
基于Filter-ary-Sketch数据结构的骨干网异常检测研究
2011-08-10 01:51郑黎明邹鹏韩伟红李爱平贾焰
通信学报 2011年12期
郑黎明,邹鹏,韩伟红,李爱平,贾焰
(1. 国防科学技术大学 计算机学院,湖南 长沙 410073;2. 装备指挥技术学院,北京 100029)
1 引言
随着互联网技术的不断发展以及各类网络应用爆炸式增长,计算机网络已经成为影响我国政治、经济、军事、文化的一个重要因素。但与此同时网络安全问题却日趋严峻,流量异常和网络攻击变得日益频繁,如DDoS、蠕虫爆发、大规模端口扫描等。为了尽早发现大规模网络安全事件,需要在骨干网上进行异常检测并对恶意流量进行阻断,这样才能把恶意流量造成的危害降到最低。但是已有的网络异常检测系统存在诸多问题,不能满足高速骨干网上异常检测的要求,总得来说有以下几点。
1) 已有入侵检测系统通常是面向主机或者面向局域网的,不能适应大规模高速网络环境,但是在蠕虫快速传播的早期对其进行检测,或者遭受DDoS攻击时尽可能靠近源地址检测又尤为重要。现有骨干网的实时海量流量数据使得已有的各类异常检测系统很难适应,以10Gbit/s的骨干网为例,报文以每秒百万的速率到达,假设每个报文40byte,报文达到的时间间隔仅为32ns。
2) 已有入侵检测工具如Snort、Bro等都采用特征匹配的方法,需要对每个数据分组的内容和特征样本进行匹配,随着网络中恶意代码数量的增加,特征库越来越大,异常检测性能随着特征样本数量的增加急剧下降,同时它还无法检测未知特征攻击。
3) 为了应对挑战,研究者提出了多种流量异常检测方法,如基于统计、机器学习和数据挖掘的方法等。按照数据来源的聚集层次,可以分为2类:基于全部(或者符合一定条件的子流量)流量值的方法和基于 Flow级别的方法。基于总体流量值的方法虽然需要的存储开销和计算资源都较少,但是容易造成检测精度不高,无法定位异常,不能提供异常的详细信息,更重要的是只针对某种特定攻击检测效果比较好,而对其他类型的攻击则存在假阳性或者假阴性概率比较高的问题。如在路由器上基于变点检测(CPM)技术[1]或者基于 CUSUM 算法的SYN防洪攻击检测系统[2],它们针对整体流量中的SYN-FIN或者 SYN-SYN/ACK数据分组对的统计行为进行异常检测。基于 Flow的方法检测精度较高,能定位异常,给管理者提供异常的详细视图,但存储开销和计算消耗较大,很难直接适用于大规模高速骨干网络。例如基于 Flow流统计的异常检测方法[3],需要保存每个 Flow流的状态信息,而Flow流由五元组构成,保存每个Flow流信息需要2104bit的存储开销,无法满足骨干网上异常检测要求。特别当面对利用大规模僵尸网络发起的 DDoS攻击时,基于 Flow流统计的异常检测系统将出现内存溢出问题。
异常检测因能检测“zero day”攻击且适用于高速网络而获得了广泛的应用,主要思想是通过历史流量得到一个正常的流量模型,然后通过检测在短期内不符合此模型的行为来发现异常。但是现有的高速骨干网通常每秒到达的 IP分组以百万计,在IPv4网络环境下单个维度的地址空间达 232,用已有算法直接处理骨干网上流量数据来检测异常是不可行的,通常可以采用降维的方法来减少需要处理的数据量。目前对流量数据进行降维的方法主要有:采样、聚集、主成分分析法 PCA(principal component analysis)和sketch(概要数据结构)。文献[4]指出采样是一个有损的信息处理过程,会丢弃重要信息,它研究采样对各类检测算法的影响,实验证明通过采样后的数据进行异常检测将会导致异常检测算法误差增大;对网络流量进行聚集可能导致恶意流量聚集后呈现正常流量的行为特征,而正常流量聚集后呈现异常流量行为特征[5];PCA是一种坐标变化方法,它将给定数据点映射到一些新的坐标轴,这些新的坐标轴就成为主成分,文献[6]提出了利用 PCA进行流量异常检测,不过算法相对复杂度高,只能进行事后异常分析,不能满足骨干网上异常检测要求。Sketch数据结构来源于数据流研究领域,是对大流量一次经过的数据进行快速查询,即在数据流上维持一个实时更新的摘要数据,在一定精度保证下快速回答用户的查询请求[7]。Sketch 是一种高效的概要数据结构,它占用的内存资源少,甚至可以移植到SRAM中,计算和更新的复杂性也小,通常能够达到O (ploy(logn0))(n0为不同数据标识的数目),且在理论上有精度保证,能够满足大规模网络条件下实时流量数据处理的要求。