
Robust cross-modal retrieval with alignment refurbishment∗
2023-11-06 06:14JinyiGUOJieyuDING
Jinyi GUO ,Jieyu DING
1School of Computer Science and Engineering,Nanjing University of Science and Technology,Nanjing 210094,China
2School of Mathematics and Statistics,Qingdao University,Qingdao 266071,China
Abstract: Cross-modal retrieval tries to achieve mutual retrieval between modalities by establishing consistent alignment for different modal data.Currently,many cross-modal retrieval methods have been proposed and have achieved excellent results;however,these are trained with clean cross-modal pairs,which are semantically matched but costly,compared with easily available data with noise alignment (i.e.,paired but mismatched in semantics).When training these methods with noise-aligned data,the performance degrades dramatically.Therefore,we propose a robust cross-modal retrieval with alignment refurbishment(RCAR),which significantly reduces the impact of noise on the model.Specifically,RCAR first conducts multi-task learning to slow down the overfitting to the noise to make data separable.Then,RCAR uses a two-component beta-mixture model to divide them into clean and noise alignments and refurbishes the label according to the posterior probability of the noise-alignment component.In addition,we define partial and complete noises in the noise-alignment paradigm.Experimental results show that,compared with the popular cross-modal retrieval methods,RCAR achieves more robust performance with both types of noise.
Key words: Cross-modal retrieval;Robust learning;Alignment correction;Beta-mixture model
1 Introduction
In this paper,we focus on the robust image-text cross-modal retrieval problem,which involves searching an image(or text)for a given sentence(or image).It offers a broader range of applications and provides a better user experience than uni-modal retrieval,such as news search and product retrieval (Wang KY et al.,2016).State-of-the-art algorithms are trained with paired multi-modal data (e.g.,Fig.1a)and provide good results.Nonetheless,those clean paired data are modally aligned,which are expensive.With the explosive growth of multimedia data,the cross-modal data collected from the Internet are easily available,but most of them have some noise alignments,i.e.,paired data but mismatched semantically.In general,these data exist in three forms:clean alignment,partial noise alignment,and complete noise alignment (Fig.1).Experiments reveal that current methods perform badly in the context of noise-aligned data.Therefore,we propose a new method,named robust cross-modal retrieval with alignment refurbishment(RCAR),to solve the noisealignment image-text retrieval problem.

Fig.1 Three types of data-alignment instances: (a)a clean instance is modally aligned,meaning that image and text have consistent semantics;(b) a partial noise-alignment instance denotes a pair with partially mismatched semantics;(c) a complete noise-alignment instance indicates a pair with entirely mismatched semantics.Noise semantics are marked in red.References to color refer to the online version of this figure
Traditional cross-modal retrieval methods(Faghri et al.,2018;Li KP et al.,2019;Chen H et al.,2020;Diao et al.,2021)project different modal data into a shared semantic space,treat paired modal data as positive instances and unpaired ones as negative instances and are optimized by contrastive learning,as shown in Eq.(1),which maximizes the image-text similarity between positive instances(i,t)and minimizes the similarity between negative instances(i,ˆt)(Faghri et al.,2018):
whereαis the similarity margin and generally takes a value of 0.2,s(i,t)is the similarity between image and text,and [x]+takes the larger value between 0 andx.However,when the positive instance is unaligned,the model will still maximize the similarity incorrectly.Furthermore,cross-modal retrieval can also be reached by image-text matching(ITM),which concatenates the input of image and text to a transformer-based model and performs the binary classification using the classification[CLS]token(Lu et al.,2019;Chen YC et al.,2020;Li XJ et al.,2020).Despite the fact that this type of method has strong interaction capabilities,incorrect labels still degrade the model performance.
