
RFPose-OT:RF-based 3D human pose estimation via optimal transport theory∗
2023-11-06 06:14CongYUDonghengZHANGZhiWUZhiLUChunyangXIEYangHUYanCHEN
Cong YU ,Dongheng ZHANG ,Zhi WU ,Zhi LU ,Chunyang XIE ,Yang HU,Yan CHEN‡
1School of Information and Communication Engineering,University of Electronic Science and Technology of China,Chengdu 611731,China
2School of Cyber Science and Technology,University of Science and Technology of China,Hefei 230026,China
3School of Information Science and Technology,University of Science and Technology of China,Hefei 230026,China
Abstract: This paper introduces a novel framework,i.e.,RFPose-OT,to enable three-dimensional(3D)human pose estimation from radio frequency (RF) signals.Different from existing methods that predict human poses from RF signals at the signal level directly,we consider the structure difference between the RF signals and the human poses,propose a transformation of the RF signals to the pose domain at the feature level based on the optimal transport(OT) theory,and generate human poses from the transformed features.To evaluate RFPose-OT,we build a radio system and a multi-view camera system to acquire the RF signal data and the ground-truth human poses.The experimental results in a basic indoor environment,an occlusion indoor environment,and an outdoor environment demonstrate that RFPose-OT can predict 3D human poses with higher precision than state-of-the-art methods.
Key words: Radio frequency sensing;Human pose estimation;Optimal transport;Deep learning
1 Introduction
Due to the non-contact and privacy-preserving characteristics of radio signals,radio frequency(RF)based human sensing tasks have drawn increasing attention in recent years.Existing signal processing based wireless sensing works include mainly human vital sign monitoring (Conte et al.,2010;Yue et al.,2018;Zhang DH et al.,2019,2020),gesture recognition(Niu et al.,2022),human gait authentication(Ji et al.,2021),human position tracking(Kotaru et al.,2015;Rampa et al.,2015;Zhang DH et al.,2018,2021;Chen Y et al.,2020;Ito and Godsill,2020),and human speed estimation(Qian et al.,2018;Zhang F et al.,2018).With the development of deep learning,some learning-based methods (Kim and Park,2018;Chen Y et al.,2021;Li YD et al.,2021;Zhang BB et al.,2021;Qiu et al.,2022)have been proposed to handle wireless sensing tasks.
In addition to the above classic wireless sensing tasks,some researchers (Zhao et al.,2018a,2018b;Li TH et al.,2019;Wang F et al.,2019;Jiang et al.,2020;Song et al.,2022;Wu et al.,2022;Yu et al.,2022) have explored using RF signals to perceive human movements finely based on deep learning methods,e.g.,designing deep learning models to construct fine-grained human poses from radio signals.Specifically,Zhao et al.(2018b) proposed a teacher-student network model to estimate two-dimensional (2D) human poses from frequency modulated continuous wave(FMCW)signals.Wang F et al.(2019) used a U-Net model to generate 2D human pose heatmaps from Wi-Fi signals.Taking this one step further,a three-dimensional (3D) human pose estimation model based on RF signals was proposed in Zhao et al.(2018a),where the pose estimation task was regarded as a keypoint classification problem in the 3D space.Wi-Fi-based 3D pose reconstruction has been explored in Jiang et al.(2020).
Although achieving promising performance,existing RF-based human pose estimation methods transform RF signals to human poses at the signal level directly,ignoring the structure difference between RF signals and human poses;i.e.,the RF signals record human activities based on the signal reflections that are processed as signal projection heatmaps,while target human poses are represented as skeletons in the real physical space based on the human visual system.Therefore,in our work,as shown in Fig.1,we pay more attention to the feature level,propose RFPose-OT to transform RF signals to the target pose feature domain based on the optimal transport (OT) theory,and then generate pose keypoints from the transformed features.Specifically,three phases are designed to train RFPose-OT: (1)We first train a pose encoder and a keypoint predictor to obtain target human pose representations in the feature space with the supervision of groundtruth keypoints;(2)Then,an RF encoder is trained to transform RF signals to the target pose feature domain using the OT distance(defined through the OT theory)as the training loss;(3)Finally,we fine-tune the RF encoder and the keypoint predictor using ground-truth keypoints for fine-grained estimation.Note that during RFPose-OT inference,the pose encoder can be removed,and only the RF encoder and the keypoint predictor are used for 3D human pose estimation.

Fig.1 RFPose-OT transforms the radio frequency (RF) signals to the pose domain to enable fine-grained three-dimensional (3D) human pose estimation
To evaluate RFPose-OT,we build a radio system to capture the horizontal and vertical RF signals,which are preprocessed to the RF heatmaps.The ground-truth human pose keypoints are obtained using a multi-view camera system.In both basic and occlusion indoor environments,we compare our proposed RFPose-OT with state-of-the-art methods and also conduct ablation studies.We further test RFPose-OT in an outdoor environment.The experimental results demonstrate that RFPose-OT can predict 3D human poses with high precision and outperform the alternative methods.
