
基于改进YOLOv5的拥挤行人检测算法
2023-10-12 09:46王宏韩晨袁伯阳田增瑞盛英杰
科学技术与工程 2023年27期
王宏,韩晨,袁伯阳,田增瑞,盛英杰
(1.郑州轻工业大学建筑环境工程学院,郑州 450002; 2.河南省智慧建筑与人居环境工程技术研究中心,郑州 450002)
行人检测作为计算机视觉领域的热门研究方向,对于行人重识别、行人多目标跟踪、视频监控、智慧交通等领域具有重要意义。由于实际场景复杂、目标密度较大、重叠率过高,以及目标距离摄像设备较远等情况,导致当前行人检测算法存在精度低、漏检和误检率高等问题,因此提出一种可用于密集场景下的行人目标检测算法具有相当的可行性[1]。
基于深度学习的目标检测算法可分为基于区域推荐的Two Stage算法和基于回归的One Stage算法。Two Stage算法首先根据图像生成可能包含检测目标的候选框,然后对生成的候选框进行类别识别和位置校准,代表性的算法主要有R-CNN(region-convolutional neural network)[2]、Fast R-CNN[3]、Faster R-CNN[4]、Mask R-CNN[5]等,其特点是检测精度较高,但推理和检测时间较长。One Stage算法不需要生成候选框,仅需要一次特征提取,就可以直接生成被检测目标的类别概率和位置信息,代表性的算法主要有YOLO(you only look once)[6-10]、SSD(single shot multibox detector)[11]、EfficientDet[12]等,其特点是推理和检测速度显著提高,但检测精度较低。
近年来,许多学者针对基于深度学习的行人检测算法展开了相关工作。张秀再等[13]将YOLOv5模型与注意力机制、残差网络和软阈值化函数相融合,有效提高了对小行人目标和密集行人目标的检测精度,但网络结构过于复杂,导致检测速度较慢。邹斌等[14]提出了改进 Faster-RCNN的密集人群检测算法,在特征提取阶段添加空间与通道注意力机制并使用S-BiFPN(strong bidirectional feature pyramid network)替代原网络中的多尺度特征金字塔,使网络可以加强对图像深层特征的提取,但该算法无法满足目标检测的实时性。Zhang等[15]提出一种基于改进YOLOv3的轻量级行人检测算法,通过引入正则化减少了不重要的通道数,充分降低了模型的计算量和复杂度,但该算法在拥挤场景下的行人检测精度还有待提高。