
基于视觉注意力的视频水印算法
2012-08-08 09:51陈梦泽
长春师范大学学报 2012年12期
陈梦泽
(长春师范学院数学学院,吉林长春 130032)
随着多媒体技术的快速发展,数字媒体呈现爆炸式增长趋势,产生了大量的视频数据[2]。如何有效实施数字多媒体版权保护和确保信息安全成为一项重要紧迫的研究课题。视频水印是一个很好的方法。传统的大多数视频方法是将图像水印方法直接移植过来,但是由于视频独有的特性,加入时间轴,没有达到很好的效果,而在视频中如何找到嵌入水印的位置是我们现在的一个研究重点。
人类视觉注意力对信息有很强的筛选能力,会自动地对感兴趣区域进行处理,提取出有用的信息,这种机制就是使人们能够在复杂的视觉环境中快速定位感兴趣的目标或者区域。我们将此机制引入到视频水印中,通过视觉注意力找出视频中的感兴趣区域作为水印的嵌入位置,从而达到不可见的目的。
1 视觉注意力机制
视觉注意是人类视觉信息处理过程中一项重要的心理调节机制,面对大量的视频信息,为了信息处理的效率,视觉注意力扮演一个信息筛选的功能。人类的感知可以让我们减弱对不相关信息的处理,专注感兴趣的事物,帮助我们快速地对视频中主要的信息(颜色、亮度、运动等)进行分析,从而提取目标对象。这种自主的选择性和主动的心理活动被称为视觉注意机制。注意机制模型分为两种:一种是基于初级视觉,由数据驱动的自底向上的注意;一种是基于高层视觉与任务、知识等相关的自顶向下的注意。
Itti模型属于自底向上的模型,主要用于显著区域快速搜索,它构建了第一个神经框架来模拟人类视觉注意力机制,由外界信号的特性而决定注意的导向,属于比较经典的模型之一[4]。它包含两个部分,即早期特征选择和显著度图融合。其基本思想是在早期特征选择阶段对输入的图像提取多方面的特征,如颜色、朝向、亮度、运动等,形成各个特征维上的显著图;然后对这些显著图进行分析,通过Center-surround算子将图像、视频中的显著区域提取出来形成一个融合成的显著图(Saliency map),显著图中由亮度值表示显著度,由强到弱依次表示显著性的强弱,越亮表明该像素点的显著度越大。图1为Itti模型图。

图1 Itti模型图

图2 水印算法流程图
该方法不需要先验知识,也不需要根据视频调整模型,因此受到很多关注。但是该方法主要用于静态的图像,没有用到视频特有的运动特征,所以直接应用到视频中没有很好的效果。目前视频序列下的显著性区域检测方法主要是在静态图像的视觉注意计算模型中增加运动特征,如光流特征。因此本文在此模型的基础上考虑将静态视觉注意区域和基于运动的动态视觉注意区域融合的方法。
2 视频水印的嵌入和提取算法
基于视觉注意力理论,本文提取了一种基于视觉注意力的视频水印。图2为水印算法的整体流程。
2.1 静态显著区域的提取
静态显著性的研究已经比较成熟,如典型的Itti模型,Le Meur’s model[5]。用Itti模型来进行视频中静态显著区域的提取。视频可以看作是一组连续的图像集,它的每一帧都有不同的亮度信息和颜色特征,通过Itti模型对进行原始载体视频中的静态显著区域提取,操作步骤如下:(1)将视频帧分为一系列的图片集,一组图片集在相同的场景下;(2)并行地对每帧图像的RGB三个通道提取图像的亮度特征,用(R+B+G)/3来表示图像的灰度图,然后将灰度图送入高斯金字塔,可得到亮度特征I;(3)建立4个颜色通道r、g、b、y作为颜色特征,对其不同尺度的特征图进行“中央-周边差”计算,得到每帧图像的颜色特征C;(4)利用Gaber小波对亮度通道进行θ方向的滤波操作,得到方向特征O;(5)对颜色、亮度、方向每个特征通道的各个特征图进行跨尺度融合,并进行归一化,得到三个特征的关注图,最后将三个特征的关注图合并为一幅综合的视觉显著图T。
显著图中由亮度值表示显著度,对输入图像中的每个像素,显著图用一个标量来衡量注意度。由经验可知一副图像中的感兴趣区域通常不大于三个,因为太多的感兴趣区域会使注意力分散,无法集中地注意某个物体。图3(a)为通过Itti模型对图4提出的静态显著图。
2.2 运动显著区域的提取
下面主要介绍一下视频中运动显著区域的提取。视频不同于图像的关键在于它包含运动信息,人眼在观看时相对于初级的视觉特征(颜色、亮度、方向等),会给运动信息更多的注意。帧与帧之间的物体运动情况能很好的说明视频的动态显著性。我们用运动概率矩阵来描述帧与帧之间的运动情况,用基于帧间差分的方法来建立运动概率矩阵。如图3(c)为图4的动态显著区域。(1)将视频分为一系列的连续的图片集,以每一组图片的第一帧为参考帧,连续的两帧图像相减得到差图像,如图3(b);(2)把差图像分为大小为8*8的无重叠的块,求每块像素的和;(3)用每块像素的和除以当前帧像素的总和,得到每块图像的运动概率;(4)对每块图像的运动概率进行排序,由此得到运动概率矩阵,矩阵中的每个值代表了该像素的运动情况,值越大说明运动得越快,显著性就越高,越能引起人眼的注意;(5)将矩阵中值小于矩阵平均值的像素置为零,得到运动的显著图S。
2.3 整体显著区域的合成
通过平均融合的方法:Z=(T+S)/2,将静态显著图和动态显著图合成一个整体的显著图,如图3(d)所示,其为图4(a)的整体显著图。
2.4 秘密信息的嵌入和提取
2.4.1 水印嵌入过程
通过以上步骤,我们得到帧图像的感兴趣区域,也就是水印的嵌入位置,那么水印的嵌入过程如下:
(1)将视频分为一系列的帧图像,提出每帧图像的蓝色通道;
(3)得到水印的嵌入位置后,修改帧图像蓝色通道中M所对应的像素值,实现水印的嵌入,公式为:

其中α是嵌入强度。然后重组含密的帧图像,最后得到含密视频。
2.4.2 秘密信息的提取
水印的提取算法为水印嵌入的逆过程,水印的提取需要原始视频的参与,具体提取过程为:(1)将原始视频和含秘视频分为一系列帧图像,提取帧图像的蓝色通道;(2)通过水印提取中的显著区域提取方法,找到原视频中的显著区域M,在显著区域中我们抽取出n*n个最大显著度值,大小为水印的像素个数,构成显著区域子图M,得到水印的嵌入位置,提取水印公式如下:

(3)重组二进制流,得到二值水印图像W′。
3 实验结果与分析
为了验证这里给的基于视觉注意力的视频水印的性能,下面给出实验结果。实验中视频序列是AVI格式的灰度视频流,共200帧,时长大约6秒,帧图像大小为352×288,水印图像为64×64二值图像。原始视频的样本帧图像和二值水印图像分别如图4和图5所示。在实验中水印的嵌入强度为α=4。

图4 原始视频样本帧图像

图5 水印图像
为了验证算法的鲁棒性,对含水印的视频采取高斯噪声、椒盐噪声、掉帧以及帧平均等攻击。我们在所有的帧图像中都嵌入相同的水印信号。因此,在下面实验中,以视频序列中的一帧(10帧)作为样本帧来描述实验。
3.1 高斯噪声攻击
向含水印的帧图像中分别加入高斯噪声,均值为零,方差分别为0.00001、0.00002、0.00003。表1显示了添加噪声后的NC值和提出的水印。实验结果表明,高斯噪声的添加并没有导致图像质量的下降,提取出的水印图像清晰。
3.2 椒盐噪声
取椒盐噪声的强度分别为0.01、0.02、0.03,表2为添加椒盐噪声后恢复出的水印图像和NC值,实验表明噪声的污染使视频质量有所下降,但并不影响水印的提取,水印图像仍然能够提取和识别。
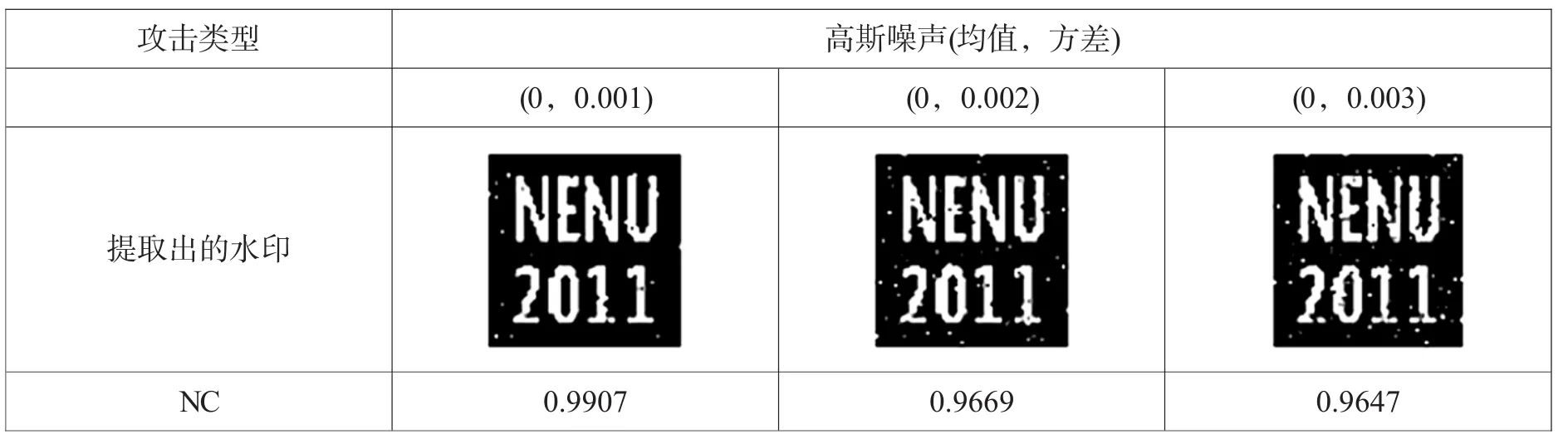
表1 高斯噪声攻击

