
基于改进熵权法和SECEEMD的短期风电功率预测
2023-10-12 10:40王永生张哲刘利民高静刘广文武煜昊
科学技术与工程 2023年27期
王永生,张哲,刘利民*,高静,刘广文,武煜昊
(1.内蒙古工业大学数据科学与应用学院,呼和浩特 010080; 2.内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010080; 3.内蒙古农业大学计算机与信息学院,呼和浩特 010018)
随着化石能源的逐渐枯竭和全球对于环境保护的愈加重视,风力发电逐渐代替火力发电,成为中国主要的发电方式。据相关统计,截至2021年底,中国的风电装机容量已经达到了3.28亿千瓦,成为全球风电装机容量第一大国家[1],成了全球规模最大的风电市场。然而过大的风力发电规模给风电场的管理以及电网调度带来了严重的影响。因此,对于实现高精度的风电功率预测迫在眉睫。
受到风的波动性影响,风电功率数据处于严重的不平稳状态[2]。刘栋等[3]通过变分模态分解将原始数据分解,然后使用加权排列熵将分量进行重组,再通过麻雀算法对支持向量机进行优化,并通过优化后的支持向量机对风电功率进行预测。武新章等[4]通过互补集合经验模态分解(complementary ensemble empirical mode decomposition,CEEMDAN)算法对风电功率数据以及风速数据进行分析,平稳其中的波动性,然后结合注意力机制以及时间卷积网络对风电功率进行预测。通过信号分解可以将不平稳的数据分解为平稳的分量,实现数据的平稳化。高精度的风电功率预测除了需要对平稳的风电功率数据之外,还需要多维气象特征的辅助。从风电产生的原理可以看出,通过使用多维气象数据对风电功率数据进行预测,能够实现较高精度的风电功率预测。杨国清等[5]利用皮尔逊相关系数对数值气象预报 (numerical weather prediction,NWP)数据进行相关性分析,然后通过Attention-GRU(Attention-gate recurrent unit)对风速进行修正,最后通过Stacking框架,结合多种模型对风电功率进行预测。康文豪等[6]通过PCA(principal component analysis)对气象数据实现降维,降低后续模型的训练复杂度,然后结合MRFO(manta ray foraging optimization)算法和极端随机数对风电功率进行预测。栗然等[7]利用PCA对多维气象数据进行预处理,然后通过卷积网络进一步降维,最后使用长短期记忆网络(long short term memory,LSTM) 对风电功率进行预测。杨芮等[8]通过Pearson相关系数分析气象特征与风电功率数据之间的相关性,然后通过结合卷积神经网络和GRU对风电功率进行预测。
上述研究中,虽然通过信号分解算法将风电功率数据平稳化,然而存在分量较多,模态混叠加剧的问题;通过特征优化方法对气象特征进行降维、优化,但单一特征优化方法存在一定的局限性,例如:主成分分析降低特征的可解释性,破坏了原始特征的完整性,影响后续预测模型的预测精度;皮尔逊相关系数仅能评价线性关系,且要求数据服从正态分布[9]。因此,为解决该问题,同时实现风电功率的高精度预测,现提出基于改进熵权法和样本熵-互补集合经验模态分解 (sample entropy CEEMD,SECEEMD)的短期风电功率组合预测方法。首先,提出一种综合相关性评价模型,通过结合多种相关性分析方法,对NWP数据进行分析,避免单一方法的局限性,准确地选择出相关程度较高的气象特征;然后,使用样本熵对CEEMD分解算法进行改进,分别建立NWP-LSTM和SCEEMD-BP(back propogation)预测模型,并利用贝叶斯优化算法对其结构进行优化;最后,通过改进熵权法寻找最优权重,并对预测结果进行组合;最后通过内蒙古碧柳河风电场的实采数据证明本文所提预测方法的有效性以及合理性。
