
一种基于全局和局部特征表示的关键词抽取算法
2023-08-20 05:30祖弦,谢飞,2**
云南大学学报(自然科学版) 2023年4期
祖 弦,谢 飞,2**
(1.合肥师范学院 计算机学院,安徽 合肥 230601;2.合肥师范学院 安徽省电子系统仿真重点实验室,安徽 合肥 230601)
关键词是最能代表文档主题的重要性词语,关键词抽取技术可以帮助人们从大量数据中迅速找出有用信息,实现对海量资源的高效智能化检索,尤其针对一些未提供关键词的文本或网络新闻,可以使读者迅速了解文章的核心含义.目前关键词抽取技术在诸多场景有着重要应用,如推荐系统、用户的兴趣挖掘、文档的自动分类[1]、信息检索[2]、社区问答系统[3]等.因此,关键词抽取算法研究在自然语言处理领域具有非常重要的研究和应用价值.
现有的关键词抽取算法分为有监督方法和无监督方法.有监督方法需要大量带有人工标注关键词的训练文档,并融入词性、词频和首次出现位置等重要特征信息训练分类器,这类方法的缺点是训练及抽取关键词的过程需要耗费大量的人力和时间,同时对语料库进行人工标注的主观性和准确性均直接影响抽取效果.无监督方法主要通过结合多项文本特征信息对每个候选词语进行打分排名,其中最著名的无监督方法是基于图的方法,它根据窗口内单词之间的共现度构建图,通过PageRank 算法对候选单词进行排名[4].基于图的方法有两个主要缺陷:①在对文档构建图模型时,图更着重于表达两个词语间的共现程度,体现的上下文信息量非常有限,也无法描述同一单词在不同句子中的不同含义;②抽取过程忽略了文本的顺序性,这不利于表现单词间的联系.
近年来,深度学习模型被用于关键词抽取任务,以获取文档中单词的上下文语义信息,在从短文本中提取关键词时取得了良好的效果.这类方法通常与传统方法相结合,采用深度神经网络架构学习单词的Embedding 嵌入信息,将嵌入结果与图模型结合完成抽取任务[5].虽然赋予了传统的图模型语义方面的特征信息,但却忽略了文本的顺序信息.另外,有学者将关键词抽取看成是序列标注任务,虽然可以有效获取单词的上下文信息,但丢失了重要的统计特征,如词性、词频等.
因此,为解决上述问题,本文在关键词抽取过程中综合考虑文本的全局语义特征信息和窗口内单词的局部特征信息,提出一种基于全局和局部特征表示的关键词抽取方法.新方法主要利用Transformer[6]和多层卷积神经网络[7]构建深度神经网络学习架构.首先,为了解决传统有监督模型和图算法中易忽略单词上下文语义关系及单词间顺序性的问题,利用Transformer 充分获取单词的语义向量表示.其次,为了解决现有基于深度学习方法易丢失单词各类统计特征信息的问题,新算法计算出每个单词的词性和词频两个统计特征的向量表示,并融合在上述阶段获得的语义向量和统计特征向量,作为下一步多层卷积网络的训练输入;另外在多层卷积网络模型的选择上,采用普通卷积加空洞卷积相结合的方式,这样使神经网络模型更容易学习和捕获窗口内单词更多的局部特征信息和单词间依赖关系.最后,在抽取关键词阶段,将关键词抽取工作看成是序列标注任务来抽取最终关键词.
本文主要贡献有以下3 点:
(1)提出了一种新的关键词抽取算法,利用Transformer 和多层卷积神经网络搭建深度学习模型,可以有效捕获文本上下文语义信息和单词局部特征表示信息,不仅解决了在传统关键词抽取算法中忽略词语间语义联系的问题,还能利用单词重要的统计特征信息来提高抽取效率.
(2)在模型训练过程中,研究如何让抽取模型学习获得更全面的单词局部特征信息,提出利用多层空洞卷积网络扩大窗口内单词的特征表示.另外还解决了如何统一各类特征信息分布于不同向量表示空间的问题.
(3)通过多项消融和调参实验,证明了该方法的有效性和可靠性;并在两个公开语料库上进行了对比实验,证明了本算法效率优于现有的主流关键词抽取算法.
1 相关工作
1.1 传统的关键词抽取方法传统的关键词抽取方法包括两大类:有监督方式和无监督方法[8].有监督方法将关键词提取任务看作是一项二元分类问题(关键词或者非关键词),该类方法融合词语的各类特征信息,使用预先标记的样本数据训练一个最优分类模型,用于判断候选短语是否为关键词.有监督方法在训练过程中需要设计一个分类器,如朴素贝叶斯分类器[9]、决策树分类器[10]、逻辑回归分类器[11]等.另外,从实验效果来看,有监督方法的提取效果通常优于无监督方法.