2 Related works
With the popularity of radio devices,recent years have witnessed more and more interest in using radio signals to deal with sensing tasks (He Y et al.,2020).
2.1 Classical wireless human sensing
Based on signal processing algorithms,some researchers (Patwari et al.,2014;Zhang DH et al.,2019) have tried to monitor human vital signs such as breathing by analyzing the heaving chest through radar or Wi-Fi signals.In an indoor environment,some researchers focused on localization (Majeed et al.,2016) and tracking issues (Zhang DH et al.,2018,2021;Wang L et al.,2021) and others attempted to estimate human speed from radio signals (Qian et al.,2018;Zhang F et al.,2018).Furthermore,some works tried to identify humans(Zeng et al.,2016;Hsu et al.,2019) or recognize gestures (Niu et al.,2022) from radio signals based on signal processing technologies.
Meanwhile,deep learning methods have made remarkable achievements in many areas (LeCun et al.,2015;Li J,2018;Zhang QS and Zhu,2018;Ma et al.,2021;Yang et al.,2021;Liu et al.,2022).Therefore,in addition to using signal processing methods,more and more researchers have explored designing deep learning frameworks to push the limit of radio sensing tasks.For example,Zhao et al.(2017) constructed a conditional adversarial architecture to monitor sleep stages from radio signals via convolutional and recurrent neural networks.Xu et al.(2022) enabled human breath detection from acoustic signals in noisy driving environments by training a deep learning model.Taking this a step further,deep neural networks can learn electrocardiograms from millimeter wave (mmWave) signals (Chen JB et al.,2022).In addition to the above coarse-grained human perception,many finergrained sensing tasks,such as human pose estimation,have been explored recently.
2.2 Human pose estimation
Before using radio signals to infer human poses,human pose estimation was a well-studied problem in computer vision literature (Wei et al.,2016;Cao et al.,2017;Fang et al.,2017;He KM et al.,2017;Martinez et al.,2017;Zheng et al.,2021).However,vision-based human pose estimation methods often suffer from occlusion or bad illumination,whereas radio signals can traverse occlusion and do not rely on lights.Hence,radio-based human pose estimation has a wider range of application scenarios and has drawn increasing attention.For example,Zhao et al.(2018b) designed a teacher-student network model to estimate 2D human poses from FMCW signals with the supervision of a vision-based human pose estimation model,and further extended the 2D version to the 3D version to achieve 3D human pose construction in Zhao et al.(2018a).After that,Li TH et al.(2019) used FMCW signals to recognize human actions based on the human pose estimation results.Efforts have been made to use Wi-Fi signals to predict human poses,including 2D(Wang F et al.,2019) and 3D (Jiang et al.,2020) human pose estimation.RF-based human pose segmentation (Wu et al.,2022) and visual synthesis (Yu et al.,2022)have been explored recently.
However,the above methods usually follow the technologies in computer vision literature to predict human poses from radio signals directly,ignoring the structural difference between radio signals and human poses.Thus,we propose to first transform radio signals to the pose feature domain based on the OT theory (Monge,1781;Kantorovich,1942),and then predict human poses.
The OT-based pose estimation method has been explored in Zhou et al.(2020),as an image-based human pose estimation work,where the human pose in the optical image has the same structure as the target human pose skeleton.In contrast,human pose information embedded in the RF signals is obscure and is divided into horizontal and vertical planes,with a totally different structure from the target human pose skeleton.Thus,RF-based 3D human pose estimation is a cross-domain problem,and thus is a much more challenging task than the image-based one,and the OT-based method is much more suitable for this cross-domain task.
3 Primer of optimal transport theory
In this study,we use the OT distance to train our model,which is defined through the OT theory.OT theory discusses the problem of how to transport one distribution to another with the lowest cost,where the transport map is defined as follows:
Definition 1MapT:Ω →Ψtransports measureμ ∈P(Ω) to measureν ∈P(Ψ),and we callTa transport map,if for allν-measurable setsB,Eq.(1)holds:
Fig.2 visualizes the transport map,whereA={z|z ∈Ω,T(z)∈B},soμ(A)=ν(B).Further,we define a cost functionC:Ω×Ψ →[0,+∞] to indicate the transportation cost,and the overall transportation cost fromμtoνcan be expressed using the Monge formulation(Monge,1781)as
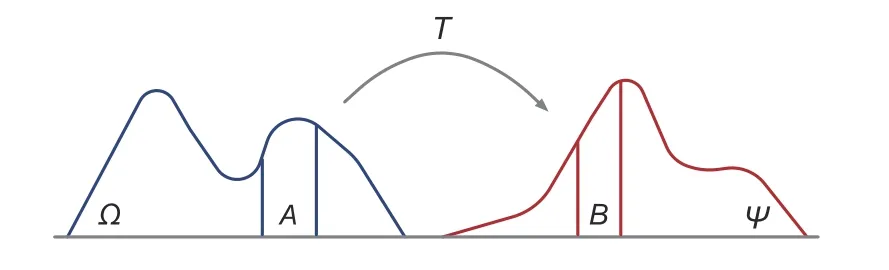
Fig.2 Transport map
OT theory finds a transport mapT†to determine the minimum transportation costM(T).Assume that there exists a transport mapT†.Then the minimum costM(T†) can be defined as the OT distance betweenμandνin the geometric space.IfM(T†)=0,we think thatΩandΨhave the same distribution.