1 风电功率预测组合方法
风电功率预测不仅受到气象数据的影响,同时也受到自身趋势的影响,因此,从两个角度出发,以NWP数据以及提出的综合相关性评价 (comprehensive correlation evaluation,CCE)模型为基础,提出了NWP-CCE-LSTM预测模型;以历史风电功率数据和提出的SECEEMD分解算法为基础,提出了SECEEMD-BP预测模型。为提高模型的预测精度,使用贝叶斯寻优对两部分预测模型的模型结构进行寻优;为保证组合权重分配的客观性,使用结合贝叶斯寻优的熵权法对最优权重进行计算,并对两个预测模型的预测结果进行加权组合。
1.1 NWP-CCE-LSTM预测模型
1.1.1 综合相关性评价模型
气象特征对风电功率预测尤为重要,通过气象对风电功率进行预测,可以实现相较于使用单一特征进行预测更高的预测性能。但过多的气象特征会导致后续的预测模型训练复杂程度上升,训练速度变慢,影响模型的预测性能,同时,不同气象特征对模型预测性能的影响不同,有影响模型预测精度的风险,因此,需要通过特征优化对气象特征进行处理。然而,现有风电功率预测的研究中,大多数的特征优化方式为单一特征优化方式,该方法存在一定的缺陷,对模型预测精度的提升较弱,无法实现高精度的风电功率预测。因此,提出一种CCE模型,通过结合多种相关性评价方法对不同气象特征进行评价,综合所有的评价结果对气象特征进行优化。
为保证特征的可解释性和完整性,综合相关性评价方法选择了两种特征选择方法,分别为Pearson相关系数法和灰色关联分析法。
Pearson相关系数法是卡尔·皮尔逊于是1897年提出的一种相关性评价方法,最为经典的相关性评价方法[10]。该方法通过计算数据之间的协方差和标准差来衡量数据之间的相关性。其计算公式为
(1)
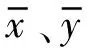
灰色关联分析法是Deng[11]于1989年提出的针对灰色系统的相关性分析方法。针对了解不完全的系统,通过分析元素的差值,得出不同元素之间的相关性。邓氏灰色关联分析法的流程如下。
(1)计算差值。
ci=|ai-bi|
(2)
(2)计算差值的最大值和最小值。
Cmax=max(C),C={c1,c2,…,cn}
(3)
Cmin=min(C),C={c1,c2,…,cn}
(4)
(3)计算单一元素的灰色关联度。
(5)
(4)计算总体灰色关联度。
(6)
式中:ci、ai、bi分别表示第i个差值和不同序列的第i个元素;p为分辨系数,其范围为[0,1],其值越大,分辨能力越强,通常取0.5。
通过Pearson相关系数分析气象特征与风电功率数据之间的线性相关性[12],通过灰色关联分析气象数据曲线与风电功率数据曲线之间的关联性[13]。同时,为了更加全面地对气象特征与风电功率数据之间的相关性进行评价,提出一种趋势相关系数(trend correlaction coefficient,TCC),用来衡量气象数据发展趋势与风电功率数据发展趋势之间的相关性,其计算步骤如下。
(1)计算不同序列的趋势变化值。
Ca=at-at-1,t=2,3,…,n
(7)
Cb=bt-bt-1,t=2,3,…,n
(8)
(2)比较单一时刻趋势变化是否相同。
(9)
(3)计算整体趋势相关系数。
(10)