Sketch数据结构已经广泛应用于网络安全领域,文献[8]利用 Hash函数建立了 Count-min概要数据结构;Krishnamurthy 等人在文献[9]中提出k-ary sketch概要数据结构,应用于变点检测,并提出一种启发式方法自动设置sketch的参数;在文献[9]的基础上,Schweller 等人在文献[10]中采用 IP 地址分块 hash和IP扰乱2种方法来解决sketch 可溯源性问题;最近Dewaele 等人在sketch 的基础上应用非高斯边缘分布(non Gaussian marginal distribution)的多时间尺度特性进行异常检测,可以检测多种攻击,包括检测低强度持续时间长的攻击和持续时间短的端口扫描攻击[11]。在众多的概要数据结构中,k-ary sketch概要数据具有最优的时间和空间约束,能够有效地应用于异常检测。但是概要数据结构的异常检测方法不能提供攻击者的详细信息,虽然文献[10,19]提出了相关算法,能够逆向还原出源IP地址,但是相关算法复杂度高,计算量较大,而且现在攻击普遍采用IP欺骗技术,还原出源IP作用并不明显。
为了提高异常检测系统的检测精度,研究者开始通过对流量数据的分布特征进行监控来检测异常,采用熵对分布特征进行度量。基于熵的异常检测系统的主要思想是:一旦有异常流量发生时,总体流量在各个维度上的分布应该会发生变化,通过熵值的变化能够检测出该异常。文献[12]通过流量特征上的熵值把流量分为异常和正常2类分量来进行异常检测;文献[13]首次提出在高速IP网络上利用熵值来检测蠕虫和流量异常;文献[14]通过比较当前分布和基准分布的差异来进行异常检测,且基于最大熵原理,提出了一种灵活计算基准分布的方法;文献[15]通过把分布的特征分为2类:数据分组头特征和行为特征,发现它们熵值序列之间的相关性,提出了在实现基于熵的异常检测系统时需要注意的若干问题。但是上述算法的空间和时间复杂度较高,通常时间复杂度为O(ploy(n0)),空间复杂度也为O (ploy(n0)),只适应于事后异常分析或者低速网络环境下的异常检测,不能满足骨干网上异常检测要求。
本文引入数据流中概要数据结构的思想,提出Filter-ary-Sketch数据结构,在该数据结构上采用基于熵的异常检测算法在骨干网上进行异常检测。首先把骨干网上海量流量数据通过 Hash映射随机投影到Filter-ary-Sketch数据结构中,再通过熵值的变化来检测异常,通过不同维度熵值变化情况来判断异常类型。检测到异常后,通过 Filter-ary-Sketch中各个桶内统计量差值的变化情况来定位异常点,最后通过Bloom Filter中存储的源IP信息进行恶意流量阻断。
本文主要贡献:
1) 在 k-ary概要数据结构的基础上,提出了Filter-ary-Sketch概要数据结构,解决了以往异常检测后不能直接定位异常流量的问题。
2) 在 Filter-ary-Sketch数据结构上对网络流量各维度熵值进行高效并行计算,解决以往基于熵的异常检测不能进行实时异常检测和不适应高速骨干网的问题。
3) 针对已有异常检测方法进行恶意流量阻断成本高的问题,本文在Filter-ary-Sketch数据结构中放置Bloom Filter存储源IP信息,利用随机Hash函数的特点识别恶意源IP。
第2节对异常检测中的关键数据结构和算法进行描述,第3节对异常检测流程进行详细描述,第4节使用真实数据验证本文所提检测方法的有效性,第5节为结束语。
2 数据模型与算法
2.1 多维十字转门模型
数据流描述模型有多种,如时间序列模型、缓冲寄存器模型、十字转门模型等。所提方法需要在多个维度上进行随机散列投影,且需要实时更新到达IP分组的数目,所以在十字转门模型的基础上进行多维扩展,提出多维十字转门模型。网络流量数据具有多个不同的维度,假设维度数为 d,则每个数据项可描述为Xi=[xi,1,xi,2,…,xi,d],Dom(xj), 0≤j ≤d表示各个维度的取值空间,流量数据在不同维度的取值空间上具有不同的分布。文献[15]研究了多个不同维度上熵值时间序列之间相关性,通过骨干网上实际采集的流量数据,分析了不同维度上熵值时间序列两两之间的相关性,对熵值异常检测中维度选择提出了一些建议,本文针对骨干网上异常检测的需求,借鉴文献[15]的结论,选择源IP、目的Port和IP数据分组长度3个相关性较少的维度作为熵值异常检测的特征维度。下面对多维十字转门模型进行定义。