The generalization of the Monge formulation is the Kantorovich formulation(Kantorovich,1942):
wherez ∈Ωand ˆz ∈Ψ,andγdenotes the transport map fromΩtoΨ,which is subject to
for all measurable setsA ⊆ΩandB ⊆Ψ.Then,assuming that the optimal transport mapγ†exists,K(γ†)is the OT distance.
4 RF signal collection and preprocessing
We use mmWave radar with multiple-input multiple-out (MIMO) antenna arrays to transceive RF signals.The received signals can be expressed as
wherem,n,l,andtdenote the indices of the receiver antenna,frequency point,signal propagation path,and time,respectively,al(t)is the complex attenuation coefficient,andψl,m,n(t)andφl,m,n(t)are the phase shifts,which can be expressed as
whereθl,m(t) denotes the angle of arrival (AoA),τl,m(t)denotes the time of flight(ToF),dis the interelement distance of the antenna array,andcis the signal propagation speed.
Human poses are often defined in the rectangular coordinate system.Thus,as shown in Fig.3,we transform the received signals to the spatial domain:
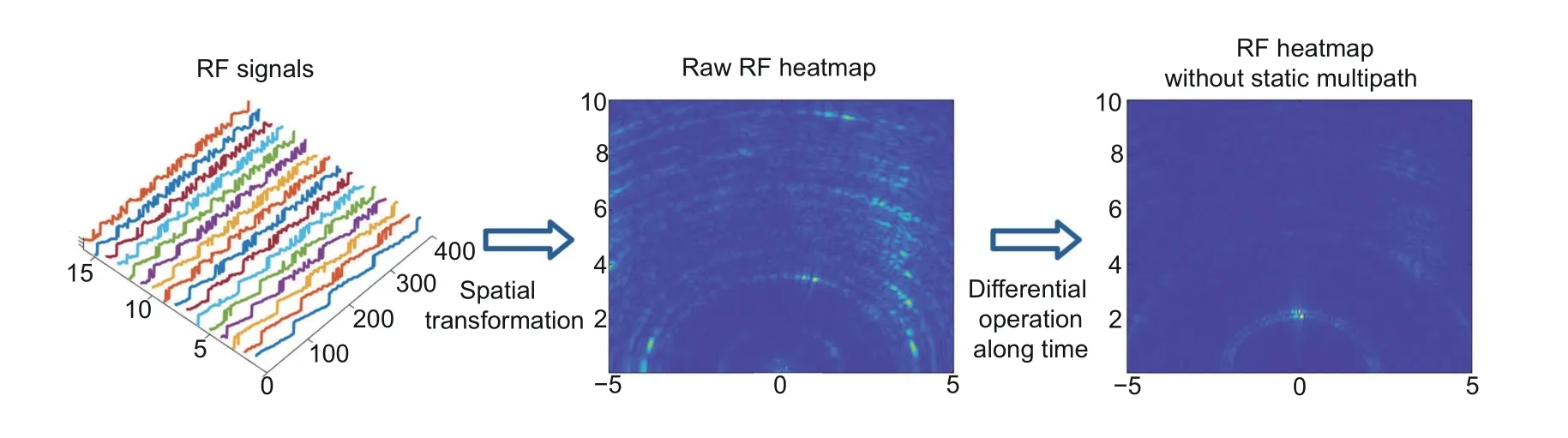
Fig.3 Radio frequency (RF) signal preprocessing
where ej2πφ(x,y,m) is the phase shift determined by the spatial positions of the signal and the antenna.Sis the RF heatmap that represents the signals in the rectangular coordinate system.According to the analysis in Zhang DH et al.(2021),there exists a static multipath in the raw RF heatmap.Therefore,we further apply the differential operation onSx,y(t)along timetto remove the static multipath.
In our work,we use two mmWave radars to obtain RF heatmaps on the horizontal and vertical planes,separately,which are denoted asSHandSVin the following sections.
5 RFPose-OT
We propose a novel framework,i.e.,RFPose-OT,to enable 3D human pose estimation based on RF heatmapsSHandSV.In the following,we first introduce the problem setup and explain the motivation for RFPose-OT.Then we discuss the network structures and the model training of RFPose-OT.
