
基于切片推理的小目标检测技术研究
2024-03-04 13:19刘玉雯刘文逸唐云龙何维真韩星烨
兵器装备工程学报 2024年2期
刘玉雯,刘文逸,唐云龙,彭 沛,何维真,韩星烨
(西北机电工程研究所, 陕西 咸阳 712099)
0 引言
目前,无人机相关技术发展迅速,无人机以其小巧灵活、高效可控、续航能力不断加强的显著特点广泛应用于民用航拍、军事侦察、农业监测等领域[1]。在航拍视角的目标检测中,其飞行高度越高,高分辨率成像画面中的目标占比越小,而且成像过程中的光照变化、遮挡、背景复杂等因素都会增加目标检测的难度。相比于常规尺寸的目标,小目标及微小目标相对于整幅图像占比较小,特征不明显且易受环境变化的干扰,存在漏检、误检的现象,使得小目标的检测精度仅为大目标的一半[2]。因此,通过增加多种小特征提取方法及模型优化策略从而提升小目标识别准确率,是当前目标检测领域的一大研究热点。
目前的小目标检测算法主要从多尺度学习、数据增强、训练策略、注意力机制、基于上下文检测的角度进行算法改进[3]。2020年,针对小目标的数据预处理技术中Mosaic增强将4幅不同图像拼接成原图像尺寸输入识别网络,在不改变输入图像尺寸的情况下,增加了图像中的目标数量,Copy-Paste增强通过复制粘贴的形式,将复制后的目标分布于图像任意位置,Mixup增强将多幅图像进行直接融合,增强后的图像是多幅图像相嵌的结果[4],这些预处理技术都是通过增加样本数量来提升网络学习效果,并未提升对小目标的特征提取能力。2020年,郑晨斌等为增强小目标与周围像素的交互学习,提出一种增强低层网络特征输出,获取更多上下文信息的强化模型,提升了小目标特征的提取效果[5]。2021年,赵亮等针对小目标所占像素较少,可能随网络层加深特征减少甚至缺失的问题,提出一种全局与局部图像特征自适应融合的小目标检测算法,利用特征选择模块对图像的不同输出进行融合,提高了小目标检出率[6]。2023年,谢椿辉等通过对特征提取模块设计注意通道机制及优化损失函数的方式对YOLOv5算法进行改进,能够有效适配航拍小目标检测需求[7]。
本文中针对航拍视角下小目标所占像素较少,在高分辨率成像中识别精度较低且易漏检误检的问题,结合小目标的先验框尺寸及成像特点,对YOLOv5进行改进并添加辅助预测机制。使用基于上下文增强算法,增加有效特征层对局部特征的学习,减少小目标的特征缺失;使用优化后的边界框损失函数,使网络更加关注有效目标,提高小目标的定位精度;使用切片辅助推理算法,增加检测网络感受野,减少局部小目标的漏检率。本文中提出的基于切片推理的改进YOLOv5算法,从特征网络提取和目标检出2个角度对网络模型进行优化,是一种高效识别小目标的算法模型。
