
基于分布式多步回溯Q(λ)学习的复杂电网最优潮流算法
2012-07-02 10:47胡细兵
电工技术学报 2012年4期
余 涛 刘 靖 胡细兵
(1. 华南理工大学电力学院 广州 510640 2. 安庆供电公司 安庆 246003)
1 引言
最优潮流(Optimal Power Flow, OPF)是电力系统基本优化问题,是现代电力系统经济调度和节能调度的基础,但是随着综合优化调度目标的提出,现有的传统算法[1-3]对这类复杂的 OPF多目标优化函数的适应性难以满足要求。此外,面对节点规模庞大的复杂电网,传统的最优潮流算法与常规人工智能算法[4,5]都面临大系统所带来的维数灾难问题,计算速度难以满足电网实时控制的要求。
为了探索更有效的复杂电网多目标OPF计算方法,国内外学者对此做了深入研究,除了研发更优的基本算法外,并行计算方法成为研究的主流。并行计算归纳起来分成两类方法,一类是常规并行算法[6,7],另一类是基于辅助问题原理(Auxiliary Problem Principle, APP)的分区分布式算法[8,9],前者采用服务器/客户端结构,计算成本较高,且存在数据传输的瓶颈问题;后者人为复杂化了OPF数学模型,增加了系统的运算负担,而且收敛速度很大程度上受到人为经验的限制[10]。
近年来,随着人工智能的不断发展和智能电网的提出,多代理系统(Multi-Agent System, MAS)技术日益得到重视,分布式强化学习[11]则是实现MAS技术的一个重要途径。本文结合强化学习中优异的多步回溯 Q(λ)学习算法和分布式处理技术,综合利用前者对多目标 OPF的良好适应性以及后者在解决维数灾难问题的有效性,提出分布式 Q(λ)学习算法来解决复杂电网的多目标 OPF快速求解问题。本方法对复杂电网采用分区的方法,使用分布式 Q(λ)学习算法,由多个学习单元同时使用 Q(λ)学习算法单独执行部分强化学习任务,最后达到整个系统意义上的学习目标。据查新显示,分布式Q(λ)学习算法尚未在国内外电力系统领域出现,因此该分布式强化学习算法的引入对求解复杂电力系统的其他动态寻优问题均具有较高参考价值。
2 OPF数学模型
传统的OPF模型中,一般以发电成本或网损作为目标函数,但是纯粹以发电成本或网损的高低作为发电调度的依据具有明显的不合理性[12]。因此,有必要采用一种在保证电网安全运行的前提下,同时考虑降低发电成本和能源损耗的电力系统综合节能的多目标函数,使电能生产和输送的综合效益最大化。
为了凸显电网安全稳定运行的重要性,除了常规的电压不等式约束外,结合文献[13]和文献[14]中电压无功优化控制的目标函数,定义本文OPF多目标函数中的电压稳定分量V为

式中,n为负荷节点个数;Vj表示负荷节点j的节点电压;Vjmax、Vjmin分别为负荷节点 j的最大、最小电压限制。
目前,学术界对多目标问题的精确处理还没有突破性的进展,本文不失一般性仍然以权值的形式反映多目标。综上,以发电成本,有功网损和电压稳定分量为目标函数,考虑多种运行约束的多目标最优潮流模型表示如下:

式中,F(x)为目标函数,g(x)为发电成本,ƒ(x)为有功网损;V(x)为电压稳定分量;ω1[0∈,1],ω2[0∈,1],ω3[0∈,1]为权重系数,ω1+ω2+ω3=1;x={PG,QG, V, θ, k, Qc}分别指发电机的有功出力,无功出力,电压幅值、相角,有载调压变压器电压比和无功补偿容量等控制变量或状态变量。
OPF中的电力系统潮流约束的等式和不等式条件不再赘述(可参见文献[3])。
3 分布式Q(λ)学习算法
随着计算机网络技术和分布式处理技术的飞速发展,以及对高速高性能计算和智能处理的迫切需求,学术界对 MAS中的分布式强化学习方法的研究不断深入,取得了大量的研究成果[15]。所谓的分布式强化学习是指该强化学习系统由多个学习单元构成,每个单元独立地执行部分或者全部的强化学习任务,最后达到整个系统意义上的学习目标,这个系统就可以称为分布式强化学习系统。
基于分布式强化学习的 MAS系统仅仅需要很少的通信量来获得相邻Agent的奖惩函数值,而且在学习过程中通过迭代来影响不相邻的 Agent,从而优化整个系统的性能。根据分布式强化学习中各Agent的学习机制将分布式强化学习分成:中央强化学习(RLC)、独立强化学习(RLI)、群体强化学习(RLG)和社会强化学习(RLS)这四类[15]。
所谓的分布式 Q(λ)算法是指在分布式强化学习中各Agent采用多步Q(λ)算法。多步Q(λ)学习(Multi-step Q(λ)learning)[16]是基于离散马尔可夫决策过程的经典 Q学习[17]结合了 TD(λ)算法[18]多步回报思想的一类强化学习算法。多步 Q(λ)学习算法不依赖于对象模型,通过不断的试错来动态寻找最优的动作,其值函数的回溯更新规则利用资格迹来获取算法行为的频度和渐新度两种启发信息,从而考虑了未来控制决策的影响。资格迹[19]更新公式定义如下

式中,Ixy是迹特征函数;γ 为折扣因子,0<γ <1,取0.000 01;λ 为迹衰退系数,取0.999 99。
资格迹λ -回报算法的“后向估计”机理提供了一个逼近最优值函数Q*的渐近机制,而这类对所有状态-动作对Q值的高效持续更新是以提高算法复杂度和增加计算量为代价的。设 Qk代表 Q*估计值的第k次迭代值,Q(λ)学习迭代更新公式如下

式中,0<α <1,称为学习因子,取 0.999 99;R(sk,sk+1,ak)是第k步迭代时刻环境由状态sk经动作ak转移到 sk+1后的奖励函数值;Q(s,a)代表 s状态下执行动作a的Q值函数,其实现方式采用lookup查表法。
迄今为止,所有的分布式强化学习算法都是基于标准单步 Q学习算法的[20],但是由于多步 Q(λ)算法所具有的在线学习能力强、收敛速度快的优点,因而本文中首次采用分布式 Q(λ)算法,并在多个标准算例中与分布式Q学习算法进行对比分析。
4 基于复杂电网分区的分布式Q(λ)学习
4.1 复杂电网分区以及学习方法选取
在研究OPF问题的标准强化学习算法中,对应的动作空间是发电机出力,变压器电压比,无功补偿设备等可控变量的组合。一旦电网规模扩大,动作空间也随之成倍增加,这使得常规强化学习算法陷入动作的维数灾难中,不能满足电网实时性的要求。
对于动作的维数灾难问题,最有效的做法即分解该电网,通常使用分解协调法[21]实现网络分离,如图1在联络线上“复制”节点,每一个边界节点看作一个虚拟的发电机节点(或者负荷节点),分解后系统与原系统等值,分解处的两边界节点需具有相同的电气量。

图1 互联电力系统的分离Fig.1 Decomposition of interconnected systems
当电网分成n个区后,目标函数分成n个部分,因为边界节点上所增加的虚拟节点仅仅是为了保证分区的有效性,不影响整个电网的目标函数值。因此,将原目标改为