5.1 Problem setup
RFPose-OT aims to predict 3D human poses from the horizontal and vertical RF heatmaps.Because human poses can be constructed using some body keypoints,the objective of RFPose-OT is to generate the 3D coordinates of the keypoints:
Although RF signals have been transformed to the spatial domain,from Fig.4,we can see thatSHandSVstill have a totally different representation of the human pose compared with the human pose skeleton which is based on the human visual system;i.e.,the RF heatmaps and the human poses belong to two different feature domains,and predicting keypoints from RF heatmaps directly may be difficult.
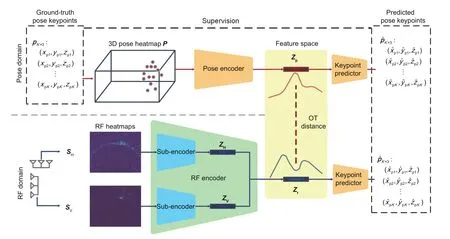
Fig.4 The RFPose-OT architecture which consists of a pose encoder,a radio frequency (RF) encoder,and a keypoint predictor.Once trained,only the RF encoder and the keypoint predictor are retained to predict 3D human poses from RF heatmaps
To tackle the above limitation,RFPose-OT tries to encode the RF heatmaps to the target pose domain.Specifically,as shown in Fig.4,we first learn the human pose embedding based on ground-truth human poses,and then train an RF encoder to transform the RF heatmaps to the human pose embedded space using the OT distance as the training loss.Finally,the RF encoder and the keypoint predictor are fine-tuned to generate target human pose keypoints.Note that once trained,the pose encoder can be removed and only the RF encoder and the keypoint predictor are needed in the inference phase.
5.2 Pose embedding
To obtain a representation of the human pose in the pose domain,as shown in Fig.4,we draw a 3D pose heatmap based on the ground-truth pose keypoint coordinates.Specifically,for each keypoint,we synthesize a 3D point heatmap using the Gaussian kernel function as follows:
wherekdenotes the index of the keypoint,andxpk,ypk,andzpkdenote the coordinates of thekthkeypoint of the pose on thex,y,andzaxes,respectively.After that,we combine all 3D point heatmaps to obtain the 3D pose heatmap:
Prepresents the human pose in the 3D physical space.Then,a pose encoder is followed to map the 3D pose heatmapPto the pose feature vectorZpin the pose domain:
whereEPdenotes the pose encoder,andZpis a manifold embedding code that contains the keypoint location information and the spatial relationship between the keypoints.Finally,a keypoint predictor is designed to transform the pose feature vectorZpto the pose keypoint coordinates:
Obviously,the predicted keypoint coordinatesK×3fromPshould be the same as the groundtruth pose keypoint coordinates.Hence,we train the pose encoder and the keypoint predictor using the following two measurements:
5.3 Transporting radio frequency to pose
After pose embedding,with the parameters of the pose encoder and the keypoint predictor being fixed,we design an RF encoder to map the RF heatmaps to the RF feature vector.Specifically,as shown in Fig.4,the RF encoder contains two subencoders to encode the horizontal and vertical RF heatmaps separately.Then the extracted RF representationsZHandZVare fused and mapped to the RF feature vectorZr:
whereERdenotes the RF encoder,andZrhas the same dimension as the pose feature vectorZp.
Considering the geometry of the feature spaces,i.e.,the RF feature space Zrand the pose feature space Zp,we use the OT distance (recall the primer in Section 3)to assess the divergence between them.Specifically,assume thatμrandμpare probability measures on spaces Zrand Zprespectively,and letC: Zr×Zp→[0,+∞] be a cost function whereC(Zr,Zp)measures the cost of transporting one unit of mass fromZr∈ZrtoZp∈Zp,based on Kantorovich’s OT theory.The OT distance can be expressed as
whereγ ∈P(Zr,Zp) denotes the optimal transport map,indicating the amount of mass transported fromZrtoZpand satisfying the following marginal constraints:
5.4 Fine-tuning
After transporting the RF domain to the pose domain,we can estimate the pose keypoint coordinates fromZrusing the keypoint predictor:
For better human pose estimation,we further fine-tune the RF encoder and the keypoint predictor.The objective functions are similar to Eqs.(14) and(15),whereK×3is replaced byK×3:
The whole training and fine-tuning procedure is described in Algorithm 1.
5.5 Inference setting
After training,the 3D pose heatmap and its embeddingZp,as well as the corresponding pose encoder,can be removed,and only the trained RF encoder is needed to estimateZrfrom the RF heatmaps.Because the RF encoder has been trained,it can directly map the RF heatmaps to the pose domain,and then the outputZris inputted into the keypoint predictor to estimate the pose keypoint coordinates.

6 Experiments
In this section,we describe first the implementation details and then the experiments conducted to evaluate the performance of the proposed RFPose-OT.
