
基于谱减的双元指向传声器阵列语音增强
2011-01-13 03:01廖逢钗卢昌荆
武夷学院学报 2011年2期
廖逢钗 卢昌荆
(三明学院 数学与计算机科学系,福建 三明 365004)
基于谱减的双元指向传声器阵列语音增强
廖逢钗 卢昌荆
(三明学院 数学与计算机科学系,福建 三明 365004)
设计了一种结构简单的用于语音增强的双元指向性传声器阵列,利用阵列中不同方位阵元对目标信号和干扰信号的增益不同的特点,有效估计噪声信号的功率谱,再利用传统谱减算法的思想,实现语音增强。实验结果表明提出的算法是有效的,与经典的谱减算法相比具有更佳的语音增强效果。
谱减;传声器阵列;语音增强;傅立叶变换;衰减系数
引言
在实际应用中,由于环境噪声的干扰,许多语音信号处理系统的性能急剧下降,导致语音的质量变差。语音增强算法就是从被污染的带噪语音信号中提取尽可能纯净的目标信号,改善语音信号的质量,它可分单通道语音增强和多通道语音增强。基于短时幅度谱估计的语音增强算法[1][2]、基于语音生成模型的语音增强算法[3]、基于听觉模型的语音增强研究[4]和基于人工神经网络的语音增强算法[5]等都属于单通道语音增强。传统谱减法[1](Classical Spectral Subtraction,CSS)是最常用的单通道语音增强算法,它具有计算量小、易于实时实现等优点,在鲁棒语音识别、助听器、语音编码技术、信号分离等领域得到了广泛的应用[6-10]。但在传统的谱减算法中,噪声的估计是用无音期间的加权平均值来代替当前分析帧中各频点的噪声频谱分布。由于噪声频谱服从高斯分布,其幅度随机变化的范围很宽,因此在相减时,如果某频点处噪声分量较大,就会产生很大的残留噪声,即 “音乐噪声”,这是谱减法中常出现的问题。近几年,在高档的语音信号处理系统中,引进多通道语音增强算法,它可以有效解决上述问题,但它在数据采集时需要较多的通道数,设备复杂,计算量随着通道数的增加而增大。
针对以上不同算法存在的问题,本文结合传统谱减算法,提出二元指向性传声器阵列谱减 (Dual Directivity Microphone Array Spectral Subtraction,DDMASS)语音增强算法。DDMA-SS算法在硬件方面要求不高,只要能双通道录音即可。在算法方面,计算量和CSS相当,它利用阵列中不同方位的阵元对目标信号和干扰信号的增益不同来估计目噪声信号的功率谱,最终实现语音增强的目标。DDMA-SS算法与传统的单通道谱减算法相比,不论目标语音是否存在,它都可以实时估计噪声功率谱密度,增强后语音的残留音乐噪声明显削弱。
1 算法描述
1.1 经典谱减算法
经典谱减法[1]的基本思想是:假设噪声是平稳的加性噪声,并且假设目标信号和噪声是相互独立的,那么就可以从带噪语音的幅度谱(或功率谱)中减去噪声的幅度谱(或功率谱),从而得到较为纯净的目标信号的频谱。假设信号模型是:

s(k)、n(k)是时域信号经过加窗处理后的目标语音信号和加性噪声信号,x(k)是合成后的信号。(1)式傅立叶变换得到:

经典谱减可以用以下式子表示:

其中,H(ejω)是谱减滤波器,可以通过以下方法计算:

这里,μ(ejω)代表噪声的频谱,它的幅度是用无语音活动期间的噪声平均值来代替,相位用X(ejω)的相位替代。谱减之后用逆傅立叶变换和帧叠加处理即可获得增强后的语音。
基本谱减算法用静音时的幅度谱(或功率谱)作为噪声幅度谱(或功率谱)的估计值,在平稳噪声场合可以获得满意的效果,而在非平稳噪声的情况下效果变差,有残留音乐噪声产生。为此,下面引入DDMA-SS算法。
1.2 二元指向传声器阵列谱减算法
1.2.1 传声器阵列的拓扑结构
图1是用于实现DDMA-SS算法的传声器阵列的拓扑结构示意图,A和B是指向性传声器,它们的间距为d,它们的极性图相差π,设目标信号S在A传声器的正前方,干扰信号n在另一侧。
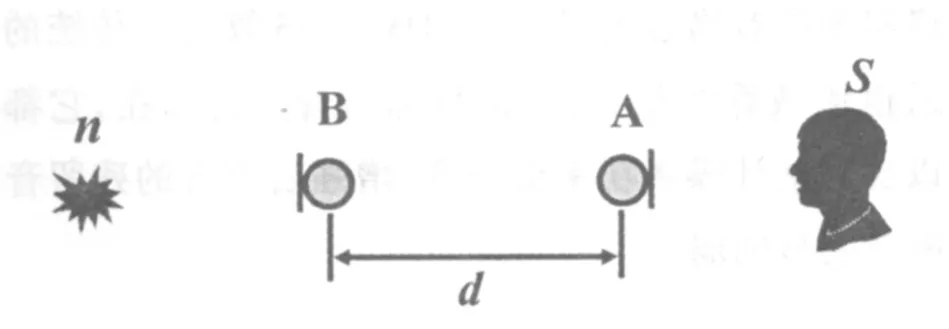
图1.DDMA-SS算法的传声器阵列的拓扑结构示意图
1.2.2 DDMA-SS算法
图2是DDMA-SS算法流程的示意图,算法主要由快速傅立叶变换(FFT)、谱减(SS)、衰减系数估计(attenuation coefficient estimate,ACE)、逆傅立叶变换-叠加(IFFT-ADD),语音活动检测(Voice Activity Detection,VAD)等几个模块构成。下面介绍算法的原理。
设纯净目标语音和加性干扰噪声分别是s、n,两个指向性传声器A、B接收到的时域信号x1、x2可以近似表示为(在下文为了叙述方便,分别称对应的两个通道为A通道和B通道):

图2.DDMA-SS算法流程示意图

这里λ和μ分别是干扰噪声和目标语音的相对衰减系数(0≤λ≤1,0≤μ≤1),它主要由传声器的指向特性决定的。式(5)、(6)离散傅立叶变换后得:

其中,i是频点 (1≤i≤ L,L=2mm ∈Z+,L 是帧长)。由(7)、(8)可得:
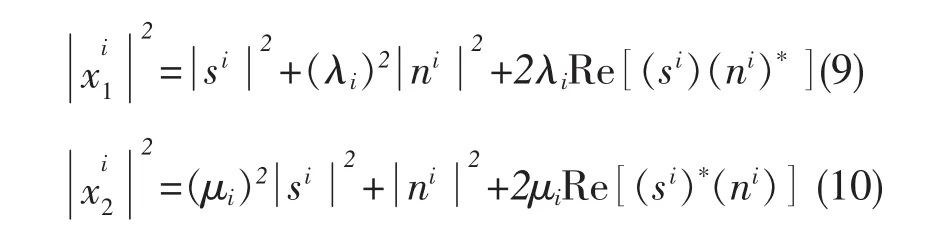
其中,Re(·)表示求互相关值。由于目标语音s和加性干扰噪声n是独立的、所以si和ni也是独立的,所以有:
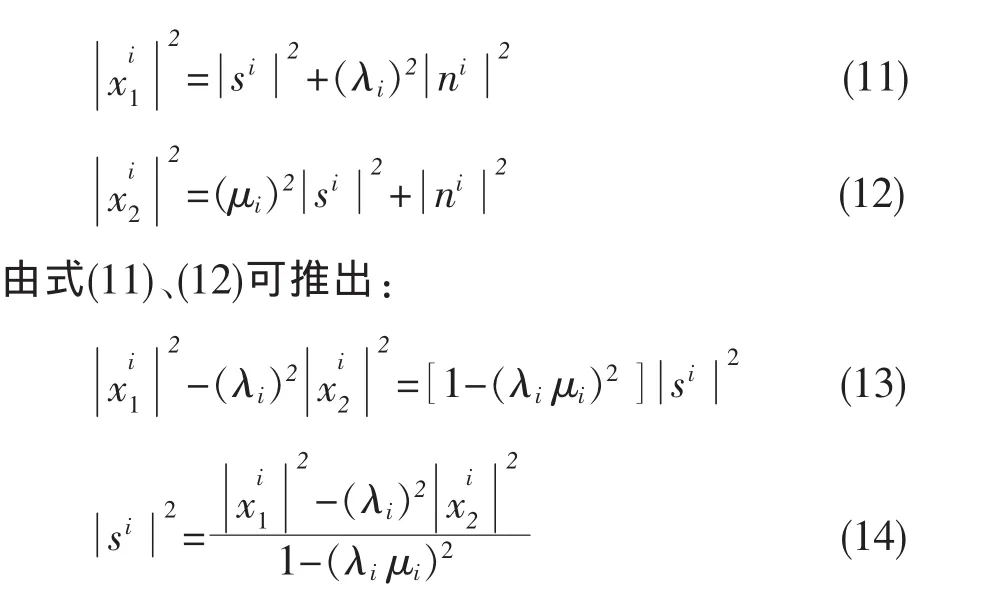
(14)式的分母部分只与衰减系数有关,可以看作常数,只影响最终总体信号的强弱。另外,在实际应用中往往(λiμi)2<<1,所以忽略分母部分得:
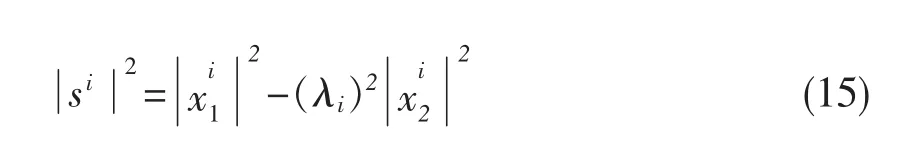
(15)式的物理意义是:一帧内,目标信号s的i第频点的功率谱可以通过以下两个步骤获得:
①传声器B接收信号的第i频点的功率谱衰减(即乘以(λi)2)后作为噪声功率谱的估计值;
②从传声器A接收信号的第i频点的功率谱减去①估计的噪声功率谱,即可得到目标语音频谱的估计值。
以上两个步骤的关键是确定衰减系数λi,它可以通过目标语音不存在时,两个通道第i频点的功率比值获得,即令(15)式左边等于零,并整理得:

这里,下标VNA表示目标语音不活动 (Voice No Activity),即只有干扰噪声。
求得λi后,由(15)式可以获得目标语音幅度的估计值:
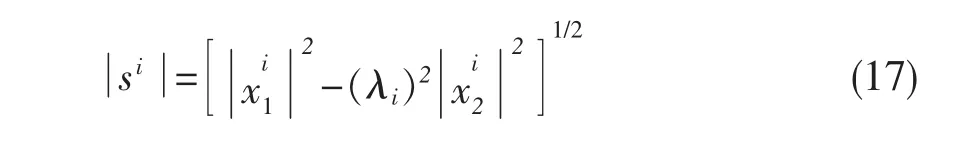
最后,si的相位用的相位代替,使用逆傅立叶变换及合成处理得到增强后的语音:

2 实验评估
2.1 实验条件和评估数据
实验数据是利用USB总线接口的2路同步数据采集系统录制的,采样频率8KHz,采样位数16bit。实验环境是一房间,长、宽、高分别是3500mm、3100mm和2650mm。为了方便控制信噪比,用两个扬声器分别播放录制好的噪声和语音。
语音的内容是中文 “近似”、“景致”、“进行曲”、“酒家”、“举例”等词组。选用的噪声是机场噪声、计算机噪声、风扇噪声等。实验时,A通道的信噪比控制在0dB左右,总共采集30组实验数据。对信号进行处理时,采用汉明窗进行分帧,每帧256个采样点(32ms),帧移40%。
2.2 实验结果与分析
图3是实验的一个语音信号波形实例,(a)、(b)、(c)、(d)、(e)分别是纯净的参考语音波形、通道A的时域波形、通道B的时域波形、CSS算法的输出波形、DDMA-SS算法的输出波形。图4是图3对应的谱图。相比于A通道信号,用CSS算法和DDMA-SS算法增强后的语音信号信噪比平均改善分别是2.1dB和2.6dB,增强后的语音清晰,背景噪声基本被抑制。通过人工反复试听发现,DDMA-SS算法采用了两个指向性传声器对噪声信号和目标信号的不同抑制作用来估计噪声的功率谱,所以它与CSS算法相比,残余音乐噪声得到明显的改善。
3 结论
在谱减算法的基础上,提出基于谱减的二元指向传声器阵列语音增强算法,实验结果表明,该算法可以有效抑制残留音乐噪声。但本文研究的声源比较单一,对复杂声源的情况有待进一步研究。
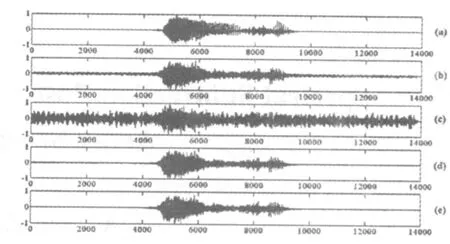
图3.语音信号波形实例