齐鹏宇等[16]提出一种全卷积One Stage目标检测框架,通过增加尺度回归提升了行人检测的性能,但该模型受行人深度特征影响较大,对遮挡目标的检测精度欠佳。刘振兴等[17]提出了一种融合上下文及空间信息的拥挤行人检测算法,通过改进特征金字塔网络结构和添加带权融合分支,有效提升了行人检测算法在拥挤场景中的检测效果,但在实验论证过程中发现该模型存在性能不稳定、检测不够精准和检测速度较慢的情况。
现有的深度学习算法在不同程度上提升了密集人群检测的性能,但部分改进后的算法网络结构较复杂,以及对遮挡程度较高的目标和极小尺寸目标的检测性能有所欠佳,导致改进后算法存在检测速度较慢、漏检和误检率高等问题。因此现提出改进YOLOv5的拥挤行人检测算法,通过公开数据集Crowd Human[18]对该算法进行训练,以期在密集场景中的拥挤行人检测能够达成更好的效果。主要工作如下。
(1)在主干网络中嵌入坐标注意力机制CA(coordinate attention)[19],用以增大主干网络的感受野和提高YOLOv5捕获位置信息的能力。
(2)在原网络三尺度检测的基础上再增加一层浅层检测层,同时改进特征融合部分,提高了对于小尺寸目标的检测性能。
(3)使用深度可分离卷积[20](DSConv)替换部分普通卷积(Conv),在对特征提取影响较小的前提下大幅降低了模型的参数量和计算量。
(4)使用有效交并比损失函数(efficient intersection over union loss,EIOU_loss)[21],融合边界框宽高比的尺度信息,有效提升了YOLOv5模型的检测精度。
1 YOLOv5算法原理
YOLOv5是YOLO系列算法中强大的一代,具有较强的实时处理能力和较低的硬件计算要求。YOLOv5包括4种不同的网络结构,考虑检测速度和精度两方面因素,以网络深度和宽度最小的YOLOv5s(简称“YOLOv5”)为基础网络进行优化。如图1所示,YOLOv5网络结构由输入端(Input)、主干网络(Backbone)、特征提取网络(Neck)、预测端(Prediction)四部分组成。
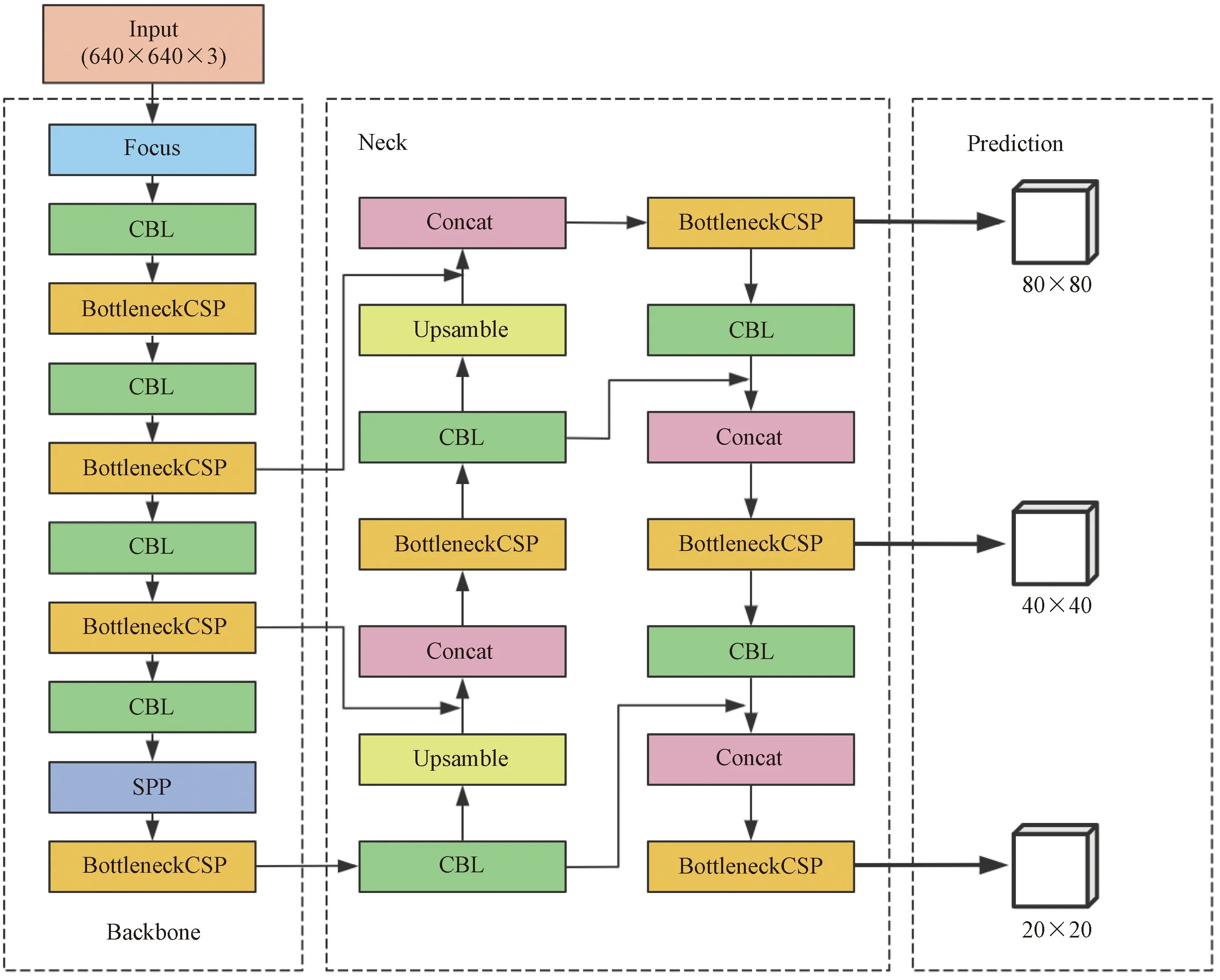
图1 YOLOv5网络结构
输入端包括Mosaic数据增强、图像尺寸处理和自适应锚框计算[22]。主干网络为CSP-Darknet53,主要包括Focus、CSP(cross stage partial)和SPP(spatial pyramid pooling)三部分。