6.1 Dataset
To collect RF signal data,we built a radio system using two mmWave radars (horizontal and vertical),where each radar was equipped with 12 transmitters and 16 receivers with a MIMO antenna array.To avoid mutual interference,one radar worked at 77 GHz while the other worked at 79 GHz,both with a 1.23 GHz bandwidth.To obtain the groundtruth human poses,we built a multi-view camera system with 13 camera nodes,and a calibration method (Zhang Z,2000) was applied to obtain the ground-truth 3D pose keypoint coordinates.
During data collection,we captured the RF signal reflections at 20 Hz,and the camera system recorded videos at 10 frames per second.The radio system and the camera system were synchronized using the network time protocol(NTP)through transmission control protocol (TCP) connection,which achieved a millisecond-level synchronization error.We collected the data for 10 indoor scenes.In total,we collected 89 090 RF signal samples and obtained the corresponding 3D pose keypoint coordinates,80% of which were used for training and the rest for testing.
Because RF signals can traverse occlusions,we collected more data in the occlusion environment as the additional testing set,where the radio system was occluded by baffles.Then 1180 RF signal samples were collected and the corresponding groundtruth poses were obtained by the camera system.
6.2 Network structure
RFPose-OT includes a pose encoder,an RF encoder,and a keypoint predictor.
The pose encoder consists of five convolutional layers and one linear layer.The RF encoder contains two sub-encoders with the same network structure,and each sub-encoder consists of six convolutional layers.The keypoint predictor consists of four linear layers.Details of these network structures are shown in Tables 1-3,where conv denotes the convolution layer,linear denotes the linear layer,BN denotes batch normalization,LN denotes layer normalization,ReLU denotes the rectified linear unit,ks denotes the kernel size,cs denotes the number of channels,and st denotes the stride.
6.3 Training details
RFPose-OT was trained using the Adam solver.The numbers of epochs for pose embedding training and RF transporting training were both 100,and the number of epochs for fine-tuning was set to 50.The initial learning rate was set to 0.002 and decayed by half every 10 epochs for all training phases.The batch size during model training was always 64.We implemented our proposed RFPose-OT using PyTorch and all experiments can be run on a commodity workstation with a single GTX-1080 graphics card.
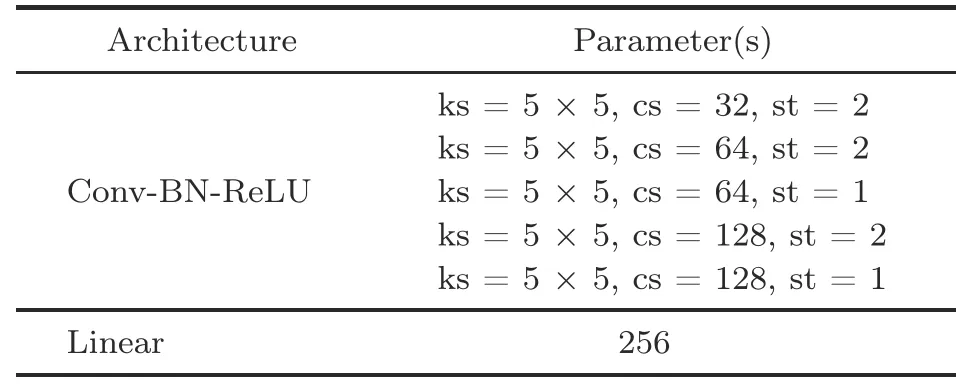
Table 1 Pose encoder

Table 2 Sub-encoder in the RF encoder

Table 3 Keypoint predictor
6.4 Metric
To assess the precision of human pose estimation,we calculated the spatial location error(SLE) between the predicted keypoints and the corresponding ground-truth keypoints using the Euclidean distance:
wherekdenotes the keypoint index,andUis the number of test samples.
So the king was forced to unlock13 the door, and the next and the next and the next, till all seven were open, and they entered into the hall where the twelve maidens were standing20 all in a row, so like that none might tell them apart
6.5 Comparison with baselines
We compared our proposed RFPose-OT with RF-Pose3D(Zhao et al.,2018a)and mm-Pose(Sengupta et al.,2020).
1.RF-Pose3D: RF-Pose3D is a classic deep learning model for 3D human pose estimation from RF signals.It regards pose estimation as a keypoint classification problem and is constructed using 18 convolution layers.
2.mm-Pose: mm-Pose is a real-time 3D human pose estimation model based on mmWave radars.It consists of six convolution layers and four linear layers,and predicts the coordinates of human pose keypoints from the horizontal and vertical RF signals directly.
The quantitative comparison results are summarized in Table 4 in the basic environment,from which we can find that RFPose-OT outperformed baseline methods in almost all pose keypoints,and achieved much higher estimation precision in small body parts,e.g.,wrists and ankles,which means that the pose perception of our proposed RFPose-OT is much more fine-grained.We also show the qualitative results in Fig.5a,from which we can see that although RF-Pose3D and mm-Pose can predict correct human locations,inaccurate poses were generated,whereas RFPose-OT can generate target 3D human poses that were consistent with ground truth.
