽略压缩视频的细节,将细节特征当成失真特征一同去除.为了解决这个问题并在去除视频损失的同时丰富视频的细节信息,受到视频增强[9-19]及其他领域[20-25]提出的新颖的深度学习模型启发,本文提出一种细节还原卷积神经网络(Detail Recovery Convolutional Neural Network,DRCNN),此网络主要由两个分支组成:主去噪分支和细节补偿分支.本文主要工作如下:
1)当压缩视频处于低码率时,视频中呈现的损失主要为全局损失,而大的感受野通常可以很好地捕捉全局损失.因此本文提出一个基于多尺度的大感受野的分支:主去噪分支.在此分支中,由于压缩视频中损失特征的尺寸通常不统一,因此本文还采用新颖的多尺度失真特征提取块(Multi-scale Distortion Feature Extraction Block,MDFEB)提高了整体网络对于不同种类失真特征的提取能力.2)因为主去噪分支更加关注全局损失,在去除局部损失的同时会去除掉同属于高频特征的细节信息,所以本文提出了基于预训练的50层残差网络(Residual Network-50,ResNet-50)[26]的细节补偿分支,将压缩视频中的细节特征提取出来补偿回增强视频中,还原出丢失的细节信息.在此分支中,由于ResNet-50中的特征丰富且繁杂,本文提出了一个基于压缩激活机制的细节响应块(Detail Response Block,DRB)将丰富的特征中的细节特征标注并提取出来,增强分支的细节提取能力.
1 基于细节还原卷积神经网络的压缩视频增强方法 为了有效地消除压缩失真,提高压缩视频的细节视觉质量,本文提出了一种基于DRCNN的压缩视频质量增强方法,DRCNN的结构如图1所示,由两个分支组成:主去噪分支和细节补偿分支.由于大量的损失出现在全局尺度,因此本文提出一个感受野逐渐扩大的主去噪分支.在此分支中提出一个多尺度失真特征提取块以提取出压缩视频的多尺度失真特征,然后将压缩视频和获得的失真特征融合提取,最终重建一个高质量的去噪视频.接着,为了恢复主去噪分支中丢失的细节特征,本文还提出一个细节补偿分支,以进一步改善压缩视频的细节.在此分支中,通过使用预训练的ResNet-50设计了一个内容特征提取器,并采用多个细节响应块来关注压缩视频的细节,从预训练的ResNet-50的内容特征中提取细节特征.
DRCNN的输入是低质量的压缩视频,而输出是增强的高质量压缩视频.为了有效提高压缩视频的质量,压缩视频被送入主去噪分支和细节补偿分支,分别获得去噪视频和细节图.在细节图的帮助下,去噪的视频被进一步增强.这个过程可以表示为
1.1 主去噪分支现有基于卷积神经网络的方法都采用寻找压缩视频特征到增强视频特征的最佳映射来增强视频,这些方法在增强过程中忽略了视频中的失真特征,使得网络的训练更加困难.为了更好地学习失真特征,本文提出了主去噪分支,它采用了残差学习机制来加速训练过程,将现有方法的学习图像干净像素特征转化为学习更加简单更容易提取的损失特征,把特征提取过程和重构过程当作两个单独的进程,以更准确地重建噪声图.在特征提取过程中,由于损失的尺度不统一,为了增强多尺度特征提取能力,主去噪分支采用MDFEB来提高对失真区域内不同尺度的失真的提取能力.在重建过程中,主去噪分支利用从前几层学到的损失特征来预测噪声图.为了进一步提高网络的失真学习能力,本文使用长连接引入压缩视频来指导重建过程.图2展示了所提出的主去噪分支的整体结构.在特征提取阶段中,主去噪分支首先采用3×3卷积层将压缩帧转换为特征,然后将这些特征输入13个MDFEB进行失真特征提取.最后,一个带有逐元素相加操作的跳连接被用来让网络学习和处理残差信息.
