
马尔可夫模型在空间数据预取中的应用
2010-11-14 10:52李云锦钟耳顺王尔琪黄跃峰
测绘通报 2010年7期
李云锦,钟耳顺,王尔琪,黄跃峰
(中国科学院地理科学与资源研究所,北京 100101)
马尔可夫模型在空间数据预取中的应用
李云锦,钟耳顺,王尔琪,黄跃峰
(中国科学院地理科学与资源研究所,北京 100101)
在地图浏览空闲时间,将用户下一时刻可能浏览的地图数据预取至本地,可以减少下次浏览的等待时间。使用邻近区域预取,方法简单但命中率低且易造成网络拥塞。为提高预取命中率,将浏览区域的中心点视为转移状态,用Markov链表示地图浏览过程,使用Markov模型预测下一时刻可能浏览的数据。试验验证表明,Markov模型的应用有效地提高了瓦片数据的预取命中率,命中率可达40%。
预取;马尔可夫;服务式地理信息系统
一、引 言
互联网技术的进步推动了空间信息服务的发展,网络成为人们获取空间信息的主要途径。然而,由于网络带宽的限制,用户浏览空间数据时仍要长时间等待。减少等待时间常采用两种方法:缓存 (caching)与预取 (prefetching)。
大多数 GIS服务器都采用了分层分块缓存技术[1-3],预先将矢量或栅格数据输出为大小固定的瓦片(tile)。在这种模式下,客户端向服务器发送数据请求,服务器根据范围参数返回已缓存的瓦片。用户执行放大、缩小、漫游等操作后,浏览的范围改变,客户端向服务器发送新的请求。下一时刻可能浏览的瓦片与当前的浏览范围及下一步的操作相关,因此,可以在空闲时猜测下一时刻可能浏览的数据并下载至本地。最为常用的方法为邻近区域预取,即在空闲时下载与当前浏览区域相邻的瓦片。如果下一步用户执行平移操作,本地缓存可能已包括全部或部分所需的瓦片数据。邻近区域预取只考虑了平移操作,准确率低且容易导致网络拥塞。本文将重点讨论分层分块缓存模式下瓦片的预取,试图借鉴网页预取的研究成果,应用Markov模型提高预测的准确性。
在网页预取中,Markov模型的应用已有较多的研究。Bestavros最早使用转移概率矩阵描述用户的浏览特征[4],模型简单、有效。Sarukkai在 EPA服务器日志文件上的试验表明[5],采用基本Markov链模型对用户的浏览进行预测,其准确率可以达到70%左右。上述模型均采用一个Markov链描述所有用户的浏览特征,存储转移概率矩阵的复杂度是网页数量的平方,而且采用高阶转移矩阵所需的存储空间还会成倍增加。为减少存储空间、提高预测准确率,邢永康等人提出了多Markov链[6],将用户分为不同类别并用不同的Markov链表示不同类别用户的浏览特征。
