
Spatially localized and joint access point selection for Wi-Fi indoor positioning
2012-08-13 09:16DENGZhianMALinXUYubin邓志安徐玉滨
DENG Zhi-an,MA Lin,XU Yu-bin邓志安, 马 琳, 徐玉滨
(Communication Research Center,Harbin Institute of Technology,Harbin 150080,China)
Indoor positioning systems are becoming more and more important in pervasive computing applications.Such systems are the key elements in many locationbased services(LBS),such as content awareness,people navigation and healthcare[1-2].For indoor positioning applications,a challenging task is how to save power usage on a client device while ensuring high-level positioning accuracy,since the client device is power limited.
The received signal strength(RSS)based on Wi-Fi positioning method[3-4]has been paid more and more attentions for its low cost and high-level positioning accuracy.RSS based on positioning is achieved by the existing Wi-Fi infrastructures and pervasively available mobile devices without any additional hardware required.The most popular method for RSS based positioning is the fingerprinting based technique[5-6].During offline phase,RSS signals from multiple access points(APs)are collected at target environment and pre-stored as fingerprinting database called radiomap.During online phase,the location is estimated by matching the real RSS signals with the pre-stored radiomap.
In realistic Wi-Fi indoor environment,the RSS value varies a lot even at the same location[7].The main reason is due to the interference,reflection,refraction and multi-path effects in radio propagation channel.One accepted practice to handle uncertainty of RSS is to use as many APs as possible since each AP is a useful location information source.There are always a large number of available APs detected in the target positioning environment with the rapid development of Wi-Fi.However,too many APs used may add the consumption of energy significantly on client device due to the increased computation cost.Furthermore,most RSS based on positioning systems are client-based architecture,because such architecture preserves the client’s privacy more efficiently.All sensing and computing tasks during positioning are taken in client device and thus requiring more power consumption in applications.
To keep balance between energy consumption on client devices and positioning accuracy,APs with the maximum mean RSS are selected in the system developed by Youssef[8].Chen et al.[9]selected the most discriminative APs measured individually by location information gain.The discriminant ability o f each AP is measured independently.However,the discriminant ability of APs is always correlated and needs to be measured jointly.A new localized and joint AP selection method is proposed by considering the AP location information gain jointly in this paper.The proposed joint AP selection method measures the discriminant ability of APs more accurately since the correlation between APs is considered.Furthermore,to avoid the suboptimality of AP selection caused by variance of RSS over different regions,we incorporate a location clustering analysis step to localize AP selection.After AP selection,the support vector regression(SVR)learning algorithm[10]is combined to estimate the client’s location for its excellent generalization capability.
Experiments in a realistic Wi-Fi indoor environment show that the proposed AP selection strategy enables a better positioning performance than previous AP selection strategies.A better balance between energy consumption and positioning accuracy is achieved by jointly selecting the optimal AP subset used.We also compare and show that SVR based on positioning algorithm outperforms the other well known algorithms including artificial neural network(ANN)[11],maximum likelihood(ML)[12]and weighted k-nearest neighbor(WKNN)[13].
1 Proposed Positioning Algorithm
Firstly,the proposed positioning algorithm is briefly introduced as shown in Fig.1.The positioning algorithm includes two phases:offline phase and online phase.During offline phase,the radiomap is created by collecting RSS samples from available APs at different reference points.Then,the whole radiomap is divided into several sub-radiomaps by clustering analysis.And then,for each sub-radiomap,a subset of all APs with the best discriminant ability is obtained by the proposed joint AP selection method.Finally,the SVR function is trained corresponding to the APs subset and related RSS fingerprints.During online phase,the user is firstly classified into the related sub-radiomap and RSS values of the selected APs are combined.Then,real-time RSS vector is taken as input to the constructed SVR function.Ultimately,the user’s location is estimated by pre-stored SVR function.
1.1 Joint AP Selection Method
Generally,there are many APs detectable in target Wi-Fi environment.Each AP provides a different location information source and it is a natural way to deploy as many APs as possible to improve the positioning accuracy.However,more APs used increase the computation cost greatly and then add the energy consumption burden to the client devices.To reduce the energy consumption on client devices,it is necessary to select a subset of available APs while maintaining as high level positioning accuracy as possible.
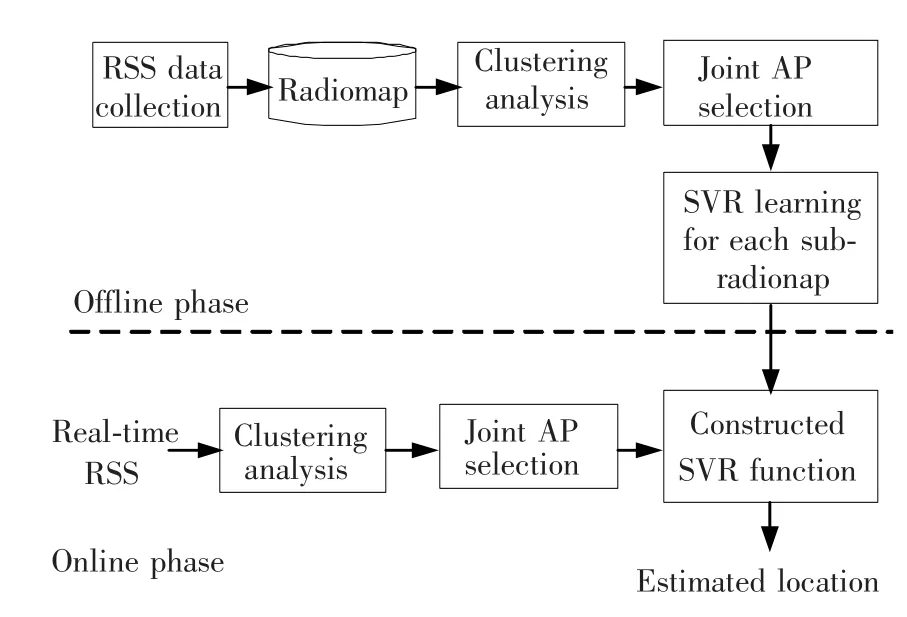
Fig.1 Proposed positioning algorithm
A joint AP selection method based on the location information gain is proposed in this section.Define the client’s location in target positioning environment as a random variable l.Let H(l)stand the entropy of the client’s location without any information from APs and H(l|APi)be the conditional entropy of the client’s location with information from APiknown.The location information gained from APican be computed by the difference between the two entropy values:

Therefore,the discriminant ability of each AP is measured by the location information gain obtained.The AP with the strongest discriminant ability is used during positioning to achieve as high positioning accuracy as possible while the number of APs is constrained to reduce the computation cost.
The basic idea of joint AP selection based on joint InfoGain is as follows:Supposing RSS positioning is a fingerprinting based architecture,and let n be the number of reference points in the target environment and m be the total number of available APs.Each AP is regarded as a location information source,and the RSS sample received from the AP at reference points can provide some location information.For a particular reference point,it is possible that some APs may be undetectable because of too large distance to the AP or the other signal propagation factors.In this case,the corresponding missing RSS value is set to-100 dBm,the minimum value of the signal received in the Wi-Fi environment.Since we can not measure the information gain obtained over all the continuous location,the information gain at the reference points are computed to approximate the information gain:whereljstands the j th reference point,and v stands all possible RSS values received from APi.Here,Pr(lj)is the prior probability of client devices at the reference point lj,which is assumed uniformly distributed if the users are assumed to be equally at any reference point.Pr(lj|APi=v)is the conditional probability computed as follows:
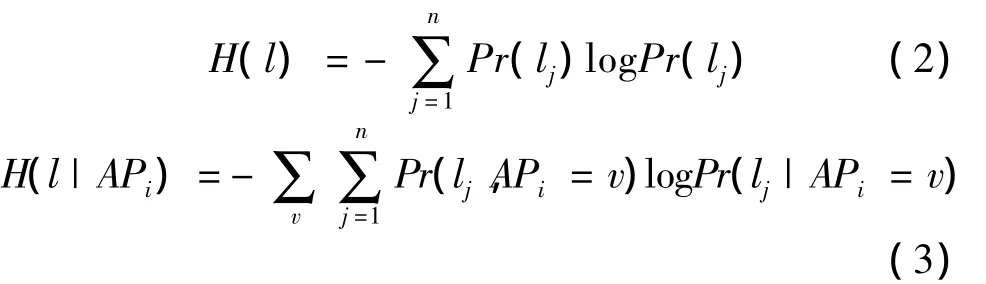
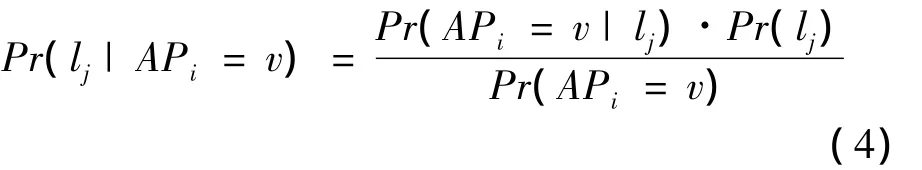
where Pr(APi=v|lj)is obtained by the offline RSS data collection and numerical statistical result at the reference point ljin the radiomap.
In contrast to traditional AP selection methods,we measure the discriminant ability of all APs jointly rather than measure them independently.Taking into account of the correlation of the discriminant ability of APs during positioning,we compute the joint location information gain of an AP subset.In practice,the positioning result is also affected by RSS from multiple APs together.Assuming k APs(AP1,AP2,…,APk)are used for positioning,there are Ckmkinds of combination for AP subset.Joint information gain of each kind of combination is computed as follows:

where Pc=log Pr(Gj|AP1=v1,…,APk=vk)is obtained by computing joint conditional probability during offline phase as in Eq.(4),Pb=Pr(Gj,AP1=v1,…,APk=vk).It can be seen that the computation cost of the proposed joint InfoGain AP selection strategy increases with the size of positioning environment.However,it is computed during offline phase and does not increase the energy consumption of the client devices during online phase.
1.2 Clustering Analysis for Localizing AP Selection
AP selection performed on the whole radiomap is suboptimal due to the variability of RSS over physical locations.Variability of RSS over physical locations is caused by the attenuations of RSS due to various propagation factors.Several statistical RSS parameters also vary with physical locations.For example,the variance of RSS from an AP is always larger in the nearer location to the AP than that in the father location.Thus,we can conclude that variability of RSS renders that the information gain of an AP over different regions is different.An extreme case demonstrates the above conclusion is that,the information gain in a region with strong RSS from one AP is lager than that from a region which cannot detect that AP.Thus,it is necessary to develop a location clustering method to localize the AP selection.
The widely used clustering analysis algorithm called k means clustering[14]is adopted in Wi-Fi positioning.The k means clustering algorithm iteratively generates clustering as shown in Fig.2.We consider each reference point as a data point represented by associated mean RSS vector.The mean RSS vector at each reference point is computed by averaging the RSS vector samples collected at each reference point during offline phase.Then,according to the size of positioning environment,the input clustering number is set and subsequently k clustering centers are initialized by selecting k reference points uniformly distributed in the whole radiomap.During each iteration,each reference point is grouped into the nearest clustering by measuring the Euclidean distance between clustering centers and the mean RSS vector of each reference point.And then,the clustering centers are recomputed for these new points in the same group and thus new clusterings are generated.The iteration continues until the stopping condition is satisfied.The stop condition of the iteration is that k clustering centers no longer change.

Fig.2 Folw chart of k means clustering method in Wi-Fi positioning
As will be seen in the realistic experiments,physical adjacent reference points are all grouped into the same clustering.The k means clustering method is an efficient clustering method that automatically divides the whole positioning environment into several sub-radiomaps.RSS patterns among the same sub-radiomap are more similar than that and are not the same.It is not only useful for subsequent AP selection,but also is beneficial for SVR learning machine of each sub-radiomap,since the overfitting problem may be avoided effectively due to the more compact RSS patterns at each sub-radiomap.
1.3 Support Vector Regression Positioning Model
After joint AP selection,the APs with the strongest discriminant ability are selected for positioning.RSS values from the selected APs are combined as input features,and their corresponding coordinates prestored in the radiomap are the outputs.The clustering analysis divides the whole radiomap into several sub-radiomaps.Thus,we develop the positioning algorithm at each sub-radiomap.In this paper,the ε loss insensitive SVR[15]algorithm is proposed to construct the nonlinear relationship between input features and physical locations.SVR algorithm is found on the VC-dimension theory and structural risk minimization(SRM)[14].Thus,the generalization ability of SVR is always better than the traditional learning machines,such as ANN,which only minimize the training errors.The nonlinear relationship between RSS features and physical locations is well constructed for its good generalization ability.
Given the training pairs(ri,zi),i=1,2,…,M,where ziis the coordinate output corresponding to the RSS vectors rifor SVR,and M is the total number of RSS samples.SVR algorithm maps the input feature space into a high dimensional feature space by a nonlinear transformation φ(·),where the linear regression function is constructed as follows:
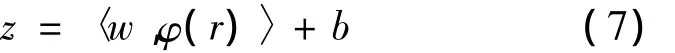
where:w is the weighting vector;z is one coordinate output of the SVR function,and b is the constant variable.According to the SRM principle,the regression can be solved by the following optimization problem:

where ξiandare the corresponding slack variables;ε is the loss intensive parameter of the approximation pairs;C determines the trade-off between the flatness of the constructed function and the tolerance for deviations larger than parameter ε.Using kernel techniques,the nonlinear transformation φ(·)may not be computed explicitly.After addressing the optimization problem in Eq.(8),the ultimate nonlinear regression function can be obtained:

where k(·,·)is the kernel function;SV is the support vector set.The widely used Gaussian kernel[16]is chosen as the kernel function for its good smoothing ability:

where γ is the parameter for Gaussian kernel.The main parameters for SVR algorithm are the kernel parameter γ and C.They can be trained by the widely used tool libsvm[17]during offline phase.
2 Experimental Setup
RSS data were collected in a realistic and typical Wi-Fi indoor environment,part of the floor 12,building 2A,Communication Research Center of Harbin Institute of Technology,as shown in Fig.3.The target positioning area included the corridors and one room whose size were 17×15 m2and 8×9 m2,respectively.There were total 16 IEEE 802.11b/g APs detectable in the target positioning area.The 5 APs seen within the area were fixed at the height with 2 m while the other 11 APs were in the other part of the same floor or in the other floors.An ASUS laptop with Intel PRO/3945ABG IEEE Wireless Card installed was used to collect and store RSS values from 16 APs.RSS measurements were taken by our developed network sniffing software.
100 RSS samples at each reference point were collected and stored to create the radiomap,2 per second.70 reference points separated by 1m were chosen for training and the other 70 points lied on or off training points for testing.The testing RSS samples were never presented and used in the training process.Three AP selection methods including proposed joint intelligent method,information gain based method and maximum mean RSS method were carried and compared in the test environment.The whole positioning area was clustered into 4 clusters as shown in Fig.3.

Fig.3 Layout of the experimental environment
3 Analysis of the Experimental Results
3.1 Accuracy Comparison of AP Selection Methods without Clustering Analysis
In this section,we firstly study the effect of different AP selection methods on positioning accuracy without clustering analysis.The Euclidean distance between the true coordinate and the estimated one is called error distance and deployed as performance metric.The proposed positioning algorithm combines the joint AP selection method with SVR algorithm.As shown in Fig.4,the positioning accuracy within 3 m distance error is compared with respect to 3 AP selection methods:proposed joint AP selection method(Joint),information gain method(InfoGain)and maximum mean RSS method(MaxMean).The proposed joint method ranks APs in order of their strongest discriminant ability combination as described in Section II-A.The information gain method ranks APs in descending order of their information gain value computed independently.The maximum mean RSS method ranks APs in descending order of their mean RSS values.

