
一种改进的关联规则算法在就业管理信息系统中的应用研究
2011-11-07 12:18周贤
当代教育理论与实践 2011年10期
周 贤
(湖南第一师范学院招生就业处,湖南长沙410002)
一种改进的关联规则算法在就业管理信息系统中的应用研究
周 贤
(湖南第一师范学院招生就业处,湖南长沙410002)
随着高校毕业生就业制度的改革和高等教育规模的迅速扩大,高校毕业生的数量迅速增加,高等教育的决策者很想知道高等教育学科专业结构、办学基本条件与学生就业之间的关系,以判断高等教育是否适应社会需求。以高校毕业生就业信息数据为研究对象,将一种改进的关联规则算法应用于就业信息数据分析,希望从大量积累的历史就业信息数据中挖掘出有意义的规则,以便以就业为导向,提高高等教育质量,提高学生就业率。
关联规则;就业管理;信息系统
随着计算机技术的发展,我国不少单位的管理工作都向信息化方向转变。比如就业管理方面的信息系统已经在不少高校投入运行,而且经过若干年的应用,系统积累了非常重要的就业管理方面的数据。但就目前所使用的就业管理信息系统而言,一般只是提供一些简单的功能,比如:信息录入、信息查询以及信息的统计等。随着就业信息量的增加,如何从其中挖掘出有效的规则,并进一步指导高校教学以及就业管理就成为一个值得关注的问题。也就是说,通过数据挖掘技术,从就业管理信息系统的数据中挖掘出知识,从而预测未来[1]。
尤其是最近几年,我国高校规模不断增大,毕业生就业制度也有了一定的变化,每年毕业生数量呈大幅度增长的趋势,高校教育也由原来的精英化教育逐渐转变成大众化教育。这时,一个关键问题就显现出来了。那就是这么多的大学生涌入社会,如何保证这些学生都能就业就成为亟待解决的问题。我国政府、高校以及企事业单位都在努力缓解就业压力。高校领导层也认识到了就业率与教学专业结构、办学基本条件等之间的关系,但只能借助于挖掘技术,才能实现以就业为导向,提取合理性的规则,从而提升高校教育水平,促进学生就业率的提高。作者提出了一种改进的关联规则看法:希望从就业信息数据中挖掘出有意义的规则。
一 关联规则Apriori算法的基本思想
关联规则挖掘在数据挖掘中是一个重要的课题,最近几年已被业界所广泛研究。而Apriori算法则是关联规则中的一个经典算法。该算法能够有效生成候选测试规则。其中,算法可以在K-项目集的基础上生成(K+1)-项目集。首先,算法生成频繁1-项目集所对应的集合,可以记为L1。在L1集合的基础上再生成频繁2-项目集的集合,可以记为L2,并再次在L2的基础上生成L3,不断按照这样的规则进行循环处理,直到最终生成频繁K-项目集。需要注意的是,生成一个Lk都必须经过一次数据库的扫描处理[2]。
Apriori算法属于层次化算法的范畴,实现过程也比较简单。但存在的关键问题是:Apriori算法每次生成项目候选集的时候都需要对数据库进行一次扫描操作,当数据库比较大,也就是对应的候选集比较大时,Apriori算法会花费大量时间在数据库的扫描操作上,从而直接导致Apriori算法在时间上的开销过大。另外,由于数据库中的数据并不是不变的,随着应用的深入,数据库中的数据也在不断增加中,而Apriori算法在运行时会涉及到频繁项目集以及关联规则的生成。这里为了挖掘结果的有效性,必须对这些增加的数据再次进行Apriori算法挖掘,这也表示之前挖掘出来的频繁项目集以及关联规则是无效的,这样将明显不利用于关联规则的高效挖掘[3]。同时,如果数据库的规模大于主存的时候,该Apriori算法的不足之处越明显,效率也会受到更大的影响。
二 关联规则Apriori算法的优化
从Apriori算法分析中,不难发现,Apriori算法生成一次频繁集,都会执行数据库扫描操作来判断候选频繁项目集是不是属于频繁项目集。在实际的执行过程中,有些项明显不属于频繁项目集的,但Apriori算法仍然要去扫描数据库,这显然是影响了Apriori算法的效率,为避免这些不必要的扫描操作还需要进一步进行研究。本文提出关联规则挖掘的改进模式,在Apriori改进算法中涉及到的关键术语定义如下:
(一)信息系统的定义
信息系统可以用S={U,I,F}加以表示,所有对象的非空有限集合用U={X1,X2,…,Xp}加以表示,属性的非空有限集合用I={I1,I2,…,Im}加以表示,我们也可以称之为属性集。