In contrast to image classification with noisy labels (Lin XY et al.,2021),we concentrate on crossmodal retrieval with noise-aligned multi-modal data,which takes mismatched multi-modal instance pairs into account rather than incorrectly labeled images.Note that many noisy label methods cannot be applied to the noise-alignment problem directly because these methods study class-level noise rather than instance-level noise in multi-modal data.However,there are still some methods that can be used,for example,sample selection(Han et al.,2018;Jiang et al.,2018) and label correction (Reed et al.,2015;Arazo et al.,2019).To make full use of noisealignment pairs,we apply the method of refurbishing labels.To make this practicable,we adopt ITM instead of contrastive learning to train the cross-modal retrieval model,because changing the binary alignment label is not affected by the batch size and is easy to reach compared with finding an aligned text(image)to the image(text).Inspired by Arazo et al.(2019),we fit the ITM loss to a two-component betamixture model (BMM) to separate the cross-modal samples into clean and noisy samples.However,directly solving the noise-alignment problem with this method is not practical.According to our observations of ITM loss,noise-alignment data are quickly fitted due to the strong fitting ability of transformerbased models,in contrast to the slow decline in noise-labeled image classification loss.Consequently,noise-alignment instances have higher loss only during a narrow time window at the beginning,which results in lack of adequate time and makes it difficult to distinguish clean and noise alignments from the loss distribution.Therefore,it is necessary to slow down the model’s fitting to the noise alignment,which can result in a larger time window for modeling a wellcategorized BMM.We discover that learning with ITM and masked language modeling (MLM) makes it possible.On one hand,MLM is self-supervised and no additional noise is brought in.On the other hand,multi-task learning(MTL) consisting of these two tasks reduces the risk of overfitting on the single task of ITM as a regularization method (Ruder,2017).
To summarize,the contributions of this paper are as follows:
1.From a practical standpoint,we divide the noise-alignment problem into two categories,partial noise alignment and complete noise alignment,based on whether the noise-alignment modality contains the same semantics.
2.We present a robust cross-modal retrieval method,RCAR,which combines the noise correction theory with MTL.
3.We construct these two types of noise on two datasets,i.e.,Microsoft Common Objects in Context(MS-COCO)and Flickr30K.We test our method and prove its robustness.Compared with popular methods,RCAR reaches the best retrieval efficiency.
2 Related works
2.1 Image classification with label noise
Image classification with noisy labels is a significant task in the field of computer vision,referring to the classification under noise supervision.Existing strategies,such as sample loss reweighting (Liu and Tao,2016;Wang RX et al.,2018;Zhang et al.,2021),label refurbishing (Reed et al.,2015;Ma XJ et al.,2018;Arazo et al.,2019),and robust learning(Manwani and Sastry,2013;Ghosh et al.,2017;Ma X et al.,2020),have been investigated from various perspectives to reduce the impact of noise on the model.Sample loss reweighting(Liu and Tao,2016)defines the sample importance weight as the quotient of the joint probability of the true and false distributions,with the correct sample having the larger weight value.The“Active Bias” (Chang et al.,2017)method assumes that the prediction variance reflects the degree of inconsistency and sample difficulty and weights the loss accordingly.
In contrast to sample loss reweighting,label refurbishment attempts to avoid overfitting to incorrect labels by refurbishing a noisy label.Deep neuron network(DNN) prediction is used to update the labels (Song et al.,2020).These methods,in some ways,enable the model to build self-confidence and robustness.The first way to implement this idea is bootstrapping.Reed et al.(2015)established a bootstrapping method that uses the label confidence discovered during cross-validation to update the target label of training data.Dynamic bootstrapping (Arazo et al.,2019) uses the expectationmaximization (EM) algorithm to evaluate the likelihood of a sample being cleanly labeled dynamically.SELFIE (Song et al.,2019)corrects the highconfidence training sample by substituting the label with network prediction.
