
一种自反馈式元搜索系统的设计
2011-12-27 09:19程传鹏王天志
中原工学院学报 2011年4期
程传鹏,王天志
(1.中原工学院,郑州 450007;2.云南师范大学,昆明 650092)
一种自反馈式元搜索系统的设计
程传鹏1,王天志2
(1.中原工学院,郑州 450007;2.云南师范大学,昆明 650092)
分析了常见元搜索系统中普遍存在的问题,对独立搜索引擎的选择以及搜索结果的集成提出了改进的方法,并在此基础上设计出一种自反馈式元搜索系统.实验结果表明,该元搜索系统提高了用户的搜索效率.
元搜索;自反馈;奖励系数;查询相关度
随着Internet的迅猛发展,搜索引擎已是人们获取知识最重要的来源之一.但由于信息量的庞大以及采用的技术不同,大部分的独立搜索引擎都只涉及到整个WWW资源的30%~50%[1].元搜索引擎的出现,整合了独立搜索引擎的资源,一定程度上解决了搜索引擎查全率低的问题.元搜索引擎依赖于独立搜索引擎进行查找,但由于各个独立搜索引擎的差异性,元搜索引擎在对各个独立搜索引擎返回的搜索结果的整合上还存在一定的问题.本文对元搜索引擎中的独立搜索引擎调度以及输出结果排序两项关键技术进行了研究,在此基础上提出了一种自反馈式元搜索系统.实验结果表明,该元搜索系统提高了用户的搜索效率.
1 关键技术
元搜索引擎的主要作用是对独立搜索引擎的检索结果作进一步处理.它没有自己的文档索引数据库,其信息来源于独立搜索引擎的结果输出[2].从元搜索引擎的工作过程来看,元搜索引擎的关键工作主要集中在对独立搜索引擎的选取以及独立搜索引擎返回的搜索结果的排序.下面对这两项技术进行分析.
1.1 独立搜索引擎返回结果的选择
对于每个查询字符串,元搜索引擎通过代理接口向独立搜索引擎提交查询请求,一般独立搜索引擎都将返回成千上万甚至几十万个搜索结果,这其中含有我们需要的结果,然而更多的是干扰信息[3].目前的元搜索引擎一般都事先设置好参数,从各个独立搜索引擎的搜索结果中提取同等数量的搜索结果.这种方法其实是不妥当的.对于同一个查询请求,有的独立搜索引擎查询精度高,有的独立搜索引擎查询精度低,我们应该从搜索精度高的独立搜索引擎里多取出一些搜索结果.由此本文提出一种可以根据反馈信息自动调整独立搜索引擎权重的算法.为了便于讨论,给出如下几个定义:
定义1 从独立搜索引擎的搜索结果中所取回的搜索比例,定义为独立搜索引擎的权重,用符号Wi表示.
定义2 每个独立搜索引擎的搜索结果的数量,定义为独立搜索引擎的基,用符号|Rei|表示.
定义3 元搜索引擎最终向用户提交的结果集,定义为最终结果集,用符号|R|表示.
定义4 独立搜索引擎在最终搜索结果集中所占的比例,定义为独立搜索引擎比重,用符号 Pi表示.
在以上分析的基础上,形成如下的算法:
(1)对每个独立搜索引擎 Rei赋以初始权重W0,即Wi=W0=1/n,n为所调用的独立搜索引擎个数.
(2)计算最初从 Rei中提取的结果的数量Ni:
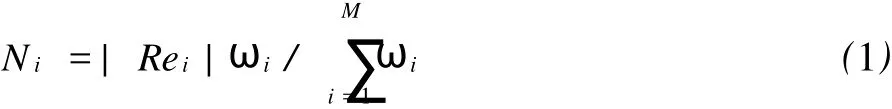
式中:Rei表示第i个独立搜索引擎;|Rei|表示集合 Rei的基.
对于一个查询请求,独立搜索引擎都会返回很多搜索结果,但用户一般只会选择前面的几页来浏览,实际浏览量很少.所以在(1)式的基础上加一个常数c1,形成公式(2):
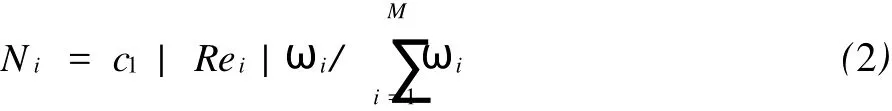
式中:c1视对返回结果数量的要求而定,可以取0.01、0.001等,目的是来缩小搜索范围.