定义1 多维十字转门模型:L=a0,a1,…为数据项逐个连续到达的输入流,其中每个数据项 ai=(SIPi, Dporti,Plengthi,ui),SIPi, Dporti,Plengthi为该数据项各维度上的标识,为了阐述方便定义identityi=σ[SIPi,Dporti,Plengthi],表示当前讨论投影维度上的标识。ui表示该数据项的特征值,[N]k= σk[Dom(SIP),Dom(Dport),Dom(Plength)]={0,1,…, nk-1}为流数据模型当前投影维度的取值空间。U[identityi]表示对所有标识为 identityi数据项的统计量,当一个数据项到达时,更新其标识所对应的统计量,即U[identityi]+= ui。
在骨干网异常检查应用场景下,多维十字转门模型中每个数据项可取IP数据分组数目或字节数,本文采用了IP数据分组长度作为分析维度,数据项记录IP数据分组数目,特征值统一定义为IP分组的数目,在每个数据项到达时ui=1,所提方法主要通过计算各个维度上 IP数据分组数目的分布变化情况来检测异常。
2.2 Filter-ary-Sketch数据结构
骨干网上异常检测过程中对流量数据的处理具有以下特点:①流量数据海量、无限、快速到达;②需要连续跟踪处理结果;③因数据量大,数据一经处理,大部分情况不再存储;④实时性要求比较高;⑤仅要求获得近似结果。针对上述特点,本文提出了Filter-ary-Sketch数据结构,其包括3个部分:Hash函数、Filter-ary-Sketch数据结构、Filter-ary-Sketch数据结构上定义的操作。
散列函数是随机投影技术的核心,它把高维度的流量数据向低纬度空间进行随机投影,是一种典型的压缩映射。散列函数的取值空间通常远小于输入空间,不同的输入可能会散列成相同的输出,也不可能从散列函数值来唯一确定输入值,即散列函数存在碰撞问题和不可逆性。为了让所提方法具有普遍适用性,同时把碰撞的概率控制在一定范围之内,本文选择通用散列函数。
定义2[19]通用散列函数簇(universal散列classes):G是从A映射到B的一系列函数,如果G满足∀x,y∈A,且x≠y,则x, y在G的所有函数下碰撞的次数C≤G B,则称G为通用散列函数簇。从通用散列函数簇随机取一个函数,具有性质:∀x,y∈A,且 x≠y,则 P(f(x)=f(y))≤1/|B|。
通用散列函数具有很好的性质,能够把冲突概率控制在一定范围内,也可以保证数据项标识均匀分布,选择通用散列函数簇中独立的h个散列函数,只要h足够大就能保证Filter-ary-Sketch数据结构上定义的算法误差足够小。本文所提异常检测方法不需要对单个Key值对应的统计量进行精确估计,只需要确保经过散列后的函数值满足均匀性分布即可,所以采用文献[19]中提出的通用散列函数簇,即
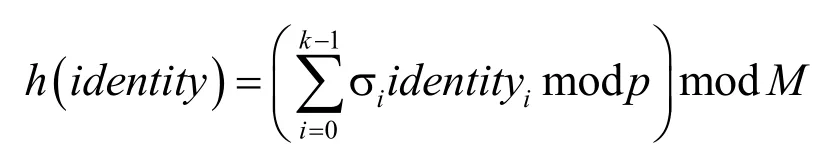
其中,p是大于identity空间[N]k元素个数的素数,δi为素数空间[p]中任意元素,k表示通用散列函数级别,因本文所提方法不需要文献[9,10]中对单个散列桶内统计量进行精度估计,为了较少计算复杂度,k取值2。
Filter-ary-Sketch数据结构在单个维度上用一个h行M列的二维数组来存储统计量,对应h×M个计数器。数组的每一行对应一个散列函数,每行中的M个计数器表示散列函数的M个桶,每个计数器记录散列到此桶的数据流元素的特征值统计量,其中 Mi[0]用于存储熵值计算的结果。所提方法需要在多个维度上进行熵值计算,同样也需要在各个维度上构建Filter-ary-Sketch概要数据结构,整个概要数据结构的结构如图1所示。
为了在异常检测后能够对恶意流量进行阻断,在每个散列函数输出桶位置对应一个 Bloom Filter数据结构,存储散列到该桶内的源IP地址。Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能快速判断一个元素是否属于这个集合。通过Bloom Filter数据结构存储投影到该桶的源IP地址,当有异常发生时,首先寻找异常点对应的散列函数存储桶,对新到达的IP数据分组提取源IP地址,在异常桶位置对应的Bloom Filter上进行查询,然后根据多个Bloom Filter上的查询结果综合判断是否属于恶意 IP,从而实现恶意流量阻断。Bloom Filter具体的工作原理参看文献[18],在此不再赘述。