(二)分辨矩阵的定义
信息系统用S={U,I,F}加以表示,定义映射φi:Vi→{0,1}如下:

(三)分辨向量的定义
若Dj称为项 Ij的分辨向量[4]。
三 Apriori优化算法的伪码描述
基于分辨矩阵的关联规则Apriori算法的优化思想描述如:
Stepl:录入信息系统,同时设置最小支持度。
Step2:对数据库进行扫描操作,并产生对应的分辨矩阵D。
Step3:由分辨矩阵生成频繁1-项目集,同时将K设置成2。
Step4:根据Lk-1中的频繁k-1项目集产生频繁K-项目集,并将频繁K-项目集命名为集合R。
Step5:根据集合R,产生对应的项集下标集W。
Step6:对W中每一个下标Wi,计算下标集L'(Wi),若存在Wi∈W,使得L'(Wi)≠Φ,则将Wi从W中删去,并加入L'中。
Step7:对剪枝后的W中的每一个下标Wi,生成对应的分辨向量DWi,计算支持度计数,如下所示:

若 support-count(Rwi)< min-sup×|D|,则将Wi从W中删去,并加入到L'中。
Step8:若W≠Φ,则根据下标集W中的每一个下标,生成集合R所相应的项集,并生成K-项目集,用Lk加以表示,令K=K+1转至Step4,否则Step9。
Step9:输出分辨矩阵中符合最小支持度的频繁目集,用L=∪KLK加以表示。
四 关联规则改进算法在就业管理信息系统中的应用
Apriori优化算法的思想就是利用Lk-1中的k-1项集连接生成K-项集的集合R,最终生成分辨矩阵D。那么针对就业信息,根据Apriori优化算法的思想,首先应找出学生就业信息系统的频繁一维谓项集,然后在频繁一维谓项集的基础上,发现所有的频繁k维谓项集,从而产生学生就业信息系统分辨矩阵所对应的关联规则。由此可见关于多维频繁谓词集的生成是核心内容。因此,应用流程的核心就是如何由频繁K-谓项集求频繁K+1谓项集,我们可以借助于函数的递归调用来实现,应用的实现过程如下:
算法开始执行后,第一步先找到频繁1-项目集,也就是频繁一维谓词集;第二步在频繁1-项目集的基础上,生成频繁二维谓词集,由此循环,生成最终的频繁k维谓词集。比如:针对就业管理信息中的“专业英语”字段,算法将其定义了一维频繁谓词,则生成的二维频繁谓词就可以是“专业 -英语”、“生源地 -长沙”。当该二维频繁谓词的相关计数值满足一开始设定的最小支持度,则可以生成三维频繁谓词:“专业 - 英语”、“生源地 - 长沙”、“综合测评 -高”。
但是,如果该二维频繁谓词的相关计算值并不满足一开始设定的最小支持度,则凡是包括“专业-英语”、“生源地-长沙”的相关模式是不再被扫描的。关联规则挖掘算法就是会其他的二维频繁项集进行计数,比如:“专业 -英语”、“生源地 -湘潭”,然后重复上面的比较操作。根据上述的步骤进行不断的频繁谓词添加后缀并判断,最终生成所有的频繁k维谓项集。
Step1:与就业管理信息系统的数据进行连接操作,查询定位相关信息,涉及到关键表的一些属性维以及记录数等等信息。
Step2:K=m=n=1,求一维频繁谓词项集,N=总属性维数。
Step3:针对于就业管理信息系统中的一维频繁谓词集,可以选择其中的第m个属性作为起始属性,并根据该属性的n个成员作为频繁维谓词集,如果k的取值是1,那么当前的频繁维谓词集就是1维的。
Step4:将频繁维谓词项与数据库表第i+1个属性维中的第j个成员进行连接操作,产生对应的K+1谓词项,同时对数据库进行扫描并生成该谓词项的计数。
Step5:判断计数与一开始设定的最小支持度之间的大小关系。如果大于,则将K+1谓词项作为当前频繁维谓词项,i及k进行步长为1的递增;否则,计算j是否大于第i+1个属性维中的成员总数,如果是,将i进行步长为1的递增,j=1。
Step6:计算n是否大于第m个属性维中的成员总数。如果是,则m++,n=1;反之,转至Step3;
Step7:计算m是否大于N,如果是,则终止算法流程。反之,转至Step3。
五 关联规则改进算法在就业管理信息系统中的应用实例
某高校计算机科学与技术专业每学期都要统计学生的就业分配情况,现随机抽取400名学生的毕业分配情况,将学号、数据结构课程成绩、大学英语成绩、文化课测评成绩、综合测评成绩、行业、收入等7项数据输入数据库(如表1所示)。我们将找出数据结构课程成绩和大学英语成绩对就业行业的影响,文化测评成绩和综合测评成绩哪个对收入的影响更大。