无监督方法由于不需要人工标注的预训练数据,因此更容易实现.此类方法的抽取过程首先根据词性组成规则从文档中选取候选词语,接着由不同的提取算法对候选词进行打分,最后根据提名选取得分较高的候选词作为关键词.各类无监督方法的区别在于其对候选词打分规则的不同,通常将无监督方法分为基于统计、基于图和基于主题的方法.
最早对无监督关键词抽取方法的研究是基于统计的方法,主要关注对文档中单词的统计信息(如词频、词性、位置等)进行处理,抽取过程中需要对不同的特征值进行量化衡量.如KP-miner 算法[12]在对候选词计算词频和逆向文档频率值的时候,对候选词的挑选规则进行了限制,并加入位置特征信息提高抽取效率.另外还有些学者不再局限于仅仅统计词语的特征信息,在抽取算法中加入文档级别的特征信息[13].
随着TextRank[4]的出现,学者们开始研究基于图模型的关键词抽取算法[14-15].TextRank 对一篇文档建立图模型,图中顶点代表单词,边代表词的共现关系,再根据Google 的PageRank 算法评估各个节点的重要性.后续研究对基于图模型的算法改进主要体现在3 个方面:①对构图规则的改变,比如节点代表的不再是单个单词,可以替换成词组,或是根据某些规则筛选后的单词;②对边的权重赋值的改变,边代表的是两个顶点之间的关联度,比如将单词间的语义相似度作为权重值;③对PageRank 算法的计算规则的改变,如改变每个节点初始权重的赋值.例如Bellaachia 等针对推特文章的非正式及噪音多等特点提出NE-Rank 算法[16],认为在计算图中结点排序权重时应该同时考虑本结点权重和边的权重.Florescu 等[17]提出的PositionRank 算法根据位置信息改变PageRank中节点的初始值,使出现位置靠前且出现次数多的词语,成为关键词的概率更大.Biswas 等[18]在计算图中节点重要性时,通过融合位置、邻居结点、与中间结点距离等多方面因素提高关键词抽取效果.
另外,很多学者尝试在图中融入主题信息提高关键词抽取效率[19-20],例如Liu 等[21]提出Topical PageRank 方法在算法中融入LDA 主题模型,图模型首先在不同主题下给边赋予不同的权重值,再利用PageRank 算法计算每个主题下单词的分值,最后结合主题分布信息计算单词得分.Sterckx 等[22]在计算单词重要性分值时考虑了该单词与主题的概率向量和文档本身同主题的概率向量的相似性问题.Bougouin 等[23]提出TopicRank 算法将候选词分成不同的主题簇,在构造词图模型时,顶点是代表不同主题的主题簇.
1.2 基于深度学习的关键词抽取方法目前深度学习方法广泛应用于图像和语音处理等领域,在自然语言处理领域也成为一大研究热点.随着Embedding 嵌入技术[24-26]的出现,文本的不同组成部分如段落、句子、单词和短语均可被映射成低维空间的不同语义相关向量[27-28].EmbedRank[29]同时计算文档与候选词在同一个向量空间中的语义相似度,并选取相似度较高的候选词作为关键词.还有一部分学者研究如何将Embedding 技术融入传统图模型[30-31]中改进关键词抽取效果,例如,GKE 算法[32]将单词与文档的语义相似度作为图模型中每个单词的初始权重,用随机游走算法计算每个候选单词的得分并进行排名.
另外,学者们也开始研究如何利用深度学习模型完成关键词抽取任务,如BERT(Bidirectional Encoder Representation from Transformers)[33]、LSTM(Long Short-Term Memory)、RNN(Recurrent Neural Network)等.例如,针对Tweets 文章的长度限制问题,Zhang 等[34]通过搭建一个基于多层RNN 架构的深度学习框架捕获更多的文本上下文语义信息,从而解决从单个较短文本中提取关键词的局限性问题.在此基础上,部分学者还将关键词抽取问题看成是一个序列标注任务[35-36].Alzaidy 等[37]提出Bi-LSTM-CRF 模型,利用模型中的Bi-LSTM 组件获取上下文语义信息,CRF 组件获取句子级的标签信息.为了解决有监督方法需要大量人工标注语料库的问题,Zhu 等[38]在神经网络模型中引入了自训练方法,从而可以利用更多未标注的文章.