空间数据浏览(包括矢量与栅格,以下统称为地图浏览)与网页浏览具有相似性,可将任意时刻窗口中的地图视为网页,将地图操作视为网页中的超链接。不使用分层分块,这样的地图有无穷多个,不能应用Markov预测模型。一种可能的方式是,使用分层分块技术将数据划分为有限个瓦片,用瓦片作为转移状态。然而,与网页浏览不同,用户可以同时浏览多个瓦片但只能浏览一个网页。文献[7-8]用前 k次瓦片移动方向作为转移状态,假定所有瓦片具有相同的转移概率,提出了邻近选择Markov链(neighbor selection markov chain,NS MC)。该模型简单,存储开销小,但是模型没有充分考虑空间数据组织形式,适合于仅有一个比例尺的情形。此外,空间地物重要性不同,被访问的几率差别较大,NS MC模型不能体现这一差异特征。本文将结合服务器缓存技术与客户端显示技术,探讨适用于地图浏览的Markov预测模型。
二、Markov预测模型
在分层分块缓存模式下,客户端向服务器发送数据请求,服务器根据空间范围返回相应的瓦片。仅就客户端而言,地图浏览过程表现为瓦片的位移与替换。如图 1所示,Ti、Ti+1分别代表 i与 i+1时刻返回给同一客户端的瓦片集合,Ti与 Ti+1大小相同,都包括 r×c个瓦片;xi、xi+1分别代表瓦片集合Ti与 Ti+1的中心。当前比例尺下,用户的浏览过程可以表示为{x0,x1,…,xi|r×c},其中 xi∈X,X为当前比例尺下所有可能中心点的集合。因此,平移过程可以表示为相同比例尺的中心点转移;放大、缩小等操作则可以表示为不同比例尺的中心点转移。
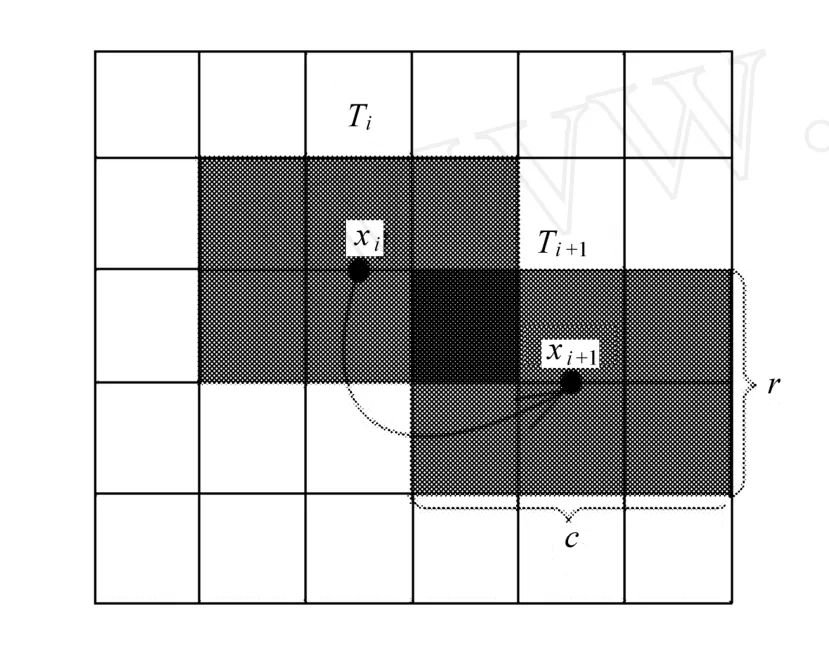
图1 地图浏览过程示意图
1.基本Markov模型
假设在地图浏览过程中,中心点转移是一个Markov过程。用随机变量 X表示中心点集合,则中心点转移过程构成一个随机变量 X的取值序列,并且该序列满足Markov性。一阶Markov模型可以用三元组MC=〈X,A,λ〉表示,其中A表示转移概率矩阵,λ为初始状态分布。采用文献[6]所述的学习方法,可以获得基本模型 (为便于论述,本文将一阶Markov模型称为基本Markov模型)的各参数。模型不能直接预测可能访问的瓦片数据,需要将中心点的概率向量转换为瓦片的概率向量。
用V(t+1)表示下一时刻中心点的概率向量,取值最大的维对应的状态 xi就是下一时刻最可能的中心点。用 n×m维矩阵 R=(rij)表示中心点与瓦片的映射关系,n为中心点个数,即状态个数,m为瓦片的个数,rij∈{0,1}。根据中心点 xi、地图窗口大小与瓦片大小,可以求得 xi对应的瓦片集合,若该集合中包含第 j个瓦片,则 rij取值为 1,否则取值为 0。
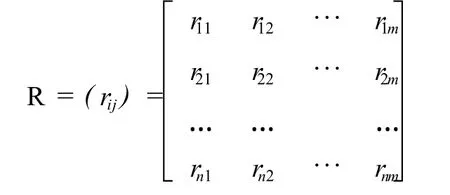
用L(t)表示 t时刻瓦片的概率向量,则 L(t+ 1)=V(t+1)×R。令 t时刻中心点对应的瓦片集合为 Tt,则预取的瓦片为不在 Tt中且 L(t+1)取值最大的 topN个瓦片。
2.高阶Markov模型