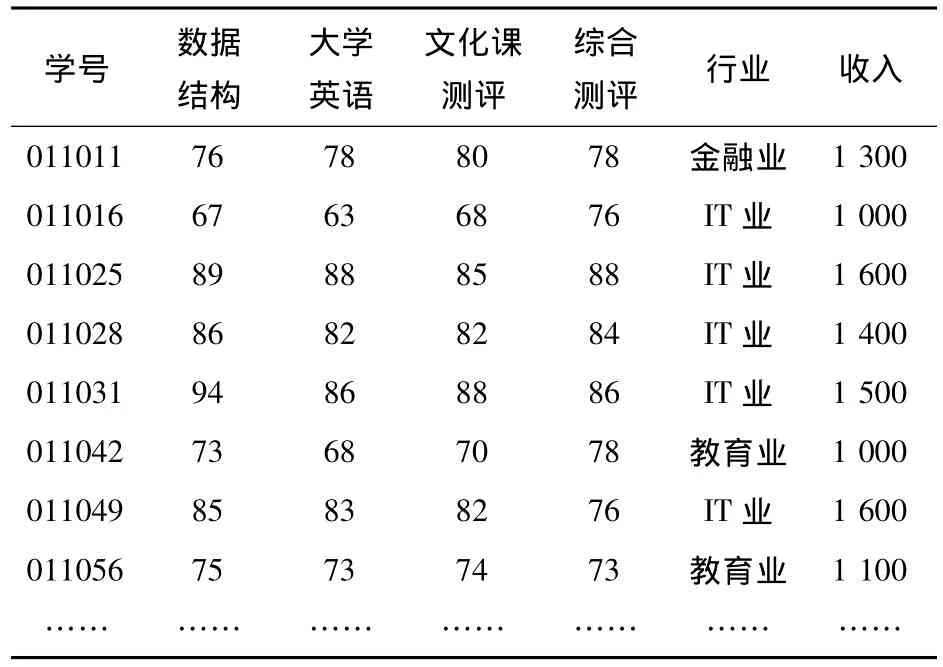
表1 就业评价信息表
在上表中,数据结构成绩、大学英语成绩、文化课测评成绩、综合测评成绩及收入都是树立属性(非离散属性),这里,我们将其离散化。首先,对数据结构成绩、大学英语成绩、文化课测评成绩、综合测评成绩采用统一的量化标准,分为两个等级,成绩高于85分的为良好,低于85分的为一般。将收入也量化为两个值,高于1 500的为高收入,低于1 500的为低收入。
将表中的相关记录进行编码,将就业评价信息表中的记录以 i1,i2,…,i8进行编码。
输入:就业评价信息表;输出:分辨矩阵表。
(1)挖掘频繁1-项集L1
输入:分辨矩阵表和最小支持度min-sup=0.25
输出:L1={i1,i2,…,i8}
(2)挖掘频繁项集L
输入:L14L
输出:L=k∪=1k,其中 L1同上
L2={i14,i16,i17,i34,i45,i46,i47,i48,i56,i67},
L3={i146,i147,i167,i456,i467},
[1]闫 禹.数据挖掘技术在高校学生就业指导决策中的运用[J].沈阳工业大学学报,2007,29(3):344-346.
[2]宋 波,李妙妍,赵 晶.利用泛型DAO模式改进轻量级J2EE架构[J].计算机工程与设计,2009,30(24):5663-5666.
[3]刘美玲,李 熹,李永胜.数据挖掘技术在高校教学与管理中的应用[J].计算机工程与设计,2010,31(5):1130-1133.
[4]李燚琳,张 璞.数据挖掘技术在教务信息挖掘系统中的应用[J].制造业自动化,2010,32(4):200-203.
L4={i1467}。
(3)挖掘关联规则集R
输入:L,最小置信度min-conf=0.75
输出:R1:i1i46(sup=0.3061,conf=0.789 5)
R1:i1i46(sup=0.2959,conf=0.878 8)
R2:i7i14(sup=0.2959,conf=0.763 2)
R3:i1i47(sup=0.2653,conf=0.787 9)
R4:i7i16(sup=0.2959,conf=0.878 8)
R5:i7i46(sup=0.2653,conf=0.896 6)
R6:i67i14(sup=0.2653,conf=0.812 5)
R7:i47i16(sup=0.2653,conf=0.896 6)
R8:i17i46(sup=0.2653,conf=0.812 5)
搜索原始数据库,得到满足最小支持度和最小置信度的关联规则:
(1)数据结构(良好)。行业(IT):数据结构成绩良好的学生从事IT行业。该规则的支持度为28%,置信度为72%。
(2)综合测评(良好)。收入(高收入):综合测评成绩良好的学生的工资收入比较高。该规则的支持度为24%,置信度为81%。
(3)文化课测评(良好)。收入(高收入):文化课测评成绩良好的学生的工资收入比较高。该规则的支持度为25%,置信度为74%。
规则(l)说明数据结构成绩好的学生的实际编程能力很强,很适合从事IT行业,大部分学生的就业行业都是IT业。规则(2)和规则(3)说明测评成绩高的学生的工资收入比较高。规则(2)的置信度高于规则(3),且规则(3)的支持度高于规则(2)的支持度,这说明综合测评高的学生获得高工资的可能性更大,也就是在找工作的过程中,用人单位更注重综合能力。因此,在培养学生的过程中,多注重综合能力的培养。
G421
A
1674-5884(2011)10-0032-03
2011-07-18
周 贤(1981-),男,湖南湘潭人,硕士生,政工师,主要从事高教管理研究。
(责任编校 杨凤娥)
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
当代陕西(2019年15期)2019-09-02
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
外语学刊(2016年4期)2016-01-23
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
