
基于大数据挖掘的公共图书馆少儿阅读推荐方法
2024-02-24 13:30谢潘佳
河南图书馆学刊 2024年1期


收稿日期:2023-12-10
作者简介:谢潘佳(1983— ),绍兴市越城区图书馆馆员。
摘 要:文章针对当前公共图书馆少儿阅读推荐服务中存在的问题,研究了基于大数据挖掘的公共图书馆少儿阅读推荐方法,通过对比实验的方式证明了该方法的优越性,即对于少儿和少儿家长偏好度的提升效果更好,且能在满足少儿阅读需求的基础上引导少儿养成良好的阅读习惯。
关键词:大数据挖掘;公共图书馆;少儿阅读;推荐方法
中图分类号:G258.2 文献标识码:A 文章编号:1003-1588(2024)01-0013-03
公共图书馆是开展阅读推广的重要机构,承担着培养少儿阅读习惯,提升其阅读能力的重要责任。在多元化时代背景下,少儿的阅读环境发生了翻天覆地的变化,阅读资源丰富,少儿的阅读需求越来越多元化、个性化[1]。与成年人相比,少儿的阅读能力和理解能力较弱[2],难以阅读理论性较强或层次较深的图书。因此,公共图书馆在为少儿读者推荐阅读资源的过程中,应积极利用大数据、云计算等现代化技术手段寻找适合其阅读的资源[3]。大数据技术中的大数据挖掘是指利用特定算法深度挖掘隐藏信息,常被应用于计算机、医学、经济等领域,成效显著,但在公共图书馆领域的研究和应用案例较少。
1 基于大数据挖掘的公共图书馆少儿阅读推荐方法
1.1 公共图书馆少儿阅读资源的获取与处理
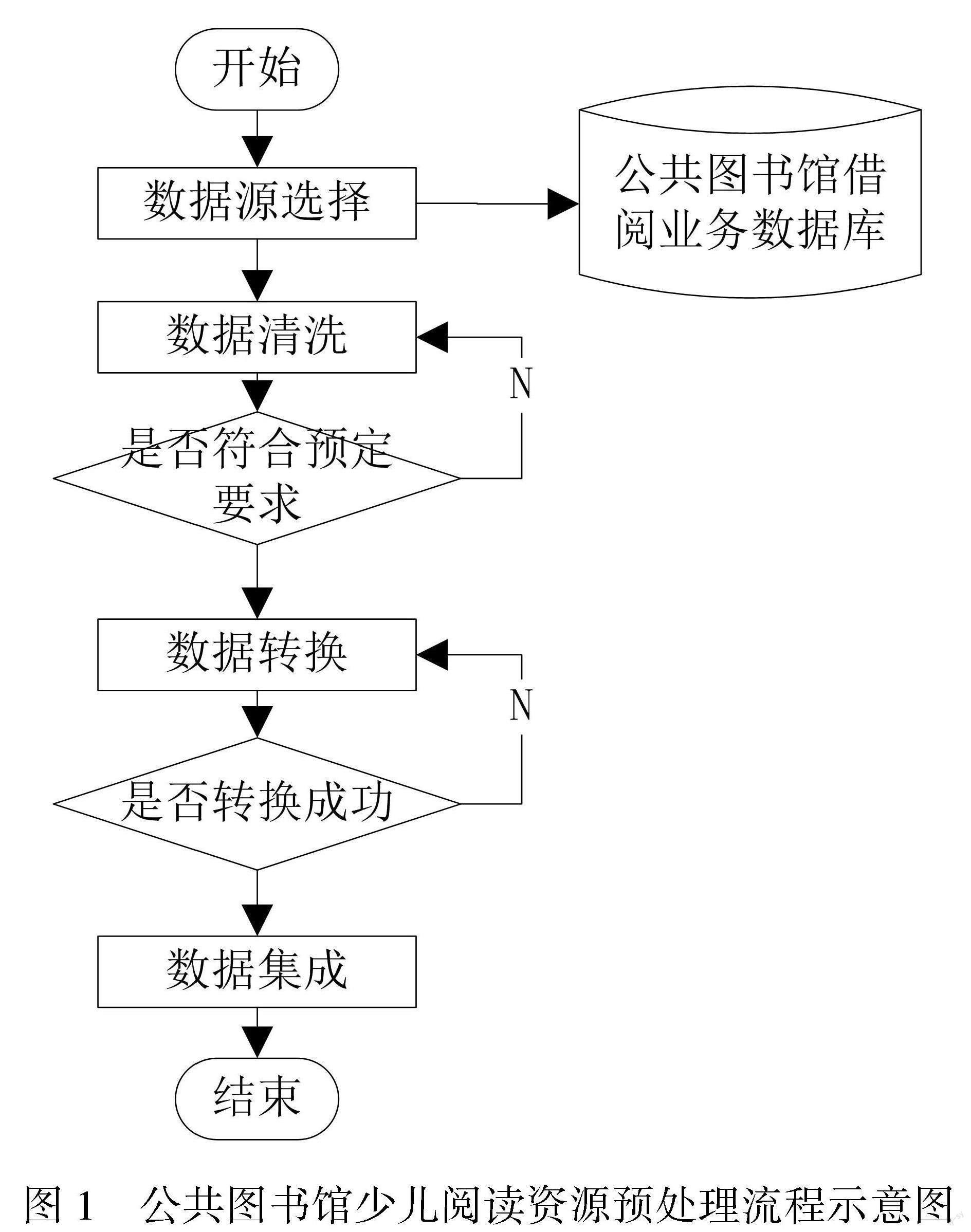
为了保障少儿阅读推荐服务的质量,公共图书馆需确保相关阅读资源的数量和质量。在开展少儿阅读资源建设的过程中,公共图书馆需要对各类信息资源进行清查、转化、集成等处理,为后续开展数据信息的挖掘工作提供优质信息源,这些信息包括馆藏图书数据、读者信息、图书借阅数据等[4]。其中,馆藏图书数据是公共图书馆在日常运行过程中必不可少的数据信息,图书数据包括书名、作者等一系列图书属性信息;读者信息是少儿阅读推荐方法必须用到的关键数据,包括读者个人信息、读者借阅情况聚类分析数据等[5];图书借阅数据是取自公共图书馆借阅业务数据库的数据信息,是研究少儿读者阅读行为的关键信息。公共图书馆在获取少儿阅读资源后,应对这些资源进行相应的预处理,处理流程如图1所示。
需要注意的是,公共图书馆应对相关数据进行空值数据处置和噪音数据过滤等处理,为每一本图书设定独立的索引,并对读者信息中的空白项(空值)进行补全处理[6]。在该过程中,如果存在无法补全的问题,公共图书馆就需要清除相关数据信息,并及时清除数据源中的重复数据,以提高大数据挖掘效率。在完成数据清洗后,公共图书馆应将各类数据转换为统一的格式[7],并进行数据集成,生成少儿基础数据表、少儿节约数据表及少儿图书数据表,为大数据挖掘奠定数据资源基础。
1.2 基于大数据挖掘的少儿读者信息挖掘
公共图书馆应对少儿读者的信息进行聚类处理与分析,合理划分少儿阅读群体,科学选取符合不同少儿阅读群体阅读要求的阅读资源开展少儿阅读推荐服务。公共图书馆可按以下步骤挖掘少儿读者信息。