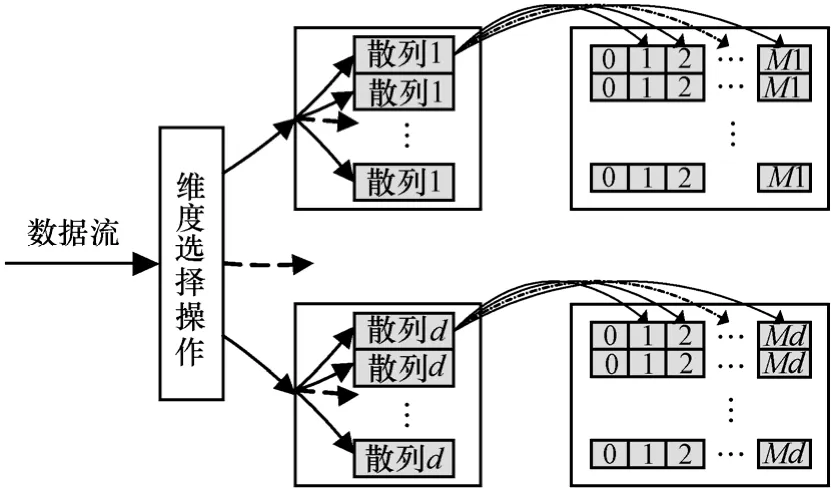
图1 Filter-ary-Sketch数据结构
在 Filter-ary-Sketch数据结构上定义了更新(update)操作、熵值计算(calculate-entropy)操作、异常点定位(detect-locate)3类操作,详细的操作流程将在第3部分详细阐述。
2.3 基于熵的异常检测算法
在每个时间周期完成数据记录后,需要在Filter-ary-Sketch数据结构上计算该时间周期内流量数据在各个维度上的熵值,然后把当前时刻的熵值和前一时刻的熵值进行对比,如果熵值的差超过一定范围则认为在该维度上出现了异常。首先给出熵异常检测算法的相关概念。
数据项出现的次数定义为mi,其中i∈[n],例如目的端口为i的IP数据分组的数目;当前时间周期内数据流中数据项的总数定义为 m,则。在每个时间周期内,并不是所有的 n个标识都有相应的数据项出现。定义 aj∈[n] 为当前时间周期内数据流上的第j个数据项,n0为当前时间周期内出现的不同数据项的数目,熵定义为。熵是对到达的数据流随机性的度量,当所有到达的数据项相同时熵取最小值0,当所有到达的数据项都不同时熵取最大值logm,为了描述地简洁,本文所有对数统一默认以2为底数,且0log0=0。为了在各个时间周期上和不同维度上对比熵值,需要对熵值进行归一化处理,定义标准熵为,熵值计算过程可描述为
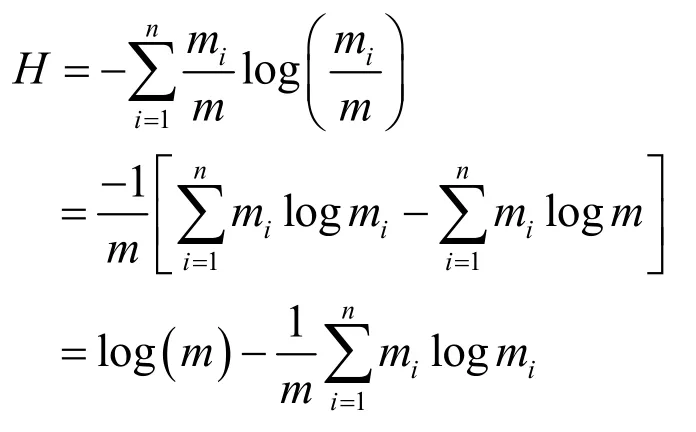
对S的准确估算并不一定能够获得一个误差足够小的熵估计值,在实际的计算过程中,如果H值很小,S值趋向于它的最大值时,计算S值时一个很小的误差可能导致H值出现无法接受的误差,定义为通过计算获得的熵估计值,即下面的定理保证通过对S的估计值来估算H值是合理的。
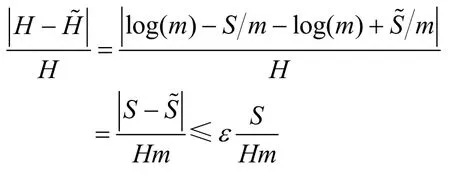
下面给出 Filter-ary-Sketch数据结构上基于熵的异常检测算法:
算法1 异常检测算法
1) for each dimensionality dk
2) for each row in Sketch ri
Detect processing
6) for each dimensionality dk
7) for each row in Sketch ri
9) A larmk←add
11) A larmk←cut
12) Type_reveal( A larm1, Alarm2, … ,A larmd)
算法复杂度分析:该算法具有很好的并行性,各个维度上没有任何数据依赖,可以直接分配到不同的处理器上执行,在此只分析每个维度的算法复杂度。熵值计算过程的时间复杂为O(ploy(M)),其中M为Filter-ary-Sketch数据结构中每个维度的散列数组长度,检测过程的时间复杂度也为O(ploy(M))。熵值计算算法在常数时间内可以完成,不随着网络流量的增加而增加,当然这样也带来了一定误差,当网络流量增大时散列函数桶内的碰撞概率增大,在某些维度上检测精度可能会降低,但在其他维度上则不会受影响,可以通过增加检测维度的方法来提高检测精度。算法中δ的选择决定了算法漏报率和误报率水平,可以通过机器学习等方法获得合适的δ值。
3 异常检测流程
异常检测的流程可分为3个部分:利用Filter-ary-Sketch数据结构进行数据记录、异常检测和恶意流量阻断。
3.1 数据记录
为了后期进行异常点定位,该系统需要2个同样的Filter-ary-Sketch数据结构,分别记录当前时刻和前一时间的流量信息,同时需要在当前时刻Filter-ary-Sketch数据结构散列桶位置存放Bloom Filter,利用它记录投影到该位置的源IP地址,Bloom Filter随着当前时刻的Filter-ary-Sketch数据结构一起更新。在异常检测阶段利用2个Filter-ary-Sketch数据结构中记录的值差异进行异常检测,在恶意流量阻断阶段根据各个散列桶当前时刻值和前一时刻值的差异来定位异常,并根据异常点位置的Bloom Filter记录的源IP地址信息进行恶意流量阻断。