1 基于航拍视角的小目标分析
小目标通常是指在成像画面中占比较少、特征不显著且难与背景有效区分的目标。当前的目标检测领域并未对小目标进行明确划分,定义标准分为绝对尺度和相对尺度。因目标识别网络需要构建有效特征层,通常是以原图像尺寸为标准进行缩放,其中最大缩放比为32倍下采样,故绝对尺度定义目标所占像素小于32×32区域即为小目标。国际光学学会认为,应按照目标的实际成像比例进行划分,即绝对尺寸定义目标像素面积占比小于0.12%确定为小目标。上述是2种常规定义,还有根据面积中位数占比、目标先验框占比进行小目标划分[8]。小目标在航拍成像中的分布情况如图1所示。图中的航拍图像源于Visdrone2019数据集,图中的矩形框代表小目标在图像中的定位结果,矩形框左上角的数字代表预测类别,该数据集共有10个类别,分别对应0~9的数字。图中识别结果主要是数字0和3,分别代表预测类别结果为行人和汽车。

图1 航拍小目标实际分布情况
根据图1的分布结果,小目标在航拍成像中是真实存在且大量分布的,图中也出现了小目标集中分布、遮挡、与背景区分度低、环境光照变差等外在变化的情况,这些影响因素都会增加小目标标注及特征提取的难度。随深度神经网络层数的加深,有效特征层中包含小目标的信息随之减少,网络学习小目标的能力逐渐减弱,从而导致检测网络对小目标的识别精度变差。
以Visdrone2019航拍数据集为例,将代表目标尺寸的先验框与原图像在宽、高方向分别进行比例分布统计,目标尺寸在原图的占比结果如图2所示。
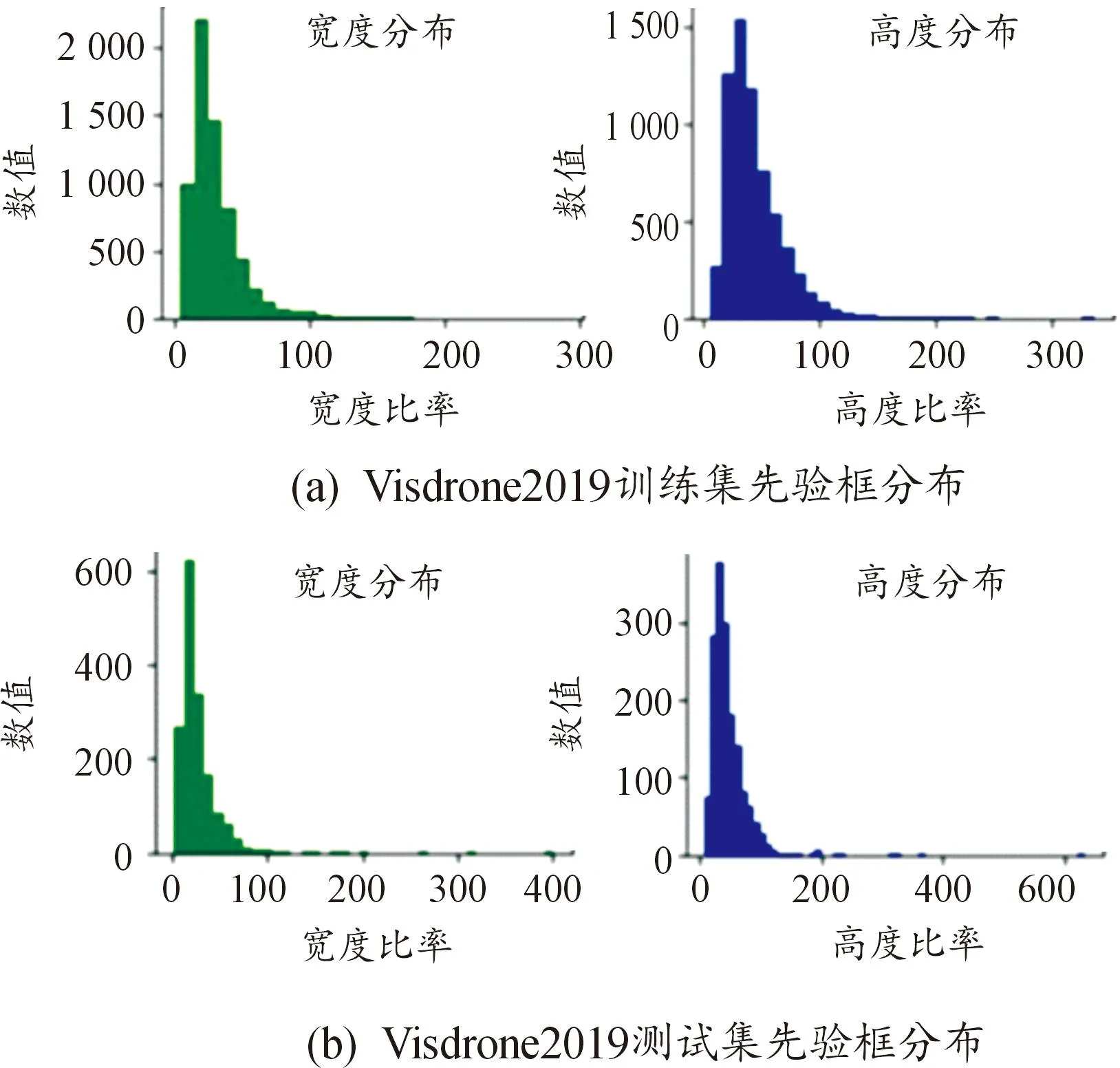
图2 Visdrone2019数据集先验框分布
由图2结果可知,Visdrone2019数据集中的多数目标所占像素较少,尺寸分布大多小于原图的0.1%。该数据集是航拍图像的典型代表,其中小目标分布较为集中,存在背景复杂难与目标有效区分的现象,故不适用于常规检测网络,需要针对小目标进行算法优化,提升模型训练时对小目标的关注度及模型验证时对小目标的检出率。
综上所述,为解决航拍视角中小目标尺寸较小、特征信息不明显、环境适应性差的问题,应在模型设计中增加对小目标的特征学习,关注代表小目标的浅层网络,通过辅助推理等方式提升小目标的识别效果。
2 基于小目标的YOLOv5目标检测识别算法
2.1 YOLOv5目标检测识别算法