1.2 细节补偿分支主去噪分支可以有效地去除压缩视频的失真,然而,由于失真和细节均为高频信息,压缩视频的细节信息也很容易被主去噪分支去除.为了恢复丢失的细节信息,本文提出一个细节补偿分支,以进一步提高压缩视频的质量.所提出的细节补偿分支利用U型网络[29]作为骨干网络,这种编码-解码结构能够更好地恢复压缩视频中退化的细节信息.图4展示了提出的细节补偿分支的结构,它包括一个使用预训练ResNet-50的内容特征提取器、三个提出的细节响应块、三个2倍pixel-shuffle层、一个4倍pixel-shuffle层以及两个卷积层.首先预训练的ResNet-50作为内容特征提取器提供了从大规模数据集中学习到的丰富特征,接着本文采用三个细节响应块来进一步提取不同感受野的细节特征.细节补偿分支使用pixel-shuffle层对小尺寸的特征图进行上采样并且不引入冗余信息.最后3×3卷积层被用来来重建细节图.所提出的细节补偿分支可以被总结为
2 实验结果与分析
2.1 实验设置1)数据集:本文采用表1所示的37个不同分辨率的视频序列制作数据集,其中21个视频序列用来建立训练集,其余16个视频序列用来建立测试集.训练集由4 200张图像组成,测试集由16个序列的所有帧组成.每个视频序列由高效视频编码测试软件16.0(High Efficiency Video Coding Test Model 16.0,HM16.0)在四个不同的量化参数(Quantification Parameters,QP)下进行编码.2)训练设置:图像像素块大小设置为64×64,跨度为32,批尺寸设置为16.采用亚当(Adam)优化器[31]来优化模型,学习率设置为0.001,训练过程将在200次迭代后停止.3)评价指标:为了评价不同方法的客观性能,峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)被用来衡量每种方法的客观质量,其单位为分贝(dB).Bjntegaard失真率(Bjntegaard-Delta-rate,BD-rate)[32]被用来评价每种方法的失真率性能.
2.2 客观增强性能的对比表2列出了全帧内(ALL Intra,AI)、低延迟(Low Delay,LD)和随机访问(Random Access,RA)编码结构的ΔPSNR结果.可以看到,当使用AI编码结构时,VRCNN[9]的PSNR增长范围为-0.657 dB到0.282 dB,平均为-0.079 dB.RHCNN[12]的PSNR增长范围为-0.075 dB到0.292 dB,平均0.143 dB.QECNN[13]的PSNR增长范围为-0.237 dB到0.300 dB,平均0.036 dB.Zhang等[14]的PSNR增长范围为-0.126 dB到0.326 dB,平均0.113 dB.本文提出的方法的ΔPSNR为0.147 dB到0.514 dB,平均0.266 dB.当使用LD编码结构时,VRCNN[9]的结果仍是负增益.RHCNN[12]的的PSNR增长范围为0.077 dB到0.335 dB,平均0.172 dB.对于QECNN[13]的PSNR增长范围为-0.097 dB到0.225 dB,平均0.092 dB.對于Zhang等[14]的方法,PSNR增长范围为0.092 dB到0.301 dB,平均0.173 dB.本文提出的方法的PSNR增长范围为0.163 dB到0.409 dB,平均0.275 dB,比表现最好的方法高出了0.102 dB.
当使用RA编码结构时,VRCNN[9]的PSNR增长范围为-0.690 dB到0.062 dB,平均为-0.086 dB.RHCNN[12]的PSNR增长范围为0.077 dB到0.376 dB,平均为0.184 dB.QECNN[13]的PSNR增长范围为-0.098 dB到0.306 dB,平均为0.010 dB.Zhang等[14]的方法PSNR增长范围为0.112 dB到0.400 dB,平均为0.195 dB.本文提出的方法的ΔPSNR从0.193 dB到0.534 dB,平均为0.290 dB.从这些结果中分析可知,当视频在不同编码结构下进行编码时,由于QP低时码率高,视频中的细节信息比较丰富,对比方法由于缺乏细节信息和损失信息的辨别能力,在增强过程中易将细节和损失共同去除,因此表现不佳.本文方法由于ResNet-50组成的内容特征提取器的存在,大量的包含细节信息的内容特征被提取出来,这些信息提高了本方法增强后视频的客观质量.