(3)将每个 Rei中前Ni个结果取出,合并形成原始结果集,对结果集用本文所提出的位置/摘要排序法进行排序,取前 n个结果形成最终结果集.其中:

式中:M为独立搜索引擎个数;c2为常数,用来缩小搜索规模.
(4)计算每个独立搜索引擎在最终结果集中所占的比例:
pi=ni/n (5)
式中:ni表示第i个独立搜索引擎中最终入选搜索结果集的搜索结果数量.
对 pi规范化,形成如下公式:
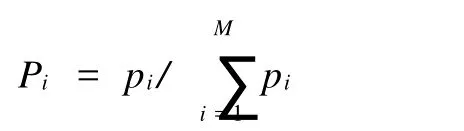
(5)根据独立搜索引擎比重重新调整每个独立搜索引擎 Rei的权重:
ωi=c3ω0+c4Pi(6)
式中:c3和 c4为常数,且c3+c4=1.c3和 c4的大小决定了 Pi对ωi的影响力.
对ωi规范化,形成如下公式:

(6)从独立搜索引擎所返回的搜索结果中提取的数量为:
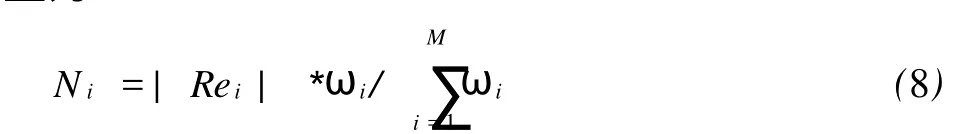
1.2 位置/摘要排序法的改进
元搜索系统中搜索结果的排序,一般采取的是位置/摘要排序法.它的主要思想是根据用户查询串与搜索结果记录中摘要信息的相关性以及查询串在摘要中的位置来对搜索结果进行排序.先计算查询串与每条搜索结果记录的相关程度,最后将这些搜索结果记录按照相关度从大到小的顺序返回给用户[4].摘要排序法的计算步骤如下:
(1)对查询串 Q进行词条切分,形成词条 l1,l2,l3,…li,…,lm,其中,m为词条个数.
(2)计算查询串Q中每个词条lj与文摘Abstracti的相关度 Rl(lj,ABstracti):

式中:Length(Abstracti)为 Abstracti的长度;Occurence(lj,Abstracti)为 lj在Abstractj中出现的次数;L ocation(lj,k,Abstracti)为词条 lj在 Abstracti中第k次出现的位置.
(3)计算 Abstracti与Q的相关度 Rq(Q,Abstracti) :

式中:m为查询串Q中的词条数.
下面我们通过一个例子,来说明此方法的不足之处.假设查询串“搜索引擎的设计与实现”,通过分词,该查询串被切分为“搜索引擎”、“设计”、“实现”3个词条.“搜索引擎”字串在 Abstract1中出现了3次,而在Abstract2中3个词条各出现了1次,如果按照式(10)来计算,那么 Rq(Q,Abstract1)=Rq(Q,Abstract2),也就是说,Q相对于Abstract1的查询相关度与 Q相对于Abstract2的查询相关度一样.但直观上来看,Abstract2更符合查询的要求,理应得到更多关注,基于此,我们考虑给词条匹配全面的文档奖励.
定义5 定义元搜索引擎最后提交给用户的搜索结果集为最终结果集.
定义6 假设查询串Q经过词条切分后,有 M个词条在文摘Abstracti中出现,则定义 Abstracti奖励系数为M T(Q,Abstracti).
定义7 定义词条 lj与文摘Abstracti的词条匹配系数为mt(lj,abstracti):
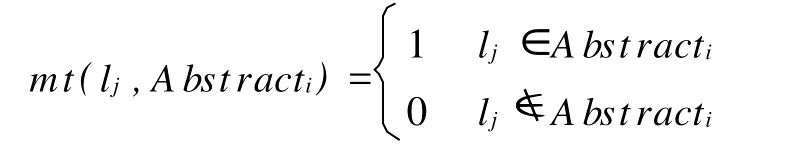
在以上分析的基础上,本文提出的搜索结果的排序算法如下:
(1)计算文摘 Abstracti的奖励系数M T(Q,Abstracti):