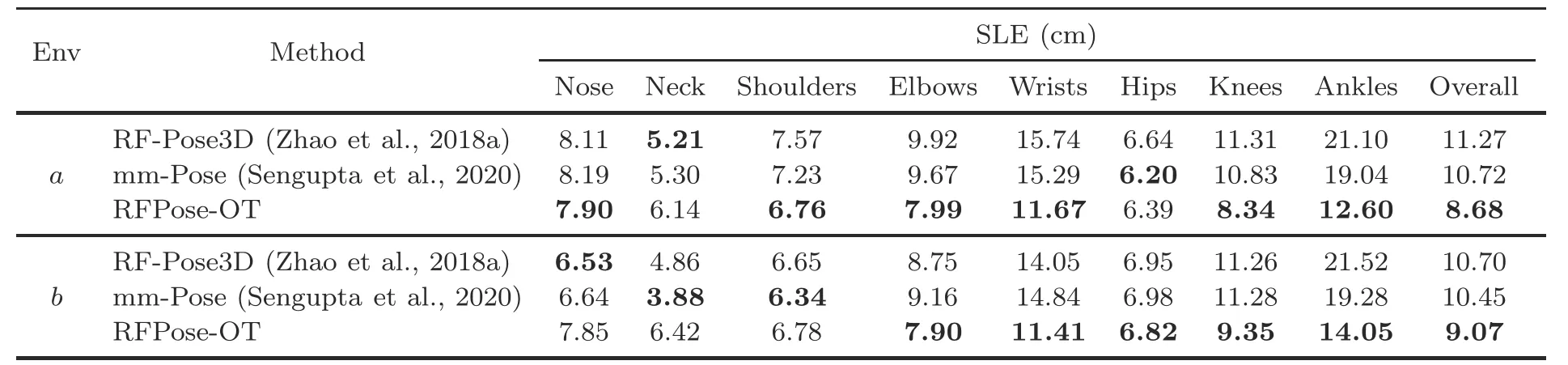
Table 4 Quantitative evaluation results of different methods in the basic a and occlusion b indoor environments
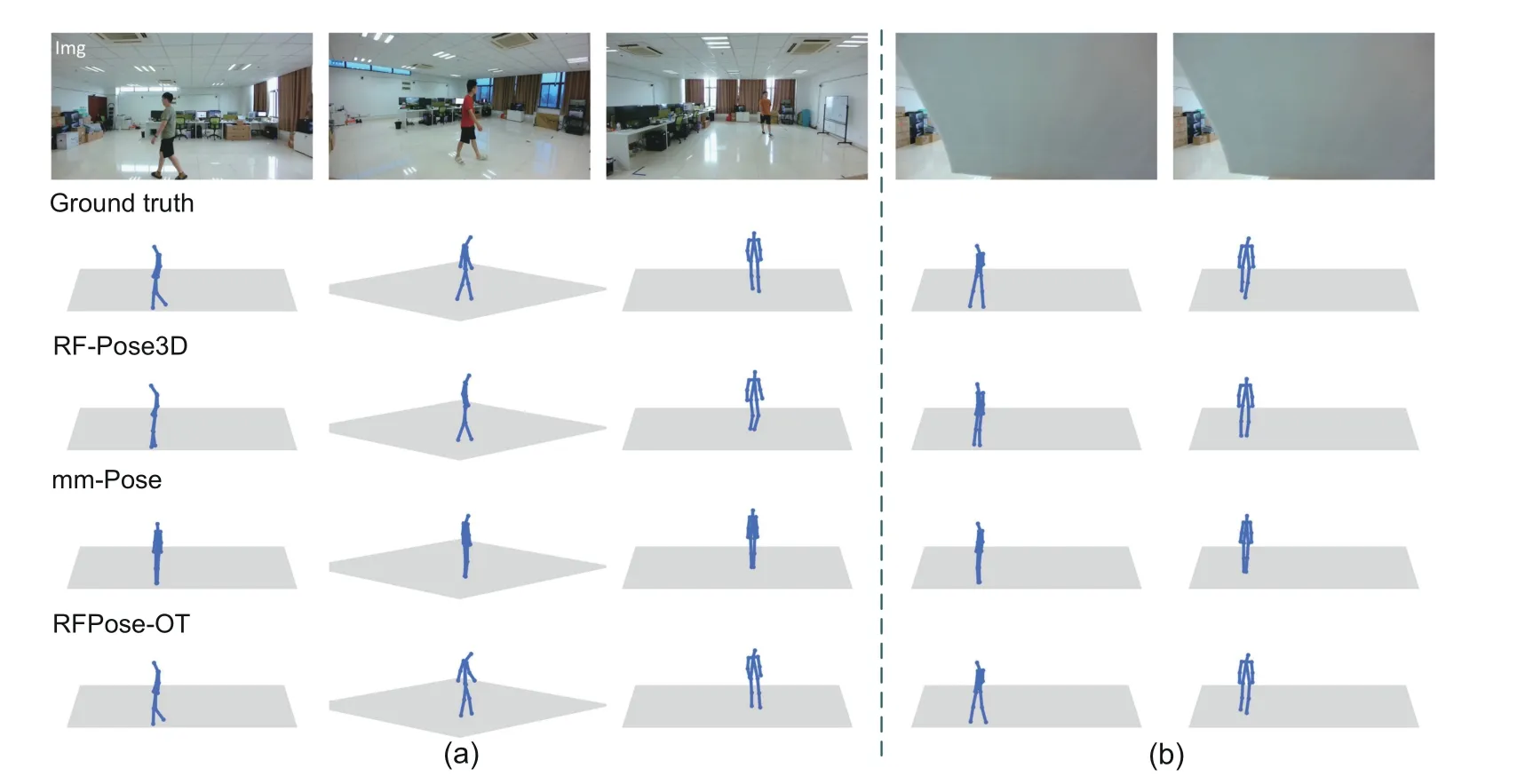
Fig.5 Qualitative results of different methods in the basic (a) and occlusion (b) indoor environmentsThe 1st row shows the images captured by a camera that is attached to the radio system,the 2nd row shows the groundtruth 3D human poses,and the 3rd,4th,and 5th rows show the 3D human poses estimated by RF-Pose3D (Zhao et al.,2018a),mm-Pose (Sengupta et al.,2020),and our proposed RFPose-OT,respectively
Compared with the vision-based pose estimation method,the RF-based pose estimation model can work in the occlusion environment.Thus,we further tested RFPose-OT and the baseline methods using an additional testing set that was collected in the occlusion environment.The quantitative and qualitative results are shown in Table 4 and Fig.5b,from which we can see that RFPose-OT can still estimate 3D human poses from RF signals with high precision and outperformed alternative methods.The above experimental results demonstrated the effectiveness of our proposed RFPose-OT model in the occlusion environment.
6.6 Ablation studies
In this subsection,we report our ablation experiments to discuss the effects of some components in the RFPose-OT model.