基于深度学习的目标识别算法根据检测流程设计的不同可分为一阶段和两阶段网络模型,由于检测任务对识别算法实时性的要求,使算法优化工作更加偏向于对端到端学习的一阶段算法进行设计改进[9-13]。针对小目标检测识别的算法,对同属于一阶段算法的SSD网络和YOLO网络的优化改进研究较多,其中SSD算法的模型设计较为复杂,涉及多重卷积嵌套叠加,而YOLO网络的模型设计较为简明,只需在主干网络中提取3个尺度的有效特征层进行预测,并在有效特征层之间进行信息融合,使每个特征层都包含多层图像信息,有利于网络整体适应于高分辨率图像及多尺度目标的学习,从而提升检测网络的识别精度。YOLOv5是目前YOLO系列算法较先进且稳定的算法,网络结构如图3所示。
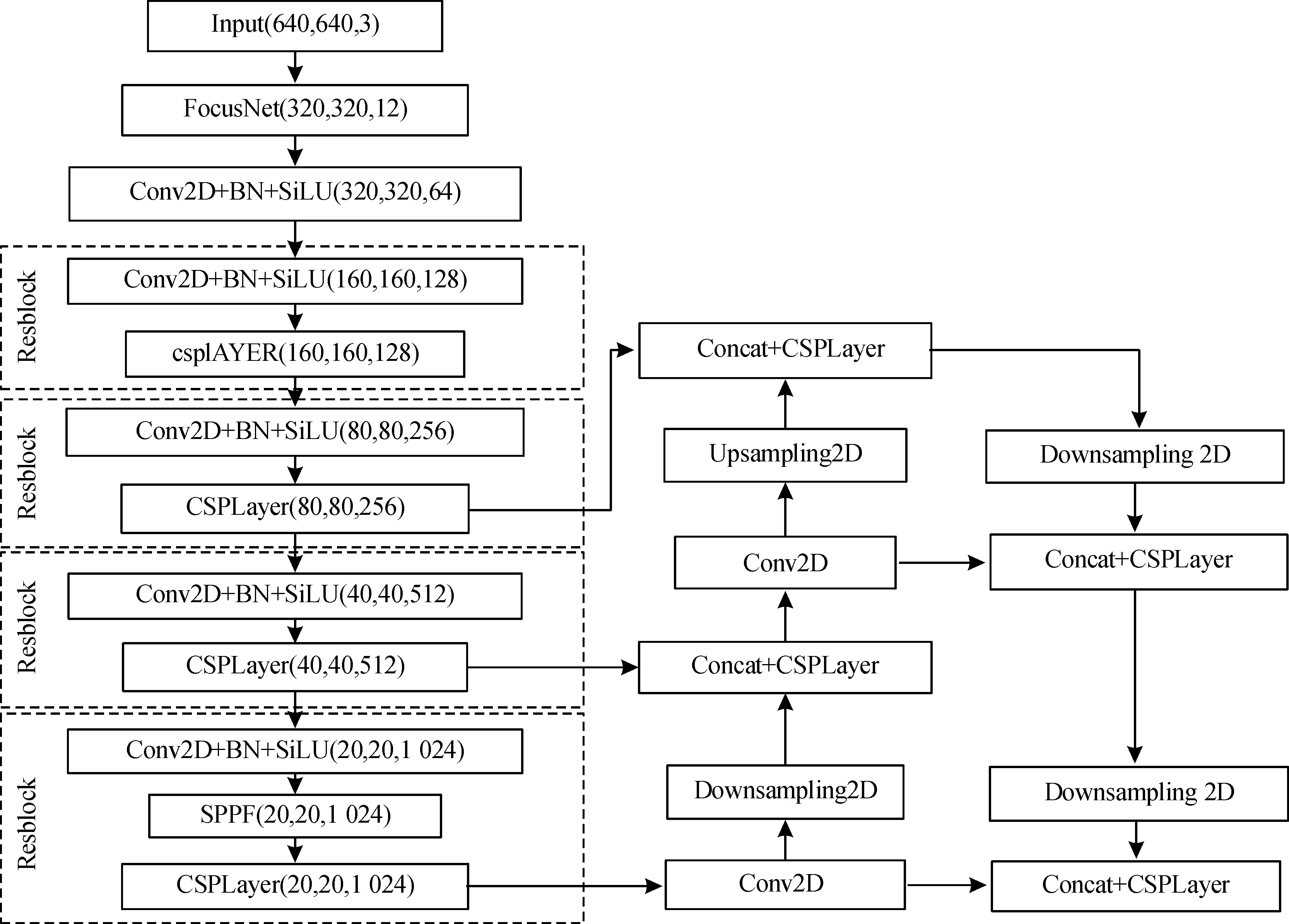
图3 YOLOv5网络结构图
如图3所示,YOLOv5主干网络为CSPDarknet,其中包含卷积层、归一化层、SiLU激活层及CSPLayer的Resblock大残差模块。CSPLayer内部使用1×1、3×3大小的卷积核,构成残差边,用于构建深层网络。主干网络中使用多组卷积与CSPLayer结合,再通过残差减少因网络层数增多带来的过拟合问题。YOLOv5是在YOLOv4的基础上进行改进,其不同之处在于YOLOv5将SPP结构放在主干网络的底部,将多尺度卷积核应用于构建有效特征层中。在特征金字塔构建时,先使用CSPLayer进行特征融合再进行上采样、下采用操作,最大限度保留本层特征并传入检测网络。
2.2 针对小目标的YOLOv5改进策略
2.2.1使用CAM模块增强上下文交互
因YOLOv5中3个特征图尺度为80×80、40×40、20×20,分别代表小目标、中目标和大目标,所以浅层网络中包含更多的小目标信息,通过提高浅层网络特征提取或增加浅层网络特征融合是针对小目标特征提取的有效手段[14-15]。文中提出将基于上下文增强的CAM模块添加到YOLOv5特征融合网络中,可有效解决小目标特征分散、特征层间语义信息差异较大的问题。CAM模块结果如图4所示。
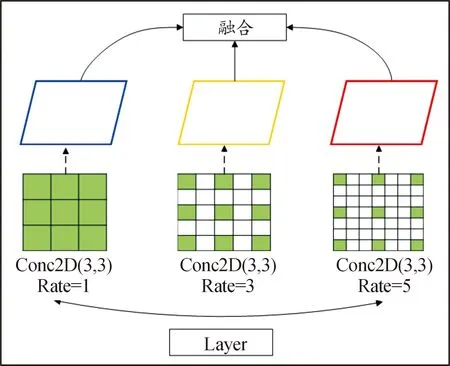
图4 CAM模块结构
如图4可知,CAM模块中的扩张卷积以其特有的扩张倍率,将标准卷积进行扩张放大,在不改变特征图尺度的前提下,扩张共享卷积核尺度,增大卷积核的感受野。为保证对特征图的全局扫描,使用扩张倍率为1、3、5的3个3×3大小卷积核将特征图进行多尺度提取,再通过不同的融合策略将特征提取结果进行合并。CAM模块包含3种融合机制,分别是相加(Weighted)、拼接(Concatenation)和自适应融合(Adaptive),3种融合结构如图5所示。
如图5所示,相加和拼接2种融合机制先通过3个1×1卷积调整特征图的通道数,再在维数或通道数方面进行特征融合,自适应机制通过卷积、拼接和Softmax函数获得自适应权重,再以跳接的方式进行融合。
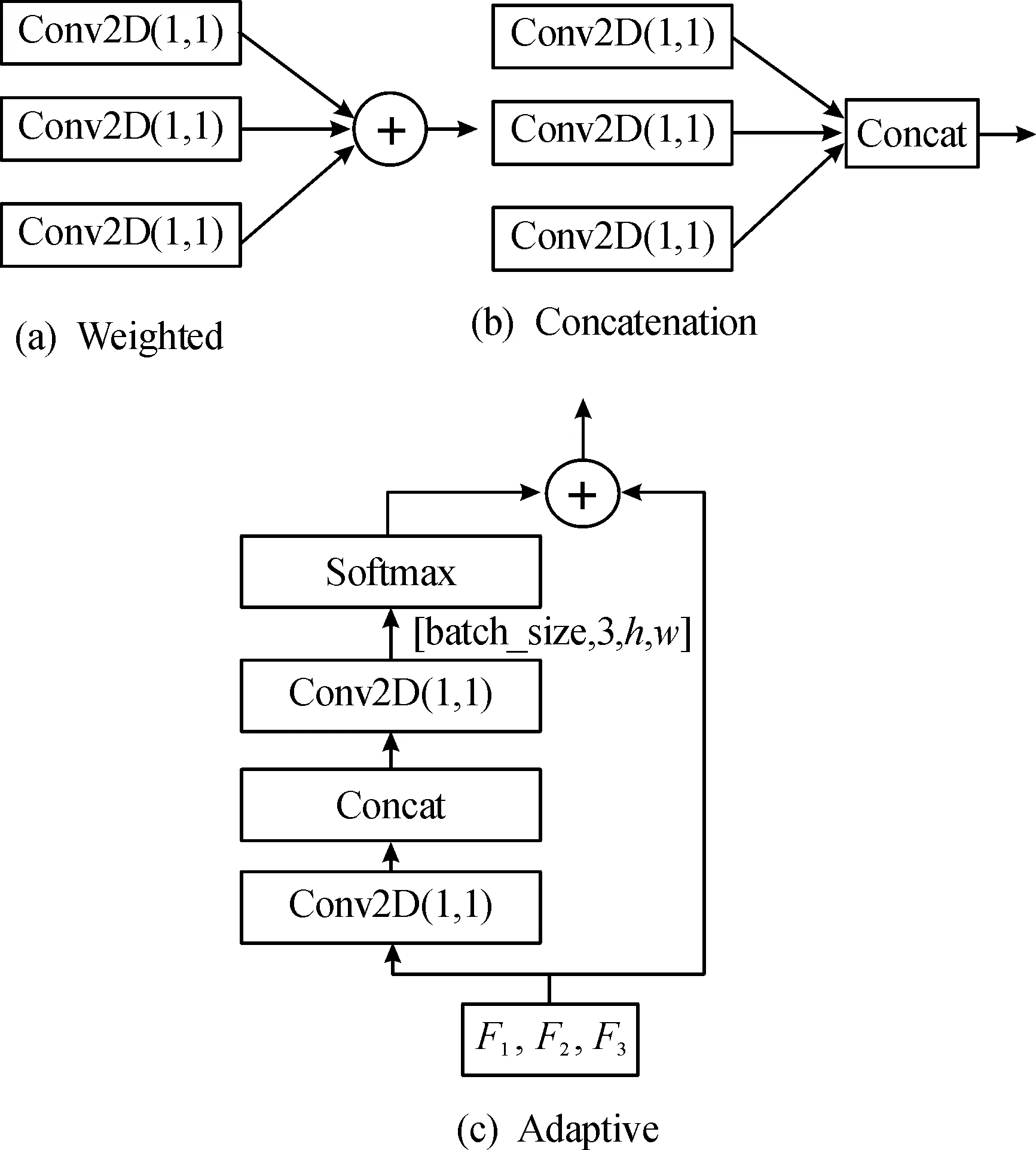
图5 CAM模块融合机制