其中Focus模块能够实现快速下采样操作;CSP结构将输入分为分别执行卷积运算的两个分支,其中一个分支中信息通过CBL模块(CBL=卷积+正则化+激活函数)后进入多个残差结构,另一分支则直接进行卷积信息,之后将两个分支合并起来[23],使网络在提高模型学习能力的同时保证准确率;SPP模块由Conv、max-pooling和concat三部分组成,其作用主要是在不影响推理速度的前提下增加特征提取的感受野,同时增强网络的非线性表示。Neck的核心为FPN(feature pyramid network)和PAN(path aggregation network)。FPN 通过自上而下的上采样实现了语义特征从深层特征图到浅层特征图的传递,PAN 通过自下而上的路径结构实现了定位信息从浅层特征层到深层特征层的传递,二者的组合大大增强了网络的特征融合能力。预测端利用GIOU_loss损失函数和非极大值抑制(non-maximum suppression,NMS)获得最优的目标框,提高了网络识别的准确性。
2 YOLOv5算法改进
以YOLOv5原算法为基础,分别对其主干网络、检测尺度、特征提取网络和损失函数进行了一系列改进。改进后的YOLOv5网络结构如图2所示。
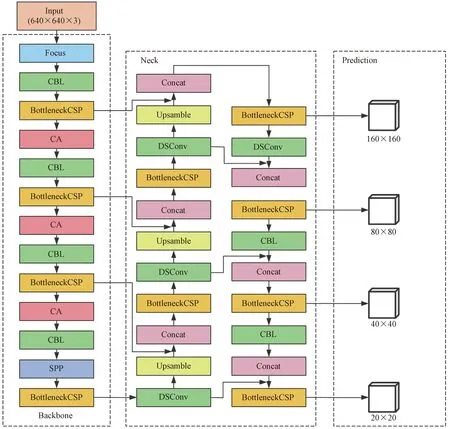
图2 改进后YOLOv5网络结构示意图
2.1 主干网络改进
在目标检测中加入注意力机制可以使模型聚焦于图像中的关键特征,抑制无关特征。为解决密集场景中背景信息杂乱导致行人目标的特征不明显,以及目标相互遮挡、重叠的问题,在主干网络中嵌入一种坐标注意力机制,使模型更准确地定位和识别感兴趣的目标。通常注意力机制会在一定程度上提高模型的精度,但同时也会使模型增加额外的计算量,影响其检测速率。但简单轻量的CA模块几乎没有额外的计算开销,能够在不影响模型检测速率的情况下提升模型的性能。
如图3所示,CA分为坐标信息嵌入和坐标信息特征图生成。
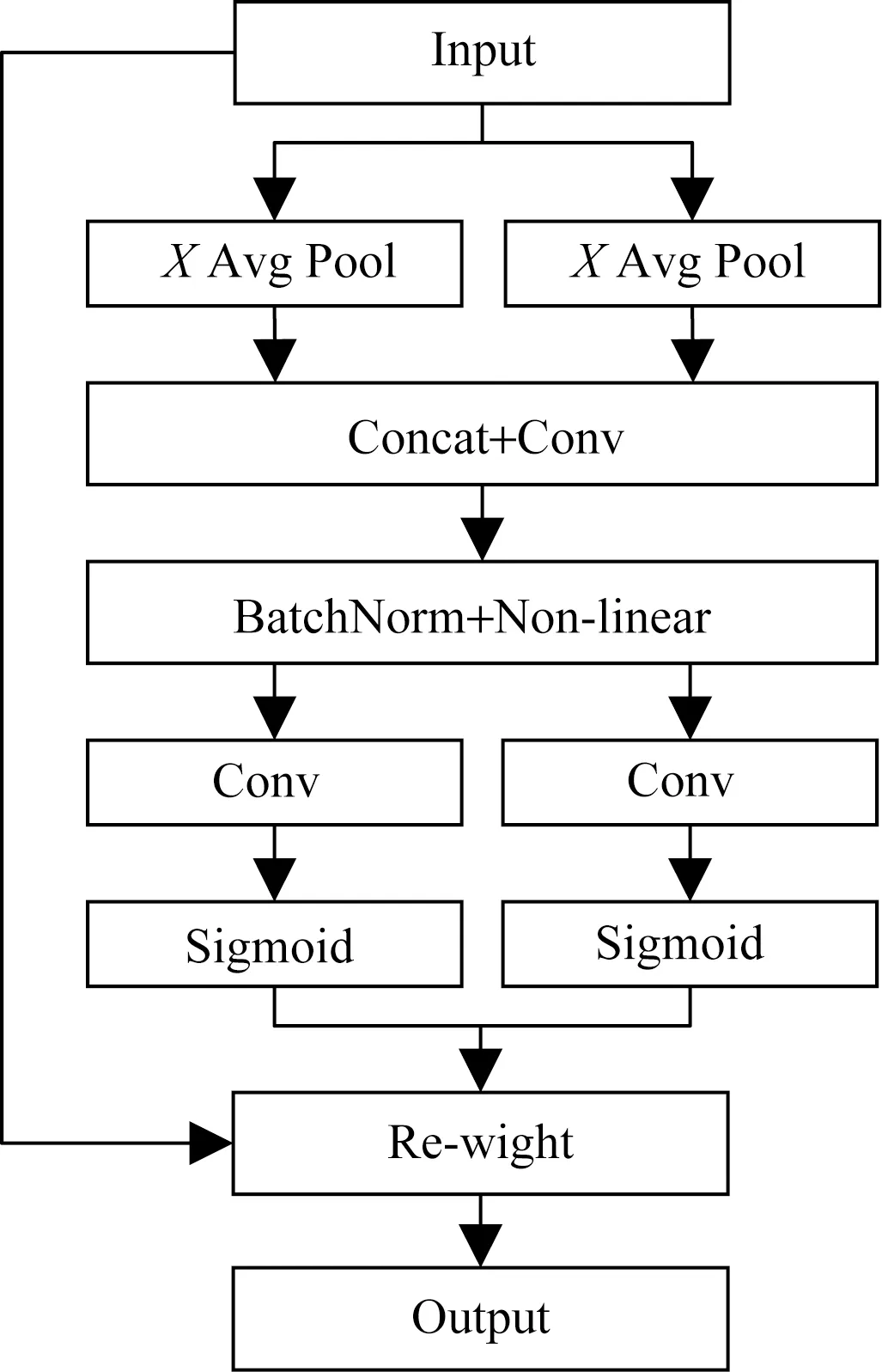
图3 CA结构示意图
第一步,CA对输入特征图X使用尺寸为(H,1)和(1,W)的池化核进行通道编码,得到高度为h的第c个通道与宽度为w的第c个通道的输出,产生两个独立方向感知特征图zh与zw,大小分别为C×1×H和C×1×W,公式为
(1)
(2)
第二步,通过Concat融合上述操作生成的zh和zw,并使用卷积核大小为1的卷积变换函数F1对其进行变换操作,生成在水平和垂直方向进行空间信息编码的中间特征图f,公式为
f=δ[F1([zh,zw])]
(3)