二维或者三维卷积神经网络(Convolutional Neural Networks,CNN)具备较强的局部特征提取能力,目前已广泛应用于图像处理领域,而一维卷积神经网络更偏向于处理时序数据的特征提取和预测,由于文本数据的顺序性,陆续有学者开始研究将一维卷积用于文本处理领域[39-40],可将文本数据看成是类似一维的时间序列或一维图像,通过在CNN 的卷积层中设置不同卷积核大小提取不同的特征信息,因此采用一维CNN 模型更容易捕获相邻单词间的特征关联信息.
综上研究不难发现,传统的有监督算法预先需要大量人工标注语料库,费时耗力;在无监督方法中,基于统计的算法缺乏单词语义信息,仅依赖文本统计特征进行抽取工作;基于图和主题的方法忽略了单词间的上下文语义关系和重要的统计特征信息,以及自然语言文本的顺序特征,从而导致关键词抽取效果不理想;现有流行的基于深度学习的方法更看重文本语义特征,忽略文本浅层的统计特征和顺序性,从而影响了抽取效果.因此,为解决以上各类算法缺陷,本文提出一种新的基于深度学习模型的关键词抽取算法,另外为提高抽取效率,对每个单词的特征表示进行了研究.算法采用Transformer 和卷积神经网络相结合搭建系统总体框架,具体来说采用Transformer 来学习文本的全局上下文语义信息,同时融合每个单词的统计特征信息,作为相应单词的特征表示.我们认为一个单词的重要性不仅与这个词本身有关,还与相邻若干窗口内的单词有着密切联系,因此单词的局部特征直接影响着最终结果,而卷积网络的作用正在于能有效利用文本的局部特征信息.为了获取有限窗口内更多的相邻单词的特征信息,在算法模型中引入了空洞卷积[41],空洞卷积通过调整正常卷积层中卷积核的间隔数量,在降低计算量的同时扩大特征捕捉区域,获取更多的局部特征信息.最终算法模型综合以上文本全局语义信息和单词局部特征信息进行训练学习得出最终关键词.
2 基于全局和局部特征表示的关键词抽取算法
本文提出一种新的基于全局和局部特征表示的关键词抽取算法,设计了一个前馈神经网络架构,系统层次架构包括以下几个部分:①全局特征抽取组件,主要结合单词的语义特征表示和统计特征表示,获取输入文本的特征表示向量,并解决不同维度空间的各类向量表示映射至同一空间;②局部特征抽取组件,利用一维卷积和一维空洞卷积神经网络共同完成对单词的局部特征提取任务;③输出组件,通过训练学习,预测单词是否属于关键词.算法模型整体架构图如图1 所示.
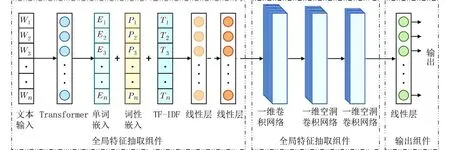
图1 本文算法的模型架构图Fig.1 Model architecture diagram of the proposed algorithm
2.1 全局特征抽取组件本文算法在全局特征抽取组件中获取输入文本中单词的各类特征向量表示,主要包括语义特征和统计方面特征.
用文本中连续离散的单词进入全局特征抽取组件,利用多层双向Transformer 模型得到每个单词的词向量嵌入表示,其结构如图2 所示,图中最低层表示在训练时每个单词的输入向量,图2 的右边展开部分是Transformer 的编码器(Encoder)结构.当输入向量进入编码器之后,首先会经过一个注意力机制层,使用注意力机制可以增强长距离特征捕获能力,以提取句子级别的语义特征信息.注意力机制采用缩放点积注意力(Scaled Dot-product Attention)和多头注意力(Multi-head Attention)两个部分组成,缩放点积注意力计算如下:
式中:Q、K、V代表输入序列的查询向量序列、键向量序列和值向量序列,dk为Q和K中的向量维度.接着多头注意力进行分头操作,然后对每个头进行缩放点积注意力计算,最后再对每个头进行拼接.
通过自注意力层使编码器对每个单词进行编码时可以查看其前后上下文信息,进行残差归一化处理.接下来将在注意力机制层得到的结果传入一个全连接的前馈神经网络,同样进行残差归一化处理后得到最终的输出.Transformer 模型在训练过程中通过考虑每个单词与句子中其他单词的相互关系,动态表示每个词的特征向量,使最终得到的向量表示不仅包含单词本身的语义,还包含了与上下文其他单词的语义联系.不难看出,Transformer赋予了不同位置的同一个单词不一样的特征向量表示.
由于关键词一般是由名词和形容词组成[14],并且常在文中多个位置出现,因此在本文算法中,就单词的统计特征而言,我们认为词语在单篇文档中的重要性由词频和词性两个方面特征来决定的.