2.2.2优化边界框定位损失函数
边界框定位损失是预测框与真实框差异的回归计算结果,代表模型对目标识别输出结果的定位精度,通常使用交并比(IOU)作为2个矩形框差异的衡量标准。常见的IOU、GIOU、DIOU函数针对矩形框间面积或中心点欧式距离进行改进,训练结果存在回归收敛慢、训练结果不均衡等问题。YOLOv5的边界框损失函数为CIOU,该函数在DIOU基础上增加了两矩形框间的长宽一致性对比,如式(1)所示:
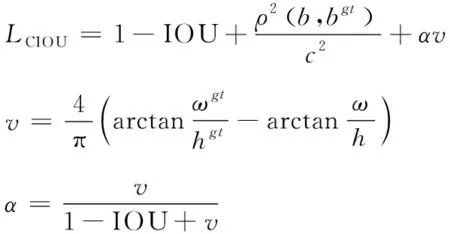
(1)
式(1)中:v判断预测框与真实框的长宽比是否一致,若一致结果为0;α表示为权重系数。
小目标尺寸较小,对预测框的定位精度要求更高,故文中使用Focal_EIOU损失函数对小目标的边界框定位损失进行改进。EIOU函数是将预测框与真实框的宽高差异最小化,将长宽比的影响因子拆开计算,从而产生更好的收敛速度和定位结果。Focal函数是解决训练样本不平衡的问题,利用长尾数据分布规律,把高质量的先验框和低质量的先验框分开,增加回归误差较小的预测框对结果的占比。将二者结合后,Focal_EIOU函数如式(2)所示:
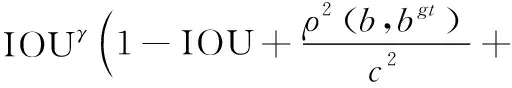
(2)
式(2)中:LIOU为IOU损失;Ldis为距离损失;Lasp为方位损失;γ为控制异常值抑制程度的参数。
2.2.3检测网络添加切片辅助推理
小目标是由少量像素构成,缺乏足够的细节特征,传统检测网络易忽视局部小目标,故提出使用切片辅助推理检测网络,提高小目标检出效果。切片辅助推理(slicing aided hyper inference and fine-tuning for small object detection,SAHI),是一种通过切片辅助推理和管道微调的高效检测网络,通过对图像进行重叠切分,使得小目标相对于原输入图像产生较大的像素区域,有利于提升对局部小目标的关注从而减少小目标的漏检率。SAHI辅助切分原理,如图6所示[16]。
由图6可知SAHI的切片推理过程,先将原图进行切片划分并限制切片步长即切片区域在原图中的滑动设置,再将切片结果进行相同宽高比例的区域分割,分割后的切片结果相互独立,最后根据分割结果分别进行预测,因滑动切片处理会使预测结果出现重复,所以需要使用非极大值抑制算法对重复预测区域进行筛选合并,再还原至原图尺寸得到最终的推理预测结果。
SAHI使检测网络对图像特征扫描更加细致,增强了局部区域中小目标的特征检出能力,是一种高效的基于局部信息增强的小目标检测算法。
2.2.4改进的YOLOv5结构