在网页预取中,采用高阶Markov预测模型可以有效地提高预测准确率。然而,地图浏览与网页浏览过程不同,更高的阶数可能不会提高预测准确率。以图 2为例,训练样本由 2个浏览序列构成: A→B→C→D与D→C→B→A,两个序列分别表示沿道路正向浏览与逆向浏览。
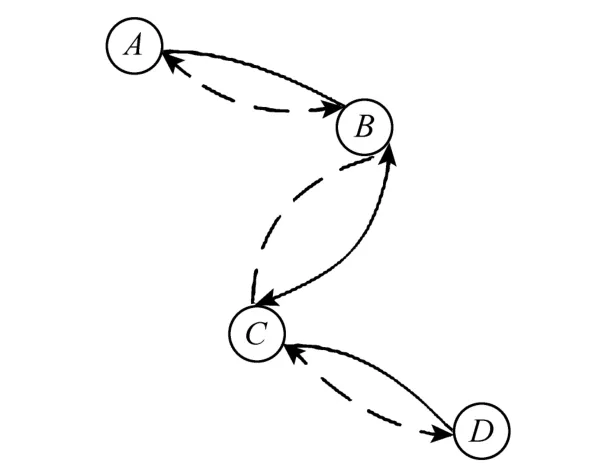
图2 地图浏览过程举例
学习训练样本,得到一阶与二阶转移概率矩阵分别为
采用加权平均法,令权值 w=[0.67 0.33],根据浏览序列 B→C计算下一时刻的概率向量,计算结果为:V=[0 0.582 5 0 0.417 5]。因此,下一时刻最可能的中心点为B。然而大量的观察表明,地图浏览具有较强的目的性,用户沿道路或某一特定方向浏览地图的几率较大,因此顺序浏览B、C后,用户浏览 D的概率一般大于 B。使用多阶Markov预测模型不能提高预测准确率。然而,在网页预取中,类似图 2所示的训练样本较少出现,这主要取决于站点的链接结构与网页浏览的习惯。首先,多数站点的结构可以认为是一种层次结构,浏览网页一般从高层次到低层次,而较少从低层次逐级返回至最上层;另外,当前网页不一定包含历史网页的链接,用户也较少浏览已经浏览过的网页。
3.其他预测模型
高阶Markov虽然使用了历史信息,但由于地图浏览的特殊性,准确率并未因提高转移矩阵的阶数而上升。另一种利用历史信息的模型为多序Markov模型,使用连续 k次浏览的中心点作为转移状态。基本的Markov模型属于多序Markov模型的一种,即 k=1。多序 Markov模型的学习类似于基本Markov模型的学习,只是需要事先将训练样本转换为 k序状态的序列。此外,多序Markov模型的状态空间较大,历史信息的匹配几率较小,即历史状态很可能并未出现在训练样本中,此时预测失败。为解决该问题,可以使用多序组合模型,对 1,2,…,k序预测结果加权平均。为便于讨论,以下称 1,2,…,k序预测加权平均模型为 k序Markov模型。
此外,为了降低存储复杂度,还可以对Markov链聚类。首先采用加权平均法计算浏览序列的平均中心,用 dai表示 di的平均中心。di={xj|xj∈X},其中,wi为中心 xi对应的权值,且中心xi的比例尺越大,其权值wi越大。然后,根据序列的平均中心将样本划分为 k类,并建立每个类别的Markov模型,判别准则为空间距离。
4.存储复杂度比较
令训练样本中中心点个数为 n,则基本Markov模型的存储复杂度为 O(n2)。h阶Markov模型需要存储 1,2,…,h阶转移概率矩阵,因此存储开销是基本模型的 h倍,复杂度可表示为O(h×n2)。k序Markov模型需要存储 1,2,…,k序的转移概率矩阵,其中 1序概率矩阵的开销为 n2,而 2,…,k序的状态个数不等于 n。粗略计算,可以认为各序状态均为 n,则存储复杂度可表示为O(k×n2)。就基本聚类Markov模型而言,设平均每个类别的状态数为n′,分类数目为 c,则每个子类的存储复杂度约为O(n′2),总的存储复杂度为 O(c×n′2)。