1.RFPose: In our full RFPose-OT model,an OT lossLOTwas designed for training the RF encoder to enable the transformation from the RF domain to the pose domain.The ablation native model RFPose removes this component;i.e.,RFPose predicts pose keypoints from the RF heatmaps directly.
3.RFPose-OT withoutLPO+RO: In the pose embedding and fine-tuning phases,LPOandLROare proposed to pay more attention to the relative human poses.In RFPose-OT withoutLPO+RO,we discuss the effects ofLPOandLRO.
The quantitative evaluation results in the basic and occlusion environments are shown in Table 5,from which we can see that the OT-based model RFPose-OT and the L2-based model RFPose-L2 both outperformed the native version RFPose;i.e.,transforming the RF domain to the pose domain first and then predicting pose keypoints can improve the pose estimation precision.RFPose-OT performed better than RFPose-L2,because it can achieve higher estimation precision than RFPose-L2 in all pose keypoints in the occlusion environment.The above experimental results demonstrated that mapping the RF signals to the pose feature space can improve the performance,and that using the OT distance outperforms the use of the L2 distance,which validates the advantage of the proposed OT-based method.Furthermore,compared with RFPose-OT withoutLPO+RO,the full RFPose-OT model performed better,which means thatLPOandLROcontribute to the pose estimation.