首先,对于单词的词性特征,以往的关键词抽取算法通常在预处理阶段会将高频却无用的停用词删去,并且认为候选词是只有形容词和名词的组合词组.因此本文算法也会对单词进行词性标注,将每个单词的词性映射成一个M维的嵌入向量Pi.其次,由于文档中有些副词或停用词出现的次数会比较多,因此在统计单词的词频信息时不能只是简单地计算某个单词在文中的出现频次.算法中计算的是TF-IDF 值,它的核心思想是一个词的重要程度与它在单篇文档中的出现次数成正比,但与它在语料库中的出现次数成反比.跟前者词性特征向量表示不同,TF-IDF 的向量表示维度只有一维,不存在将离散数值映射转换成向量的操作,而是利用文档和语料库信息直接计算所得.每个单词i的TFIDF 值Ti计算公式如下:
基于上述计算所得每个单词i的语义特征向量Ei、词性特征向量Pi、词频的向量表示Ti,根据公式(5)计算得出每个单词的特征向量表示Xi.
式中:“+”表示向量的拼接.
通过实验我们发现,不同类型特征的向量表示空间并不相同,且影响算法抽取效果,为解决这一问题,我们在输入层的最后增加了两个线性层对不同的向量空间进行了统一化处理,首先利用第一个线性层将单词的特征向量表示映射到同一个高维空间,实验中将此维度设为3 000,接着利用第二个线性层进行降维处理,将单词的向量维度降低至最初的维度,并将此结果作为下一层隐藏层的输入向量.
2.2 局部特征抽取组件我们认为,对于固定长度的序列文本,单词不仅仅与全文具有语义相关性,还同相邻的若干个单词有着高度相关性,因此在图1 中的局部特征抽取组件中,设计了一个包含多层卷积的深度前馈神经网络,完成对单词局部特征的学习表征.CNN 能同时完成特征提取和识别分类两大任务,传统的CNN 网络架构通常包括卷积层、池化层和全连接层,具体如下:
(1)卷积层 完成特征提取功能,为避免训练过程中网络参数过多,采用稀疏连接,从而降低模型复杂度.另外为减少训练时过拟合情况发生,通过使用权值共享,减少参数,来提高训练优化效率,卷积结果的运算如下所示:
(2)池化层 利用特征降维完成特征选择功能,降低卷积层数据输出的特征维度,减少模型参数,防止过拟合.该层对卷积特征进行采样操作,一般包括平均池化和最大池化两种方式.
(3)全连接层 将前面获得的特征展平,完成下游回归或识别等任务.
在本文算法中,由于输入文本数据向量的维度不高,为防止特征数据信息的丢失,在训练过程中需要保持文本长度不变,因此删去池化层和全连接层,只需要卷积层帮助完成局部特征的提取.因此,我们设计了一维多层卷积神经网络,主要包括了1个卷积层和2 个空洞卷积层,如图1 中的局部特征抽取组件区域所示.模型利用卷积核以一定步长在文本上的顺序移动能有效提取这些局部区域内的特征信息.在一维卷积的工作过程中,可将卷积核看成一个固定大小的滑动窗口,并只沿着输入单词的方向按顺序移动,此时的卷积层可看成特征提取器.而空洞卷积网络通过调整卷积核的间隔数量,在降低计算量的同时扩大特征捕捉区域,从而捕获更大范围内的局部特征信息.
多层卷积网络实现细节如图3 所示,在图3 中,L表示文本长度,每个卷积核尺寸设为1×3,第一层卷积核的宽度设为512,第二层卷积核的宽度设为128,第三层卷积核的宽度设为50,所有卷积层的步长设为1,由于需要提取每个单词的特征信息,两层空洞卷积的卷积核间隔数量都设为2,因为如果设置间隔太远易丢失相关性较强的相邻单词间特征,影响实验结果.另外,不论哪一层都需要根据卷积核间隔对文本长度的首尾进行补齐操作,以保证经过卷积网络出来的文本长度保持不变.
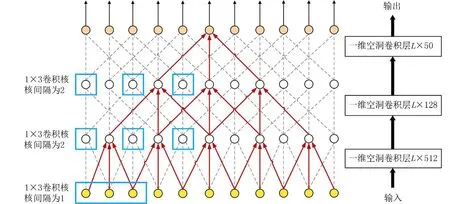
图3 多层卷积网络实现细节Fig.3 Implementation details of multi-layer convolutional networks
2.3 输出组件与2.1 小节介绍的两层线性层是用于统一不同向量表示空间的作用不同,本小节输出组件中线性层的作用可以看成分类器,对2.1 小节和2.2 小节提取的各类特征进行分类,即将所有从前面层获得的特征表示结果映射到样本标记空间.本文算法将关键词抽取看成是序列标注问题,通过线性层预测每个单词最有可能的类别.本文算法对所有单词的标记有3 种类:B-Key、I-Key 和O,其中B-Key 标记着关键词最开始的单词,I-Key 标记关键词中除首个单词以外的所有单词,O 标记非关键词的单词.