三、试验分析
为建立Markov预测模型,我们使用了缓存服务器的 26 437条日志信息,信息包括:请求时间、IP地址、中心点坐标、当前比例尺与地图窗口大小。对数据进行预处理,将日志文件整理为浏览序列集。预处理步骤为:①根据 IP地址将日志文件分解成独立的请求记录集;②将每个请求记录集按时间排序,设立时间窗口阈值 tw,分割请求记录集,时间间隔小于 tw的相邻操作属于同一浏览序列,然后所有序列组成用户浏览序列集;③所有用户的浏览序列集组成服务器浏览序列集,即训练样本。设 tw= 10m,记录集被转换为 2 011条请求序列,平均每个序列的长度为 26 437/2 011≈13。定义预取命中率为预取的瓦片恰好在下一时刻被访问的几率。
试验 1比较了基本Markov模型与邻近预取方法,对比结果如图 3所示。从浏览序列集合中随机选取了 80%的序列用于建立基本Markov模型,并将其余 20%序列用于验证模型的有效性。试验记录了预取瓦片数(topN)在 1~60变化时,基本预测模型的预测准确率。随着预取瓦片数的增加,虽然平均每次预测命中瓦片数呈上升趋势,但预测的命中率呈下降趋势。例如,topN=22时,平均每次预测命中的瓦片数为 6.19,预测准确率为 38.9%; topN=52时,平均每次预测命中的瓦片数为 8.34,预测准确率为 28.9%。试验 1还记录了Buffer大小分别为 1与 2时,邻近预取的准确率。使用邻近预取方法,预取的瓦片数目取决于客户端窗口大小及Buffer大小。以 4×5客户端为例,若 Buffer大小为1,则预取的瓦片数目为 (4+2)×(5+2)-4×5= 22,此时预取命中率为 8.28%;Buffer大小为 2时,预取的瓦片数目为 52,预取命中率为 3.79%。
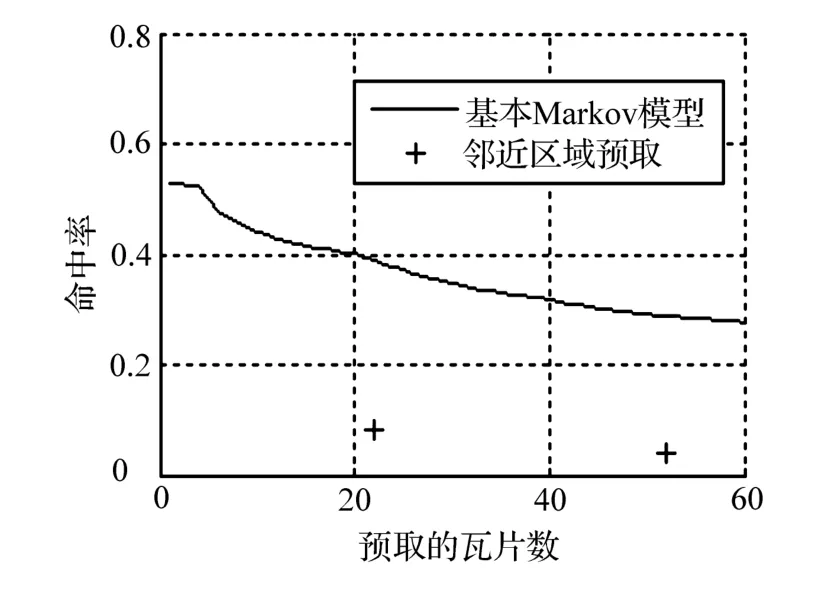
图 3 基本Markov模型与邻近区域预取比较
使用与试验 1相同的学习序列集与验证序列集,试验 2比较了基本Markov模型、高阶Markov模型、多序Markov模型及聚类模型四类模型的预测准确率,比较结果如图 4所示。结果表明,相对基本Markov模型而言,增加转移概率矩阵的阶数并没有提高命中率;使用多序Markov模型可以提高命中率,且序列越长,命中率越高;使用系统聚类后,预取的命中率有所下降。以 topN=5为例,预取命中率由低至高排列为:基本聚类,二阶Markov,基本Markov,二序Markov,三序 Markov,二序聚类,命中率分别为:46.3%,47.5%,49.9%,54.8%,56.7%, 57.3%。试验 2中,基本聚类与二序聚类使用的类别数等于22。