YOLOv5的网络结构主要考虑常规目标的检测精度及模型泛化性应用,并未过多关注目标尺度的极限情况,所以模型训练的收敛方向更倾向于中大尺度目标,小目标会因其特征提取不充分、训练数据不平衡等因素在识别结果中表现较差。改进后的YOLOv5模型如图7所示。
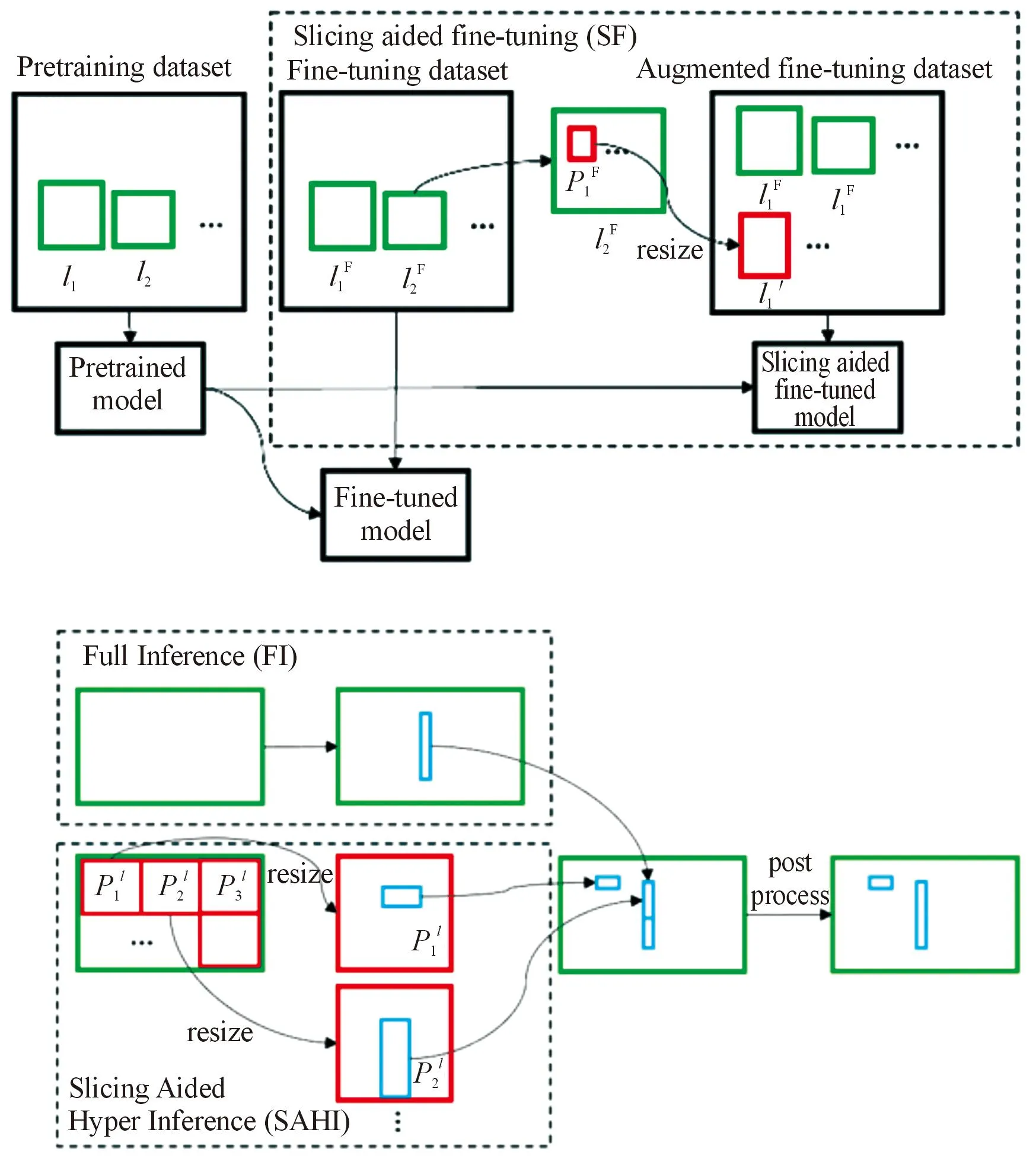
图6 切片辅助推理原理图
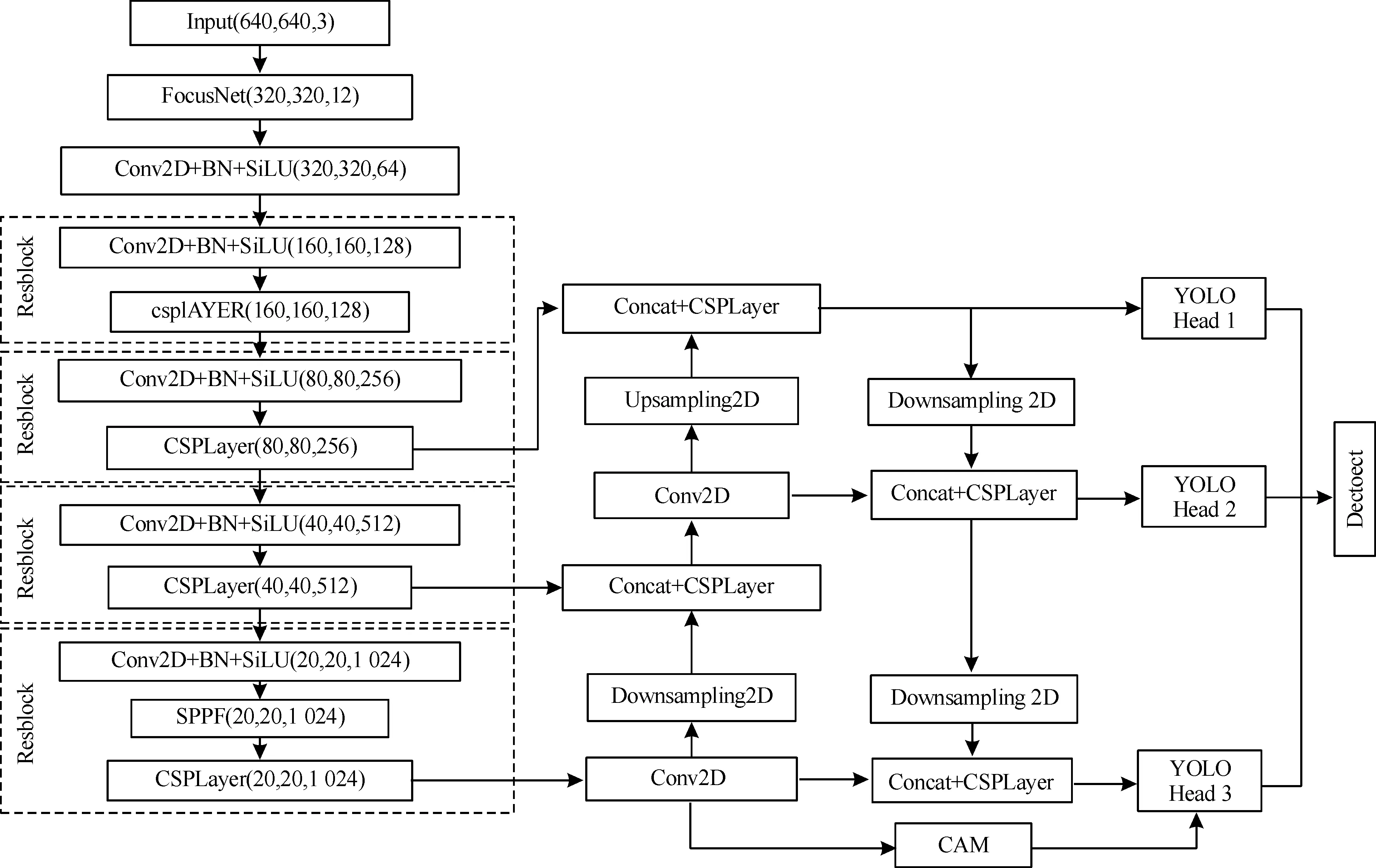
图7 改进的YOLOv5模型
图7中,YOLOv5主干网络输出80×80、40×40、20×20大小的3个尺度特征层,根据上、下采样等特征融合方式输出YOLOHead1,YOLOHead2,YOLOHead3,即代表小、中、大尺度的包含浅层特征和语义信息的有效特征图,将代表稀疏特征提取的CAM模块添加至特征融合的前端,使小目标特征提取更具泛化效果。Detect表示模型的预测阶段,包含真实标注结果与模型预测的差值、预测类别置信度等输出结果的计算和表示。在预测阶段添加SAHI的切片推理,通过放大局部特征的像素占比,提升小目标的检出率;在预测结果评估阶段,添加改进的Focal_EIOU函数,在模型参数迭代更新中提高预测框的定位精度。
2.3 目标识别算法评价指标
1) AP(average precision)、mAP(mean average precision)
AP、mAP均代表目标识别准确率,AP是相对单类目标的识别精度,mAP是多类目标的识别精度取均值。在模型训练时可能存在正负样本不均衡或某类目标分布较多的情况,导致识别结果出现某类目标AP较高而整体mAP较低的情况,故在分析网络模型性能时应根据数据分布情况选择合适的识别精度评价指标进行结果的总和分析。
2) 准确率(precision)和召回率(Recall)
准确率是真正的正样本数除以检测的总数,如式(3):
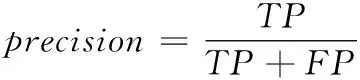
(3)
召回率是预测为正例的样本中预测正确的数量除以真正的正样本数量,如式(4):
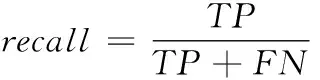
(4)
3 实验分析
3.1 实验平台搭建及数据集预处理
本次网络构建基于Python 3.8.1和Pytorch 1.13.1框架搭建,在Tesla T4显卡和NVIDIA GeForce GTX 3090Ti GPU的配置环境下完成训练和测试。文中的对比实验采用公开数据集Visdrone2019进行训练,网络抓取UAV-ROAD数据进行算法验证测试。