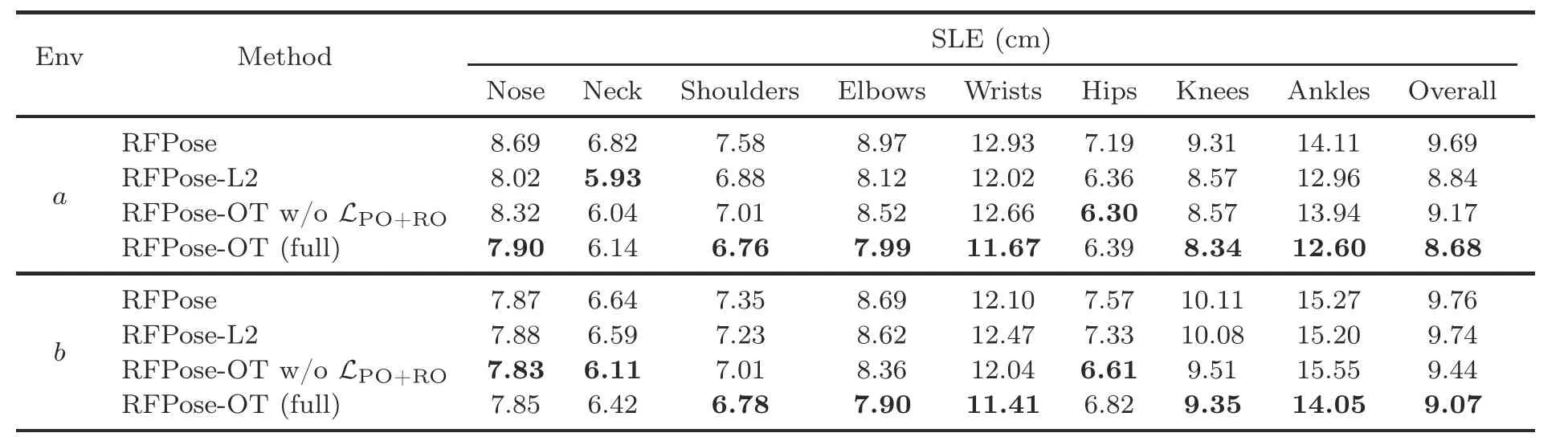
Table 5 Quantitative evaluation results of different ablation models and the full model in the basic a and occlusion b indoor environments
6.7 Performance in the outdoor scene
Even though the RFPose-OT model was trained in the indoor environment,we directly applied it to a new outdoor environment to evaluate its generalization.Because it is difficult to move the multiview camera system to the new scenario to provide ground-truth poses,here we qualitatively evaluated only performance.Fig.6 shows the 3D poses generated by our model and the corresponding snapshots,from which we can see that our model can correctly estimate 3D human poses from RF signals in the outdoor environment.This confirms the crossenvironment generalization ability of RFPose-OT.

Fig.6 Qualitative results by RFPose-OT in an outdoor environment
7 Discussion
7.1 Model complexity
In this subsection,we calculated the number of parameters and the number of multiply-accumulate operations(MACs)to evaluate the complexity of our proposed RFPose-OT,and further tested RFPose-OT on a single GTX-1080 graphics card to calculate the average runtime for predicting one frame of human pose from RF signals.The results are shown in Table 6,from which we can see that RFPose-OT can support real-time processing.

Table 6 Model complexity and runtime
7.2 Trajectory tracking
RFPose-OT is a fine-grained human activity sensing framework.Obviously,it can be used for handling some classic wireless sensing tasks,e.g.,tracking a moving person.In this subsection,we used the trained RFPose-OT to track a subject who was asked to walk randomly in the basic and occlusion scenes.The ground-truth trajectories were obtained by the multi-view camera system.RF signals were inputted into RFPose-OT,and we calculated the average value of the horizontal coordinates of the output keypoints as the predicted trajectories.The quantitative errors are shown in Table 7,and the qualitative results are shown in Fig.7,from which we can see that RFPose-OT can recover the moving trajectories in both basic and occlusion indoor environments.

Fig.7 Trajectories of a moving person in the basic environment (a,b) and occlusion environment (c)
7.3 Scope and limitations
Experimental results demonstrated the effectiveness of RFPose-OT in basic and occlusion environments.However,RFPose-OT has some limitations.On one hand,the operating distance of our radio system was limited to 20 m.Extra transmission power would be needed to cover a larger space.On the other hand,micro hand motions may be missed by RFPose-OT due to few signal power reflections.
8 Conclusions
In this paper,we proposed a novel RF-based 3D human pose estimation model,RFPose-OT,which first transports the RF domain to the target pose domain based on the OT theory,and then estimates human pose keypoints from the transported RF features.To assess RFPose-OT,we conducted experiments in both basic and occlusion indoor environments and an outdoor environment,and the experimental results demonstrated that our proposed RFPose-OT can estimate 3D human poses with higher precision.We believe that this work provides a new and valid framework to tackle RF-based human sensing tasks.
Contributors
Cong YU and Yan CHEN conceived the method.Cong YU designed and implemented the RFPose-OT model.Cong YU and Zhi LU performed the experiments and conducted the comparisons.Dongheng ZHANG,Zhi WU,and Chunyang XIE collected and processed the data.Cong YU drafted the paper.Yang HU and Yan CHEN helped organize the paper.Yan CHEN supervised all aspects of the project.All authors contributed to designing the experiments and revising and finalizing the paper.
Compliance with ethics guidelines
Cong YU,Dongheng ZHANG,Zhi WU,Zhi LU,Chunyang XIE,Yang HU,and Yan CHEN declare that they have no conflict of interest.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
 Frontiers of Information Technology & Electronic Engineering2023年10期
Frontiers of Information Technology & Electronic Engineering2023年10期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Towards robust neural networks via a global and monotonically decreasing robustness training strategy∗
- Federated mutual learning: a collaborative machine learning method for heterogeneous data,models,and objectives∗
- Robust cross-modal retrieval with alignment refurbishment∗
- A knowledge-guided and traditional Chinese medicine informed approach for herb recommendation∗
- Attention-based efficient robot grasp detection network∗
- Synchronization transition of a modular neural network containing subnetworks of different scales*#