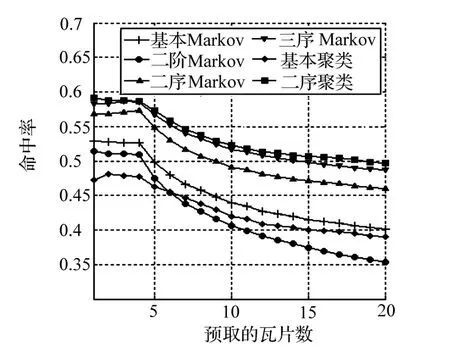
图4 四类模型的对比结果
分类的结果决定了模型的空间复杂度,试验 2中的训练样本在聚类前具有 1 580个不同的中心点,因此基本模型的存储开销为 1 5802=2 496 400。采用系统聚类后,平均每个子类的状态数小于聚类前的状态数。试验 3将训练样本划分为 4~30个子样本,统计每种聚类情形下所需的存储空间;此外,试验 3设定 topN=10,分别统计各种情形下的预取命中率,统计结果如图 5所示。试验结果表明,当分类数在 4~30间变化时,分类的数目对预取命中率影响较小,波动范围在 2%以内;随着分类数目的增加,存储开销呈下降趋势。以类别数等于 20为例,平均每个子类包括 63个转移状态,总的存储开销约为 20×912=165 620,约为基本Markov模型存储开销的6.6%。这种分类方式下,聚类模型的预取命中率为43.5%,使用相同的 topN,基本Markov模型的命中率为44.4%,聚类模型的命中率略低。
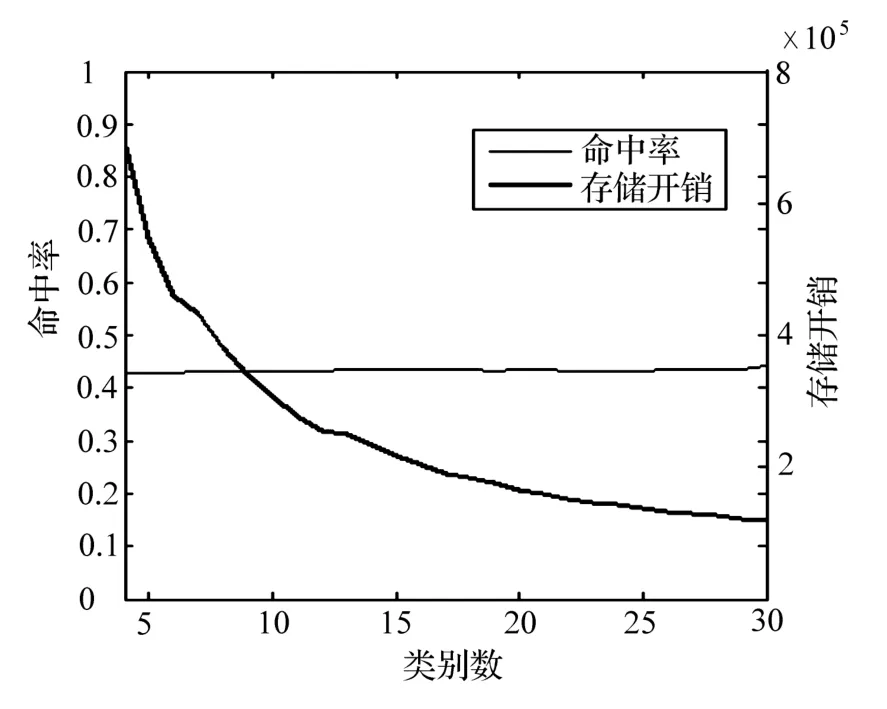
图 5 基本聚类Markov模型的命中率与存储开销
四、结 论
以浏览区域的中心点作为转移状态,可以建立地图浏览的Markov模型。采用瓦片作为转移状态,一次地图操作可能导致多个瓦片同时转移,学习与预测过程都较本文所述方法复杂。试验表明,基本Markov模型能有效提高预取的命中率,与邻近区域预取方法对比,在同取 22个瓦片的情形下,两者命中率分别为 38.9%与 8.3%。使用高阶Markov模型,在网页预取中一般能获得更高的命中率,但在瓦片预取中命中率可能会更低,这主要取决于地图浏览与网页浏览的差异。多序Markov模型有效地利用了历史信息,试验表明,序列越长,命中率越高。使用空间聚类,能有效地降低存储复杂度,但并没有提高命中率,这主要是由于空间聚类过程并未充分利用历史的访问信息。如何优化聚类方法,提出更合理的聚类准则,在降低存储复杂度的同时提高预取命中率,是今后研究的重点。
[1] 陈静,龚健雅,朱欣焰,等.海量影像数据的Web发布与实现[J].测绘通报,2004(1):22-25.
[2] 陈能成,龚健雅,朱欣焰,等.多级缓冲提升海量影像数据在线服务质量[J].测绘通报,2007(6):19-22.
[3] 李锐,潘少明,喻占武.基于主动缓存的 P2P海量地形漫游瓦片调度算法 [J].测绘学报,2009,38(3): 236-249.
[4] BEST AVROSA.Using Speculation to Reduce ServerLoad and Service Time on theWWW[C]∥Proceedings of the Fourth InternationalConference on Information and Knowledge Management.Baltimore,Maryland,United States:ACM Press,1995:403-410.