初始状态时,Filter-ary-Sketch数据结构中每个散列桶初始值为0,每个散列桶对应的Bloom Filter每位都初始化为0。在每个时间周期内,用每个新到达的数据项更新Filter-ary-Sketch数据结构,具体过程如下。
1) 当一个数据项(<SIPi, Dporti, Plengthi>,ui)到达时,首先投影到各个不同维度,在各个维度上计算hd个散列函数值,得到Md个计数器中的对应项,hashk( identityi)∈{1,…,Md},k∈{1,…,hd}。
2) 对每个hashk( identityi)标识的计数器统计值进行更新,即:T[ k][ hashk( identityi)]+=ui,其中k∈{1,…,hd}。
3) 用该数据项的SIPi更新对应散列函数桶位置的Bloom Filter。
4) 当时间周期结束时,计算Filter-ary-Sketch中各个维度每行的值,并存储到T[ k][0]。
5) 把该Filter-ary-Sketch标识为当前记录Sketch,另一Filter-ary-Sketch标识为最近记录Sketch,转异常检测流程。
算法需要对采集到的每个数据项进行处理,所提方法对每个数据项的处理过程分为3个阶段,投影、更新Sketch数据结构和更新Bloom Filter。投影的计算复杂度为O(ploy(D)),其中D为需要投影的维度,更新Sketch数据结构的时间复杂度为O(c+ploy(h)),其中c为散列函数计算时间,h为Sketch数据结构的行数,而更新Bloom Filter的时间复杂度也为常数[18]。综上,对每个数据项可以在常数时间内处理完成,并不随着网络流量数据的增加而增加,当然更新过程总体的时间复杂度为O(m),其中m为到达数据分组的数目,随着流量数据的增加成线性增长,但是可以采用采样的方式降低计算复杂度,通过文献[4]的方法进行实验,当网络流量数据中每秒到达的数据项个数在106量级时,所提方法采样率为10%时依然能够获得很好的检测精度。
3.2 异常检测流程
在每个时间周期完成数据记录过程后,需要根据计算得到该时间周期内流量数据在各个维度上的值和最近一次时间周期内值的对比来进行异常检测,具体检测过程如下所述。
2) 根据各个维度上异常情况判断异常是否真的发生,如果发生判断事件类型。其中通过多个维度异常检测结果进行异常判断可采用多种方法,如基于规则的方法、投票的方法、聚类方法等,在本文实验中采用简单的投票方法,多维综合检测将在下一步工作中进行研究。
4) 取Cij对应的Bloom Filter,转恶意流量阻断流程。
3.3 恶意流量阻断
在检测到异常后,首先需要根据Filter-ary-Sketch数据结构内每个散列桶位置当前时刻值和最近时刻值的差异定位异常点,利用异常点位置对应的Bloom Filter内存储的源IP地址进行恶意流量阻断。具体的流程如下。
1) 对下一时刻到达的数据分组,取出源IP地址,分别在各个Bloom Filter上进行查询判断。
2) 如果在每个Bloom Filter上判断都成功,则该IP是恶意流量IP,即该IP属于。
3) 对恶意IP的流量进行阻断。
由于Bloom Filter本身存在假阳性问题,恶意流量阻断同样也存在误差,下面分析恶意流量阻断的精度。
恶意流量阻断误差主要来源于2个方面,Bloom Filter带来的假阳性错误和Sketch随机投影带来的误差。按照Bloom Filter理论,设集合S={x1, x2,…,xn},为了表示这样一个n个元素的集合,Bloom Filter使用k个相互独立的散列函数,它们分别将集合中的每个元素映射到{1,2,…,m}的范围中,则该Bloom Filter的误差f=(1-e-knm)k,那么一个不属于恶意IP的IP地址在所有异常点对应的Bloom Filter都出现假阳性错误概率为(1-e-kn/m)h·k,其中h是Sketch数据结构中散列函数的个数。在Filter-ary-Sketch的构建过程中知道,每个散列桶对应的元素个数Ai均值为a/Md,其中a为数据流每个时间周期内数据项个数的平均值,Md为某个维度散列桶的个数,当前维度的Sketch数据结构有hd个独立散列函数,那么一个不属于恶意IP地址的源IP同时出现在Hh个异常点的概率为(1/Md)hd。综上,只要合理地选择Sketch数据结构中散列函数的个数h、Bloom Filter中散列函数数目以及数据位数m就可以控制2个方面的误差,把恶意流量阻断系统的精度控制在可接受的范围内。