式(3)中:δ为非线性激活函数。沿着空间维度将f分解为两个独立的张量fh∈RC/r×H和fw∈RC/r×W,其中r表示下采样比例。然后利用两个卷积核大小为1的卷积变换函数Fh和Fw将特征图fh和fw变换为与输入X具有相同通道数的张量[24]。公式为
gh=σ[Fh(fh)]
(4)
gw=σ[Fw(fw)]
(5)
式中:σ为sigmoid激活函数。最后将输出gh和gw进行拓展,分别作为注意力权重分配值,最终输出公式为
(6)
2.2 检测尺度改进
对于输入尺寸为640×640的图像,YOLOv5分别利用8倍、16倍、32倍下采样输出检测尺度为20×20、40×40、80×80的特征图,对应检测大、中、小3种尺度的目标。但在实际场景中,很多行人目标由于距离当前摄像头较远,导致其在图像或视频中所占像素过小,而用来检测小目标的80×80尺度的特征图无法有效检测到这些更小尺寸的目标,极大地影响了检测结果。
针对以上问题,在YOLOv5原有网络结构上增加一层尺度为160×160的检测层,同时将原来的特征融合部分改为对应的四尺度特征融合。具体操作为:第17层后继续增加CBL层和上采样,使得特征图进一步扩大;在第20层时,将扩展得到的尺度为160×160的特征图与Backbone中第2层特征图进行Concat拼接,融合其细节信息和语义信息,获取更大尺度的特征图用以检测更小尺寸的目标;第21层增加尺度为160×160的浅层检测层,其他3个检测层保持不变。改进后的四尺度检测有效利用了浅层特征信息和深层特征的高语义信息,使模型能够从更深层的网络中提取特征信息,提高了模型在密集场景下多尺度学习的能力。
2.3 特征提取网络改进
改进YOLOv5的四尺度检测虽然提高了模型的检测精度,但同时也在一定程度上加深了网络深度,再加上YOLOv5网络中存在大量的卷积操作,导致模型参数量过多,检测速度较慢。使用深度可分离卷积替换Neck中的部分普通卷积,旨在确保精度基本不变的情况下降低模型的复杂度。深度可分离卷积的原理如图4所示。
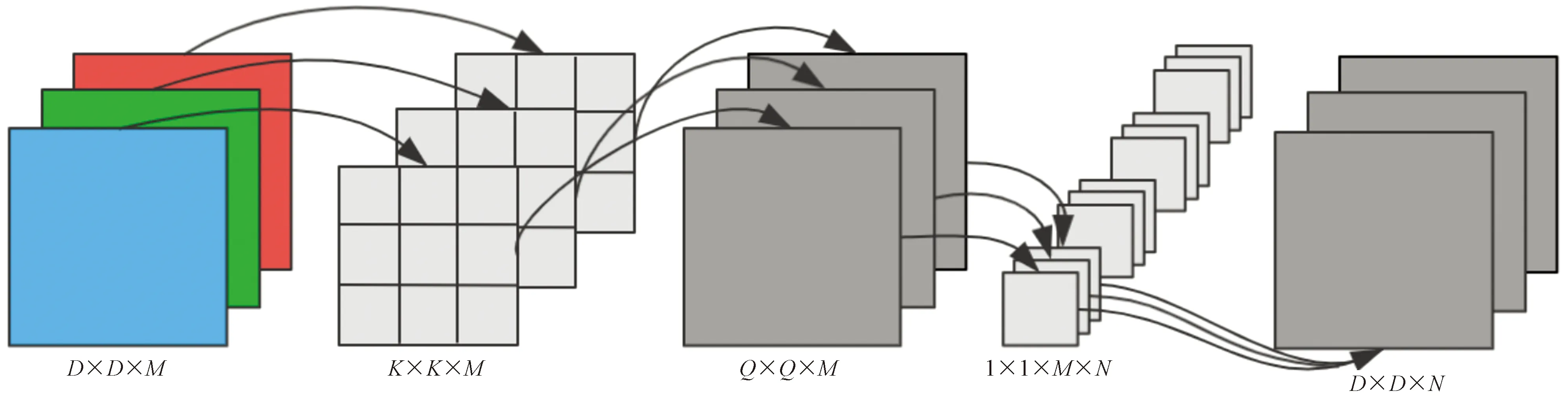
图4 深度可分离卷积原理图
深度可分离卷积将普通卷积分解为深度卷积和点态卷积。首先使用尺寸为K×K的卷积核对通道数为M的输入特征图做逐通道卷积,得到M个尺寸为Q×Q的特征图。然后由N个过滤器对特征图进行点态卷积操作,最终得到通道数为N,尺寸为D×D的输出特征图。普通卷积的计算公式为
K×K×M×N×D×D
(7)
深度可分离卷积的计算公式为
K×K×M×D×D+M×N×D×D
(8)