第一步,设置聚类个数,对已完成处理的数据源进行聚类解析,以随机的方式获取少儿读者阅读信息,利用K-means算法对数据表中的数据进行聚类和挖掘处理。王凤燕结合公共图书馆的读者借阅数据将少儿读者分为活跃型、普通型及其他类型3类[8],因此笔者将聚类K值设定为3。在分类过程中,笔者引入欧氏距离计算公式,计算不同少儿读者信息与所属分类之间的欧式距离,计算公式为:
d(x1,x2)=∑di=1(x1k-x2k)2
其中,d(x1,x2)为两个陈述属性x1和x2之间的欧氏距离,x1k和x2k为两个陈述属性的详细选值。公共图书馆根据该公式计算得出欧氏距离后,可基于聚类相关结构,重新设定k个簇,利用误差平方等对聚类特性进行评定。假设在某一数据集中,k个簇的子集分别为各个簇的样本数据,则其误差平方和的计算公式为:
E=∑ki=1‖p-m‖2
其中,E为误差平方和,p为簇的个数,m为各簇样本数目。将数据集中的所有元素按照新的中心重新完成聚类,若汇总计算得出的误差平方和不再发生明显变化,则说明已完成聚类和收敛。
第二步,在完成对准则函数是否收敛的判断后,将各类少儿读者信息进行分类存储,并通过可视化的方式进行展示。
第三步,将少儿读者聚类挖掘的行为有效值设定为k,在此过程中,应知悉k的有效取值范围会直接影响对少儿读者信息聚类的效果。如果k的最终选值较小,则会在聚类后出现簇族覆盖范围过大的问题,甚至会出现聚类结果价值性信息较少的问题;如果k的最终选值较大,则会在聚类后出现簇族覆盖范围过小的问题,导致聚类数据分散,无法得到关联性较强的数值。通常情况下,在初步完成对k的赋值后,必须通过持续调节的方式对k的值进行优化,得到一个簇间距较小的有效区间,在该区间内输出合适的k值。
1.3 基于大数据挖掘的少儿借阅信息挖掘
在完成对少儿读者信息的挖掘后,公共图书馆应利用大数据技术进一步挖掘少儿借阅信息,研究少儿读者的潜在阅读行为规律,并通过设置支持度有效阈值、借阅行为信度等方式,对不同图书的价值与关联度进行分析,具体的信息挖掘步骤如下。
第一步,利用公共图书馆历史数据库中的信息资源建设少儿借阅信息数据库。在数据库建设过程中,公共图书馆可将部分图书借阅记录作为项数集合,以分析数据库中信息的关联性。
第二步,定义少儿借阅信息行为的支持度S,行为有效置信度C及行为提升潜在空间lift,将这3个参数作为变量参数,并进行关联处理,得到少儿借阅信息挖掘的关联规则。公共图书馆通过调整参数有效范围的方式,可实现对挖掘信息中关联值的干扰,并通过迭代的方式,对关联规则进行优化。在确认各参数之间具有强关联性后,公共图书馆应对lift参数进行调整,仅保留大于lift值的数据,并将其作为关联规则數值,并对相关信息进行强关联处理,以深入挖掘少儿借阅信息。
第三步,在完成对信息的处理后,通过设置项集的方式,对关联信息进行集中展示,由终端技术人员负责对数据信息进行筛查,手动清除无关信息,优化信息挖掘成果。
1.4 公共图书馆少儿阅读个性化推荐
在完成信息挖掘的基础上,公共图书馆可有效开展少儿阅读个性化推荐服务,在为少儿读者推荐优质阅读资源的同时,快速检索并聚类相似度较高的读者信息群。公共图书馆可收集少儿读者的个人及检索数据,利用大数据挖掘结果构建关联模型,精准地为少儿读者推荐阅读资源。