2.3 失真率性能的對比为了比较所提出的方法和有代表性方法之间的失真率性能,表3中列出了每种方法的BD-rate.可以看出,VRCNN[9]的BD-rate节省范围为8.313%到-4.630%,平均1.046%.RHCNN[12]的BD-rate节省范围为1.836%到-7.932%,平均-2.957%.QECNN[13]的BD-rate节省范围为0.820%至-6.250%,平均为-2.249%.Zhang等[14]的的BD-rate节省范围为0.922%至-7.340%,平均为-2.985%.与这些压缩视频质量增强方法相比,本文的方法的BD-rate节省范围为-1.869%到-9.529%,平均-4.964%.由表3可以发现,几种对比方法均有BD-rate负增益的情况,因此对比方法在不同视频序列上的增强效果是有波动的,在细节丰富的视频中,这些方法增强性能大大受限.受益于细节补偿分支提取细节信息的能力,本文提出的DRCNN在每个序列上都获得了稳定的增强效果.
2.4 视觉质量对比为了比较所提出的DRCNN和最先进的视频质量增强方法之间的视觉质量增强性能,如图7所示,本文从五个视频序列中取出最具代表性的帧做视觉质量对比,包括“PeopleOnStreet”、“Cactus”、“BQMall”、“FourPeople”和“BQTerrace”五个视频序列.对于“PeopleOnStreet”和“Cactus”视频序列,可以看到由于严重的压缩失真,砖块和数字的边缘变得十分不清晰,现有的方法如VRCNN[9]、RHCNN[12]、QECNN[13]和Zhang等[14]都难以改善质量下降的帧的视觉质量.相比之下,本文提出的DRCNN在使用所提出的细节补偿分支后可以更好地改善细节区域的质量.对于 “BQMall”和“FourPeople”序列,许多伪影和模糊出现在视觉质量下降的帧中.与其他增强方法相比,本文提出的DRCNN具有更强的伪影去除能力,并取得了更满意的结果.此外,压缩过程会将色调偏离引入压缩后视频帧中,如“BQTerrace”中的放大区域,由于其学习能力有限,传统的基于卷积神经网络的方法很难将其去除.与这些方法相比, DRCNN能有效地去除色调偏离,并显著改善质量下降的帧的视觉质量.
2.5 计算复杂度的对比为了比较各方法的计算复杂性,表4列出了一帧的显卡测试时间,表5给出了显卡内存消耗的结果.从表4可以看出,VRCNN[9]、RHCNN[12]、QECNN[13]、Zhang等[14]和DRCNN的平均显卡测试时间分别为0.19、0.27、0.15、1.10和1.18 s.由于VRCNN[9]、RHCNN[12]和QECNN[13]的网络层数较浅,这三种方法的显卡测试时间少于其他两种方法,但是,它们取得的质量提升性能比Zhang等[14]和DRCNN差很多.为了有效提取失真特征并提高降噪能力,Zhang等[14]和DRCNN被设计为深度神经网络.与Zhang等[14]相比,本文方法实现了更好的增强性能,并保持了相当的显卡测试时间.从表5可以发现,VRCNN[9]、RHCNN[12]、QECNN[13]、Zhang等[14]和DRCNN方法的显卡内存消耗分别为2.1、2.5、1.3、3.2和4.1 GB.总的来说,相比于对比方法,本文方法的复杂度高出一点,处理一帧的平均测试时间比对比方法中最高的Zhang等[14]多了0.08 s,显卡内存大小也多了0.9 GB.但是考虑到本文在PSNR和BD-rate上比Zhang等[14]提升了0.117 dB和1.979%,复杂度微微上升是可以接受的.