The purpose of the robust loss function is to provide loss functions that keep the risk of unseen test data low even when the data are noisy.Manwani and Sastry (2013) investigated the noise tolerance property of risk minimization (under various loss functions),theorized a sufficient condition for the loss function,and made the risk minimization of this function a noise tolerance for binary classification.The robust mean absolute error(MAE)(Ghosh et al.,2017) model,on the other hand,demonstrates that the MAE loss shows a better generalization since it satisfies the aforementioned requirement.The curriculum loss (CL) model in Lyu and Tsang(2020)shows that 0-1 loss offers some robustness;however,optimization is challenging.Hence,they proposed a very straightforward and effective loss.Additionally,it is demonstrated that CL provides a tighter upper bound for the 0-1 loss than the typical alternative loss based on summation.Rather than using a predetermined threshold or calculation to do curriculum learning,MentorNet (Jiang et al.,2018)applies a data-driven strategy.However,MentorNet is a self-training system that tends to accumulate errors.All these methods focus on image classification with noisy labels and cannot directly be applied in robust cross-modal learning because of modal heterogeneity.
2.2 Cross-modal retrieval
Cross-modal retrieval is the process of finding a common representation space for various modalities so that they can retrieve each other.The most important problem that needs to be solved is modal heterogeneity.For modal retrieval strategies,there are two approaches(Geigle et al.,2022).The first approach involves early interaction methods(Jia et al.,2021;Radford et al.,2021).This kind of method maps image regions and text words to the same dimension before concatenating the input to the transformer and then performs the binary classification task using the [CLS] token.Cross-modal retrieval methods are usually used to train several largescale multi-modal pre-training models (Yang et al.,2022).The reason is that these are simple in principle,fast to train,and treat image regions and text words as equal tokens that can be fully interacted with inter-modal features while also fully interacting with intra-modal features,which is more beneficial to reducing inter-modal heterogeneity.The second approach is late interaction methods,e.g.,visualsemantic embedding(VSE++)(Faghri et al.,2018),stacked cross attention network(SCAN) (Lee et al.,2018),and similarity graph reasoning and attention filtration (SGRAF) (Diao et al.,2021),which encode the modalities individually,project them into a shared latent semantic space,and then compute the similarity between the projected points for contrastive learning.According to the features used,this technique can be divided into two types.The first category mines the hardest negative for targeted training using the global features of the modal data(Faghri et al.,2018),with the image’s global features retrieved using ResNet (He et al.,2016) and the text’s global features extracted using gate recurrent unit (GRU) (Chung et al.,2014).The second category (Lee et al.,2018;Li KP et al.,2019;Chen H et al.,2020;Diao et al.,2021;Messina et al.,2021)uses local features of modal data,with the image’s modal local features extracted using bottom-up attention and the text’s modal local features extracted using GRU or BERT (Devlin et al.,2019).The most significant distinction between these methods is the method of calculating the image-text similarity.Lee et al.(2018) used stacked cross attention to find potential alignment between regions and words and thereby to infer image-text global similarity.Li KP et al.(2019) pointed out that simply using the features of image region lacks the semantic concept of the scene,and that directly calculating the image-text similarity is not the best option;they proposed the use of a graph convolutional neural network to infer the image region’s relations,generating the region’s features with a semantic concept of the scene.In fact,semantics can be complicated,such as shallow and confusing.Chen H et al.(2020)computed the image-text similarity using an iterative matching strategy to achieve semantic alignment for mining various semantic complexities.Diao et al.(2021) used the graph convolutional neural network to obtain the similarity.However,these methods are trained with clean image-text pairs and generate bad results under noise-alignment supervision.
3 Proposed method
Cross-modal retrieval can be formulated as the problem of learning a modelf(I,T) to predict the similarity of imageIand textTfrom a set of multi-modal training instanceswithyi ∈{0,1}being the binary ground-truth label that indicates whether the image-text pair(Ii,Ti)is aligned(1)or not(0).For the noise-alignment problem,it is defined that some image-text pairs(Ij,Tj)cannot be identified in the training data,which are unaligned but are labeled as positive incorrectly.
3.1 Model pipeline
As illustrated in Fig.2,RCAR contains an image encoder,a text encoder,a single-stream transformer as a cross-modal encoder,and an alignment refurbisher.In this way,an input imageIand input textTcan be encoded into two sequences of embeddings{v1,v2,···,vO}and{w1,w2,···,wL},whereOis the number of detected image regions andLis the length of the sentence.As the input of the cross-modal encoder,we concatenate the image and text embeddings into one sequence{[CLS],v1,v2,···,vO,w1,w2,···,wL}.At the start of training,MTL is used with ITM and MLM to prevent the model from overfitting the noisy data.Then,ITM is conducted to do cross-modal retrieval.The refurbisher starts working after the warm-up period and it trains the network formepochs.
