
基于Web的概念属性抽取的研究
2009-06-19 08:24吴月萍陈玉泉
中国管理信息化 2009年10期
吴月萍 陈玉泉
[摘 要] 针对现今通用搜索引擎存在信息量大、查询不准确、深度不够的问题,提出概念分析的方法。它是用于研究信息检索的一条重要思路,它所倡导的以叠置原理为核心的语义分析技术,目标是自动地解析复合概念的语义,解决从简单的符号处理走向词的意义处理。通过实现基于Web的属性抽取,以支持基于概念的搜索模型。最终使用实验来分析验证算法,所获得的查全率随着迭代的递增,不断增加;相反,准确率却相应下降,这个评测结果说明属性抽取方法的可行性。
[关键词] 属性抽取;概念;过滤;查全率;准确率
doi:10.3969/j.issn.1673-0194.2009.10.033
[中图分类号]F270.7;TP391[文献标识码]A[文章编号]1673-0194(2009)10-0098-04
0引言
全球调查显示,在互联网上搜索引擎的使用率仅次于电子邮箱,搜索引擎服务能成为最受欢迎的服务是因为它解决了用户在浩瀚的互联网海量快速定位信息瓶颈的问题,在海量的网页里找信息,按照传统方式需要用户一个网站一个网站、一级目录一级目录往下找,要耗费大量的精力和时间,而且互联网的信息量呈爆炸趋势增长,几年前全球式搜索引擎收录的网页量只有几千万页,而现在已经达到几十亿页,数量增加带来的是搜索服务的品质下降,查询的结果集是海量的,且结果里存在大量的重复信息和垃圾信息,用户越来越难迅速地找到符合的信息。
本文所研究的属性抽取基于概念分析方法,它所倡导的以叠置原理为核心的语义分析技术,目标是自动地解析复合概念的语义。同一概念可以用不同的语言表现形式来表达,也就是“一义多词”,如“计算机”和“电脑”就表示同一个概念。而相同的词也可以表示不同概念,也就是“一词多义”,如“苹果”,既可以表示水果,也可以表示美国的一家著名的电脑公司,也就是词汇与概念之间的非一一对应。在特定的检索目的下,如果限制“红苹果”和“红颜色的苹果”都是在说明“具有红色属性值的苹果(水果)”这样的实体时,两个检索表达式是等价的。这样就可以避免单纯的字符匹配所带来的查准率,查全率不高的问题,也就是说,要从简单的符号处理走向词的意义处理。
1国内外研究状况
近几年,国内外研究人员在信息模型的基础上,加入了自然语言处理(NLP)以及机器学习的方法,从而使信息检索系统更为“智能”。NLP技术试图通过将某个查询的语义信息与文档的语义信息进行匹配来提高查询的性能。它通常用于自由文本的信息抽取,即把文本分割成多个句子,对一个句子的成分进行标记,然后将分析好的句子语法结构和事先定制的语言模式匹配,获得句子的内容。NLP技术已经被应用于大规模文本检索(Text Retrieval Conference,TREC)语料库,并获得了一定程度的成功。尽管人们声称,要使信息检索达到其最佳潜能,必须对文本和查询进行更深层次的语义分析,所做的努力就包括潜在语义分析(Latent Semantic Analysis,LSI)的方法,它可以运用统计技术去除文本中的“噪声”,让和文本更相关的语义特征凸现出来,而且也取得了不错的应用效果。
如Hearst和Caraballo从语料库中抽取词汇概念间的上下位(isa)关系[1-2], Berland ,Charniak和Poesio等人从中抽取part-of关系[3-4], Almuhareb 和 Poesio 使用普通英语模板从Web中识别属性[5]。但应用本文的方法基于Web抽取概念属性的方法还是首例。
2属性抽取算法整体流程