式中:X为查询串Q中词条的个数.
(2)计算查询串 Q与文摘Abstracti的相关度R(Q,Abstracti):
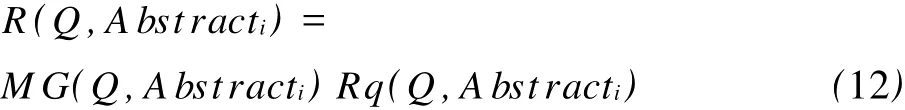
(3)计算最终结果集中第 i个搜索结果的位置信息得分Pos(ri):

(4)综合位置信息和相关度信息,得到最终排序分数Rank(ri):
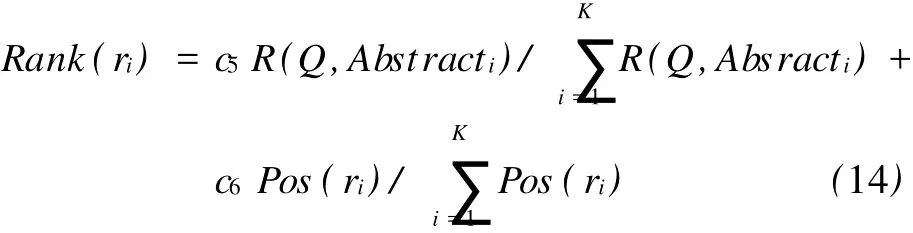
式中:c5、c6是常数,它们的大小决定了位置信息和相关度信息对最终排序的影响力;K为最终选择的搜索结果个数.
(5)将最终结果集中的 r1按照 Rank(ri)的值从大到小排列.
2 自反馈式元搜索系统的结构
元搜索引擎又称作搜索引擎之上的搜索引擎,它没有自己的网页数据库和索引库.用户通过元搜索引擎接口向独立搜索引擎提交查询请求,独立搜索引擎返回的结果再通过元搜索引擎进一步整合后,提交给用户.在以上分析的基础上,设计出一个元搜索引擎模型,其中包含有用户接口、元搜索接口、搜索结果提取和搜索结果排序4个模块.整个系统的结构如图1所示.
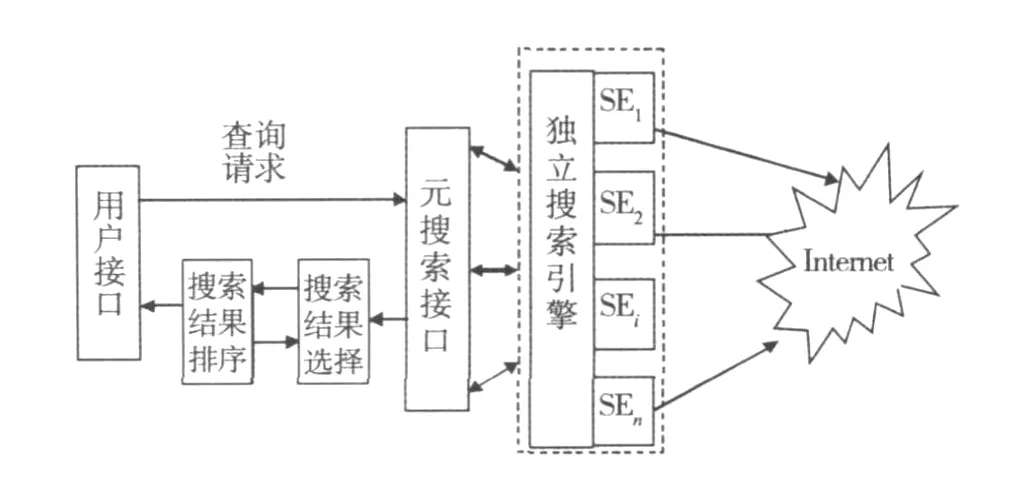
图1 自反馈式元搜索系统结构图
自反馈式元搜索系统的流程如下:
(1)用户通过元搜索接口提出搜索请求;
(2)元搜索接口将查询短语整理后,发送到独立搜索引擎,并获取搜索引擎的搜索结果,形成原始网页集;
(3)由元搜索接口返回的搜索结果集,通过本文所提出的选择方法进行二次选择;
(4)经过二次选择的搜索结果集,按照本文所提出的相关度排序方法进行排序;
(5)经过查询相关度排序后,最终提交给用户一定数量的搜索结果.
3 实验结果及分析
在搜索引擎返回的结果中,符合用户查询意图的结果数量所占的百分比,称作搜索引擎的查准率.查准率是衡量搜索引擎搜索质量的一个重要指标,但目前还没有很好的方法对这一指标作出量化.本文中查准率可通过多个人工专家分别打分,取得分的平均值来确定.这里假设人工专家的查准率为100%,以百度和搜狗2个搜索引擎作比较,以不同的关键词进行搜索,百度和搜狗的返回结果只取前面10页.经过实验,得到如表1所示的结果.
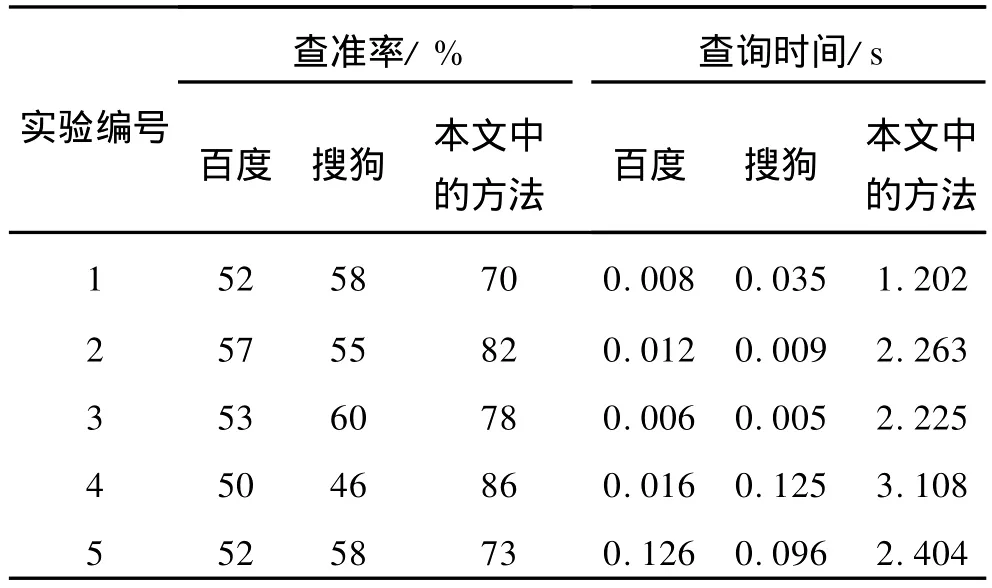
表1 实验结果
从表1中的实验数据可以看出,本文中的方法虽然在时间上劣于其他搜索引擎的搜索时间,但大大提高了查准率.
4 结 语
搜索引擎的选择和查询结果的排序是元搜索引擎需要重点解决的关键技术.本文在分析了常见元搜索系统结果集成的基础上,根据每次查询的反馈信息自动调整独立搜索引擎的权重,做到了依据查询串动态地调整从每个独立搜索引擎中返回的结果,并且对传统的位置/摘要排序方法进行了分析,指出了其不足之处,提出了相应的改进措施.