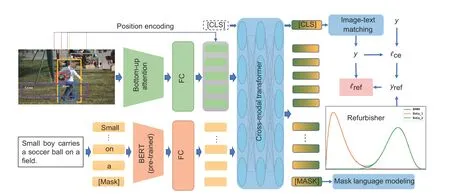
Fig.2 Illustration of robust cross-modal retrieval with alignment refurbishment (RCAR).RCAR learns a robust cross-modal retrieval model by combining a modal alignment refurbisher with multi-task learning.Image-text matching (ITM) and masked language modeling (MLM) are used to motivate multi-task learning to alleviate overfitting to the noise.To make full use of noisy data,the refurbisher is used to correct the noise-alignment label yi.FC: fully connected
3.2 Training objectives
3.2.1 ITM process
We use ITM as shown in Eq.(2) to predict whether a pair of image and text is aligned or not.Then,we make a binary classification according to the [CLS] token.
wherep(Ii,Ti)denotes the binary softmax probability of theithpair.
3.2.2 MLM process
In addition to ITM,we apply MLM to motivate MTL.The input words are randomly masked offwith a 15%probability and the masked ones are replaced with a special token [MASK].The objective is to minimize the negative log-likelihood of these masked words by observing their context wordswmand all image regionsv:
whereθrepresents the trainable parameter.
3.3 Alignment refurbisher
For noise-alignment correction,we introduce an alignment refurbisher which builds a mixture distribution model.Although the Gaussian mixture model (GMM) is the most widely used,its performance in approximating the loss distribution of a mixture of clean and noisy samples is worse than that of BMM (Arazo et al.,2019),because BMM can model both symmetric and skewed distributions ranging in [0,1] (Ma ZY and Leijon,2011).By modeling the normalized ITM loss of the image-text pairs,the refurbisher fits a two-component BMM that can be defined as follows:
whereμkis the mixing coefficient of thekthmixture component andf(ℓ|αk,βk) is the probability density function of thekthbeta distribution:
where Γ(·)is the gamma function andαk,βk >0.
To fit BMM to the ITM loss,we apply an EM algorithm.We define latent variableλk(ℓ)=p(k |ℓ),which represents the posterior probability of the valueℓbeing originated by mixture componentk.In the expectation-step(E-step),the Bayes rule is used to update the latent variablesλk(ℓ) with the other parametersμk,αk,andβkbeing fixed:
After the E-step,we fixλk(ℓ) and use a weighted version of the method of moments to estimate the distribution parametersαk,βk:
Then the updated mixing coefficientsμk’s can be calculated in the following way:
Finally,we can estimate the probability that the image-text pair is noise-aligned by calculating the posterior probability:
wheretindicates the noise-alignment class,which is the beta component with a larger mean value.
We refurbish only the positive instance because the negative instance is manually constructed and clean.With the computation above,the alignment labelyican be refurbished in the following manner:
whereziis the one-hot class prediction andHuses the class with the highest probability after weighted summation as a hard label.The loss after alignment refurbishment can be denoted as follows:
4 Experiments
4.1 Experimental settings
4.1.1 Noise-alignment type
From a practical standpoint,we propose two types of noise alignment with different proportions.The first type is partial noise alignment,which means that the image and text have matched semantics partially as shown in Fig.1b.It is constructed by calculating the Jaccard similarity,as shown in Eq.(13),of the objects between different positive pairs,which measures the similarity between two sets of classes(Niwattanakul et al.,2013):
The second and third reef are passed in the same manner; then the fishermen jump into thewater and push the boat towards the shore- every wave helps them-and at length they have it drawn up, beyond the reach of the breakers
Then,we replace the image or text randomly according to the similarity matrix.The second type is complete noise alignment,which means that the image and text are totally mismatched in terms of semantics,as shown in Fig.1c,and this is constructed by replacing the captions of the images randomly.