式中:Ca、Cb分别表示序列a和序列b不同时刻的趋势变化值;at-1、at分别表示序列a第t时刻和第t-1时刻的数据;ζt表示第t时刻两序列的趋势变化情况;ζ表示两序列整体的趋势相似系数,其范围为[0,1],其数值越大,表示两个序列之间的发展越相似。
通过上述的三种相关性评价方法对气象特征和风电功率数据之间的相关性进行分析,然后计算均值作为最终的综合相关性系数,实现更为全面、准确地对进行特征选择,对后续预测模型精度较大的提高。CCE模型的结构如图1所示。
1.1.2 LSTM神经网络
LSTM神经网络是目前常用于时间序列数据预测的深度学习模型。LSTM神经网络的核心为三种“门”:遗忘门、输入门、输出门[14]。LSTM为实现对数据时序性的考虑,通过输入门和遗忘门对细胞状态进行更新,然后将在计算下一时刻的细胞状态时,考虑该时刻的细胞状态。其过程如下所示。
(1)遗忘门对上一时刻的隐藏状态和该时刻的输入进行计算。
ft=σ(Wf[ht-1,xt]+bf)
(11)
(2)输入门对上一时刻的隐藏状态和该时刻的输入进行计算。
it=σ(Wi[ht-1,xt]+bi)
(12)
(13)
(3)更新该时刻的细胞状态。
(14)

更新完细胞状态后,便可以对当前时刻的输出以及要向下一时刻传递的隐藏状态进行计算,其计算公式为
ot=σ(Wo[ht-1,xt]+bo)
(15)
ht=ottanh(Ct)
(16)
式中:ot为第t时刻输出门的输出;Wo为输出门的权重;bo为输出门的偏置权重;σ为Sigmoid函数。
通过门控机制,LSTM可以实现对数据集时序性的考虑。同时,LSTM作为一种目前主流的深度学习模型,对多维数据的处理性能更优,因此,将LSTM与提出的CCE模型结合,通过多维气象数据对风电功率进行预测。
1.2 SECEEMD-BP预测模型
风电功率数据除了受到多维气象因素的影响外,还受到自身数据不平稳性的影响。由于风的波动性、随机性,导致风电功率数据的不平稳性[15],使得后续预测模型的预测精度较低,因此,提出采用样本熵改进的CEEMD分解算法对风电功率数据进行分解,在将其平稳化的同时,降低分量数量,保证分量的时序稳定性。
1.2.1 SECEEMD分解算法
针对非平稳的时序数据,对其使用时序分解便可以将其平稳化[16],使得可以更加容易地获取到时序数据的特征趋势,从而提高时序预测的精度。
CEEMD分解算法是目前信号分解领域较新的分解算法[17],该分解算法虽然解决了EMD分解算法存在的模态混叠问题[18]和EEMD存在的对数据完整性造成影响的问题[19],但随着数据量的增大,CEEMD分解算法会出现分解出的分量过多,分解不完全,模态混叠程度加剧的情况。
针对这一问题,对CEEMD分解算法进行了改进。样本熵作为一种衡量时序数据混乱性时序熵,其值越大,时序数据的混乱性、随机性越大,产生新模式的可能性越高。其计算方式如下所示。
(1)将原始数据划分为窗口大小为m的时间窗口序列。
Xi=[xi,xi+1,…,xi+m-1]
(17)
(2)计算除自身外,与其他窗口的距离。
d=max(|xi-xj|)
(18)
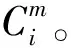
(19)
(4)计算平均值φm。
(20)
(5)将m+1,重复步骤(1)~(4),得出另一个平均值φm+1。
(6)计算样本熵。
sampen=lnφm-lnφm+1
(21)
式中:xi和xj属于不同时间窗口对应的数据;db为超过阈值的距离的个数。
由于样本熵能够对时序数据的混乱性进行衡量,因此,为了降低分量产生新模式的概率,提高预测模型的预测精度,提出使用样本熵对CEEMD分解算法进行改进。该改进算法通过样本熵对分量进行进一步筛选,剔除其中混乱程度较高的分量,保证分量的时序稳定性,其步骤如下所示。