Fig.4 Comparison of the positioning accuracy within 3 m between different AP selection methods versus AP number
As shown in Fig.4,the positioning accuracy of using proposed joint method increases faster than the traditional AP selection methods.The proposed joint method uses only 10 APs to reach the accuracy of 82.0%within 3 m while the other AP selection methods need to use almost all APs.In other words,when using 10 APs by all the AP selection methods,the proposed joint AP selection method achieves the highest accuracy of 82.0%,while the information gain and maximum mean RSS based on AP selection methods obtain the accuracy of 70.9%and 67.0%,respectively.This can be contributed that the subset of APs selected by the joint method does have the best discriminant ability.Therefore,the proposed joint AP selection method obtains the same required positioning accuracy with the smallest number of APs and keeps the best balance between computation cost on client devices and the positioning accuracy.
Let us further compare the performance of the proposed AP selection methods with another two methods.The first 5 APs selected by the proposed method and information gain method are the same including AP1to AP5,as shown in Fig.5.However,their relative orders are different.As shown in Fig.5,the individual information gain of the AP4is bigger than that of the AP1,whereas joint information gain of the APs subset(AP4,AP2,AP3,AP5)is less than that of the APs subset(AP1,AP2,AP3,AP5).The reason may be contributed that there are a lot of redundant information gain between AP3and AP4whose physical locations are adjacent.The main difference between the three AP selection methods is the relative order of the other 11 APs.The proposed joint AP selection method selects the APs in descending order of the joint discriminant ability,while the information gain based on method considers their discriminant ability independently.The worst AP selection method is the maximum mean RSS method,which just considers exploring the mean RSS values of APs received from different reference points,instead of their joint discriminant ability.In addition,we can also see from Fig.4,not all the APs are useful for positioning.There are some APs with little discriminant ability and can not improve the positioning accuracy.

Fig.5 Discriminant ability measure comparison between proposed intelligent AP selection method and information gain based method
3.2 Effect of Clustering Analysis on Positioning Performance of AP Selection Methods
This section discusses the effect of clustering analysis on positioning accuracy in Wi-Fi positioning.Fig.6 shows the accuracy comparison of the different AP selection methods with and without clustering analysis.Fig.7 shows the average optimal number of APs for different AP selection methods with and without clustering analysis.Three conclusions are drawn as follows:
1)Clustering analysis improves the accuracy of all AP selection methods,because RSS patterns at each sub-radiomap are more compact and renders more accurate measurement about the discriminant ability of APs.

Fig.6 Comparison of the positioning accuracy within 3 m between different AP selection methods with and without clustering analysis

Fig.7 Comparison of the average optimal number of APs between different AP selection methods with and without clustering analysis
2)After clustering analysis,the optimal number of APs for AP selection method becomes smaller.An average number of 7.3 APs are needed for the proposed joint AP selection method,while that of the method without clustering analysis is 10.
3)The proposed joint AP selection method achieves the best positioning accuracy with the smallest number of APs used.Thus,the proposed method keeps the best balance between accuracy and power consumption on mobile devices.
3.3 Accuracy Compared to the other Positioning Methods
After choosing the optimal AP subset by the proposed joint AP selection method at each sub-radiomap,we compare the performance of SVR algorithm with ML,ANN and WKNN positioning algorithm.As shown in Tab.1,SVR algorithm performs better than the other algorithms in terms of accuracy and positioning error.Particularly, accuracy within 1 m of SVR is 43.3% while those of ML,ANN and WKNN are 41.1%,35.4%and 33.7%,respectively.Accuracy within 2 m of SVR is 68.3%while those of ML,ANN and WKNN are 66.3%,61.8%and 56.6%,respectively.The mean positioning error for SVR,ML,ANN and WKNN is 1.64 m,1.73 m,1.86 m and 2.01 m,respectively.ML performs better than WKNN since only the mean RSS for each reference point is deployed in WKNN while the statistical information is used in ML.SVR obtains better positioning accuracy than ML.Moreover,SVR just needs to compute a simple mapping function and thus the computation cost is less than ML,which needs to compute and sort the likelihood values at all reference points.ANN just performs better than WKNN because of its local optimality and the lower generalization ability than SVR.Therefore,the proposed method obtains the best accuracy with less computation cost.It enables the best balance between accuracy and energy consumption on client devices.