式中,Fi(xi)表示分区后各子系统的目标函数,xi表示各子系统的相关动作变量或状态变量。
由于分布式 Q(λ)算法中的 RLC和 RLG并不能减少动作组合。因而,本文的复杂电网OPF研究中,更适合使用 RLI,其 Agent的独立性较强,容易动态增减Agent的个数,而且Agent个数对学习收敛性的影响较小,适合处理大系统的强化学习问题,特别是协作型 RLI,其中各 Agent是并发执行的,任意时刻有多个Agent处于工作状态,共同影响环境的变化,只要设置合理的信度分配机制(强化信号分配),就能在大大简化运算的同时克服局部最优的缺点。
4.2 协作型RLI中对边界节点的处理
复杂电网分解处的边界节点的电气量对于复杂电网的分解至关重要,是协作型RLI实现的基础,决定了所有分解后的各子系统计算结果的有效性,是本文分布式Q(λ)学习算法的核心部分。
为了保证分解处的两边界节点具有相同的电气量,本文所阐述的分布式 Q(λ)学习中,不对目标函数进行辅助处理,而是利用分布式强化学习算法中的协作机制,设置合理的信度分配,实行统一的奖惩约束。本文中,对分解处的边界节点从两个方面进行同步约束:首先,在不等式约束中,增加关于边界节点约束条件,两者之差的绝对值以 3%为限,并通过状态来反映;其次,将边界节点的约束信息附加在各Agent在并行运算时对环境所产生的综合响应中。该“响应”关系到整个算法的收敛性,它包括两个要素:各种约束信息的奖惩值和目标函数值;它对每个Agent的反馈作用也包含两个方面,一是对立即奖励的调整分配,二是对状态的确定。
分解后各子系统中有自己的参考节点,这就涉及多平衡节点问题。参考文献[10]中,对不含全局平衡节点的子系统,将某一边界节点设置成参考节点,采用传递“Δ-变量”的模式。但是此模式不利于并行运算,因而本文将该等效的边界节点在两个子系统中设置成不同类型,一个是 PV节点,另一个为平衡节点,以该平衡节点的θ 角作为其所属子系统动作空间的组成部分,进行并行运算,比较P、Q、V、θ 这 4个量。
本文的分布式 Q(λ)学习中,边界节点的有关电气量将作为各子系统动作空间的组成部分。如果分解后的各子系统内动作过少(主要指边界节点)则很难满足收敛精度要求,动作过多,又有悖于复杂电网分解的初衷。为了克服这一矛盾,利用电力系统中有功-无功这种弱耦合的特性,可以适当运用解耦所得到的先验知识。
4.3 应用流程
基于分布式 Q(λ)算法的复杂电网最优潮流计算中,通过分解复杂电网成几个子区域(子系统),每一个子系统内(含虚拟的边界节点)使用标准多步 Q(λ)算法,通过电力系统的运行特征,判断状态(s)、动作(a)、奖励(r)来在线寻找最优策略(具体s、a、r的设置见第5节中算例),学习流程如下:
(1)通过有功-无功的解耦,得到相关先验知识。
(2)复杂电网分解。分解复杂电网,确定分解处节点及该节点类型,构成多Agent的分布式强化学习。
(3)分布式Q(λ)算法。
初始化s,a, Q(s,a),令e(s,a)=0
Repeat (对每一Agent)
①根据当前的状态s,执行动作a,得到相关奖励要素和状态信息。
②依次执行所有 Agent,根据边界节点的电气信息量修正r和s′。
③从s′中利用Q派生出来的策略选择a′。
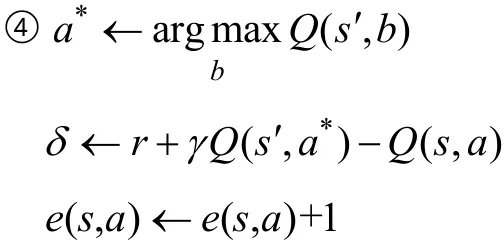
对于所有的s, a来说

5 算例分析
为了证明分布式 Q(λ)算法的可行性,本文在Matlab 6.5仿真平台上通过建立S函数的方法实现所提出的OPF算法,并在2.0GHz、1GRAM的计算机上对IEEE标准算例进行了仿真。
对于现代电力系统这种复杂的高低压电磁环网模式,电压等级高的网内发电机的容量裕度大,相应的发电成本调节空间较大;而低电压等级的电网,其网损率较高,节能降耗的空间较大。为了使复杂电网OPF问题更具针对性,更符合电网实际的运行特点,本文采用实用化OPF模型:高电压等级电网中以发电成本为主要目标,低电压等级电网中以网损为目标函数,两者在统一的复杂电网中通过边界节点的无功功率进行协调。
本文以 IEEE118节点为例,其包含 345kV和138kV两个电压等级。在对IEEE118节点分区时,提出了以下几点标准:①不同电压等级进行分离;②动作变量尽可能均匀地分散在不同的子区域内;③考虑实际地理位置或电网工程实际;④不同子区域之间联络线尽可能少。最终确定将其划分为7个子区域(子系统)。在分区标准的基础上,主要得到以下三种不同的分区方案。其中分区方案 3如图2所示,各个子区域内的数据统计见表1。