3 实验结果与分析
3.1 实验数据及评价标准为了保证实验结果的有效性、正确性和公平性,我们在两个公开语料库Inspec 和kp20k 上进行实验.Inspec 语料库[42]由2 000 篇英文科技论文的摘要部分组成,整个数据集分为训练集、验证集和测试集,分别为1 000、500篇和500 篇.kp20k 语料库由Meng 等[43]创建,该数据库由来自各种在线数字图书馆(如ACM 数字图书馆、ScienceDirect等)的567 830 篇科学文章组成,分为3 个集合:用于模型训练的包含527 830个文档的训练集,用于参数调优的包含20 000 个文档的验证集,用于模型评估的包含20 000 个文档的测试集.这两个数据集的详细统计信息如表1所示.表1 中文本平均长度是指在不同的数据集中,统计单篇文档中所有单词的平均个数,人工标注关键词总数是指预先标注的正确关键词个数.
两个语料库中的每篇文档都包括标题、摘要和正确标注的关键词.当算法提取关键词时,使用标题和摘要作为输入数据,而在评估算法结果时使用人工标注的关键词进行对比.实验中,我们使用F1 值(F-Measure)作为评价指标来衡量所有模型的性能,其计算公式如下:
式中:P(Precision)代表准确率,指通过该算法抽取出正确的关键词与该算法抽取的所有关键词的比例;R(Recall)代表召回率,指通过该算法抽取出正确的关键词与全部人工标注的正确关键词的比例.
3.2 实验环境与工具本文算法所有代码基于Python 3.7 和Pytorch 1.1.0,代码运行电脑内存为32 GB,处理器为Intel Core i7-9700K CPU @3.60 GHz 8 核处理器和GTX1080 GPU,操作系统是Ubuntu 16.04 LTS.
在预处理阶段,我们使用NLTK ToolKit 标记每个单词的词性.算法构建的神经网络第一层使用Transformer 对单词提取全局特征信息,选择采用BERT 将文档中的离散单词转换为包含语义信息的向量表示.谷歌为不同的语言和不同的模型大小提供了各种预先训练好的BERT 模型,实验中使用“bert-base-uncased”预训练模型训练每个单词,得到一个768 维的单词嵌入向量.用于训练神经网络模型的优化器是Adam[44],初始学习率设置为3×10−5,梯度裁剪设置为1.0.此外,损失函数使用CrossEntropy,为了避免过拟合,dropout比率设置为0.25.
3.3 消融实验及调参实验我们通过消融实验和特征参数调节实验,证明本文算法设计的网络架构的有效性及各类特征信息的有用性.
首先,对模型的神经网络架构进行了消融实验,具体来说,将本算法模型同只包含Transformer架构、Transformer+1 层卷积、Transformer+3 层卷积(无空洞)、Transformer+1 层卷积+1 层空洞卷积、Transformer+1 层卷积+3 层空洞卷积等这5 种架构模型进行了对比,在两个数据集上的实验结果如表2 所示.