4 实验与结果分析
为了验证所提检测方法的有效性和合理性,并与文献[10]和文献[20]的方法进行对比,设计了2个实验。实验1采用的是CAIDA组织发布的2007年互联网中实际爆发的一次大规模DDoS攻击数据[21],主要从检测时间和所需存储空间2方面进行对比试验。实验2采用NLANR PMA组在Internet 2实验网上采集的一段含有异常事件的流量数据,主要从检测精度方面进行对比试验。
4.1 效率对比实验
CAIDA发布的DDoS attack 2007数据集为发生在2007年8月4日的一次大规模DDoS攻击流量数据,主要消耗被攻击主机的计算资源和网络带宽。实验1主要使用DDoS攻击开始的前10min数据进行实验,分析所提异常检测方法在时间和空间上特性。因为数据集不包含正常的网络流量,采用WIDE组织[22]在穿越太平洋的骨干链路上采集的流量数据作为正常流量,数据分组含2005年1月7日13:00到13:10分的流量。具体的流量信息如图2所示,DDoS攻击发生于第6min附近,目的IP71.126.222.64的流量由每分钟4 000个IP分组剧增到每分钟8×105个IP分组。总体流量上,数据分组峰值达到每秒2.2×104,假设每个数据分组在数据链路层大小为100byte,则该骨干网的流量达到174Mbit/s,通过实验已经证明所提方法在采样率为10%时,依然有较好的检测精度,所以该方法能够在吉比特每秒级别的网络上进行异常检测,当然,本文所有实验都通过C语言实现,下一步将通过硬件平台实现,有望进一步改善性能。
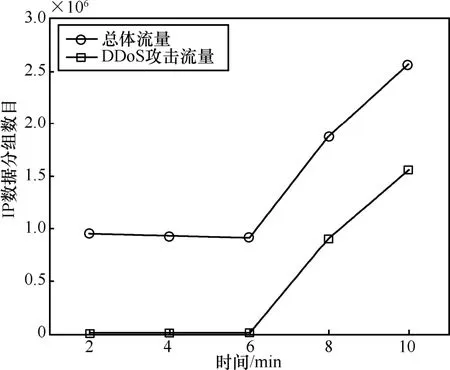
图2 网络流量
在试验中除了实现本文所提检测方法外,还实现了文献[10,20]所提方法,分别在该数据集上进行异常检测。本文所提方法具有很好的并行性,在异常检测时,以3个维度上最长的计算时间作为总的检测计算时间。Filter-ary-Sketch数据结构的参数h和M采用和文献[20]中一样的设置,每个维度h取值8,源IP维度的M值取1 024,端口维和IP数据分组长度维M取值256;检测算法的阈值取值0.1 logmm,其中0.1是对H归一化后的阈值;检测的时间周期为2min。
检测方法的计算时间对比:3个方法都是基于概要数据结构的检测方法,主要对比每个周期数据记录和检测异常2部分时间,图3是3个方法各个时间周期上计算时间的对比,IP traceability是文献[20]所提方法,Sketch是文献[10]所提方法,从图中看出所提方法比文献[10]的方法耗时多,但明显优于文献[20]的方法。比文献[10]的方法耗时多是因为文献[10]所提方法不具备IP还原或恶意流量阻断功能,而优于文献[20]主要是因为:①采用了基于熵值的异常检测,不需要计算误差Sketch结构;②采用了Bloom Filter结构记录源IP地址,更新源IP集可以在常数时间内完成。
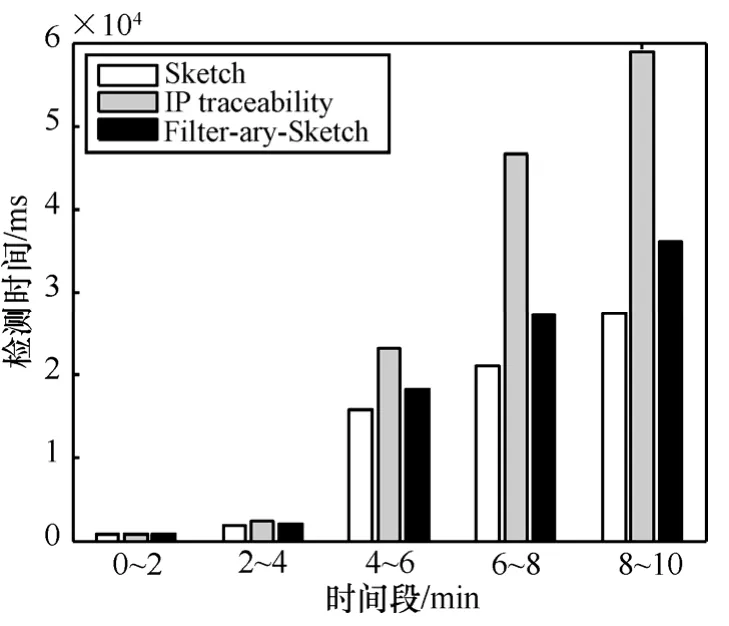
图3 计算时间对比
所需存储空间对比:因为文献[10]不具备恶意流量定位和阻断功能,所需空间仅为Sketch存储空间,在这里主要和文献[20]的方法进行对比。图4为3种方法在数据集上所需要的存储开销对比,从图中看出,本文所提方法优于文献[20]的方法,主要是因为采用Bloom Filter结构记录源IP地址,但同时也带来了一定的误差。
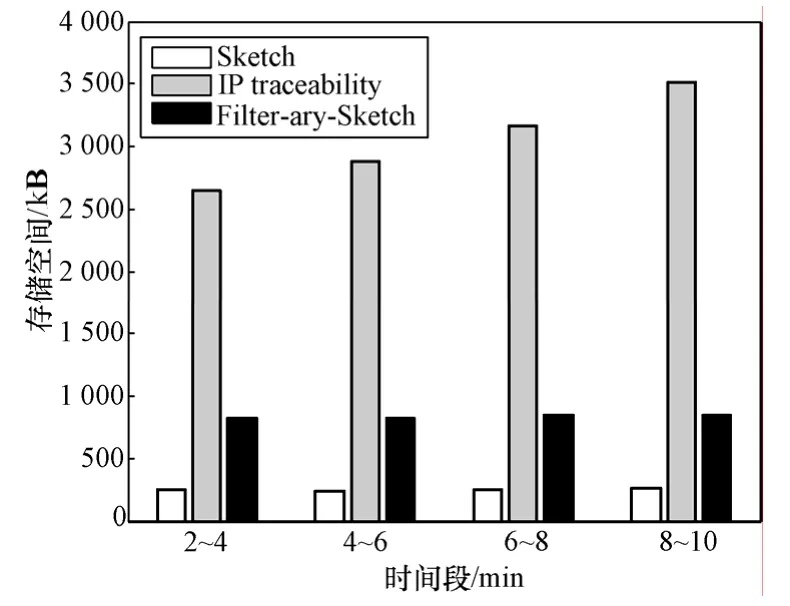
图4 存储开销对比
4.2 精度对比实验
精度对比实验(实验2)数据采用NLANR PMA组在Internet2 实验网上获取的真实网络流量trace数据。为了和文献[10,20]工作进行对比,选取IPLS-KSCY 数据,该数据为美国Indianapolis 到Kansas City 的OC192 链路数据,时间为2004年8月19日,每个数据文件持续时间长度为10min,本文选择下午2点的6个trace文件顺序连接成一个小时。6个Trace文件的主要特性见表1。