图4.语音信号谱图实例
[1]S.F.Boll.Suppression of acoustic noise in speech using spectral subtraction [J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1979,vol.27(no.2):113.
[2]EPHTSIM Y ,MALAH D .Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1984,vol.32(no.6):1109.
[3]LIM F,OPPENHEIM A V .All-pole modeling of degraded speech [J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1978,vol.26(no.3):197.
[4]VIRAG N.Single channel speech enhancement based on masking properties of the human auditory system[J].IEEE Transactions on Speech and Audio Processing,1999,vol.7(no.2):126.
[5]TAMURA S.An analysis on a noise reduction neural network[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1989,vol.3:2001.
[6]Xu,H.;Tan,Z.-H.;Dalsgaard,P.;Lindberg,B..Robust Speech Recognition by Nonlocal Means Denoising Processing[J].IEEE signal processing letters,2008,vol.15:701.
[7]IOSIF MPORAS;TODOR GANCHEV;OTILIA KOCSIS;NIKOS FAKOTAKIS.SPEECH ENHANCEMENT FOR ROBUST SPEECH RECOGNITION IN MOTORCYCLE ENVIRONMENT [J].International Journal of Artificial Intelligence Tools,2010,vol.19(no.2):159.
[8]Fa-Long Luo;Arye Nehorai.Recent Developments in Signal Processing for Digital Hearing Aids[J].IEEE Signal Processing Magazine,2006,vol.23(no.5):103.
[9]Chatree BUDSABATHON;Akinori NISHIHARA.Dithered Subb and Coding with Spectral Subtraction [J].IEICE Transactionson Fundamentals of Electronics,Communications and Computer Sciences,2006,vol.E89-A(no.6):1788.
[10]Hsu,C.-L.On the Improvement of Singing Voice Separation for Monaural Recordings Using the MIR-1K Dataset[J].IEEE transactions on audio,speech,and language processing,2010,vol.18(no.2):310.
Spectral Subtraction Based on Dual Directivity Microphone Array Speech Enhancement
LIAO Fengchai LU Changjing
(Mathematics and Computer Department,Sanming University,Sanning,Fujian 365004)
A simple dual directivity microphone array used to speech enhancement is designed,noise power spectral is est mated availably using the characteristic that difference azimuth element in array has difference gain to object signal and interfere signal.Any more,achieves speech enhancement using the idea of classical Spectral Subtraction.Experiment result indicates that proposal algorithm is effective,and it’s speech enhance ment effect is better than classical Spectral Subtraction algorithm.
Spectral Subtraction ;microphone array;speech enhancement;Fourier transform ;attenuation coefficient
TN641
A
1674-2109(2011)02-0073-04
2011-01-31
福建省自然科学基金(2009J01296)。
廖逢钗(1968-),男,汉族,副教授,主要研究方向:语音信号处理和嵌入式技术。
book=4,ebook=242
猜你喜欢
科学技术创新(2021年31期)2021-11-27
空军工程大学学报(2021年2期)2021-05-29
福建质量管理(2020年11期)2020-06-18
通信电源技术(2020年2期)2020-02-22
制导与引信(2018年2期)2018-11-09
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
中国测试(2017年4期)2017-07-18
人民论坛(2015年8期)2015-09-10
火控雷达技术(2014年1期)2014-06-23