4.1.2 Data sources
We construct complete noise alignment on two public datasets,i.e.,MS-COCO(Lin TY et al.,2014)and Flickr30K (Huiskes and Lew,2008),and adopt partial noise alignment on only MS-COCO because the image-text pairs in MS-COCO have class information in the form of 80-dimensional one-hot vectors.For each type of noise,we validate our method’s robustness at four different noise ratios,i.e.,0%,20%,40%,and 60%,and report the results of other experiments at the 40% noise ratio.For the original dataset,MS-COCO contains 123 287 images and five captions for each image.Flickr30K consists of 31 000 images collected from the Flickr website,and here also each image is associated with five captions.We follow the split in Karpathy and Li (2015).
4.1.3 Evaluation metrics
We use the recall atK(R@K),which is defined as the fraction of queries for the correctly retrieved item among the closestKpoints to the query to measure the performance of image retrieval and text retrieval.
4.1.4 Implementation details
The entire network is trained on a TITAN RTX GPU.Following the method of Messina et al.(2021),we adopt faster regions with convolutional neural networks (Faster R-CNN) (Ren et al.,2017)as the image encoder and a pre-trained BERT (Devlin et al.,2019)as the text encoder,to extract local features.An eight-layer transformer is used with eight heads per layer.We train RCAR with MTL for 10 epochs and with ITM for 20 epochs.The model is warmed-up for seven epochs.The batch size is set to 64.We use the Adam (Kingma and Ba,2015) optimizer with a learning rate initialized by 3×10-5and use the cosine annealing strategy to update parameters.
4.2 Retrieval results on noisy cross-modal datasets
We provide the results of representative models,including VSE,VSE++,visual semantic reasoning network (VSRN),transformer encoder reasoning and alignment network(TERAN),SCAN,iterative matching with recurrent attention memory(IMRAM),and SGRAF.These methods represent four distinct technical paths: (1) global-feature-based methods: VSE,VSE++;(2) transformer-based model: TERAN;(3) local-feature-based methods without inter-modal attention: VSRN;(4) localfeature-based methods with inter-modal attention:SCAN,IMRAM,and SGRAF.Tables 1 and 2 present the quantitative results of comparison between these methods on two datasets with different ratios of noise-alignment data.

Table 1 Comparison of performance of RCAR with state-of-the-art methods in the context of partial noise-alignment data(part)on the MS-COCO dataset
The experiments reveal the following: (1)Complete noise alignment is more harmful for models to learn cross-modal consistency than partial noise alignment because models can still learn the object information in partially noisy data.(2) Hard negative mining(VSE++)has poor robustness compared with the traditional loss function (VSE) model because the hardest negative is likely to be a positive instance for noise-aligned data.(3) Using intra-modal attention to optimize modal features,i.e.,VSRN,has little effect on robustness improvement because the cross-modal attention mechanism is not optimized.On the contrary,using cross-modal attention to compute image-text similarity,i.e.,SCAN and SGRAF,can increase model robustness.The reason is that the model focuses attention on the aligned regions and reduces the learning of non-aligned regions.However,performance drops significantly on 60% complete noise.(4) Transformer-based model,i.e.,TERAN,has bad performance because it overfits the noise alignment easily due to its excellent fitting ability.(5) Traditional methods have some robustness because some of them still have a good performance in the context of 20% complete noise and all of them suffer from a “cliff-like drop” in the context of 60% complete noise.The reason is that these methods cannot learn a good semantic common space of those two modals on high-ratio noise.(6)RCAR is more robust because it reduces overfitting to the noise alignment and can still learn correct knowledge from the refurbished noisy instances.
4.3 Ablation study
Table 3 provides the results of ablation studies.To explore the effect of MTL and the refurbisher,we validate our approach by revisiting each term in Flickr30K with 40% complete noise alignment.The results reveal the following: (1)Baseline,i.e.,single-stream transformer with ITM,has a little worse performance than SCAN.(2) Both MTL and the refurbisher contribute to model robustness,and RCAR acquires better improvements by considering both of them.For example,the improvements of Image2Text and Text2Image are 21.9 and 13.6 respectively in terms of theR@1 score.