表1 IEEE118节点不同分区方案Tab.1 Different distribution cases of IEEE118 system

式中,i为高压子系统;j为低压子系统;ω1、ω2、为权值,其中ω1=0.01、ω2=0.1、ω3=0.89,0.2,=0.8;Cgeni为高压发电成本;Plossi、Plossj为有功损耗;Vi、Vj为电压稳定分量。

图2 IEEE118电网分区方案三示意图Fig.2 Distribution case 3 of IEEE 118-bus system
参照 4.2节,在分解的联络线的两边添加虚拟发电机(负荷),针对实用化的OPF模型,在IEEE118系统中,对边界节点处理遵循以下原则:
(1)高电压等级内部的边界节点一般设置为PV节点,P为动作变量。
(2)低电压等级内部的边界节点一般设置为PQ节点,Q为动作变量。
(3)高低压之间的边界节点设置为PQ节点,Q为动作变量。
(4)对于各子系统内的平衡节点,高电压等级中确保有且仅有一个区域内有确定的平衡节点(此时的θ已知),对于其余的高压区域,设置其某一边界节点为平衡节点,其中的θ为动作变量,低电压等级各子系统的平衡节点都是确定的(由于这仅是无功优化过程)。
为了使各子区域的动作空间设置更为统一,本文中对动作变量做如下的离散化处理:
(1)实际发电机的出力以其最大出力为限均分成4等分,共5档;无功补偿容量以常规潮流中的数据为界,上下各增两组,每组容量为原容量的20%,共5档;有载调压变压器的分接头分成:0.98,1.00和1.02这3档。
将乡村旅游纳入各级乡村振兴干部培训计划,加强对县、乡镇党政领导发展乡村旅游的专题培训。通过专题培训、送教上门、结对帮扶等方式,开展多层次、多渠道的乡村旅游培训。各级人社、农业农村、文化和旅游、扶贫等部门要将乡村旅游人才培育纳入培训计划,加大对乡村旅游的管理人员、服务人员的技能培训,培养结构合理、素质较高的乡村旅游从业人员队伍。开展乡村旅游创客行动,组织引导大学生、文化艺术人才、专业技术人员、青年创业团队等各类“创客”投身乡村旅游发展,促进人才向乡村流动,改善乡村旅游人才结构。
(2)边界节点中虚拟PV节点中的P,虚拟PQ节点中的Q,虚拟平衡节点中的θ 均以常规潮流中的数据为界,其中P上下各增两档,每档步长为原大小的20%,共5档;Q上下各增一档,每档步长为原大小的20%,共3档;θ 上下各增4档,每档步长为原大小的10%,共9档。
以分区方案 3为例,其子区域 1中,节点 10作为平衡节点,在常规潮流经验中可得出其相对于全局平衡节点的电压角度,以节点8和节点26的有功出力,边界 PV节点的有功出力以及三台虚拟发电机 PQ节点上的无功出力作为控制变量,总的动作个数为 5×5×5×3× 3×3=3 375。同理可知,其他区域中动作个数,见表2。分区方案1各个区域内的动作数与方案3相同。分区方案2由于新增了一条断开联络线,区域5动作个数为19 683,区域6动作个数为9 375,其他区域动作数不变。

表2 分区方案3数据统计Tab.2 Data of distribution Case 3

(续)
状态变量的确定与约束条件相关,具体包括各子系统内实际发电机无功出力,平衡节点的有功出力和 PQ节点的电压是否满足约束条件,以及分解处两相邻节点的电气量(有功功率、无功功率和电压角度)是否吻合。分区方案3中区域1中的状态变量个数为3+1+5+9=18,其余各子系统状态变量个数依次分别是:29,49,27,42,53,20。分区方案一状态变量总数为 238,分区方案 2状态变量总数为240。
立即奖励值与潮流计算结果中是否满足不等式约束条件的个数有关,为了保证各子系统计算结果的有效性,对不同类型的不等式约束条件必须有不同的奖惩,其中以区域间的边界平衡节点的电压角度最重要,其次是边界节点的其他电气量,再次是各子区内的电气约束。由于在强化学习中,奖励函数的值越大越好,因而各子系统立即奖励函数r如下式:

式中,ri(i=1,2)为高电压等级的子区域系统的奖励函数,rj(j=3~7)为低电压等级的;ω1、ω2、ω3、取值与目标函数中相同;n1为不满足边界平衡节点的电压角度约束个数,只取 0或 1;n2为不满足边界所有节点其他的约束不等式的个数,n3为不满足子系统内部约束不等式的个数。k1、k2、k3分别为系数,比较多个取值,本文仿真中取 k1=100.4,k2=48.8,k3=19.7。不同分区方案下分布式Q(λ)学习算法学习结果对比见表3。
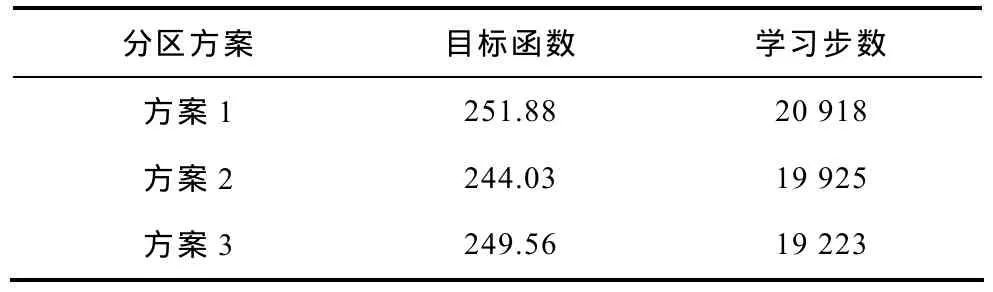
表3 不同分区方案OPF结果对照表Tab.3 OPF results comparison of three distribution cases
从表3多次仿真统计的计算结果可知,不同的分区方案下目标函数值基本相同,从而验证了分布式 Q(λ)学习算法的可行性和准确性,而误差主要来源于在分区优化过程中对不同电压等级之间和相同电压等级之间边界节点的假设处理。综合学习结果和学习步数可知,方案3是最好的分区方案。
分区方案3下分布式Q学习算法和分布式Q(λ)学习算法学习结果如图3所示。

图3 基于分布式Q-学习算法和分布式Q(λ)算法的多目标最优潮流计算收敛示意图Fig.3 OPF convergence results based on distributed Q-learning and multi-step Q(λ)learning
本文中对这两种算法在IEEE 118节点的详细计算结果进行统计,与优化前的结果进行比较,见表4。