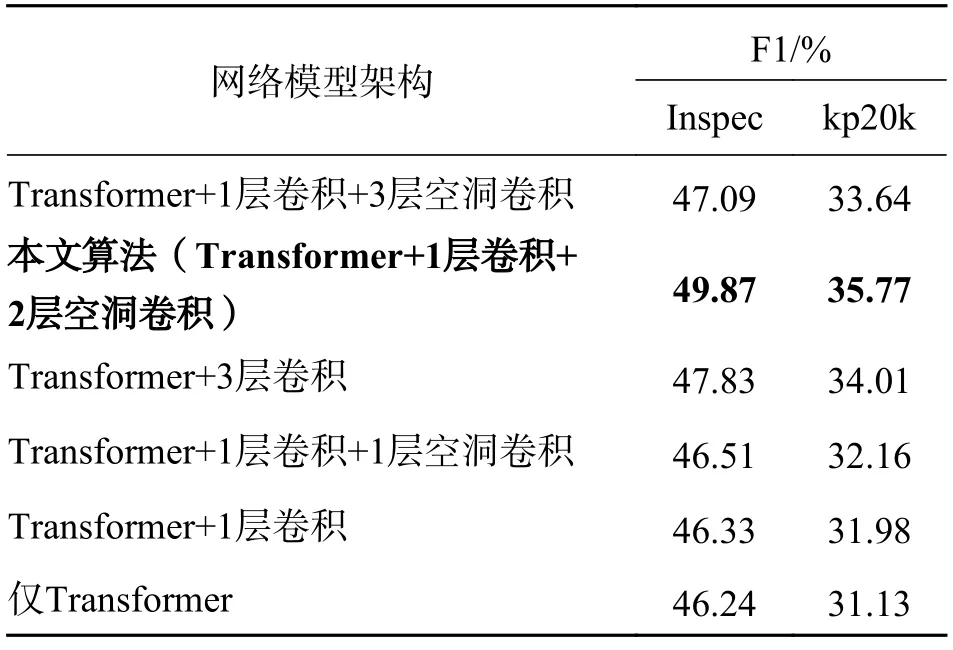
表2 在Inspec 和kp20k 上的消融实验结果Tab.2 The results of the ablation experiment in Inspec and kp20k
从表2 可以看出,本文算法模型架构较其他架构而言,获得了最高的F1 值,证明我们构建的深度神经网络架构对关键词抽取工作效率的提升有一定效果.以Inspec 语料库实验结果为例,当网络架构中只剩Transformer 时,F1 值降低了3.63 个百分点,由于卷积层的主要作用是提取单词的局部特征信息,说明算法融合单词的局部特征信息对抽取结果有帮助.另一方面,仅有Transformer 的网络架构意味着我们只使用了文档的上下文语义关系,抽取效果同3.4 节中其他主流关键词抽取方法相比依然有较大提升,这是由于Transformer 强大的自注意力机制不仅能获取单词级别的有效语义表示信息,还能对句子级别和文档级别的语义表示有很好的学习能力.当Transformer 对文本序列进行双向训练时,embedding 嵌入向量的层数较深导致可表征的函数空间足够大,每个单词的输出都能包含文档中其他单词的信息,因此极大地提高了模型抽取效率.实验结果还表明,本文算法与其他隐藏层中只有卷积网络而不包括空洞卷积网络的模型相比,F1 值最高降低了3.54 个百分点,最低降低了2.04个百分点,证明了空洞卷积网络的有用性,因为空洞卷积通过扩大卷积核特征捕捉区域,进而提高更大范围内的局部特征提取效率.另外在表2 中当模型中只有一层空洞卷积时,F1 值较本算法而言降低了3.36 个百分点,说明2 层空洞卷积网络较1 层空洞卷积网络而言能捕获并利用窗口内更多的局部特征信息.然而并不是空洞卷积层越多越好,比如采用3 层空洞卷积时,F1 值较本算法而言反而降低了2.78 个百分点,这是因为空洞越多,来自上一层的相邻局部信息越少,而越远距离卷积获得的信息相关性联系越少,会干扰相邻词语间特征提取的训练结果.
接下来,为了验证单词每一种统计特征的有效性,我们逐次往本文算法模型中增加一种新的统计特征,在两个数据集上的实验结果如表3 所示.从表3 中不难发现,每加入一个新的统计特征,关键词抽取的效率都得到了提高,当同时采用二个统计特征(词性、词频)时,获得了最高的F1 值.

表3 在Inspec 和kp20k 上调整不同统计特征的实验结果Tab.3 The results of adjusting different statistical features in Inspec and kp20k
另外,我们测试了统计特征信息的不同向量维度对算法结果的影响.由于对词频特征的向量表示只有一维,因此只需要调整词性特征的向量维度,图4 中折线代表不同的词性向量维度下模型性能的改变.从图4 中发现,当维度设置为40 的时候,F1 值达到了峰值,但增加词性维度时,反而降低了,说明维度增加并不一定能增强词性特征的重要性,这是因为关键词的词性一般只局限于名词和形容词的组合,关键词的正确词性范围较小,而过多的特征向量维度会使单词的向量表示分布比较离散,不能代表正确的特征信息.