在数据集预处理阶段,对Visdrone2019训练集的先验框大小进行聚类,其中不同颜色区域代表不同的聚类结果,颜色区域分布越广,代表数据在该聚类中心的结果越集中,聚类中心即聚类结果根据数据分布进行更新,如图8所示。得到3种不同比例和尺寸的9个结果(3,5)、(4,9)、(9,8)、(6,14)、(10,19)、(16,12)、(20,23)、(34,16)、(47,37)。
根据聚类结果可知,小目标先验框尺寸较小,与YOLOv5中默认设置的先验框相差较大,为使预测结果更加符合小目标真实尺寸,在模型训练前将先验框聚类结果进行替换,使模型在训练学习中更倾向于小目标分布。
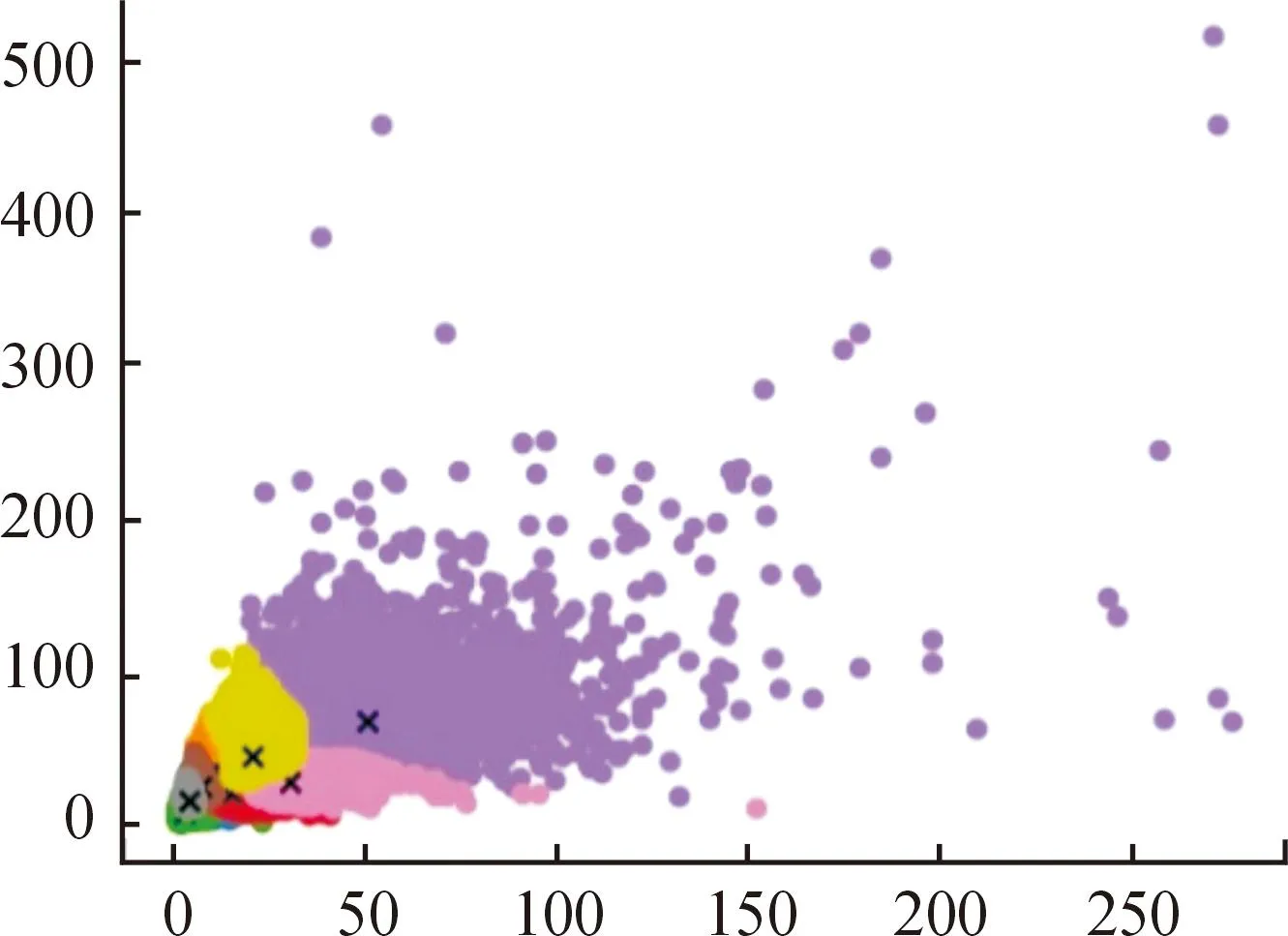
图8 Visdrone2019数据集先验框聚类结果
3.2 训练参数对比
为验证CAM模块中多尺度扩张卷积对小目标局部特征的提取效果,从特征提取和特征融合2个角度分别进行基于CAM的改进对比实验。对比实验模型参数如表1所示。
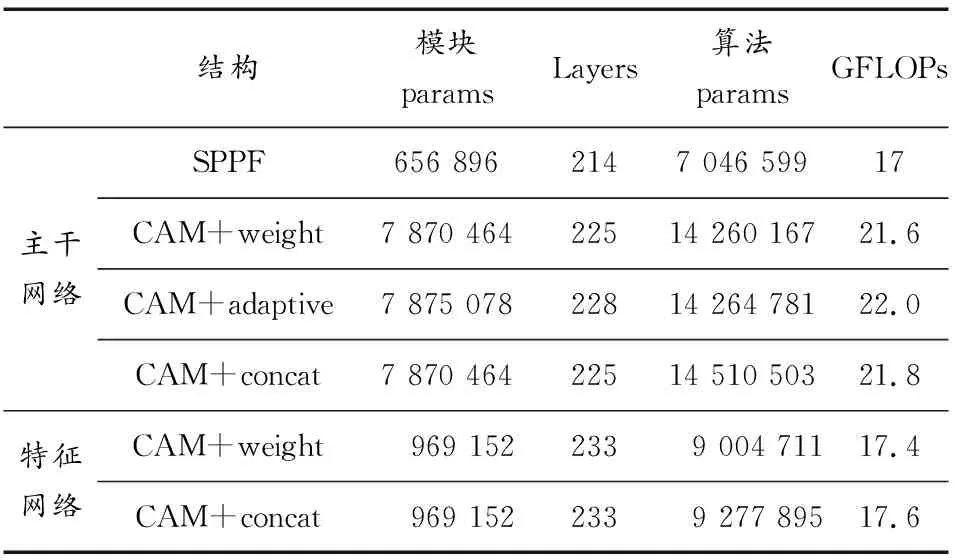
表1 模型参数对比
表1记录了实验中各模型参数变化情况,使用模块参数和算法参数对比各改进模块对YOLOv5模型运算的影响,其中Layers表示神经网络层数,GFLOPs表示模型计算复杂度。在主干网络中,将CAM替换SPPF,对比2种模块实验参数可知,CAM的参数量较大,算法复杂度较高;对比CAM的3种融合方式,weight和concat都是在维数或通道进行拼接,参数量和模型结构一致,adaptive包含残差结构,模型参数量大,算法层数较多。
根据参数数据及算法计算复杂度对比可知,在主干网络中使用残差结构进行多层特征提取,将改进模块放置于融合网络的处理方式能够增强目标特征表达,且改进后的融合网络与原算法相比,模型参数差异较小,是一种参数量变化较少的改进分支结构。
3.3 损失值对比
边界框回归结果是衡量目标定位精度的关键,基于YOLO算法的损失值包含置信度损失、分类损失和定位损失如式(5)所示:
L(o,c,O,C,l,g)=λ1Lconf(o,c)+λ2Lcla(O,C)+
λ3Lloc(l,g)
(5)
式(5)中:λ1、λ2、λ3为平衡系数;Lconf、Lcla、Lloc分别为置信度损失、分类损失和定位损失。置信度损失用于模型判别目标与背景;分类损失用于判别目标是否属于该类型;定位损失用于判别模型预测结果是否准确。
采用批梯度下降的方式,对CAM在主干网络和融合网络改进的多种结构分别进行训练。对Visdrone2019中的训练集和验证集进行随机组合,随机选取80%作为训练集,每次训练进行100次迭代,批量大小设置为16,初始学习率为0.01,权重衰减为0.000 5,不进行额外数据增强处理。使用YOLOv5默认损失函数,以50个epoch为例进行对比,3种损失函数对比结果如图9所示。