Table 2 Comparison of performance of RCAR with state-of-the-art methods in the context of complete noise-alignment data (cmp) on the Flickr30K and MS-COCO datasets

Table 3 Ablation study in the context of 40% complete noise-alignment data on the Flickr30K dataset
4.4 Sensitivity to parameters
To explore the influence of the warm-up epochs after which the refurbisher begins to work,i.e.,the parameterm,we tunemin{6,7,8,9,10,11}and show their performance in Fig.3.We find that the retrieval results are the best whenm=7,because the model is affected by the noisy sample whenmis large,while the losses are not separated because of the underfitting of the clean sample whenmis small.
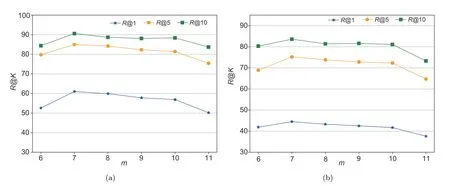
Fig.3 Parameter sensitivity of m in Image2Text (a) and Text2Image (b)
4.5 Computation time
We record the computation time of representative methods (i.e.,VSE++,VSRN,SCAN,TERAN,SCAN,IMRAM,SGRAF,and RCAR).The results in Table 4 reveal the following: (1)The global-feature-based model,i.e.,VSE++,has fewer parameters and shorter computation time compared with local-feature-based and transformerbased models,i.e.,VSRN,SCAN,TERAN,SCAN,IMRAM,SGRAF,and RCAR.The global-featurebased method cannot fit the training data well,which leads to the fact that the model does not achieve the best performance on clean data and also does not achieve the worst performance on data with high percentage of noise.(2) RCAR has more parameters because RCAR uses the BERT-based model as the text feature extractor,which has 109M parameters.(3) RCAR has the longest inference time,because RCAR uses the pre-interaction method and needs to concatenate different image-text pairs and input them into the transformer layer when calculating the similarity,which increases the inference time.However,the training time of RCAR is the shortest among the local-feature-based methods.Because RCAR uses the pre-trained BERT-based model for parameter initialization and a robust strategy for label correction,the training time is significantly reduced.For example,VSRN and RCAR have a similar size of parameters,but the training of VSRN takes 25.40 h,while RCAR takes only 7.50 h,which indicates that RCAR can converge faster.
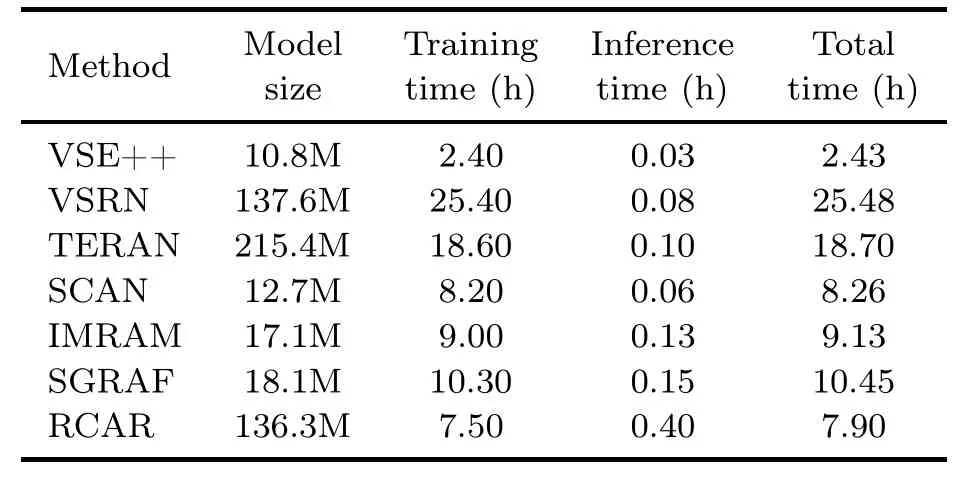
Table 4 Comparison of methods in the context of model size and computation time for 40% complete noise-alignment data on the Flickr30K dataset
4.6 Visualization and analysis
To illustrate the effect of MTL,we draw the boxplots shown in Fig.4,which demonstrates the distribution of 90%ITM loss of clean and noisy instances over the first 15 epochs.The remaining 10% loss data that are too large or too small are regarded as outliers.When the two distributions do not overlap,the data become more divisible.From observation,MTL creates a larger time window(4-14 epochs)for data separation.