表4 IEEE 118节点OPF结果对照表Tab.4 OPF results comparison of IEEE 118
从表4中的统计结果可知,两种算法的结果基本一致,目标函数值相差3.0%,相比优化前的常规潮流计算结果,各个指标都有很大幅度的提高,且两类算法的计算结果均基本满足电网实际运行条件,边界节点电气量之差最大为3.7%(由于动作的离散化步长较大)。分布式 Q(λ)算法学习 19 223步,耗时约96s就能达到收敛,而分布式Q学习需23 176步收敛,耗时约 116s,可知分布式 Q(λ)算法在收敛速度方面优势较为明显,且达到了工程上潮流优化的要求。
为了进一步与当前最优潮流算法在主流算法——内点法进行比较,很明显对于本文这一类复杂目标函数,内点法难以处理,而针对单目标的网损,通过计算、统计结果见表5。
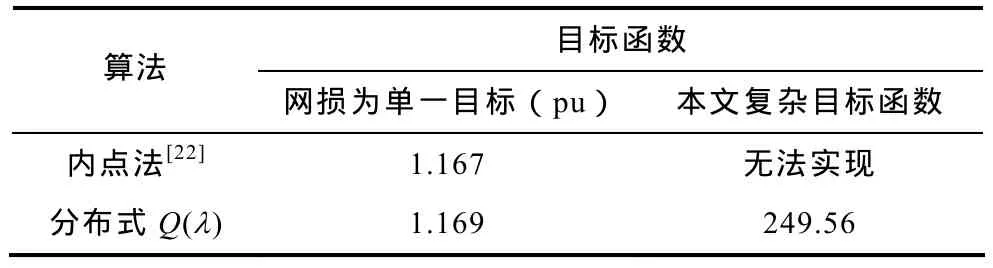
表5 不同目标函数下结果对照表Tab.5 Results comparison with different objective functions
本文中对 OPF问题的处理是以离散化为基础的,对简单的单目标函数(如网损),分布式Q(λ)学习算法,相比内点法一类的算法,结果可靠,只是时间略长。然而分布式 Q(λ)学习算法不依赖数学模型,在处理复杂多目标方面显示了很强的优越性。相比同样以离散化为基础的其他现代智能算法,在处理IEEE 118这类高维大系统时,在收敛时间上达到了很好的要求。
6 结论
本文所提出的分布式 Q(λ)算法在求解复杂电网OPF问题,具有以下特点:
(1)基于分布式强化学习中的 RLI原理,各Agent独立承担各子系统的学习任务,经过多Agent统一协作处理后,更适合现代大区电网中各省网/地区电网分区调度和分层控制模式,工程上具有更高的实际应用价值。
(2)分布式强化学习算法不依赖于 OPF目标函数的一阶或二阶梯度进行寻优,是解决更符合电网实际运行特点的多目标OPF计算问题的有效算法。
(3)各 Agent中包含了一个独立的多步回溯Q(λ)算法,该算法是一种具有快速动态优化和自学习能力的强化学习算法,对电网的变化具有较高的自适应能力。
(4)该算法继承了电网分区的思想,通过在奖励函数中附加对边界节点电气信息的奖惩,约束边界节点的电气信息量满足电网实际的运行条件,从而避免了对OPF模型的人为复杂化。
(5)将所提出算法在多个 IEEE标准算例的计算结果表明,分布式 Q(λ)算法在处理该类复杂电网OPF问题时,其收敛速度快,收敛精度较高,为解决复杂电网多目标函数的 OPF问题提供了一种全新可行的方法。
(6)针对多目标优化问题,目前国际上的趋势是求取帕累托解集。目前公认求解帕累托解集的方法是进化算法[23]和强化学习[24]算法,内点法等经典算法则无法直接求取帕累托解集。因此,本文所提出分布式强化学习方法较易于进一步推广到 OPF帕累托解集。考虑使用帕累托来解决多目标问题,这就避免了灵敏度带来的多量纲复杂处理模式,克服加权多目标不能精确解决目标函数的缺点。
[1]David I Sun, Bruce Ashley, Brian Brewer , et al.Optimal power flow by newton approach[J]. IEEE Transactions on Power Apparatus and Systems, 1984,103(10): 2864-2880.
[2]韦化, 李滨, 杭乃善, 等. 大规模水-火电力系统最优潮流的现代内点算法实现[J]. 中国电机工程学报,2003, 23(6): 13-18.Wei Hua, Li Bin, Hang Naishan, et al. An implementation of interior point algorithm for large-scale hydro-thermal optimal power flow problems[J]. Proceedings of the CSEE, 2003, 23(6):13-18.
[3]赵晋泉, 侯志俭, 吴际舜. 改进最优潮流牛顿算法有效性的对策研究[J]. 中国电机工程学报, 1999,19(12): 70-75.Zhao Jinquan, Hou Zhijian, Wu Jishun. Some new strategies for improving the effectiveness of newton optimal power flow algorithm[J]. Proceedings of the CSEE, 1999, 19(12): 70-75.
[4]周明, 孙树栋. 遗传算法原理及应用[M]. 北京: 国防工业出版社, 1999.
[5]Luonan Chen, Hideki Suzuki, Kazuo Katou. Mean field theory for optimal power flow[J]. IEEE Transactions on Power Systems, 1997, 12(4): 1481-1486.
[6]李晓梅, 莫则尧. 可扩展并行算法的设计与分析[M].北京: 国防工业出版社, 2000.
[7]潘哲龙, 张伯明, 孙宏斌, 等. 分布计算的遗传算法中无功优化中的应用[J]. 电力系统自动化, 2001,6(13): 37-41.Pan Zhelong, Zhang Boming, Sun Hongbin et al. A distributid genetic algorithm for reactive power optimization[J]. Automaticon of Electric Power Systems, 2001, 6(13): 37-41.
[8]Batut J, Renaud A. Daily generation scheduling optimization with transmission constraints[J]. IEEE Transactions on Power Systems, 2000, 7(3): 982-989.
[9]程新功, 厉吉文, 曹立霞, 等. 电力系统最优潮流的分布式并行算法[J]. 电力系统自动化, 2003,27(24): 23-27.Cheng Xingong, Li Jiwen, Cao Lixia, et al.Distribution and parallel optimal power flow solution of electric power systems[J]. Automation of Electric Power Systems, 2003, 27(24): 23-27.