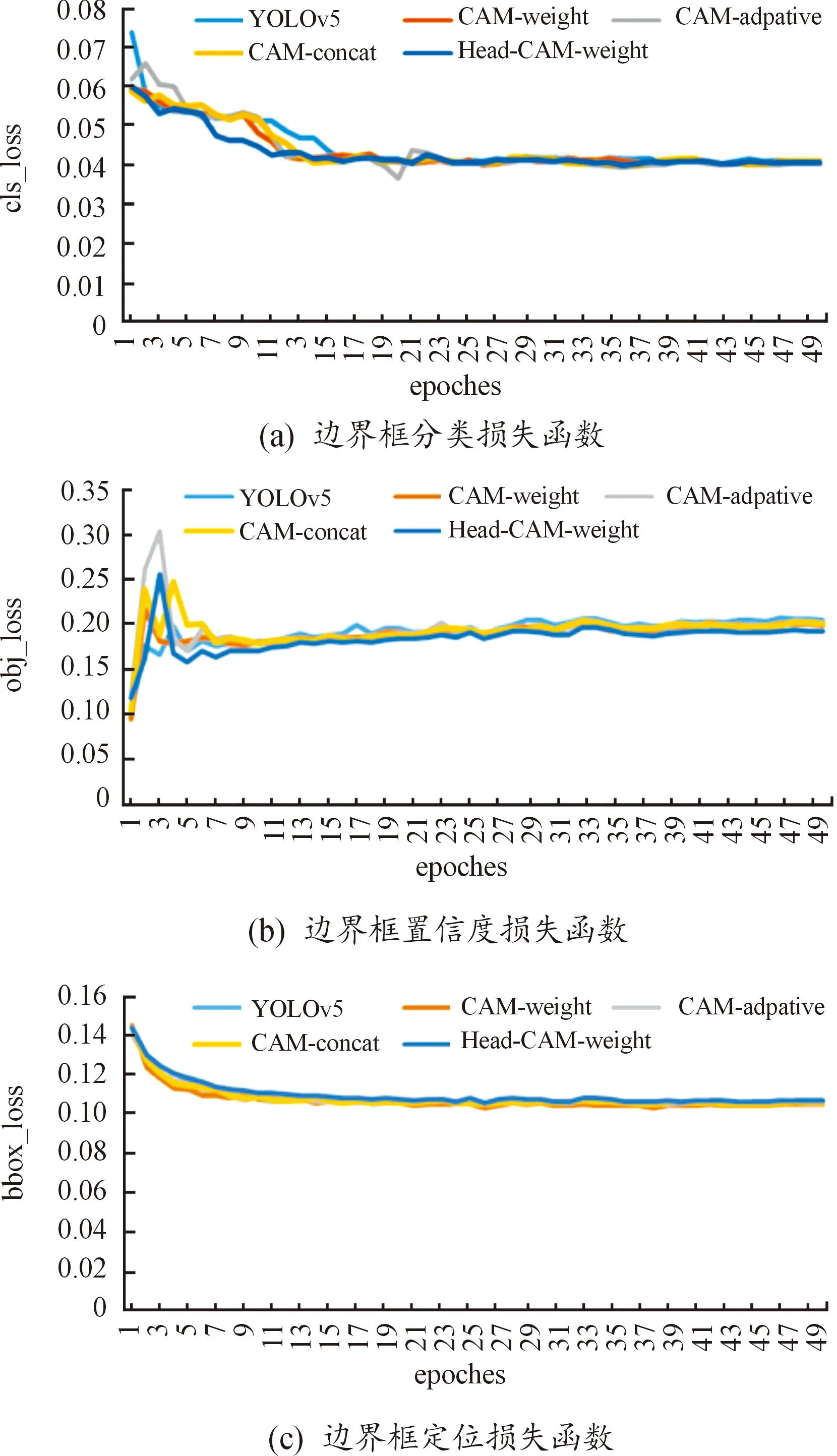
图9 边界框损失函数对比
图9中“head-cam-weight”为本文中的改进框架,可见几组改进结构对于目标分类较为准确,边界框损失基本在20个epoch趋于稳定,而本文中提出的改进方式收敛速度最快,在12个epoch趋于稳定;置信度损失函数中,前10个epoch的数值变化剧烈,本文中的改进算法在5个epoch时存在小幅波动后趋于稳定;边界框定位损失中,各改进方式的变化趋势较为相似,基本在0.11左右收敛结束。因此,将CAM模块添加至YOLOv5特征融合网络并使用“weight”融合方式在检测网络的损失函数中收敛最快,数据波动较小。
另外,针对小目标进行了边界框定位损失函数优化,采用Focal_EIOU替代CIOU函数,分别对比CIOU、EIOU及Focal_EIOU在CAM改进框架中的损失值收敛效果,如图10所示。
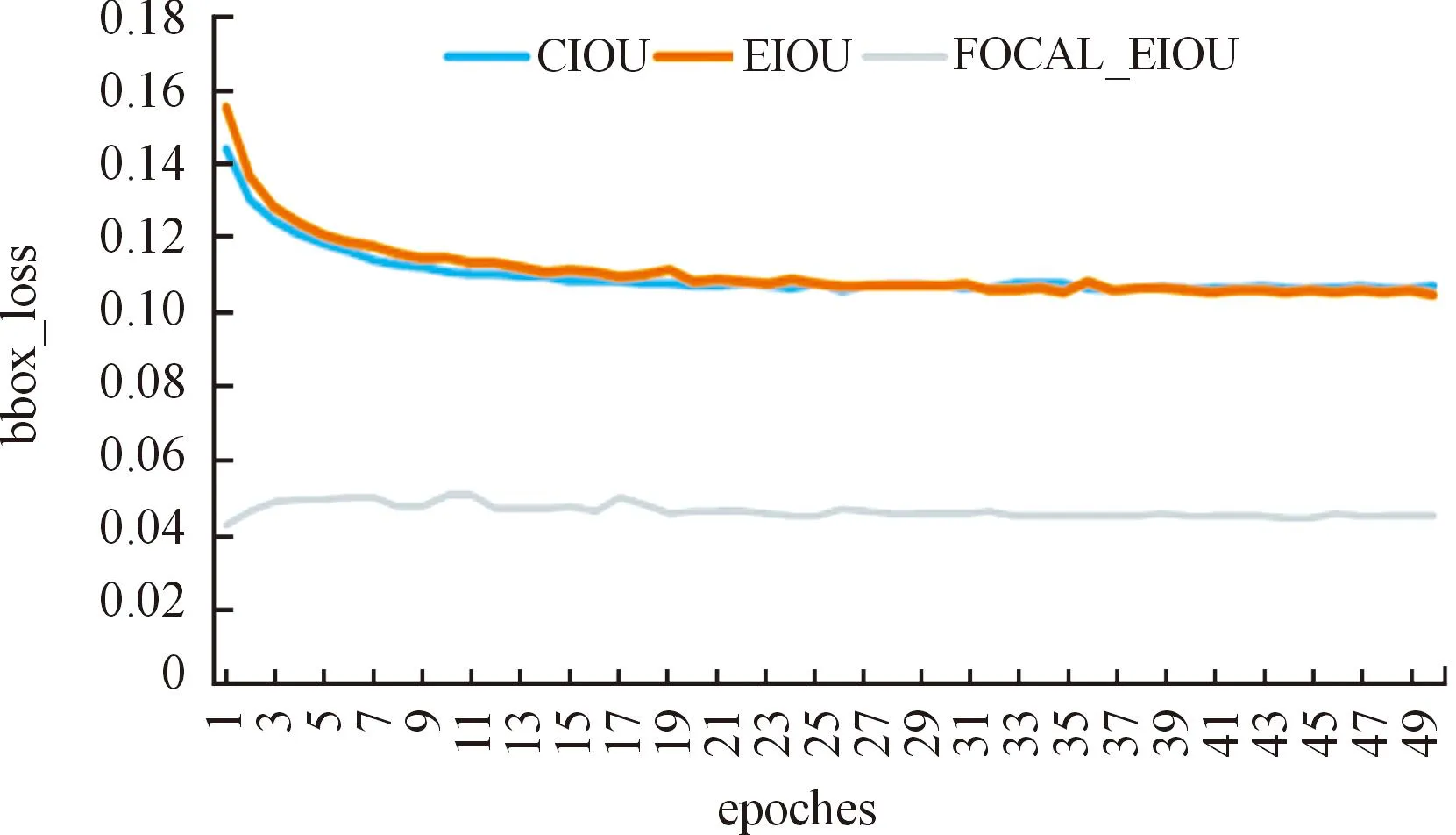
图10 改进算法边界框定位损失函数对比
由图10可知,边界框定位损失函数为CIOU或EIOU,函数收敛变化差异较小,而Focal_EIOU在训练初始阶段的损失值明显下降,且随迭代次数的增加趋于稳定。综上,Focal_EIOU适用于改进后的网络结构,且提升了数据集中小目标的定位精度。
3.4 识别结果分析
3.4.1数据集识别结果分析
因Visdrone2019数据集包含10个类别,且各类样本分布不均,选取数据集中目标分布较多的4个类别进行识别效果对比,将IOU阈值均设置为0.5,选取20%的数据进行验证,使用目标识别评价指标对改进结构的目标识别效果进行对比,各类目标识别结果如表2所示。
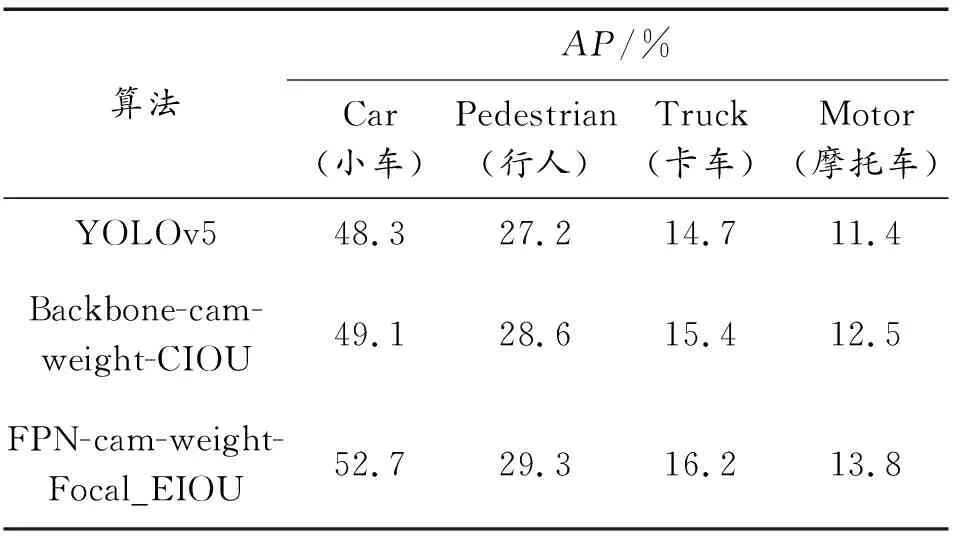
表2 目标识别结果对比
从表2可知,改进算法(FPN-cam-weight-Focal_EIOU)的识别准确率最高,在检测小车(car)、行人(pedestrian)、卡车(truck)、摩托车(motor)等小目标的效果上提升明显,对比原YOLOv5模型,分别提升了4.4%、2.1%、1.5%、2.4%。对比数据集全类别的PR曲线变化,可以看到小车的准确率和召回率结果最优,对改进算法的应用效果最好,如图11所示。
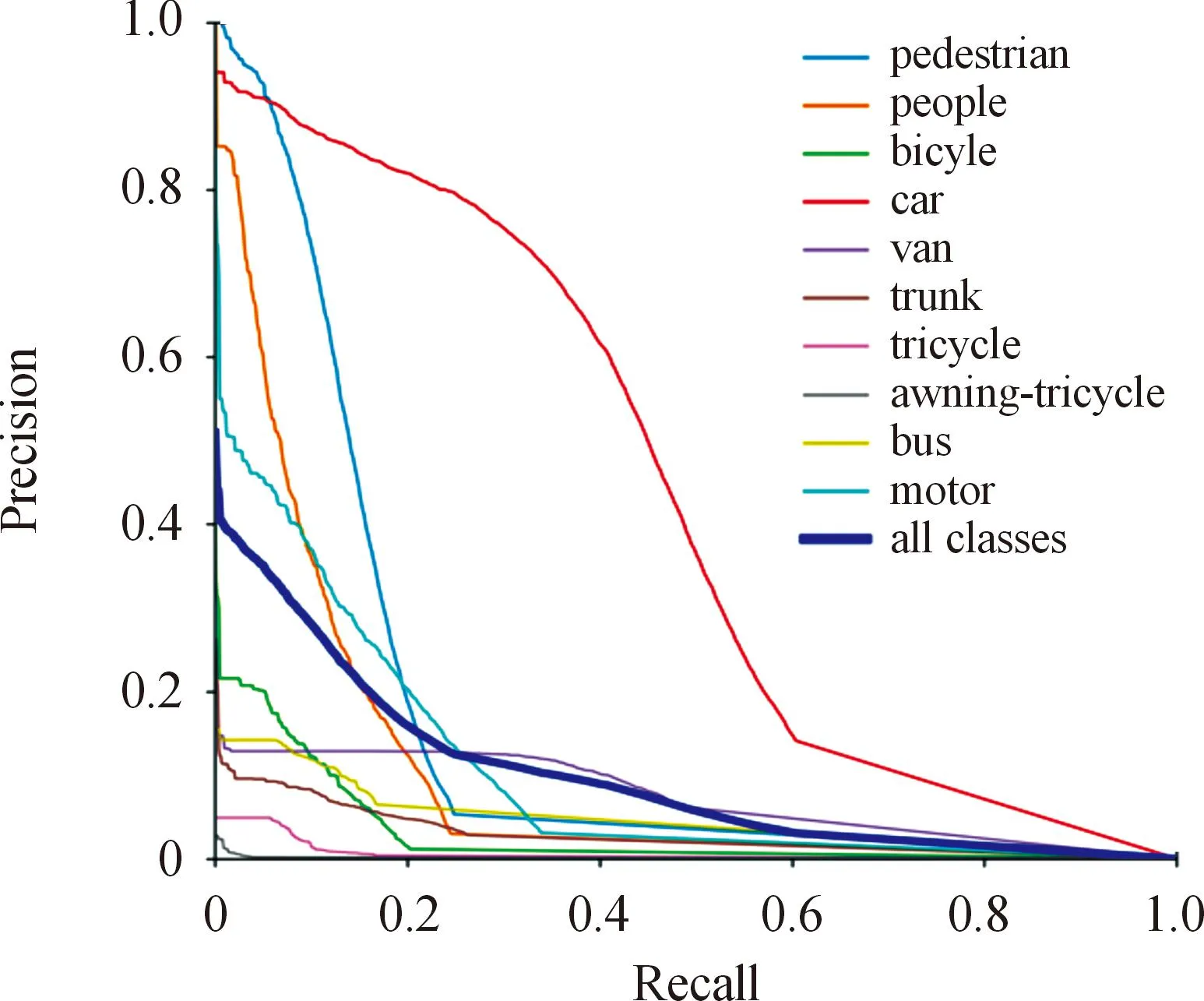
图11 改进算法在Visdrone2019数据集的PR曲线
综上,可见改进算法相比于原YOLOv5识别准确率明显提升,尤其是小车这种目标分布较多且特征显著的类别,改进算法的特征提取能力较强且训练效果最好。
3.4.2小目标检出结果分析