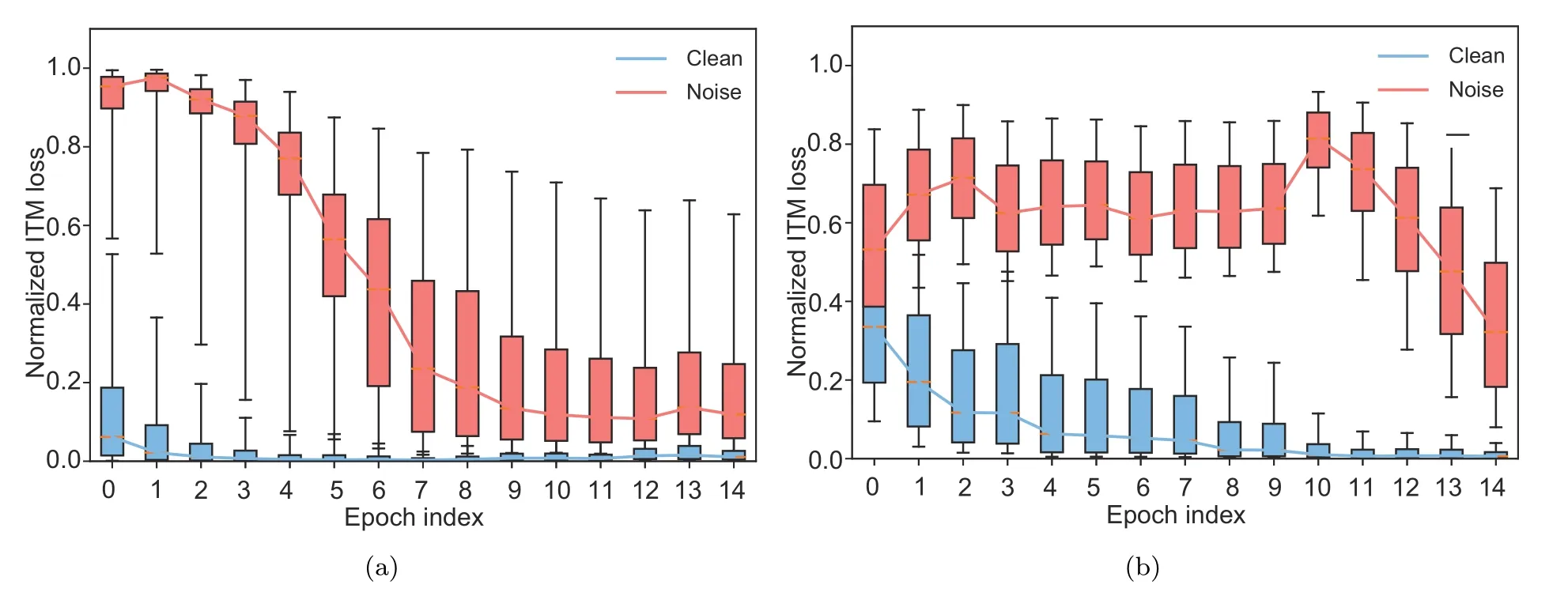
Fig.4 Visualization of the effect of multi-task learning(MTL):(a)without MTL;(b)with MTL(the refurbisher is not involved)
Meanwhile,as shown in Fig.5a,we visualize the effect of the refurbisher.By fitting the sample losses to a beta mixture distribution,we can find the following: (1)The loss of most noisy instances is larger than the loss of the clean instances.(2) The sample losses are clustered into two classes,with the small mean value being the clean cluster(blue curve)and the larger mean value being the noisy cluster(gray curve).