表2 椒盐噪声攻击
3.3 掉帧攻击
掉帧攻击是指从含密的视频序列中任意的除去一帧或几帧。如果在攻击实验中去掉太多的帧,会大大降低视频的质量,被人眼所察觉。在实验中,我们在含密视频序列中随机地去掉一帧。由于该算法是将同一个水印分别嵌入到所有的视频帧中,所以掉帧不会对水印图像的完全提取造成影响,NC值为1
3.4 帧平均
帧平均是一种简单的联合攻击。对一帧进行平均攻击的步骤如下:首先,从视频中随机的选择一帧fn;然后,利用帧fn-1,fn和fn+1计算得到平均帧fn;最后,用平均帧fn替换帧fn。图5(a)为平均5帧后提取的水印。由于将同一水印嵌入到视频中,帧平均造成第五帧中水印信息的丢失,我们还可以从其他帧中完整地提取出水印信息。
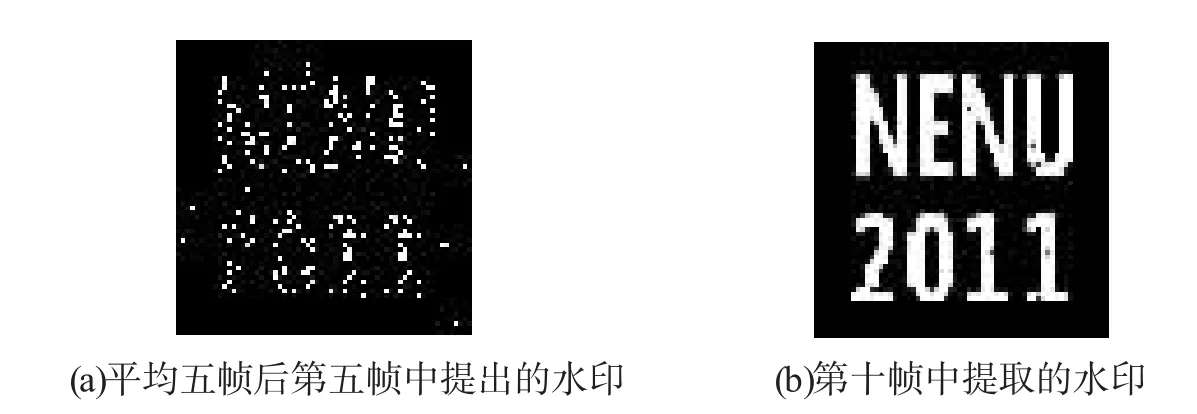
图5 提取的水印图像
由以上实验结果可以看出,该视频水印方法对高斯噪声、椒盐噪声、掉帧以及帧交换的攻击都具有较好好的鲁棒性,但对Jpeg压缩的鲁棒性不是很好。
4 结论
本文提出了一种基于视觉注意力的视频水印算法。在基于视觉注意力的视频水印中,通过Itti模型的生成静态显著图,利用帧间差分的方法构造运动概率矩阵,以此得到动态显著图,最后用平均值融合法生成整体显著图的方法得到视频中每一帧的感兴趣区域(ROI),将秘密信息或者水印信号隐藏在感兴趣区域内。由于对于每一帧图像都有不同的嵌入位置,因此本算法有较高的安全性。实验结果表明,该算法对于高斯滤波、高斯噪声、椒盐噪声、掉帧以及帧交换等攻击都具有很好的鲁棒性。
[1]L.Itti,C.Koch.Computational modelingofvisual attention[J].Nature Reviews Neuroscience,2001,2(3):194-203.
[2]梁华庆,王磊,双凯,等.一种在原始视频帧中嵌入的鲁棒的数字水印[J].电子与信息学报,2003,25(9):1281-1284.
[3]L.Itti,C.Koch and E.Niebur.AModel ofSaliency-Based Visual Attention for Rapid Scene Analysis[J].IEEE Trans.on Pattern Analysis and MachineIntelligence,1998,20(11):1254-1259.
[4]L.Itti,Koch C.Feature combination strategies for saliencybased visual attention systems[J].Journal ofElectronic Imaging,2001(10):161-169.
[5]O.Le Meur,P.Le Callet,D.Barba and D.Thoreau.Acoherent computational approach tomodel the bottom-up visual attention[J].IEEE Trans.On Pattern Analysis and Machine Intelligence,2006,28(5):802-817.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年3期)2020-10-27
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