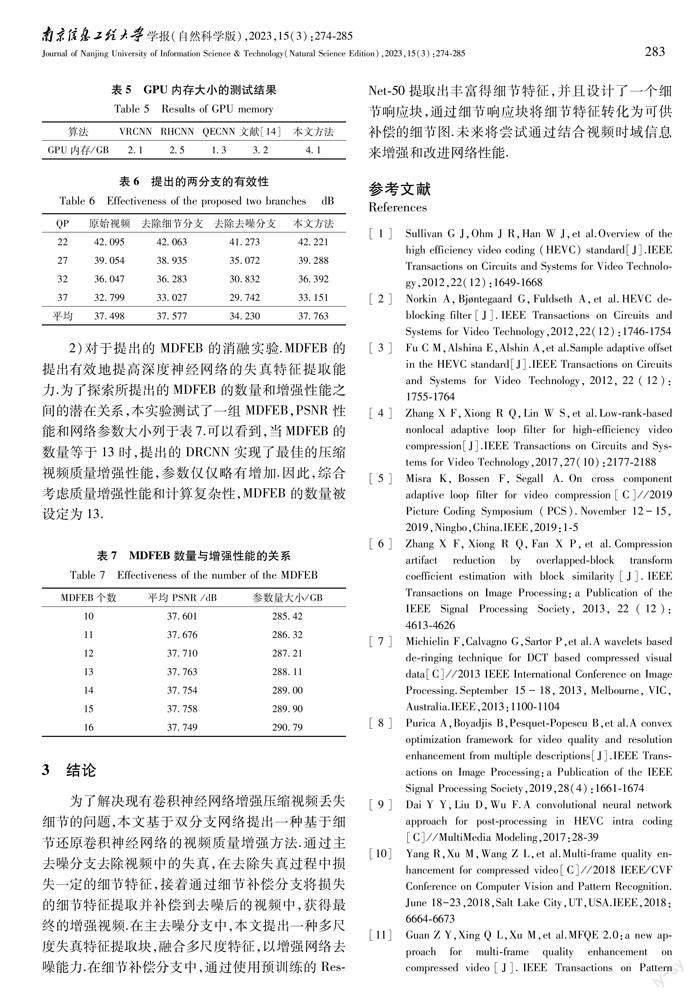
2.6 消融实验1)对于提出的两分支的消融实验.DRCNN采用一个主去噪分支和一个细节补偿分支来有效地消除失真,提高压缩视频的质量.为了验证这两个分支的有效性,本文将它们从 DRCNN中分别删除,在测试集上进行消融研究.实验结果列于表6,其中“去除去噪分支”表示从DRCNN中删除了主去噪分支,而“去除细节分支”表示从提出网络中删除了细节补偿分支.可以看出,当主去噪分支被移除时,所提出的DRCNN的质量增强能力大大降低,平均PSNR下降了3.533 dB.这一结果证明,主去噪分支可以有效地消除压缩视频中的失真,提高DRCNN的增强性能.此外,可以看出,当去除细节补偿分支时,PSNR平均下降了0.186 dB.从这些结果中可以发现,所提出的主去噪分支和细节补偿分支大大提高了DRCNN的压缩视频增强能力.
2)对于提出的MDFEB的消融实验.MDFEB的提出有效地提高深度神经网络的失真特征提取能力.为了探索所提出的MDFEB的数量和增强性能之间的潜在关系,本实验测试了一组MDFEB,PSNR性能和网络参数大小列于表7.可以看到,当MDFEB的数量等于13时,提出的DRCNN实现了最佳的压缩视频质量增强性能,参数仅仅略有增加.因此,综合考虑质量增强性能和计算复杂性,MDFEB的数量被设定为13.