(1)向原始数据中添加M组正负相抵的白噪声。
X+(t)=X(t)+c+(t)
(22)
X-(t)=X(t)+c-(t)
(23)
(2)对添加白噪声的数据进行EMD分解。
(3)将多次分解后的分量求平均,得到CEEMD分解的分量。
(24)
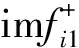
(4)计算每个分量的样本熵。
(5)通过设定的混乱性阈值,对高于该阈值的分量从原始数据中剔除,低于该阈值的分量保留,作为后续预测模型的输入特征。
通过SECEEMD分解算法,将非平稳的风电功率数据平稳化,并且降低了分量数量,保证了分量的时序稳定性,在提高后续预测模型训练速度的同时,提高模型的预测精度。
1.2.2 BP神经网络
BP神经网络是最为经典的神经网络。在目前风电功率预测领域中,很多研究将BP神经网络作为风电功率单特征预测的预测模型。BP神经网络的核心为“前向预测,反向修正”,结构为三层网络结构,包括:输入层、隐藏层、输出层,每一层有多个神经元,每个神经元与下一层的每个神经元连接,并拥有一个权重。通过将输入与权重相乘,然后加上每一层的偏置权重,得到该层的输出,然后通过激活函数,输出到下一层,作为下一层的输入。
BP神经网络的反向修正是其最为重要的核心。通过反向修正,可以依据预测与真实值的误差对神经网络的权重进行更新,从而实现对真实值更加贴近的预测。其主要公式为
(25)
(26)
ωjk=ωjk+ηHjek
(27)
(28)
bk=bk+ηek
(29)
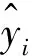
通过上述公式,可以对BP神经网络每一层的权重进行更新,使预测值与真实值逐渐贴近,逐渐拟合。
1.3 改进熵权法以及组合模型
权重分配方式对于组合模型尤为重要,决定了组合模型最终的预测性能。为保证权重分配的客观性,结合贝叶斯寻优算法对熵权法进行改进,通过改进的熵权法计算NWP-CCE-LSTM预测模型和SECEEMD-BP预测模型的权重,并对其预测值进行组合。
1.3.1 BO-EWM权重分配
熵权法(entropy weight method,EWM)是一种客观权重赋予办法,通过信息熵来对权重进行计算[20]。信息熵是一种衡量数据信息量的熵值,其数值越大,信息量越小,那么发生的概率越大。在目前的风电概率预测领域中,已有人使用熵权法作为组合模型的权重分配方式,例如:杨锡运等[21]通过熵权法计算了风电概率组合概率区间预测模型的权重。以NWP-CCE-LSTM预测模型为例,熵权法的步骤如下所示。
(1)将预测值与验证值的MAE、MSE、MAPE组为N×3的矩阵。
(30)
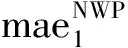
(2)计算单一指标占该指标全部数据的概率,以NWP-CCE-LSTM的MAE为例。
(31)
(3)计算单一指标的信息熵,以NWP-CCE-LSTM的MAE为例。
(32)
式(32)中:emae为通过NWP预测的预测值的mae的信息熵;N为预测数据的总量。
(4)计算该预测模型总体信息熵。
(33)
式(33)中:eNWP为通过NWP预测的预测值的整体信息熵;emae为预测值的emae的信息熵;emse为预测值的mse的信息熵;emape为预测值的mape的信息熵。
(5)计算信息效用值。
dNWP=1-eNWP
(34)
式(34)中:dNWP为通过NWP预测的预测值的信息效用值。
(6)计算权重。