实现基于Web的属性抽取首先要得出两个结果:一为分类规则;二为原始属性集。所谓原始属性集就是通过一个给定的模板和一个具体的产品基于Web首次抽取出的属性集合,但这个集合还存在一些垃圾属性,需要将它过滤掉,那么就要通过分类规则来测试原始属性以实现过滤。分类规则是基于分类算法得到的,使用最大熵分类器,匹配两个字典模板组和人工标注后的属性获得PMI特征值,由人工标注后的属性和属性标记词素生成词素特征值,分类器通过这两个特征训练,得到分类模型,即为分类规则,以作为过滤的依据[6]。属性抽取算法的整体流程如图1所示,对原始属性通过获得的分类模型进行过滤之后得到的属性集需进一步实现扩展,因为在自然语言中是不可能抽取完那些已用的属性,这里使用连接短语模板抽取属性的并列词,并对并列词进行验证,以判定并列词是否为属性。符合属性条件的放入属性集中,再对这个属性进行扩展、过滤,这是一个迭代的过程。
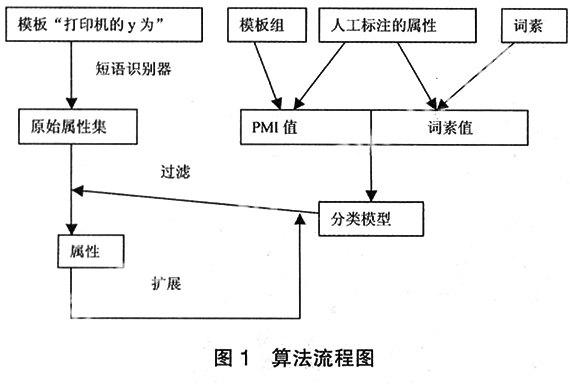
2.1分类模型
实现分类过滤属性首先要建立一个模型,描述预定的数据类集或概念集, 使其满足所有已知的事实。通过分析由属性描述的数据库元组来构造模型。假定每个元组属于一个预定义的类,由一个称作类标号属性(0或1)的属性确定。对于分类,数据元组也称作样本、实例或对象。为建立模型而被分析的数据元组形成训练数据集即特征,通过最大熵分类器,执行命令[7]:
Maxent train_data.txt –i 200 –m model –v
其中train_data.txt为由PMI值和词素值形成的训练数据集,model为所创建的模型,参数- i 200指迭代200次,通过参数–v显示训练的过程。
根据已知属性分类事实,寻找其中的规则,所建立的模型即可对未知属性进行判断。并且可以测试分类算法的准确率,仍使用命令行:
Maxent –m model –p test_data.txt
其中model即为训练时所得的模型,test_data.txt是从训练集中随机选取的数据。
对未知属性的判断同样使用的命令行:
Maxent –m model –p test_data.txt –o output.txt
test_data.txt是测试数据量,即为未知属性的特征值,自动判断的结果存于output.txt文本中,从中过滤掉标注为“0”的非属性,图1每次循环中的过滤就是通过model模型使用命令行实现对扩展后的属性特征值分类过滤。
2.2基于Web扩展基础属性组
在自然语言中是不可能抽取完那些已用的属性。这主要是因为属性词可能是复合的,且新的复合的属性每天都在出现。例如,属性“能力”能与“飞行”和“语言”复合形成新的属性,分别为“飞行能力”和“语言能力”。因此,在获取基础属性集后还要进行属性扩展。
本文扩展属性组的方法使用连接短语模板一。
的x和NP(模板一)
使用这样一个短语模板的目的是基于Resniks的假设[8],并列部分在语义上是类似的。
给予一个可知的属性x,可以设想在模板一中的并列部分NP也是一个属性。例如,如果x是感光度,连接短语一显示了快门速度也是一个属性。
的感光度和快门速度(连接短语一)
在连接短语一显示了快门速度也是一个属性确认之前要确认两个问题:{1}并列部分NP是否是个名词短语;{2}并列的界限确定。
解决第一个问题,可以使用名词知识识别器来判定并列部分是否是名词,前提确定是名词再来确定并列的界限;另一种方法,限定并列部分的字符数为不超过6个,再查看并列部分中是否有所给定的标点符号(" , ; . , - ; 。 、 ! ! ~ ”)(( 》 ? ?: “ "等),如果有的话就过滤掉包括标点符号右边的文本,最后获得的为并列名词。
使用以上连接短语模板扩展属性获取的主要困难在于确定并列的界限。例如连接短语一,因为快门和速度都是一个名词,所以感光度和快门速度结构模糊,如连接短语二中所说明的。
a.[感光度和快门]速度
b.[感光度]和[快门速度] (连接短语二)
在a中,感光度的并列部分是快门,而在b中,相应并列部分是快门速度。现可以使用称为位置交换搜索(PES)的方法来解决这个问题。PES假设,如果A和B在并列句“A和B”是并列部分,那么很可能有“B和A”结构的语句。那么,给予一个已知的属性a和通过名词识别器所验证得到的一个可能的并列部分b。通过Web搜索短语“的b和a”来测试b成为候选属性是否合适。如果b通过了PES测试,那么将它送到Web过滤器以进一步验证。
3实验分析与结果
3.1实验设计