[5] SARUKKA I R R.Link Prediction and Path Analysis U-singMarkov Chains[C]∥Proceedings of the 9th International World W ide Web Conference on Computer Networks. Amsterdam, The Netherlands:North-Holland Publishing Co,2000:377-386.
[6] 邢永康,马少平.多 Markov链用户浏览预测模型[J].计算机学报,2003,26(11):1510-1517.
[7] K IM Y S,K IM K C,K IM SD.Prefetching Tiled Internet Data Using a Neighbor SelectionMarkov Chain[J].Lecture Notes in Computer Science,2001,2060:103-115.
[8] LEE D H,K IM J S,K IM S D,et al.Adaptation of a Neighbor Selection Markov Chain for Prefetching Tiled Web GIS Data[J].Lecture Notes in Computer Science, 2002,2457:213-222.
MarkovM odel in Prefetching SpatialData
L I Yunjin,ZHONG Ershun,WANG Erqi,HUANG Yuefeng
0494-0911(2010)07-0001-04
P208
B
2009-09-01
国家 863计划资助项目(2007AA12Z213,2007AA120501)
李云锦(1984—),男,湖北仙桃人,博士生,研究方向为 Service GIS、空间数据的多尺度表达。
猜你喜欢
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
浙江大学学报(理学版)(2020年1期)2020-03-12
电脑报(2019年4期)2019-09-10
扬子江(2019年1期)2019-03-08
中国生殖健康(2019年11期)2019-01-07
长江丛刊(2018年31期)2018-12-05
NBA特刊(2017年8期)2017-06-05
大众摄影(2015年9期)2015-09-06
梧州学院学报(2015年3期)2015-02-28