3 结论为了解决现有卷积神经网络增强压缩视频丢失细节的问题,本文基于双分支网络提出一种基于细节还原卷积神经网络的视频质量增强方法.通过主去噪分支去除视频中的失真,在去除失真过程中损失一定的细节特征,接着通过细节补偿分支将损失的细节特征提取并补偿到去噪后的视频中,获得最终的增强视频.在主去噪分支中,本文提出一种多尺度失真特征提取块,融合多尺度特征,以增强网络去噪能力.在细节补偿分支中,通过使用预训练的ResNet-50提取出丰富得细节特征,并且设计了一个细节响应块,通过细节响应块将细节特征转化为可供补偿的细节图.未来将尝试通过结合视频时域信息来增强和改进网络性能.
参考文献 References
[1]Sullivan G J,Ohm J R,Han W J,et al.Overview of the high efficiency video coding (HEVC) standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1649-1668
[2] Norkin A,Bjntegaard G,Fuldseth A,et al.HEVC deblocking filter[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1746-1754
[3] Fu C M,Alshina E,Alshin A,et al.Sample adaptive offset in the HEVC standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1755-1764
[4] Zhang X F,Xiong R Q,Lin W S,et al.Low-rank-based nonlocal adaptive loop filter for high-efficiency video compression[J].IEEE Transactions on Circuits and Systems for Video Technology,2017,27(10):2177-2188
[5] Misra K,Bossen F,Segall A.On cross component adaptive loop filter for video compression[C]//2019 Picture Coding Symposium (PCS).November 12-15,2019,Ningbo,China.IEEE,2019:1-5
[6] Zhang X F,Xiong R Q,Fan X P,et al.Compression artifact reduction by overlapped-block transform coefficient estimation with block similarity[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2013,22(12):4613-4626
[7] Michielin F,Calvagno G,Sartor P,et al.A wavelets based de-ringing technique for DCT based compressed visual data[C]//2013 IEEE International Conference on Image Processing.September 15-18,2013,Melbourne,VIC,Australia.IEEE,2013:1100-1104
[8] Purica A,Boyadjis B,Pesquet-Popescu B,et al.A convex optimization framework for video quality and resolution enhancement from multiple descriptions[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2019,28(4):1661-1674
[9] Dai Y Y,Liu D,Wu F.A convolutional neural network approach for post-processing in HEVC intra coding[C]//MultiMedia Modeling,2017:28-39
[10] Yang R,Xu M,Wang Z L,et al.Multi-frame quality enhancement for compressed video[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:6664-6673
[11] Guan Z Y,Xing Q L,Xu M,et al.MFQE 2.0:a new approach for multi-frame quality enhancement on compressed video[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021,43(3):949-963
[12] Zhang Y B,Shen T,Ji X Y,et al.Residual highway convolutional neural networks for in-loop filtering in HEVC[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2018,27(8):3827-3841
[13] Yang R,Xu M,Liu T,et al.Enhancing quality for HEVC compressed videos[J].IEEE Transactions on Circuits and Systems for Video Technology,2019,29(7):2039-2054
[14] Zhang F,Feng C,Bull D R.Enhancing VVC through CNN-based post-processing[C]//2020 IEEE International Conference on Multimedia and Expo.July 6-10,2020,London,UK.IEEE,2020:1-6
[15] Zheng H,Li X,Liu F L,et al.Adaptive spatial-temporal fusion of multi-objective networks for compressed video perceptual enhancement[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).June 19-25,2021,Nashville,TN,USA.IEEE,2021:268-275
[16] Ding Q,Shen L Q,Yu L W,et al.Patch-wise spatial-temporal quality enhancement for HEVC compressed video[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2021,30:6459-6472
[17] Meng X D,Deng X,Zhu S Y,et al.A robust quality enhancement method based on joint spatial-temporal priors for video coding[J].IEEE Transactions on Circuits and Systems for Video Technology,2021,31(6):2401-2414
[18] Huang J W,Cui J Z,Ye M,et al.Quality enhancement of compressed screen content video by cross-frame information fusion[J].Neurocomputing,2022.DOI:10.1016/j.neucom.2021.12.092
[19] Luo D Y,Ye M,Li S,et al.Coarse-to-fine spatio-temporal information fusion for compressed video quality enhancement[J].IEEE Signal Processing Letters,2022,29:543-547
[20] 李春平,周登文,贾慧秒.基于边缘指导的双通道卷积神经网络单图像超分辨率算法[J].南京信息工程大学学报(自然科学版),2017,9(6):669-674