深度可分离卷积与普通卷积的计算量之比为1/N+1/K2,所以将特征提取网络中的部分普通卷积替换为深度可分离卷积可以降低模型参数量,提高模型检测速度。
2.4 损失函数改进
YOLOv5的损失函数包括边界框回归损失(bounding box loss)、置信度损失(objectness loss)以及分类概率损失(classification loss)三部分[25]。原YOLOv5算法采用GIOU_loss作为Bounding box的损失函数,其缺点是没有考虑到预测框在目标框内部且预测框尺寸相同的问题。针对这一情况,CIoU_loss通过考虑边界框回归的重叠面积和中心点距离,以及预测框和目标框的长宽比,使YOLOv5模型更精确地定位回归框。CIoU_loss计算公式为
(9)
(10)
(11)
式中:ρ2(b,bgt)表示预测框和真实框中心点之间的欧氏距离;c表示两框相交时构成的最小外接矩形的对角线距离;w和h表示预测框的宽度和高度;wgt和hgt表示真实框的宽度和高度;IOU表示预测框和真实框的交并比。
CIoU_loss提高了模型的检测性能,但未考虑到宽高与其置信度的真实差异。因此,引入性能更优的EIoU_loss作为bounding box的损失函数。EIoU_loss由重叠损失LIOU、中心距离损失Ldis和宽高损失Lasp三部分组成,前两部分保留了CIOU_loss的优势,宽高损失将优化目标设置为预测框与真实框的最小宽高差,能够加快模型的收敛速度和提高模型的精度。EIoU_loss计算公式为
LEIOU=LIOU+Ldis+Lasp
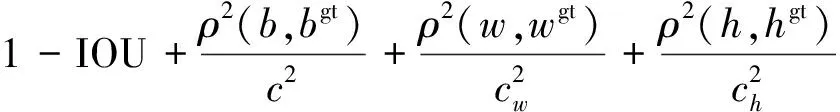
(12)
式(12)中:cw和ch为预测框和真实框的最小外接矩形的宽度和高度。
3 结果与分析
3.1 实验平台
所有实验均在操作系统 Windows10下进行,硬件设备为 GPU NVIDIA Tesla,深度学习框架为Pytorch 1.12.0,开发环境为 Python 3.8,CUDA 11.2。实验参数配置:初始学习率设置为0.01,使用余弦退火算法动态调整学习率,以实现有效收敛;学习率动量设置为0.937,以防止过拟合。训练批次设置为16,一共训练200个epoch。
3.2 实验数据集
采用开源的CrowdHuman数据集,主要采集于背景复杂多变的密集人群场景。该数据集包含约24 000张图片,共有470 000个标注实例,平均每张图片的行人数量达到了22.6人,存在各种遮挡情况。CrowdHuman数据集的目标边界框有3种,分别为头部框、可见身体框和目标全身框。本实验在训练时采用可见身体框,随机抽取8 000张图片作为训练集,2 000张图片作为测试集。