参数选择:该异常检测方法涉及到的参数主要有:检测的维度D、选择源IP、目的端口和数据分组长度3个维度;Filter-ary-Sketch数据结构参数h和M也按照文献[20]所提供的设置方式设置,每个维度h取值8,源IP维度的M值取1 024,端口维和数据分组长度维取值256;检测算法的阈值取值0.1m log(m),其中0.1是对熵值H归一化后的阈值;为了提高检测精度,检测的滑动窗口时间长度取值2min。Bloom Filter中依据c=(1-e-knm)k进行参数设置,其中c=0.05为假阳性概率,k=8为散列的数量,n是Filter里keys的数量,m是Filter的位长,从实际数据统计情况来看,n=100,所以计算得出m=688。
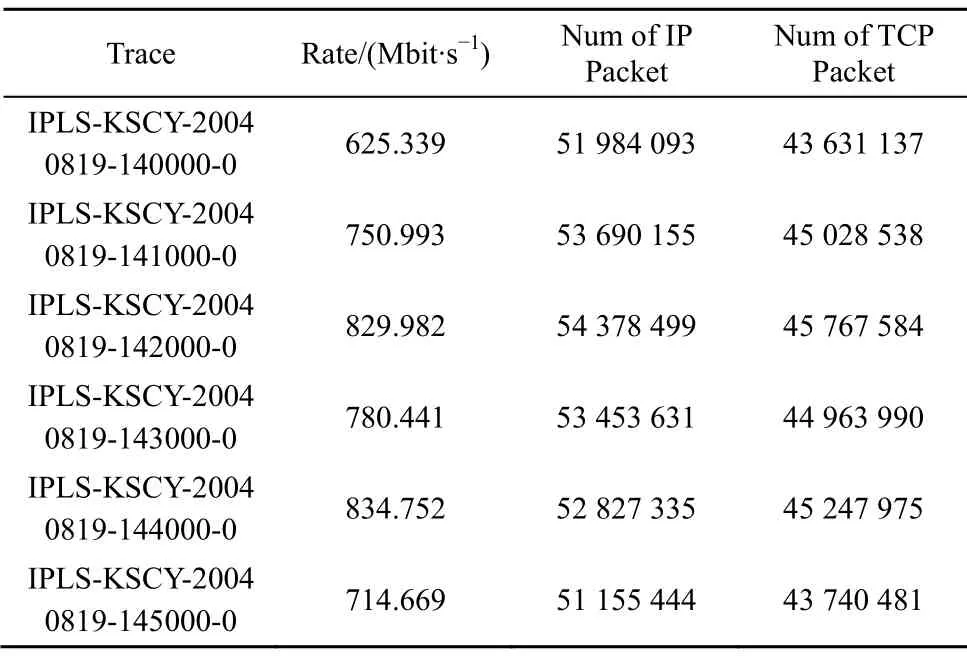
表1 Trace文件流量特征
实验结果:为了能与其他基于熵值的算法进行比较,通过计算得到值换算成熵值,图6为3个维度上熵值曲线,其中目的端口维和源IP维度的熵值曲线有较强的相关性,而包长度维的熵值对该时段内的异常并不太敏感,不过依然可以为异常检测提供有效的辅助信息。图5中出现了4个异常点,分别在14:14-14:18, 14:26-14:30, 14:42-14:44, 14:44-14:56时间段。通过对流量的详细分析,发现在这几个时间点上都出现了流量异常,如在14:42-14:44时间段,目的IP为10.1.130.153的IP数据分组从20多万突然增加到140多万个,这种流量的突然变迁代表了网络中出现了异常情况,根据3个维度上熵值的变化情况可以初步判定造成这样异常的原因可能是针对该目的IP的 DDoS攻击或者突发访问。在其他3个时间点上也同样出现了一些目的IP流量上发生较大突变的情况,图6给出了几个目的IP上流量的异常变化情况。
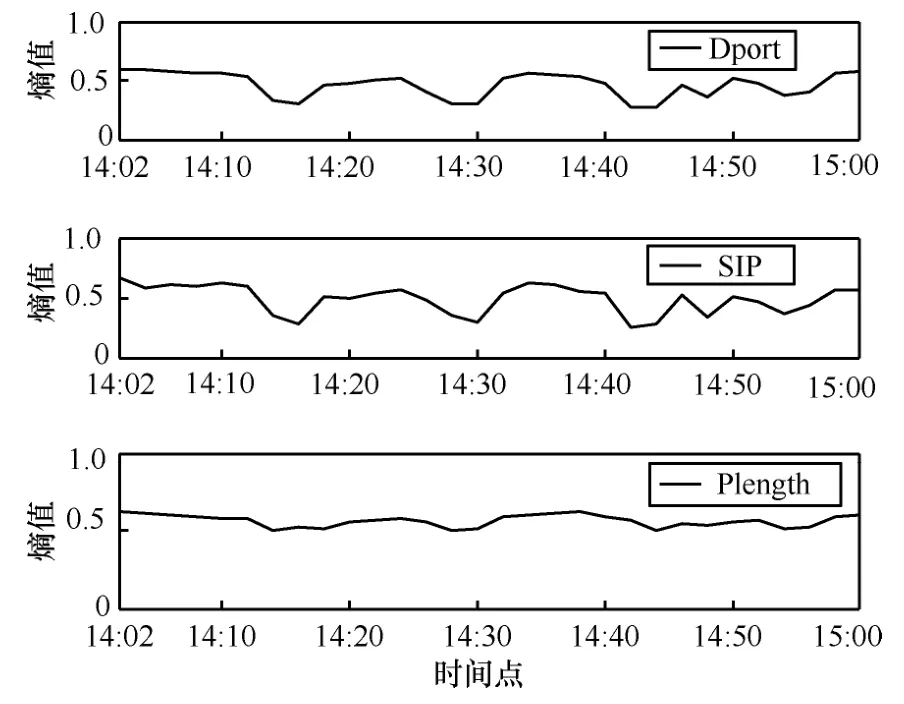
图5 熵值曲线

图6 异常IP流量
该方法能检测到文献[10]所提方法检测到的4个异常点,文献[20]所提方法还能检测到一些其他的异常点,不过会带来很高的误报率。在对文献[20]方法检测到的其他异常点进行分析的过程中发现,其他异常点发生时网络中各个主机流量并没有出现大的突变,所以本文所提方法在误报率和漏报率上是一个较好的折中。在恶意流量阻断方面,本文所提方法错误阻断率小于 3%,如在 14:42-14:44时间段,目的IP为 10.1.130.153的数据分组阻断方面,通过 Bloom Filter的记录和查询操作后,所有的源IP都能被成功过滤,只有小量的源IP被错误阻断,该部分IP只占全部阻断IP的2%,虽然文献[20]所提方法比本文方法的恶意 IP定位准确度高,但是以高的存储开销和高的计算时间为代价。
基于Filter-ary-Sketch的检测方法的优点如下:①当网络流量在整体上看不出异常时,Filter-ary-Sketch中的某个维度上的计数器可能表现异常。它在空间复杂度上和时间复杂度上都远远优于基于per flow 的检测,特别在当前高速骨干链路上基于per flow的检测方法基本上无法适应的情况下,该方法能够满足检测的要求。②基于Filter-ary-Sketch的异常检测能够检测隐藏于大量背景流量下的异常,优于基于整体流量特征的检测(把整个网络流量看成一个时间序列,采用时间序列相关方法进行异常检测)。③基于 Filter-ary-Sketch的异常检测能检测只在特定维度上呈现异常行为的异常,且能够根据各个维度熵值的不同变化提供详细异常信息。
5 结束语
为了解决高速骨干网上异常检测面临的问题,本文首先提出 Filter-ary-Sketch数据结构存储骨干网上流量信息,然后在该概要数据结构基础上采用改进的基于熵的异常检测算法,在多个维度上进行基于熵的异常检测,增加检测精度,且根据多个维度上熵值的计算结果判断大规模网络安全事件类型,最后根据Filter-ary-Sketch中Bloom Filter记录的源IP地址有效地进行恶意流量阻断。通过实验验证了该异常检测方法在一定的精度条件要求下时间复杂度和空间复杂度相对其他算法更低。
但是本文提出的在 Filter-ary-Sketch数据结构上基于熵的异常检测算法并没有理论上的精度保证,在基于熵的异常检测维度选择以及多维度整合方面也需要进一步的理论和实验证明,这些都将是下一步工作的重点。
[1] WANG H N, ZHANG D L, SHIN K G. Change-point monitoring for the detection of DoS attacks[J]. IEEE Transactions on Dependable and Secure Computing, 2004, 1(4):193-208.