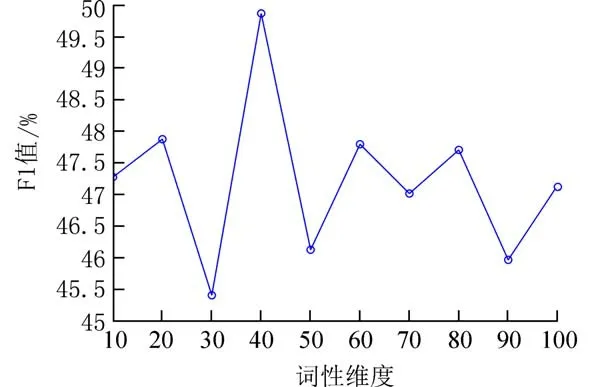
图4 Inspec 中不同词性维度下的实验结果Fig.4 Experimental results under different dimension of the part-of-speech in Inspec datasets
3.4 与基本算法的对比实验我们选取了8 种不同类型的主流关键词抽取算法,分别在两个公开数据集Inspec 和kp20k 上进行了对比实验,具体的对比算法及参数设置如下:
(1)TF-IDF 基于统计的方法,主要利用词频特征抽取关键词;
(2)TextRank[4]基于图的方法,采用词之间的相邻关系建立有权重的图模型,利用PageRank 算法,窗口大小设置为10,阻尼系数为0.85;
(3)TopicRank[23]基于图和主题的方法,图建模时将主题簇作为图中结点,实验中选择每个簇中离中心最近的词语作为最终结果;
(4)SingleRank[14]基于图的方法,图中结点为名词或形容词,利用窗口内词之间的距离计算边的权重,窗口大小设置为10,阻尼系数为0.85;
(5)PositionRank[17]基于图的方法,对图结点的初始赋值中加入位置信息,窗口大小设置为10,阻尼系数为0.85;
(6)EmbedRank[29]:基于深度学习的方法,利用嵌入技术将语义信息融入算法,权衡参数设置为1.
(7)Bi-LSTM[37]基于深度学习的方法,利用Bi-LSTM 架构将关键词抽取作为序列标注任务.
(8)Bi-LSTM-CRF[37]基于深度学习的方法,利用Bi-LSTM-CRF 模型选择关键词.
由于语料库中正确标注的关键词一般在10 个左右,因此上述对比的基线方法在实验中统一抽取10 个关键词进行比较,实验结果如表4 所示.
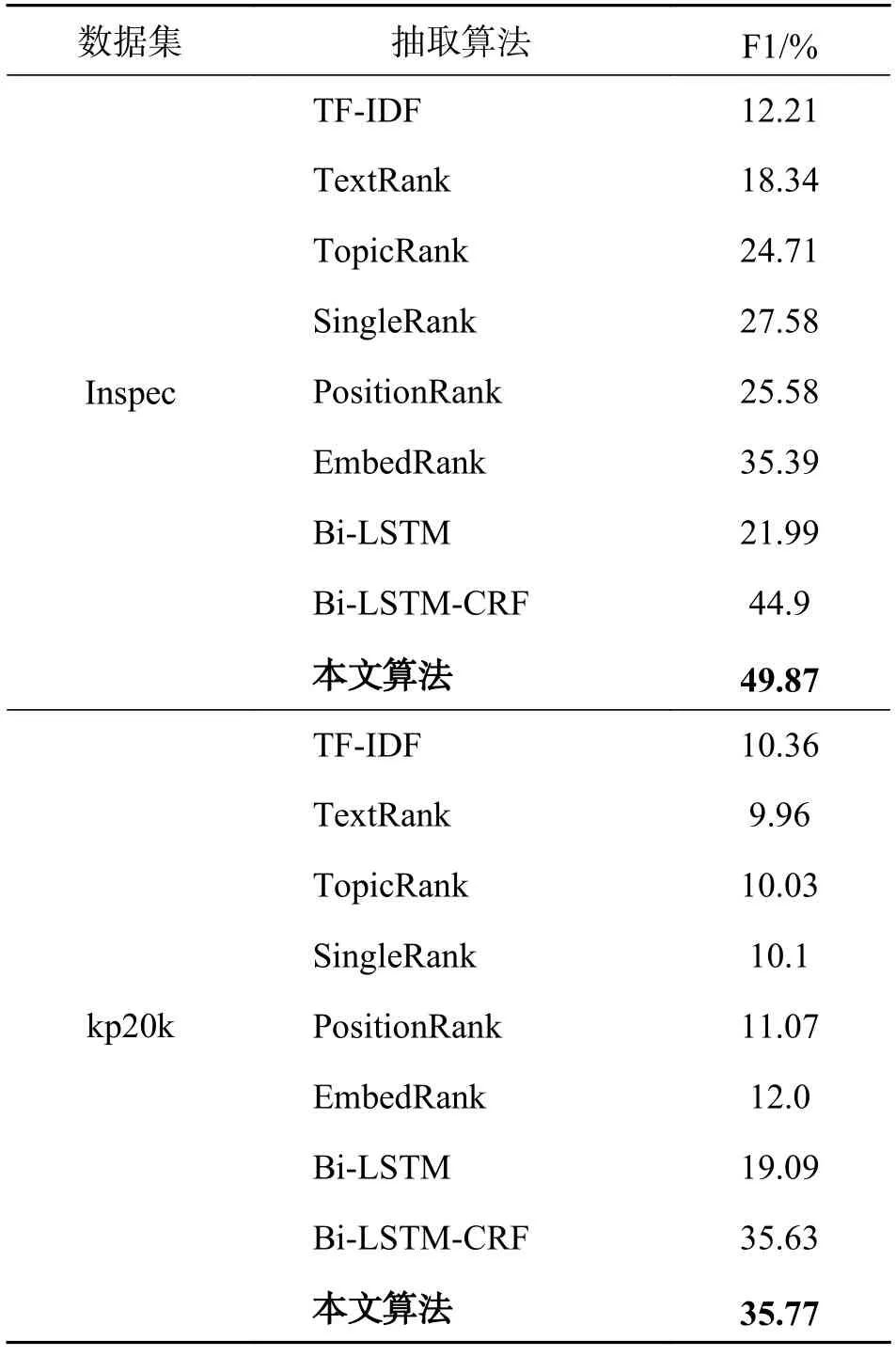
表4 在Inspec 和kp20k 上的对比实验结果Tab.4 Comparative results in Inspec and kp20k
从表4 可以看出,在两个公开语料库上,本文算法相对于其他8 种主流关键词算法,抽取性能均得到了较大地提升.实验中TF-IDF 是基于简单统计词频的方法,忽略了其他各类特征,导致抽取性能最差,在两个数据集上,本算法较TF-IDF 而言,F1 值分别提高了37.66 和25.41 个百分点.通过实验发现,在抽取算法中融合多特征信息(如语义特征、统计特征)的思想比以往只依赖位置信息(如PositionRank)或主题信息(如TopicRank)能获得更好的效果,比如在Inspec 数据集上,本文算法较PositionRank 而言,F1 值增加了24.29 个百分点,较TopicRank增加了25.16 个百分点.