3.3 评价指标
为了更好地分析模型检测性能,采用平均精度均值(mean average precision,mAP)[26]、每秒处理图像帧数(frame per second,FPS)、参数量M、计算量(floating point operations,FLOPs)和模型大小,作为本实验模型的评价指标。其中mAP的计算公式为
(13)
(14)
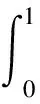
(15)
(16)
式中:P为精确率;R为召回率;TP为正确检测的行人数量;FP为误检的行人数量;FN为未被检测出的行人数量。
3.4 实验结果与分析
为验证模型改进后的效果,分别将改进前后模型的平均精度均值迭代曲线以及损失迭代曲线进行对比,结果如图5所示。
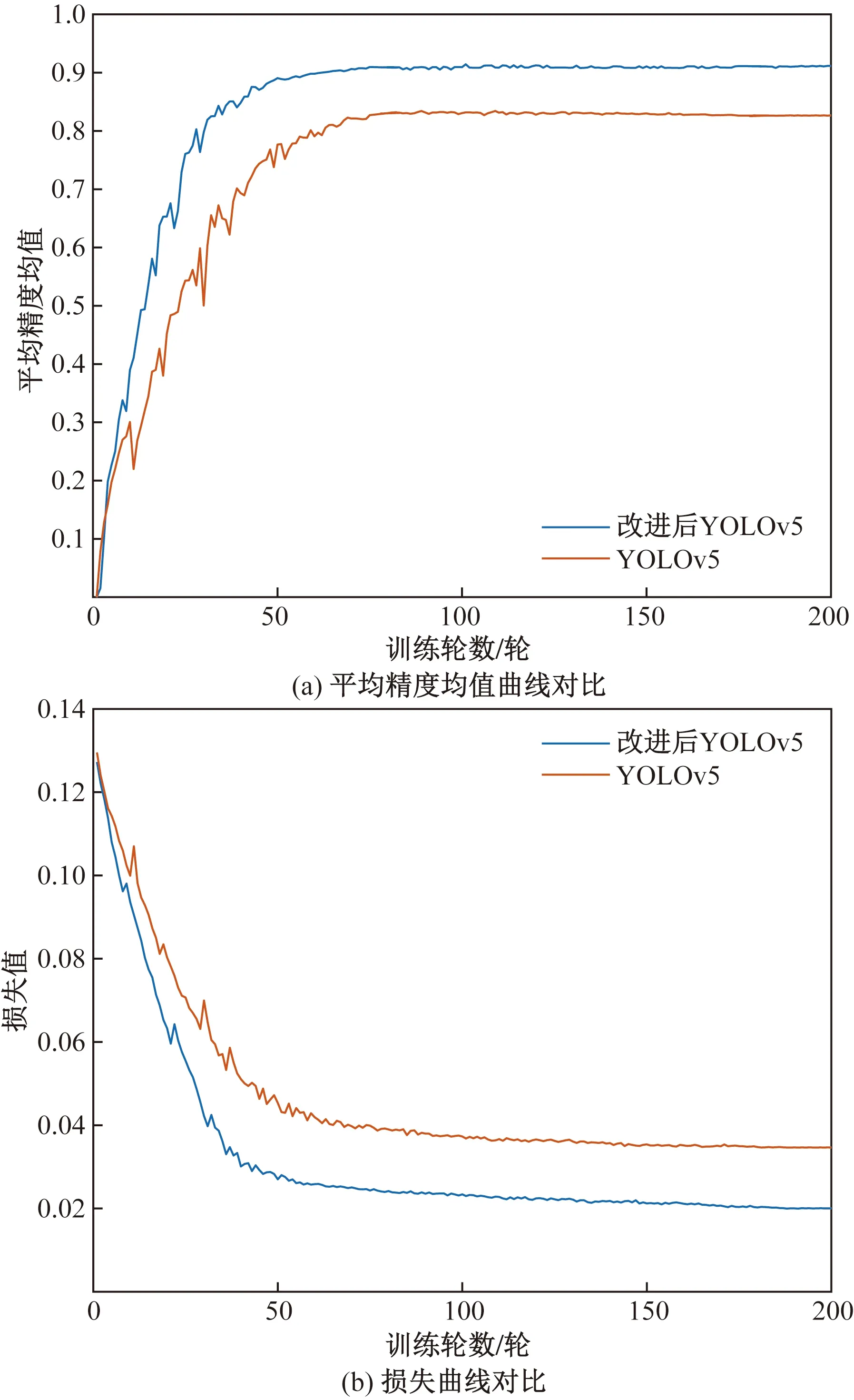
图5 结果对比
从图5(a)中可以看出改进后模型的曲线增长速度较快,mAP最终稳定在0.907,相较于原模型提高了7.4个百分点,且改进后模型的迭代曲线更加平稳,波动较原算法更小,从一定程度上反映了改进后的YOLOv5算法拥有更稳定的性能和更高的检测精度。从图5(b)中可以看出改进后模型的收敛速度更快和平滑性更好,损失值随着迭代次数的增加在50个epoch后逐渐趋于平稳,且最终稳定在0.020 04,相比原模型下降了0.014 6,表明改进后模型的训练效果更加理想。
为分析改进后YOLOv5的复杂度,将改进前后模型的参数量、计算量和模型大小进行对比,结果如表1所示。其中参数量可看作模型的空间复杂度,模型的参数越多则训练模型所需的数据量就越大;计算量可看作模型的时间复杂度,计算量越大则模型的训练和预测时间越长。由表1可知,相较于原YOLOv5模型,改进后模型的参数量减少了11.6%,计算量减少了10.7%,模型大小减少了11.1%。结果表明改进后YOLOv5能够在降低模型复杂度的同时大幅提高检测精度。

表1 模型复杂度对比
3.4.1 消融实验
本文改进后的模型在原YOLOv5的基础上添加了CA模块,将三尺度检测改为四尺度检测,使用深度可分离卷积和有效交并比损失函数。为了进一步分析每个改进点对原模型的优化作用,以YOLOv5原算法为基础模型设计消融实验,结果如表2所示。
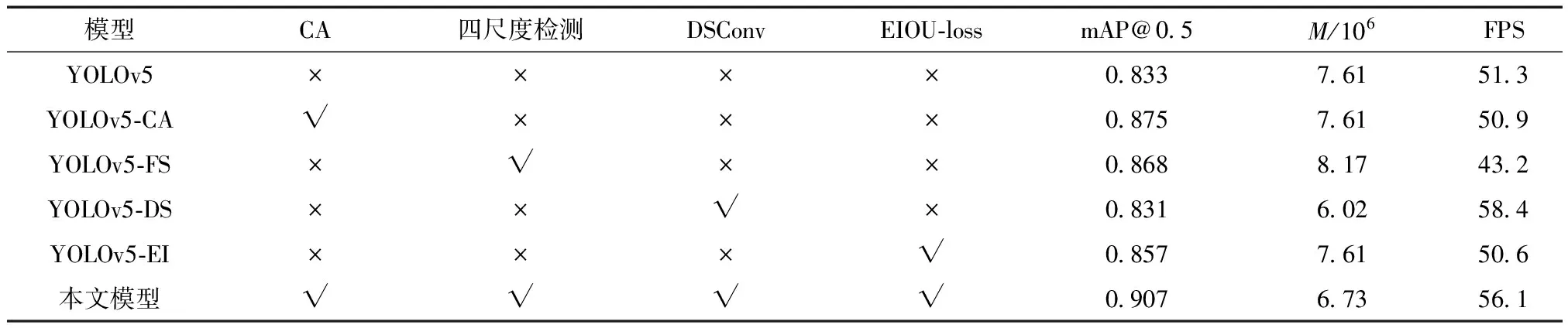
表2 消融实验