WNWP=dNWP/(dNWP+dSECEEMD)
(35)
式(35)中:WNWP为通过NWP预测的预测值的权重;dSECEEMD为通过SECEEMD预测的预测值的信息效用值。
通过上述步骤,便可计算两个预测模型的客观权重。但客观的权重分配无法使组合模型的预测精度达到最佳,因此,需要向对权重分配方案进行进一步寻优。
贝叶斯优化算法(Bayesian optimiazation,BO)是一种参数优化算法,可以对神经网络的结构进行优化[22]。该算法的本质为通过给定的目标函数,通过采集函数来确定参数的范围,然后考虑上一次的信息,来更好地选择参数。相较于传统的网格搜索,贝叶斯优化算法迭代次数少,寻优速度快。
因此,结合贝叶斯优化算法和熵权法,提出了基于贝叶斯优化的熵权法 (Bayesian optimiazation entropy weight method,BO-EWM)权重分配算法。将EWM算法计算的客观权重作为权重分配的下限,通过贝叶斯优化算法寻找最优权重组合。
1.3.2 组合模型
本文提出了一种基于改进熵权法和SECEEMD的风电功率短期组合预测方法。该方法针对影响风电功率的多维气象因素和风电功率自身趋势,分别构建了NWP-CCE-LSTM预测模型和SECEEMD-BP预测模型,并使用BO算法对模型结构进行寻优,然后使用改进的熵权法对两个模型的权重进行计算,并依据最优权重组合,将两个模型的预测值组合为最终预测值。组合模型的整体结构如图2所示。
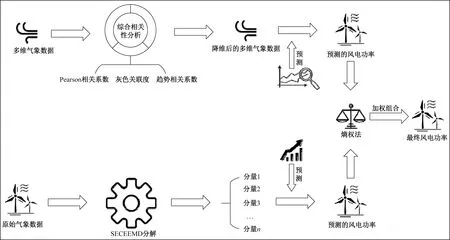
图2 整体流程图
2 实例验证
2.1 实验数据
本文所使用的数据为内蒙古碧柳河风电场2019年1月1日至2019年3月1日的实采数据,包含了风电功率数据以及多维气象数据,其中多维气象数据包括:风速、风向、温度、湿度、空气密度和气压。数据的采集频率为15 min采集1次,共5 760条数据。本实例中将数据按照4∶1的比例将数据分为训练集和验证集。
2.2 模型评价指标
为合理、科学地对本文所提模型的预测性能进行评价,依照国家现行的关于风电功率预测系统的评价标准[23],选择拟合优度(R2)、平均绝对误差(mean absolute error,MAE)[24]、均方误差(mean square error,MSE)、平均绝对百分比误差(mean absolute percentage error,MAPE)[25]。以及运行时间作为评价标准,其公式如下所示。
平均绝对误差:
(36)
均方误差:
(37)
平均绝对百分比误差:
(38)
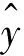
2.3 数据预处理
2.3.1 缺失值填补
在神经网络的训练过程中,数据集的完整性对模型的性能也存在着一定的关系。时序数据会因为人为原因或一些不可抗的因素,如人为误删、数据采集传感器损坏等原因,导致数据丢失或数据缺失[26],从而对数据集的完整性造成影响。针对缺失的数据,一般采用删除法、权重法、填补法等方式[27]进行处理。由于本实验所使用的数据集的损失率较低,因此,本实验选择较为简单的均值填补方法对缺失值进行处理。
2.3.2 标准化
在多元特征预测中,由于不同的指标,其值的范围不同,因此,为统一其范围,需要进行标准化,将其数值统一在统一量纲分数内。无量纲化的方式有最大值-最小值方法、Z方法等。本实验由于使用了灰色关联分析算法,而使用该算法对使用最大值-最小值方法进行无量纲化处理的数据进行分析时,可能会存在灰色关联度大于1的情况,因此,本实验选择使用Z方法。其公式为
(39)
式(39)中:Xmean为数据集的平局值;Xstd为数据集的标准差。