LI Chunping,ZHOU Dengwen,JIA Huimiao.Edge guided dual-channel convolutional neural network for single image super resolution algorithm[J].Journal of Nanjing University of Information Science & Technology (Natural Science Edition),2017,9(6):669-674
[21] 陳西江,安庆,班亚.优化EfficientDet深度学习的车辆检测[J].南京信息工程大学学报(自然科学版),2021,13(6):653-660
CHEN Xijiang,AN Qing,BAN Ya.Optimized EfficientDet deep learning model for vehicle detection[J].Journal of Nanjing University of Information Science & Technology (Natural Science Edition),2021,13(6):653-660
[22] 郭新,罗程方,邓爱文.基于深度学习的开放场景下声纹识别系统的设计与实现[J].南京信息工程大学学报(自然科学版),2021,13(5):526-532
GUO Xin,LUO Chengfang,DENG Aiwen.A deep learning-based speaker recognition system for open set scenarios[J].Journal of Nanjing University of Information Science & Technology (Natural Science Edition),2021,13(5):526-532
[23] Li J T,Wu X M,Hu Z X.Deep learning for simultaneous seismic image super-resolution and denoising[J].IEEE Transactions on Geoscience and Remote Sensing,2022,60:1-11
[24] Liu Z S,Siu W C,Chan Y L.Features guided face super-resolution via hybrid model of deep learning and random forests[J].IEEE Transactions on Image Processing,2021,30:4157-4170
[25] Qian J,Huang S Y,Wang L,et al.Super-resolution ISAR imaging for maneuvering target based on deep-learning-assisted time frequency analysis[J].IEEE Transactions on Geoscience and Remote Sensing,2022,60:1-14
[26] He K M,Zhang X Y,Ren S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:770-778
[27] Ding X H,Guo Y C,Ding G G,et al.ACNet:strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).October 27-November 2,2019,Seoul,Korea (South).IEEE,2019:1911-1920
[28] Shi W Z,Caballero J,Huszár F,et al.Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:1874-1883
[29] Ronneberger O,Fischer P,Brox T.U-net:convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention,2015:234-241
[30] Hu J,Shen L,Sun G.Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:7132-7141
[31] Kingma D P,Ba J.Adam:a method for stochastic optimization[J].arXiv e-print,2014,arXiv:1412.6980
[32] Bjntegaard G.Calculation of average PSNR differences between RD-curves[J].VCEG-M33,2001:1-4
Quality enhancement for compressed video via detail recovery convolutional neural network
LI Zihan SHAO Xiao ZHANG Peiyun
1School of Computer Science,Nanjing University of Information Science & Technology,Nanjing 210044
Abstract Video coding has effectively addressed the too large data volume of raw videos,however,the achieved compression efficiency comes at the cost of video quality degradation.To improve the visual quality of compressed video,a Detail Recovery Convolutional Neural Network (DRCNN)-based video quality enhancement method is proposed,which consists of a main denoising branch and a detail compensation branch.To effectively extract and eliminate the compression distortions,a Multi-scale Distortion Feature Extraction Block (MDFEB) is added to the main denoising branch,which can pay attention to the distorted areas in the compressed video,and improve the distortion feature learning ability of the proposed DRCNN.Furthermore,to enrich the details in the compressed video,the detail compensation branch adopts a content feature extractor composed of a pre-trained ResNet-50 to provide abundant content features,such as salient objects,shapes,and details,and then involves a Detail Response Block (DRB) to efficiently extract the detailed features from the content features.Extensive experimental results show that the proposed DRCNN achieves the best performance in enhancing the compressed video quality as compared with four representative methods.
Key words video quality enhancement;deep learning;video post-processing;multi-scale feature extraction
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