由表2可知,模型YOLOv5-CA 加入CA模块较原模型mAP增加了4.2个百分点,主要是因为原算法对特征的提取不够准确,将多个密集行人目标误检为一个目标,从而造成漏检,而添加CA后的模型精度得到大幅提升,并且对模型的参数量和FPS几乎没有影响。模型YOLOv5-FS 将三尺度检测扩展为四尺度检测,可以检测出原算法漏检的较小尺寸目标,将mAP提高了3.5个百分点,但新增的检测尺度加深了网络结构,导致模型参数量增加5.6×105,检测速率降低。模型YOLOv5-DS将部分普通卷积替换为深度可分离卷积,使参数量较原模型减少1.59×106,模型检测速度显著提高,mAP值虽略有下降,但对模型的精度几乎没有任何影响。模型YOLOv5-EI 使用EIoU_loss作为边框回归的损失函数,考虑到了预测框和目标框的重叠面积、中心点距离和长宽比,有效提高了模型边界框的定位精度,将mAP提高了2.4个百分点。对YOLOv5原算法同时使用以上4种改进方法,检测精度和检测速度均有明显的提升,且模型参数量较原模型减少8.8×105。实验结果表明CA模块、四尺度检测、深度可分离卷积和EIoU_loss的共同改进可以大幅提高拥挤行人检测模型的性能。
3.4.2 不同目标检测模型性能对比
为进一步分析改进YOLOv5算法的性能,将其与目前几种主流目标检测算法进行对比,结果如表3所示。
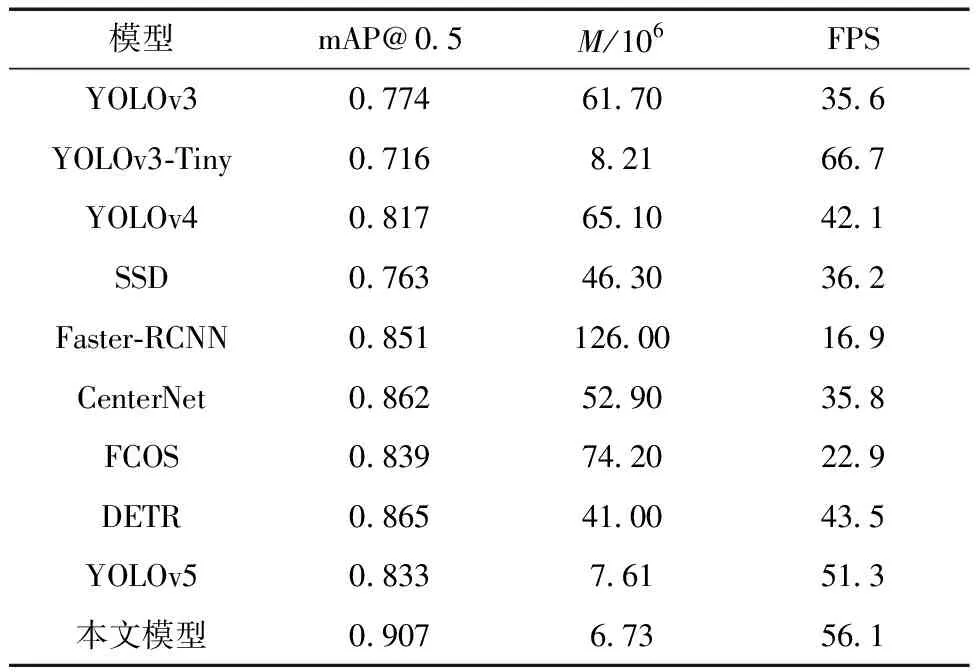
表3 不同算法性能对比
由表3可知,基于同一数据集,本文改进后模型与同系列YOLOv3和YOLOv4模型相比,参数量分别减少了54.97×106和58.37×106,mAP分别提升了13.3个百分点和9个百分点,检测速率分别快了1.58倍和1.34倍,表明改进后的YOLOv5模型在精度和速度方面有较大的优势;YOLOv3-Tiny模型的检测速率最高,但其mAP较改进后的YOLOv5模型减少了19.1个百分点,这是因为YOLOv3-Tiny算法在YOLOv3算法基础上去除了一些特征层,对小目标的检测精度影响较大;与同为One Stage算法的SSD 相比,本文模型的参数量降低了39.57×106,mAP提高了14.4个百分点;Two Stage算法Faster-RCNN较YOLOv5原算法mAP提升了1.8个百分点,但其模型参数量过大,对硬件设备要求较高,以及检测速率较慢,无法满足目标检测所需的实时性;与近几年的CenterNet、FCOS(fully convolutional one-stage object detection)和DETR(detection transformer)模型相比,本文模型的参数量分别减少了46.17×106、67.47×106和34.27×106,mAP分别提升了4.5个百分点、6.8个百分点和4.2个百分点,检测速率分别快了1.57倍、2.45倍和1.29倍,表明改进后YOLOv5模型能够以更低的空间复杂度达到更好的检测效果。