2.3.3 时间滑动窗口搭建
时间滑动窗口(time sliding window,TLW)是一种数据重构技术。风电输出功率由于受到风速、风向等不稳定、随机性强的气象因素的影响,导致其数值同样具有随机性,但仍具有一定的周期性。为考虑到历史风电功率在时间维度上的特征,提高预测精度,本实验使用时间滑动窗口对风电功率数据进行相空间重构。
已知风电功率数据为[x1,x2,…,xn],时间滑动窗口大小为m,则重构后的风电功率数据可以表示为Xm(i)=[xi,xi+1,…,xi+m]。其重构过程如下式所示:
(40)
通过时间滑动窗口重构算法,对气象数据、功率数据以及分解算法分解出来的分量进行重构,以便于后续的神经网络可以捕获到数据在时间维度上的特征。
2.4 实验部分
2.4.1 NWP-CCE-LSTM预测
在NWP-CCE-LSTM预测部分,对全部气象数据与风电功率数据进行相关性分析。经计算,全部气象数据与风电功率数据之间的Pearson相关系数、灰色关联度、趋势相关系数以及综合相关性系数如表1所示。
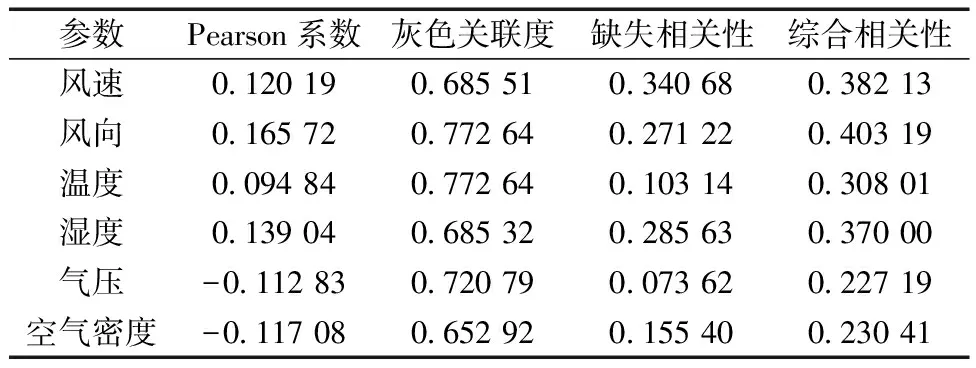
表1 不同相关性分析结果
通过表1可以看出,经过CCE模型进行相关性评价后,风速、风向、温度和湿度相较于剩下的气象特征与风电功率数据的相关性更强,因此,将其作为选择的气象特征,与风电功率数据一同作为NWP-CCE-LSTM预测模型的输入特征。
为验证本文所提NWP-CCE-LSTM预测模型的优势,本实例做了大量的对比实验,其实验结果如表2所示。

表2 特征优化对比实验结果
其中,实验1为未进行特征优化,将全部气象特征和风电功率数据一起作为LSTM的输入特征,从中可以看出,其结果并不理想,拟合优度仅达到了91%,MAE和MSE也高达0.21和0.1,其MAPE值也超过了1,说明该模型属于劣质模型;实验2为使用灰色关联度进行特征优化的结果,其R2相较于实验1提高了1%,MAE和MSE均为轻微下降,约为0.01,MAPE下降较多,下降了0.27,但其预测精度依旧不是最理想;实验3为使用主成分分析法对特征进行优化,虽然主成分分析法对特征数据的完整性和可解释性造成了影响,但其作为目前主流的特征优化方法,其优化性能较为良好。经过主成分分析优化气象特征后,模型的预测精度接近93%,提高较多,MAE、MSE和MAPE也有所下降,但由于对特征的完整性造成了影响,因此,该模型的预测精度仍有很大的提升空间;实验4为本文提出了NWP-CCE-LSTM预测模型,经过CCE模型进行特征降维后,模型的预测性能有了很大的提升,R2达到了93.6%,相较于实验1、实验2和实验3分别提高了2.4%、1.4%和0.8%,MAE、MSE和MAPE也有较大程度的下降,因此,证明了本文所提的CCE模型相较于目前主流的特征优化方法有较大的优势,能够为模型预测性能的提高提供更大的帮助。
2.4.2 SECEEMD-BP预测
在SECEEMD-BP预测部分,首先使用CEEMD分解算法将其分解为平稳分量,然后计算每个分量的样本熵,其结果如表3所示。
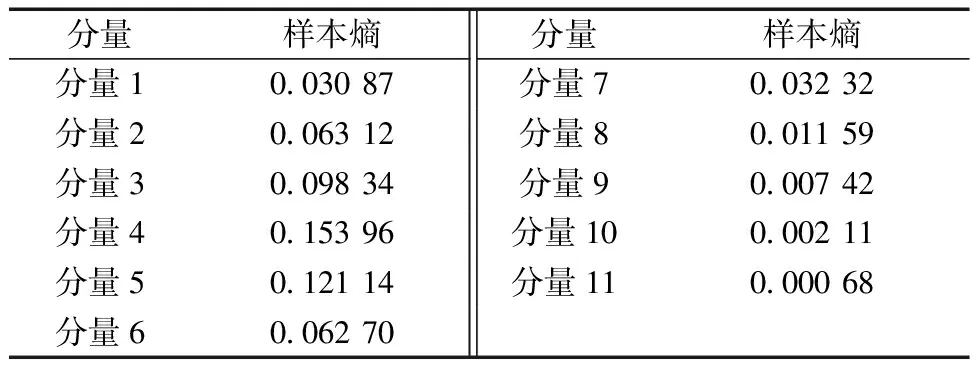
表3 所有分量的样本熵
通过表3可以看出,经过CEEMD分解后,大部分分量处于较为平稳的状态,其时序平稳性较好,产生随机新模式的可能性较低,但其中仍有部分分量相较于其他分量平稳性较差,产生新模式的可能性较高,例如,分量4和分量5。因此,为提高模型的预测精度,设定样本熵阈值,将超过阈值的分量从原始数据中剔除,保留稳定分量。为验证本文所提SECEEMD分解算法对后续预测模型的预测性能有较大的提升,对比了CEEMD分解算法和SECEEMD分解算法,其对比结果如表4所示。