对于另外两个基于图的方法TextRank 和SingleRank 均利用图模型在算法中加入两个词语间的关联信息,在构图时忽略了语义层面的特征信息,而本文算法利用Transformer 模型充分考虑了文本的上下文语义信息,结果明显优于前两者,如在Inspec 上,本文算法的F1 值较TextRank 方法增加了31.53 个百分点,较SingleRank 方法增加了22.29 个百分点.由于EmbedRank 只计算了词语同文本间的语义相似度,忽略了单词与单词间的局部语义相关性,而本文算法利用多层卷积和空洞卷积网络,能有效提取单词间的局部特征信息,因此较EmbedRank 而言,在两个数据集上得出的F1 值分别提高了14.48 和23.77个百分点.基于Bi-LSTM 和Bi-LSTM-CRF 模型的两种方法更注重利用Bi-LSTM 组件获取上下文语义信息,而本文算法不仅关注全局上下文信息,还增加对局部信息的考量,从而得到较好的抽取效果,如在Inspec 上,本文算法较Bi-LSTM-CRF 而言,F1 值增加了4.97 个百分点.
在各类算法运行过程中,基于统计(TF-IDF)和基于图的方法(TextRank、TopicRank、SingleRank和PositionRank)均为无监督方法,其中基于图的4种方法由于要对全文候选词语进行构图处理,时间复杂度要稍高于基于统计的方法.基于深度学习的4 种方法(EmbedRank、Bi-LSTM、Bi-LSTM-CRF、本算法)均为有监督方法,在运行时,由于事先需要在训练集上优化模型参数,训练的时间复杂度虽高于其他方法,但在模型参数训练稳定后,就推理时间而言明显优于其他无监督方法.
另外我们在实验中发现,表4 中后4 个基于深度学习的抽取方法的效率普遍高于其他类型抽取方法,这是因为神经网络架构具有强大的表征学习能力,从而可以提取很多有用的特征信息,说明深度学习模型是用来大幅度提高关键词抽取效率的重要手段.
4 结束语
本文通过研究如何在关键词抽取过程中同时利用文本的全局语义特征信息和单词间的局部特征信息,提出了一种基于全局和局部特征表示的关键词抽取算法.采用Transformer 模型获取文档中单词的语义特征表示,并计算单词的词频和词性两方面统计特征信息,融合上述两种特征信息得出每个单词的向量表示,利用一维卷积和一维空洞卷积神经网络获取单词在某一窗口内尽可能多的局部特征,综合利用以上全局语义信息和局部特征信息,通过训练学习得出最终关键词.实验结果表明,本文算法效果明显优于目前其他8 种主流关键词抽取方法.
下一步的研究工作预计在以下两方面进行:一是利用其他的神经网络模型学习单词更多的特征信息,并融入更多的统计特征信息,以提高关键词抽取效率;二是目前大部分关键词抽取算法都在短文本上效果比较好,如何提高在长文中的抽取效果,是我们感兴趣的方向.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