由以上结果得出,本文改进后算法在显著减少模型参数量的同时具有较高的检测精度和速度,实现了更好的检测性能。
3.4.3 改进前后检测效果对比
为进一步验证改进YOLOv5算法的检测性能,本文使用CrowdHuman数据集中未经训练和测试的图片,对原YOLOv5算法与改进后YOLOv5算法在密集人群场景中的检测效果进行对比,结果如图6所示。由图6(a)和图6(d)可以看出,两种算法对遮挡程度较低的大尺寸行人目标均有较好的检测效果,但原算法对严重遮挡的小尺寸目标的检测效果不佳,改进后的算法能够更准确地识别此类目标;由图6(b)和图6(e)可以看出,两种算法均能较准确地检测出被遮挡目标,但原算法将人群旁边的壁画误检成行人目标,以及个别遮挡程度较低的小目标存在漏检情况,改进后的算法有效改善了此类问题;由图6(c)和图6(f)可以看出,原算法将广告牌上的人物和图片中的水印误检成行人目标,以及未能检测出被严重遮挡的小行人目标,改进后的算法针对此类问题的检测效果更佳。综上,原YOLOv5算法在严重遮挡的密集人群场景中的误检和漏检率较高,改进后的YOLOv5算法虽不能完全准确地检测出所有行人目标,但对于遮挡程度较高的小尺寸行人目标具有更好的检测效果。
4 结论
为解决目前拥挤人群目标检测存在的目标相互重叠、遮挡以及目标尺寸偏小等问题,本文提出了基于改进的YOLOv5拥挤行人检测算法。
(1)通过添加坐标注意力机制显著提升了模型检测精度,且对模型参数量几乎没有影响。
(2)在原算法的基础上增加小目标检测尺度,有效提升了模型在密集场景中多尺度学习的能力。
(3)将部分普通卷积替换为深度可分离卷积,在确保精度基本不变的前提下减少了模型的参数量。
(4)通过优化边界框回归损失函数,使模型在训练时的收敛速度更快,精度更高。
在公共数据集上的实验结果表明,改进后YOLOv5算法的平均精度均值为0.907,检测速度达到了56.1f/s,具有较好的检测精度和实时检测速度,能够有效应用于密集场景下的拥挤行人检测任务中。接下来将进一步完善算法的具体功能,通过结合自适应卡尔曼滤波实现多行人目标的检测和跟踪。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