为了验证本文中提出的在检测网络中添加SAHI切片辅助推理算法,在高分辨率图像中小目标的检出率方面的提升效果,在网络中抓取1080P分辨率的UAV-ROAD视频数据。将切片重叠率设置为0.2,切片步长为512,切片宽高比一致,并使用NMS筛选重叠率高的检测框。将原YOLOv5检测网络及本文中改进检测算法进行对比,识别结果如图12所示,图中矩形框及标号代表了算法预测结果,依据数据集的数字-类别对应关系,在图中直接进行类别显示和置信度标注,如“car 0.71”代表算法预测图中的小目标类别为汽车,且该目标为汽车的置信度概率为0.71。

图12 检测网络识别结果对比
由图12可知,在同帧图像中原YOLOv5检测网络识别出12辆小车,未识别出行人;改进检测网络识别出26辆小车和8个行人。可见,改进的检测网络对于高分辨率中的小目标检出效果较好,使图中右上角容易被忽视的行人及左上角远处的车辆,通过切片的方式,使网络能够检测识别局部区域内的有效目标,提升了整幅图像中小目标的检出率,且在同一位置的目标识别精度有所提高,证明了本文中改进算法能够有效提升小目标检测效率。
4 结论
本文中的改进算法从模型特征融合、目标矩形框定位及目标检出率3个方面进行优化,使用公开数据集进行算法对比验证,实验结果证明了本文中的改进算法在小目标检测精度及检出率方面均优于原YOLOv5算法,是一种针对小目标的高效识别检测网络。
1) 根据高分辨率图像中小目标先验框宽高占比,验证了小目标是大量分布且像素占比仅为0.1%左右,通过对目标数据集先验框尺寸聚类,得到符合该数据集的9个聚类结果,并将其应用于模型训练中。
2) 本文中改进算法在特征融合中使用CAM模块,提升了局部特征感受野,增强了小目标与其周围像素的交互式学习;在目标矩形框定位中使用Focal_EIOU损失函数,增加了有效识别结果的关注度,显著提升了图像中小目标的定位精度,使得单类别识别精度提升4.4%。
3) 将SAHI辅助推理算法应用于检测网络中,通过切片的方式增加局部区域中小目标的检测效果,通过与原YOLOv5检测网络的对比,小目标检出率提升为原来的2倍。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
今日农业(2019年15期)2019-01-03
数学小灵通·3-4年级(2017年9期)2017-10-13
电信科学(2016年11期)2016-11-23
中国组织化学与细胞化学杂志(2016年3期)2016-02-27
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
中国当代医药(2015年17期)2015-03-01