[2] 严芬, 陈轶群, 黄皓. 使用补偿非参数CUSUM方法检测DDoS攻击[J]. 通信学报. 2008, 29(6):126-132.YAN F, CHEN Y Q, HUANG H. Detecting DDoS attack based on compensation non-parameter CUSUM algorithm[J]. Journal on Conmmunications, 2008,29(6): 126-132.
[3] JUNG J, PAXSON V, BERGER A W. Fast portscan detection using sequential hypothesis testing[A]. Proceedings of the IEEE Symposium on Security and Privacy[C]. 2004.
[4] MAI J N, CHUAH C N, SRIDHARAN A. Is sampled data sufficient for anomaly detection[A]. Proceedings of the 6th ACM SIGCOMM conference on Internet measurement[C]. 2006.
[5] KOMPELLA R R, SINGH S, VARGHESE G. On scalable attack detection in the network[A]. Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement[C]. 2004.
[6] LAKHINA A, CROVELLA M, DIOT C. Mining anomalies using traffic feature distributions[A]. SIGCOMM[C]. 2005.
[7] MUTHUKRISHNAN S. Data stream: algorithms and applications[A].Proceedings of the 14th annual ACM-SIAM Symposium on Discrete Algorithms[C]. 2003.
[8] CORMODE G, MUTHUKRISHNAN S. An improved data stream summary: the count-min sketch and its applications[J]. Journal of Algorithms,2005,55(1).
[9] KRISHNAMURTHY B, SEN S, ZHANG Y. Sketch-based change detection: methods, evaluation, and applications[A]. Proceedings of the 3th ACM SIGCOMM conference on Internet measurement[C]. 2003.
[10] SCHWELLER R, LI Z C, CHEN Y. Reverse hashing for high-speed network monitoring: algorithm, evaluation, and applications[A]. IEEE Infocom[C]. 2006.
[11] DEWAELE G, FUKUDA K, BORGNAT P. Extracting hidden anomalies using sketch and non gaussian multiresolution statistical detection procedures[A]. Proceedings of the 2007 workshop on Large scale attack defense[C]. 2007.
[12] XU K, ZHANG Z L, Supratik bhattacharyya. profiling internet backbone traffic: behavior models and applications[A]. ACM Sigcomm[C]. 2005.
[13] WAGNER A, PLATTNER B. Entropy based worm and anomaly detection in fast IP networks[A]. Proceedings of the 14th IEEE Internatinal Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprise[C]. 2005.
[14] GU Y, MCCALLUM A, TOWSLEY D. Detecting anomalies in network traffic using maximum entropy estimation[A]. Proceedings of the 5th ACM Sigcomm Conference on Internet Measurement[C].2005.
[15] NYCHIS G, SEKAR V, ANDERSEN D G. An empirical evaluation of entropy-based traffic anomaly detection[A]. Proceedings of the 8th ACM SIGCOMM Conference on Internet Measurement[C]. 2008.
[16] LI X, BIAN F, CROVELLA M. Detection and identification of network anomalies using sketch subspaces[A]. Proceedings of the 6th ACM Sigcomm Conference on Internet Measurement[C]. 2006.
[17] ZHAO H Q, LALL A, OGIHARA M. A data streaming algorithm for estimating entropies of OD flows[A]. Proceedings of the 7th ACM Sigcomm Conference on Internet Measurement[C]. 2007.
[18] BRODER A, MITZENMACHER M. Network applications of bloom filters: a survey[J]. Internet Mathematics, 2004, 1(4):485-509.
[19] WEGMAN M, CARTER J. New hash functions and their use in authentication and set equality[J]. Journal of Computer and System Sciences, 1981,22(3):265-279
[20] 罗娜, 李爱平, 吴泉源. 基于概要数据结构可溯源的异常检测方法[J]. 软件学报,2009,20(10):2899-2906.LUO N, LI A P, WU Q Y. Sketch-based anomalies detection with IP address traceability[J]. Journal of Software. 2009,20(10):2899-2906.
[21] The cooperative association for internet data analysis(CAIDA)[EB/OL]. http://www.caida.org/data.
[22] Measurement and analysis on the WIDE Internet (MAWI) working group traffic archive[EB/OL]. http://mawi.wide.ad.jp/mawi/.
猜你喜欢
课程教育研究(2021年23期)2021-04-13
铁道通信信号(2020年3期)2020-09-21
甘肃科技(2020年19期)2020-03-11
计算机教育(2019年1期)2019-12-20
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
电子制作(2017年14期)2017-12-18
中国市场(2016年45期)2016-05-17
中国交通信息化(2015年10期)2015-06-06
中国教育技术装备(2015年21期)2015-03-11