以Visual C++ 6.0为实验环境, 建立4个实验模块,其中第一个模块是计算分类特征值[6],第二个模块实现读入扩展后的属性集(人工认为标注都为“1”的属性)和通过分类器自动产生的属性标注,凡是自动产生的标注为“1”的属性都以正确的属性保存下来,并作为下阶段扩展属性模块的种子。本模块基于抽取属性的迭代数,来决定调用次数。
第三个,笔者通过Google查询配置出针对具体产品实体相对应的属性的最佳匹配模板,并通过语言专家组的认可,最终确定“打印机的A为”这样一个模板,基于这个模板在Web上抽取出其中的A,再过滤掉结果中的非短语结构,最后形成原始属性集。以此为基础进行下面的扩展和过滤,过滤的算法是基于第一个模块中得出的分类模型。
Google搜索限制查询结果最多1 000项,且每页面最多可显示100项。根据模板“打印机的”作为Google关键字获取1 000项查询结果,并精确定位于HTML标记“<td class=”j”><font size=-1>”和“</b><br><span”之间的内容,且过滤掉HTML标记“<” 和“>”之间及 “&”和 “;”之间的内容,以获得纯文本信息作为下一步查询“打印机的”“为”字符串中间内容的语料库。使用字符数、标点符号来过滤掉其中的一些垃圾:判断语料库 “打印机的”与“为”间隔是否超过6个字,若不超过,那6个字中是否带有标点,如有标点符号,就过滤掉包括标点以后的文本。最终获得的文本再通过短语识别器过滤掉结果中的非短语结构,最终获得的A集作为原始属性集。
第四个,笔者基于连接短语模板扩展属性种子,利用连接短语的并列特性,抽取出连接词“和”右边的并列词,作为候选属性。此模块关键在于如何确定并列词的长度界限,一般地,都要通过名词短语识别器,首先确定是一个名词,并且可通过PES实现与连接词“和”之前的属性位置交换后,仍能在Web中查找到结果。但本文是根据特定的产品实体抽取出属性,其连接模板为“(产品实体)的x和NP”,增加了一个产品实体的限定,在这种情况抽出的数据比较稀疏,能扩展的属性有限,若再增加一个条件,需通过PES交换,那结果数据将更稀疏,因此在这里省去PES交换。这里获取并列词与抽取原始属性一样,首先限定了长度,不超过6个字,且判断6个字中是否有给定的标点符号,如果有的话,就过滤掉标点符号右边的文本。经过这两个条件的筛选后,获得的文本再通过短语识别器过滤,最后的结果作为扩展到的候选属性。
3.2实验结果
根据“打印机的A为”这样一个模板,基于Web抽取出9个属性的原始属性集,然后基于以上得出的分类模型进行过滤,得到真正的属性数为7,通过语言专家对这7个属性进行评测,以确定得出其中合理的有3个属性,4个为非属性,这样就得出准确率0.43,如表1所示。以后每次迭代都对属性进行一次扩展,再对它进行过滤,根据过滤后的属性,由语言专家确定其间的合理属性数,由此得出准确率。P=人工判定的属性数/过滤后的属性数。
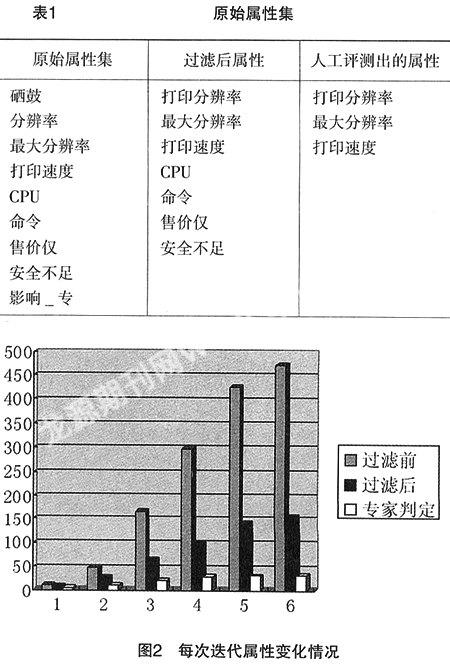
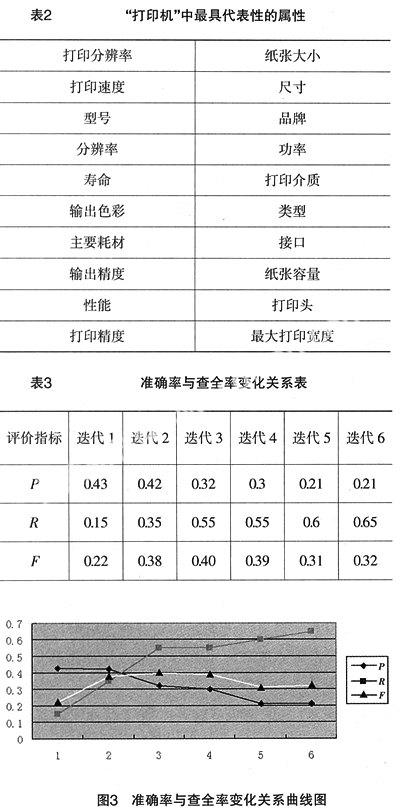
对于另一指标查全率R,首先由语言专家根据特定的产品实体“打印机”选出20个最具代表的属性,如表2所示,每次迭代后,查看这些属性在过滤后的属性中的覆盖程度,即为查全率。这样多次迭代后便得出一个准确率与查全率的关联变化的曲线图。整个迭代过程所得数据由图2所示,图2是6次迭代获得的扩展属性数、过滤后的属性数以及根据过滤后的属性数语言专家判定的合理属性数。根据这几次数据获得如表3所示的准确率P、查全率R和F综合指标,图3是相应的准确率与查全率的关联变化的曲线图,从图中可看出准确率与查全率是一对矛盾的评价指标,随着迭代的递增,查全率会增加,而准确率就相应下降,F值随着准确率P与查全率R的变化而变化。
4总结与展望
随着Internet的迅猛发展,人们对高效率的信息获取技术的需要越来越迫切,对海量信息进行采集、分析、整理,得到高质量的分门别类的结构化信息,方便用户快捷地浏览查询,是极具现实意义的重大课题。本文就是基于这个现状集中研究其中的一个分支,实现基于Web的属性抽取,以支持基于概念的搜索模型。