Fig.5 Visualization of the refurbisher’s effect (a),t-SNE result of RCAR (b),and t-SNE result of SCAN (c).In (a),the x-axis is the normalized loss values.The left scale of the y-axis is the sample number of the loss values in different intervals corresponding to the histogram and the right scale is the probability density for the given loss values corresponding to the three curves.In (b),most of the noise-alignment data are clustered into the negative category.In (c),SCAN overfits the noise,and most of the noise-alignment data are clustered into the positive category.References to color refer to the online version of this figure
At-distributed stochastic neighbor embedding(t-SNE) figure is often used to visualize the data distribution by the downscaling technique (van der Maaten and Hinton,2008),and we demonstrate the distribution of training data,as shown in Fig.5b.Note that to use the large amount of image-text multi-modal data with noise (i.e.,data from the Web),the influence of noise-aligned image-text pairs must be reduced.In other words,in the noise crossmodal retrieval task,the term “noisy data” refers to negative samples that are incorrectly marked as positive.We construct these data by randomly replacing the aligned text (or image) with an incorrectly aligned text (or image).Therefore,noisy data are negative samples in fact.Figs.5b and 5c demonstrate the data distribution after dimensionality reduction by the t-SNE method,revealing the following: (1) For the SCAN method,most of the noisy samples and positive samples are clustered into one class,which shows that SCAN overfits the noisy data and has poor robustness.(2)For our RCAR method,a large amount of noisy data and a large number of negative samples are clustered into one class,which illustrates that our model does not overfit the noisy data in the end,demonstrating the robustness of our model.
Fig.6 illustrates the qualitative results of text retrieval for the given image queries.Most of the retrieved sentences are correct(shown as tick).Some outputs are mismatched (shown as fork),but reasonable,for example,4 in Fig.6b and 4 in Fig.6c contain similar semantic meaning to the image.On the other hand,there are semantically incorrect outputs such as 5 in Fig.6a,possibly due to the influence of noise-alignment data.Fig.7 shows the qualitative results of image retrieval for the given sentence queries.Each sentence corresponds to a ground-truth image.For each sentence query,we display the top-three retrieved images,ranking from left to right.As indicated in these examples,our model retrieves the ground-truth image successfully and other top-ranking results are also reasonable.

Fig.6 Qualitative results of text retrieval for the given image queries.For each image query,we show the top-five ranked sentences (or expressions) in (a)-(d).We observe that our RCAR retrieves the correct results in the top-ranked sentences.References to color refer to the online version of this figure

Fig.7 Qualitative results of image retrieval for the given sentence queries.For each sentence query,we show the top-three ranked images,ranking from left to right.We outline the true matches in green boxes and false matches in red boxes.References to color refer to the online version of this figure
5 Conclusions
This paper presented the RCAR method for robust cross-modal retrieval with noise alignment.It combines the noise classification theory with MTL,increasing the model’s robustness by adaptively refurbishing the label of the noise-alignment data in cross-modal learning.Experimental results showed that RCAR has better performance than the current popular methods on two types of noise-alignment data.
Contributors
Jinyi GUO and Jieyu DING designed the research.Jinyi GUO processed the data and drafted the paper.Jieyu DING helped organize the paper.Jinyi GUO and Jieyu DING revised and finalized the paper.
Compliance with ethics guidelines
Jinyi GUO and Jieyu DING declare that they have no conflict of interest.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
 Frontiers of Information Technology & Electronic Engineering2023年10期
Frontiers of Information Technology & Electronic Engineering2023年10期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Towards robust neural networks via a global and monotonically decreasing robustness training strategy∗
- Federated mutual learning: a collaborative machine learning method for heterogeneous data,models,and objectives∗
- A knowledge-guided and traditional Chinese medicine informed approach for herb recommendation∗
- Attention-based efficient robot grasp detection network∗
- RFPose-OT:RF-based 3D human pose estimation via optimal transport theory∗
- Synchronization transition of a modular neural network containing subnetworks of different scales*#