2 对比实验
为了验证基于大数据挖掘的少儿阅读推荐方法的效果,笔者分别将该方法与基于信息觅食的少儿阅读推荐方法应用于某公共图书馆的相关实践,对两种方法的用户偏好度进行对比,用户偏好度计算公式为:
U={(a1,b1),(a2,b2),…,(a3,b3)}
其中,U为少儿阅读推荐结果中的用户偏好度,ai为某一类公共图书馆阅读资源的评价数据,bi为某一类阅读推荐方法的用户评价指数,i的取值范围均为1,2,3,……,n。根据实际情况,笔者将U的取值范围设定为0到1之间,U的值越接近1,說明推荐的图书越能够满足少儿读者的阅读需求。由于少儿的认知发育不够健全,因此,公共图书馆在计算用户偏好度的过程中,除考虑少儿读者的阅读需求外,还应考虑少儿家长的教育需求。表1为笔者针对两种少儿阅读推荐方法的用户偏好度计算结果,基于大数据挖掘的少儿阅读推荐方法的用户偏好度明显高于基于信息觅食的少儿阅读推荐方法。
3 结语
基于大数据挖掘的少儿阅读推荐方法有助于公共图书馆充分挖掘少儿读者信息及借阅信息,为少儿读者提供精准的阅读资源推荐服务。在实际应用过程中,公共图书馆应结合少儿读者的历史借阅数据,开展个性化推荐服务。此外,公共图书馆还应利用大数据技术开展多角度、多层次的数据信息挖掘工作,进一步提升少儿阅读推荐服务质量。
参考文献:
[1] 叶颖.面向阅读推广评论数据的书目个性化推荐方法探究[J].新世纪图书馆,2021(10):31-36.
[2] 刘朝晖.信息觅食视域下图书馆智慧阅读推荐服务质量影响因素及提升策略[J].图书情报导刊,2020(12):7-13.
[3] 王会玲.高校图书馆阅读书目推荐浅析:以武汉工程科技学院图书馆为例[J].河南图书馆学刊,2021(10):80-82.
[4] 余建芳.基于“互联网+”的高校图书馆个性化阅读推荐系统的设计与实现[J].数字技术与应用,2021(9):146-149.
[5] 程全.基于情景感知的智慧图书馆阅读推荐服务模型构建与优化策略[J].图书馆工作与研究,2021(10):119-128.
[6] 唐玖江,荣维东,薛相锋.青少年课外阅读推荐书目研究:基于中小学语文课程标准实施视角[J].图书馆杂志,2020(5):64-74.
[7] 黄逸秋.做领导干部的“阅读顾问”:以三项领导干部阅读书目推荐活动为例[J].新阅读,2019(12):71-73.
[8] 王凤燕.优化阅读推荐实施分层阅读:对班级共读一本书的冷思考[J].福建教育学院学报,2020(5):86-88.
(编校:冯耕)
猜你喜欢
河南图书馆学刊(2017年3期)2017-03-31
河南图书馆学刊(2017年3期)2017-03-31
河南图书馆学刊(2017年3期)2017-03-31
新世纪图书馆(2016年9期)2016-11-15
新世纪图书馆(2016年9期)2016-11-15
新世纪图书馆(2016年9期)2016-11-15
科技视界(2016年21期)2016-10-17
商(2016年27期)2016-10-17
求知导刊(2016年22期)2016-10-08
科教导刊·电子版(2016年11期)2016-06-03