在基于Web实现概念属性抽取的整个方法所获得的查全率随着迭代的递增,不断增加;相反,准确率却相应下降,这个评测结果说明属性抽取方法的可行性。
由于时间的有限,本文在基于网页表格和模板的识别属性的两种方法上未进行实验性比较,只是鉴于前人的总结经验作出的选择。包括在分类算法的选择上也是如此。另要想成为一个真正的实用系统,本文提出的方法还需要很多改进工作要做:{1}缺乏全面性;{2}未建立可视化界面。针对上面的不足,我们可以在以后作进一步的深入研究,并在属性抽取基础上扩展对应的属性值,以真正能运用于商业领域搜索引擎中。
主要参考文献
[1] M A Hearst.Automatic Acquisition of Hyponyms from Large Text corpora[C]// Proceedings of the 14th Conference on Computational Linguistics,1992:539-545.
[2] S A Caraballo.Automatic Construction of a Hypernym-labeled Noun Hierarchy from Text[C]//.Proceedings of the 37th Annual Meeting of the Association for Computational Linguistic on Computational Linguistics,1999:120-126.
[3] M Berland and E Charniak.Finding Parts in Very Large Corpora[C]//Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics,on Computational 57-64.
[4] M Poesio, T Ishikawa,etal.Acquiring Lexical Knowledge for Anaphora Resolution[C]//Proceedings of the 3rd Conference on Language Resources and Evaluation (LREC),2002.
[5] A Almuhareb and M Poesio.Attribute-Based and Value-Based Clustering:An Evaluation[C]//Proc of EMNLP,2004:158-165.
[6] 吴月萍. 基于Web属性抽取训练分类模型的方法研究[J].上海第二工业大学学报,2008(1).
[7] Zhang Le. Maximum Entropy Modeling Toolkit for Python and C++[EB、OL]. URL http://homepages.inf.ed.ac.uk/s0450736//maxent-toolkit.html.
[8] P Resnik.Semantic Similarity in a Taxonomy:An Information-Based Measure and its Application to Problems of Ambiguity in Natural Language[J]. Journal of Artificial Intelligence, 1999(11):95-130.
猜你喜欢
现代装饰(2022年1期)2022-04-19
医学食疗与健康(2021年27期)2021-05-13
现代装饰(2020年2期)2020-03-03
现代电子技术(2018年20期)2018-10-24
中国交通信息化(2018年5期)2018-08-21
现代情报(2018年11期)2018-01-07
网络安全与数据管理(2016年12期)2016-08-01