表4 不同信号分解算法的对比结果
从表4可以看出,相较于CEEMD分解算法,本文所提的SECEEMD分解算法精简了分量,降低了分量的数量,因此使后续预测模型的运行速度较快,提高了35%。同时,由于使用样本熵对分量进行了筛选,降低了分量产生新模式的几率,使模型的预测精度有所提高,R2提高了0.3%,MAE降低了1.5%,MAPE的大幅度降低,说明SECEEMD更加适合对风电功率数据进行处理。
2.4.3 组合模型预测
在该部分,以NWP-CCE-LSTM预测模型和SECEEMD-BP预测模型的评价标准为基础数据,通过改进的熵权法对两种预测模型的权重进行计算。经计算最优权重为NWP-CCE-LSTM的预测值占10%,SECEEMD-BP的预测值占90%。为证明改进熵权法对组合模型的有效提高,本文做了对比实验,其结果如表5所示。

表5 不同权重分配方式的对比结果
其中,实验1为使用熵权法计算的客观权重作为权重分配方式的组合模型预测性能,其R2已经达到了97.3%,相较于单一模型有了较大的提高,MAE为0.104 16,MAPE的结果并不理想,达到了2.12,属于劣质模型,说明以熵权法计算的客观权重作为权重分配方式并不合适;实验2为使用改进的熵权法寻找出的最优权重作为权重分配方式,相较于实验1,其预测精度提高了0.3%,MAE下降了1%,但MAPE降为了0.47,下降了77.6%,MAPE的大幅度下降,证明改进的熵权法模型对于风电功率预测更加合适。
组合后,模型的部分预测值与验证值的拟合程度如图3所示。

图3 最终预测值与验证值的拟合程度
3 结论
实现风电功率的高精度预测,结合多维气象数据和风电功率本身趋势对风电功率预测的影响,提出了一种基于熵权法和SECEEMD的风电功率组合预测方法。
(1)提出了一种新的相关性评价方法——CCE,综合相关性评价方法,并且经过实例验证,该方法相较于目前主流的相关性评价方法,能够为预测模型提供更加准确的特征。然后结合该方法,针对多维气象数据对风电功率预测的影响,提出了NWP-CCE-LSTM预测模型。
(2)使用样本熵对CEEMD分解算法进行改进,并且经过实例验证,SECEEMD能够大幅度提高模型的预测速度,降低分量产生新模式的概率,提高模型的预测精度。
(3)结合贝叶斯优化算法对熵权法进行改进,结合熵权法的客观权重计算方法和贝叶斯优化算法的寻优能力,计算出组合模型的最优权重分配方式。经实例验证,改进后的熵权法能够提高模型的预测精度,大幅度提高模型的合适程度。
本文所提的组合预测方法,在特征优化方法、信号分解方法以及组合模型权重赋予方法上进行了改进,并经过实例验证,改进后的方法均能够对后续模型的预测性能有所提升,为风电功率预测的研究提供了一种有效方法,但仍有改进地方,目前仅为时域的分析,对于整体趋势的捕获能力不足,使其预测精度无法达到最大值,后续会以这一点为研究目标进行研究。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
成都信息工程大学学报(2022年2期)2022-06-14
基层中医药(2021年12期)2021-06-05
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2018年12期)2019-01-31
英美文学研究论丛(2018年1期)2018-08-16
中成药(2017年9期)2017-12-19
自然资源情报(2017年7期)2017-11-26
纺织科学研究(2017年6期)2017-07-03