[10]李强. 分布式优化算法的算法研究[D]. 北京: 华北电力大学, 2006.
[11]仲宇, 顾国昌, 张汝波. 多智能体系统中的分布式强化学习研究现状[J]. 控制理论与应用, 2003,20(3): 317-322.Zhong Yu, Gu Guochang, Zhang Rubo. Survey of distributed reinforcement learning algorithms in multi-agent systems[J]. Control Theory &Applications, 2003, 20(3): 317-322.
[12]胥传普, 杨立兵, 刘福斌. 关于节能降耗与电力市场联合实施方案的探讨[J]. 电力系统自动化, 2007,31(23): 99-103.Xu Chuanpu, Yang Libing, Liu Fubin. Discuss on the Union implementation scheme of energy conservation measures and electricity marketability methods[J].Automatic of Electric Power Systems, 2007, 31(23):99-103.
[13]Vlachogiannis J G, Hatziagyriou N D. Reinforcement learning for reactive power control[J]. IEEE Transactions on Power Systems, 2004, 19(3): 1317-1325.
[14]邱晓燕, 张子健, 李兴源. 基于改进遗传内点法的电网多目标无功优化[J]. 电网技术, 2009, 33(13): 27-31.Qiu Xiaoyan, Zhang Zijian, Li Xinyuan. Multiobjective reactive power optimization based on improved genetic-interior point algorithm[J]. Power System Technology, 2009, 33(13): 27-31.
[15]仲宇, 顾国昌, 张汝波. 分布式强化学习的体系结构研究[J]. 计算机工程与应用, 2003, 39(11): 111-113.Zhong Yu, Gu Guochang, Zhang Rubo. Research on the architectures of distributed reinforcement learning systems[J]. Computer Engineering and Applications,2003, 39(11): 111-113.
[16]Jing Peng, Williams R J. Incremental multi-step Q-learning[J]. Machine Leaning, 1996(22): 283-290.
[17]Watkins J C H, Dayan Peter. Q-learning[J]. Machine Leaning, 1992(8): 279-292.
[18]张汝波. 强化学习理论及应用[M]. 哈尔滨: 哈尔滨工程大学出版社, 2001.
[19]Richard S Sutton, Andrew G Barto. Reinforcement learning: an introduction[M]. Cambridge: MIT Press,1998.
[20]余涛, 周斌, 甄卫国. 强化学习理论在电力系统中的应用及展望[J]. 电力系统保护与控制, 2009,37(14): 122-128.Yu Tao, Zhou Bin, Zhen Weiguo. Application and development of reinforcement learning theory in power systems[J]. Power System Protection and Control, 2009, 37(14): 122-128.
[21]Kim B H, Baldick R. Coarse-grained distributed optimal power flow[J]. IEEE Transactions on Power Systems, 1997, 12(2): 932-939.
[22]刘明波, 谢敏, 赵维兴. 大电网最优潮流计算[M].北京: 科学出版社. 2010.
[23]Deb K, Pratap A, Agarwal S. A fast and elitist multi-objective genetic algorithm: NSGA-II[J]. IEEE Transactions on Evolutionary Computation, 2002,6(2): 182-197.
[24]H L Liao, Q H Wu, L Jiang. Multi-objective optimization by reinforcement learning for power system dispatch and voltage stability[C]. Proceedings of IEEE PES Conference on Innovative Smart Grid Technologies Europe, Gothenburg, Sweden, 2010:1-8.
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
环球时报(2022-03-29)2022-03-29
儿童时代·幸福宝宝(2021年11期)2021-12-21
铁道通信信号(2020年3期)2020-09-21
现代装饰(2020年4期)2020-05-20
铁道通信信号(2018年8期)2018-11-10
证券法律评论(2018年0期)2018-08-31
知识经济·中国直销(2018年7期)2018-07-27
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