[1] 李永平,文坤梅.集成搜索引擎中结果排序的优化分析[J].华中科技大学学报(自然科学版)2001,31(11):28-30.
[2] 王敏,杨炳儒.基于主题的个性化元搜索引擎的设计与实现[J].情报检索2005,31(11):57-58.
[3] 肖建华,蒋明,何瑗,等.二次搜索系统的设计与实现[J].计算机应用研究2003,20(9):28-30.
[4] 张卫丰,徐宝文,周晓宇,等.元搜索引擎结果生成技术研究[J].小型微型计算机系统,2003,24(1):123-126.
Design of Self-response Meta Search System
CHENG Chuan-peng1,WANG Tian-zhi2
(1.Zhongyuan University of Technology,Zhengzhou 450007;2.Yunnan Normal University,Kunming 650092,China)
This paper analyzes the common question in meta-search system,and proposes improvement method for selection of independent search and integration of search result.On this basis,a response metasearch system is designed.Experiments show that the meta search system has improved efficiency of search
meta-search engines;self-response;incentive factor;query relevance
TP391
A
10.3969/j.issn.1671-6906.2011.04.015
1671-6906(2011)04-0068-04
2011-06-13
程传鹏(1977-),男,河南郑州人,讲师,硕士.
猜你喜欢
疯狂英语·新阅版(2020年11期)2020-12-21
电脑知识与技术·经验技巧(2020年3期)2020-05-07
现代电子技术(2018年16期)2018-08-21
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
知识经济·中国直销(2016年5期)2016-11-07
中国卫生(2015年12期)2015-11-10
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