Tab.1 Performance comparison of positioning algorithms
4 Conclusions
A joint AP selection method based on joint location information gain in Wi-Fi indoor environment,is proposed in this paper.The discriminant ability of all available APs is measured by joint location information gain.In contrast to traditional AP selection methods which only measure the discriminant ability of the APs independently,we consider measuring them jointly and give a more accurate measure.The subset of APs with the strongest discriminant ability is selected for positioning.Furthermore,a clustering analysis method is incorporated to localize the AP selection and subsequent positioning.It enables a better balance between the energy consumption on client device and positioning ac-curacy by selecting the most discriminant APs.Besides,SVR is deployed as positioning algorithm after joint AP selection at each sub-radiomap.The relationship between RSS and physical locations is well constructed to estimate the client’s location.
As experiments carried in realistic Wi-Fi environment shown,the proposed AP selection method performs the best and keeps the best balance between computation cost and positioning accuracy.Adding to the good positioning accuracy and low computation cost of SVR,the proposed positioning algorithm enables low energy consumption on client devices while achieving high-level positioning accuracy.
[1]Gu Y Y,Lo A,Niemegeers I.A survey of indoor positioning systems for wireless personal networks.IEEE Communications Surveys& Tutorials,2009,11(1):13-32.
[2]Rodriguez M,Favela J,Martinez E,et al.Location-aware access to hospital information and services.IEEE Transactions on Information Technology in Biomedicine,2004,8(4):448-455.
[3]Kushki A,Plataniotis K,Venetsanopoulos A.Intelligent dynamic radio tracking in indoor wireless local area networks.IEEE Transactions on Mobile Computing,2010,9(3):405-419.
[4]Fang S H,Lin T N.Indoor location system based on discriminated adaptive neural network in IEEE 802.11 environments.IEEE Transactions on Neural Networks,2008,19(11):1973-1978.
[5]Kuo S,Tseng Y.A scrambling method for fingerprint positioning based on temporal diversity and spatial dependency.IEEE Transactions on Knowledge and Data Engineering,2008,20(5):678-684.
[6]Chai X Y,Yang Q.Reducing the calibration effort for probabilistic indoor location estimation.IEEE Transactions on Mobile Computing,2007,6(6):649 -662.
[7]Kaemarungsi K,Krishnamurthy P.Properties of indoor re
ceived signal strength for WLAN location Fingerprinting.Proceedings of the First Annual International Conference on Mobile and Ubiquitous Systems:Networking and Services.Piscataway:IEEE.2004.14-23.
[8]Youssef M,Agrawala A,Shankar A U.WLAN location determination via clustering and probability distributions.Pervasive Computing and Communications,2003.(PerCom 2003).Proceedings of the First IEEE International Conference on.Piscataway:IEEE.2003.143 -150.
[9]Chen K Y,Yang Q,Yin J,et al.Power-efficient accesspoint selection for indoor location estimation.IEEE Transactions on Knowledge and Data Engineering,2006,18(7):877-888.
[10]Brunato M,Battiti R.Statistical learning theory for location fingerprinting in wireless LANs.Computer Networks,2005,47(6):825-845.
[11]Fang S H,Lin T N.Indoor location system based on discriminant-adaptive neural network in IEEE 802.11 environments.IEEE Trans Neural Networks,2008,19(11):1973-1978.
[12]Castro P,Chiu P,Kremenek T,et al.A probabilistic room location service for wireless networked environments.Ubiquitous Computing/Handheld and Ubiquitous Computing-UbiComp(HUC).Jakobl.2003.18-34.
[13]Bahl P,Padmanabhan V N.RADAR:An in-building RF-based user location and tracking system.INFOCOM 2000.Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies.Proceedings.IEEE.Piscataway:IEEE.2000.775-784.
[14]Theodoridis S,Koutroumbas K.Pattern recognition.3rd Ed.Orlando:Academic Press.2005.
[15]Christopher J C,Burges.A tutorial on support vector machines for pattern recognition.Data Mining and Knowledge Discovery,1998,2:121-167.
[16]Keerthi S S,Lin C J.Asymptotic behaviors of support vector machines with Gaussian kernel.Neural Computation,2003,15(7):1667-1689.
[17]Zhang Z Z,Lin Z R.LIBSVM:a library for support vector machines.Taiwan.2006.http://www.csie.ntu.edu.tw/~cjlin/libsvm.
 Journal of Harbin Institute of Technology(New Series)2012年6期
Journal of Harbin Institute of Technology(New Series)2012年6期
- Journal of Harbin Institute of Technology(New Series)的其它文章
- Load distribution of involute gears along time-varying contact line
- High-gain planar TEM horn antenna fed by balanced microstrip line
- Multiband printed monopole and dipole antenna with square-nested fractal
- Research on the Seebeck effect in efficient turning process and improving tool life
- A reliable and high throughput hybrid routing protocol for vehicular ad-hoc network
- An innovative detection method of high frequency BPSK signal with low signal-to-noise ratio