
基于奇异值模型的中国区域经济差异分类研究
2013-07-23 11:10焦爱丽李诚固
统计与决策 2013年8期
焦爱丽,李诚固
(1.东北师范大学城市与环境科学学院,长春130024;2.吉林工商学院教务处,长春130062)
0 引言
中国区域经济发展这一概念在中国改革开放之后才得以真正的发展。伴随着中国改革开放的深入发展,中国区域经济逐渐进入了发展调整的关键时期,如何在未来的发展中为中国区域经济把好脉,就显得尤为重要。此次研究就以中国区域经济差异作为研究对象,通过多指标的测度分析,来找到中国区域经济差异的深层次原因。通过对国内相关文献的研究,我们初步确定了采用奇异值分解方法来进行多指标测度的降维计算,由此来对区域经济发展中的多指标进行有效性融合。
1 中国区域经济差异的奇异值模型构建
1.1 方法研究
对于区域经济差异的研究方法较多,在此仅对其中的经典方法进行论述,主要是三个分析方法,熵系数、差异系数、变异系数法等,其表述为:

说明:变量Entropy代表熵系数;变量CY代表差异系数;变量V代表变异系数;变量pi代表地区i的指标数据在整个区域内该指标的占比比率;变量Xi代表地区i的某项指标数据;变量代表区域内的该项指标的合计;变量n代表区域内的地区数量。
在下面的区域差异分析研究中,我们将采用如上的度量标准进行计算。
1.2 自主研究方法论证
通过以下步骤完成:
第一步:选定区域因素、选择指标集合,来对区域发展进行指标分析数据收集与整理。一般而言,我们用变量m表示区域因素数量,也就是说一共有m个区域作为研究对象。同时,用变量n表示指标因素数量,也就是说一共有n个指标来考量区域发展的质量。还要注意,我们用Am×n矩阵来存储一个观察期的m个区域的、n个指标对应的具体数值。
第二步:利用上述数据,并结合熵系数、差异系数法确定区域发展的差异度。同时需要注意,我们用每个区域的整个观察期的平均差异度做为该区域的差异度数据。将上述数据集中汇总到Bm×n(简写为B)矩阵中。
第三步:考虑矩阵B是一个实系数的非对称矩阵。我们需要对该矩阵进行标准化分解。用传统的若当标准型分析方法无法分解。但是如果考虑矩阵B×BT,不难发现该矩阵是一个实对称矩阵,且该矩阵为一个正定矩阵。这是因为对任意的X,有X(B×BT)XT=(XB)(XB)T=成立。所以对实对称矩阵B×BT而言,有如下分解成立:

说明:W为对角矩阵,其对角线上的元素σi为矩阵BT×B的特征向量的平方根。
对于公式4,我们进行变化,得到下式:

我们令VT=W-1UTB,有下式成立:

将公式5代入到公式7中,得:
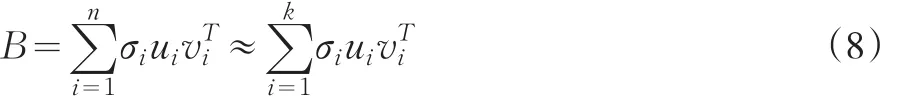
说明:[u1,u2,…,un]=U,[v1,v2,…,vn]=V;变量k为选取的主要奇异值的数量。
完成上述工作后,我们就可以确定一个地区的整体区域差异,是由分量指标如何进行权重配比完成的。

利用前述的分解结果有,X=U×W×VT×Y,对其进行变化,得到下公式:

这样我们就可以将地区整体区域差异度分解为几个关键指标和关键因素的累加和。
1.3 中国区域经济差异的奇异值模型构建
考虑我们提出的14个分量指标中有两项应为总体差异数据,即人均国内生产总值(现价)和地区国内生产总值。将此二者去除,利用剩余的12项指标作为分量指标,将其与31个省(市、自治区)的数据相结合,就得到基础数据A31×12。随后我们即可得到31个地区的差异度数据(平均差异度数据),将其存储在矩阵B31×12中。接下来,我们对矩阵B31×12进行奇异值分解,得到如下结果:


说明:矩阵W中的子矩阵Wsvd为对称标准型矩阵,其它同前述说明。整个计算采用软件Matlab计算完成,下同。
从公式13我们可以看出,对角线上的元素是按照数值大小降序的顺序排列的,居于第一位元素的数据值最大,取值为19.2339;居于之后的数据明显小于该数据,在第三个数据之后,其取值已经小于0.1。这说明,原有的12个指标数据进行平移、旋转等操作后,变换后的数据可以仅仅采用新的3个指标来替代即可。即用19.2339、0.2934、0.1274对应的新指标数据替代即可。这也就反映了1.2中的公式8在本次实证研究中,具体变形为下式:

说明:考虑到文章篇幅,在此对6个向量-u1、u2、u3、对应的数据不再展示。
2 中国区域经济差异的宏观分析
2.1 数据的收集与整理
为了对中国区域经济差异进行研究,我们需要获得相应的区域发展数据来对区域差异进行测度。考虑到这些因素,我们通过查阅中国统计年鉴等相关资料库,初步确定了14个因素作为备选的指标因素,具体如下:地区国内生产总值(现价)、人均国内生产总值(现价)、各地区第一产业增加值、各地区第二产业增加值、各地区工业增加值、建筑业增加值、各地区第三产业增加值、全社会固定资产投资总额、出口总额、国际旅游收入、年末从业人数、第一产业年末从业人员数、第二产业年末从业人员数、第三产业年末从业人员数。同时考虑到研究的有效性和时效性,我们确定研究的时间范围为2001~2011年。最后,我们确定最小的地域单位为省(市、自治区)。通过基础调研,将符合上述要求的数据汇总整理。
2.2 中国区域经济差异分类测度
在此就区域经济差异进行分类测度,分类就采用上述的14个指标进行分类,差异度计算则采用公式2所示的差异度计算公式。通过计算,最终得到如下结果(参见表1)。
由于表1中所包含的数据项较多,且每种数据项的取值范围存在明显的差异。因此,我们将通过分类进行曲线拟合分析的方法进行深入分析。具体说来,将指标分为四类:产业就业人数为第一类,各产业增加值为第二类,产值为第三类,其它数据为第四类。整个曲线拟合与展示采用Excel2003完成。
从图1中可以清晰地看出,产业就业人数差异度总体上出现泾渭分明的变化趋势。其中,第二产业、第三产业的就业人数差异度在2009年之前呈现出逐步下降的趋势;第一产业的就业人数差异在2009年之前呈现出逐步放大的趋势。在2001~2009年这段时间,第三产业的就业人数差异度降幅明显低于第二产业的就业人数差异度降幅。在2009年之后,第一、第二、第三产业的就业人数差异度均呈现出V字形变化,且V字形的右侧端口高度是略微高于左侧端口的高度,这说明经过国家的产业调整与产业扶持之后,产业就业差异度最终出现了小幅上升。

表1 中国区域经济差异分类测度结果

图1 产业就业人数差异度变化图

图2 产业增加值差异度变化图
从图2中可以看出,产业增加值差异度出现三类变化特征。第一类的特征为稳步下降的特征,这主要体现在各地区第三产业增加值的差异度方面。第二类的特征为U字形反转的特征,这主要体现在第二产业增加值的差异度方面。在第二产业增加值差异度方面,工业增加值的差异度明显低于建筑业增加值的差异度,且建筑业增加值的差异度停留在U字形谷底的时间要明显短于工业增加值的差异度在其U字形谷底停留的时间。第三类的特征为整体平稳发展的特征,这主要体现在各地区第一产业增加值的差异度方面。虽然第一产业增加值差异度起点较高,但是除去个别年分外,其发展整体式平稳的,仅仅在2003年出现短期冲高现象,随后又迅速回落了。

图3 产值差异度变化图

图4 其它数据差异度变化图
从图3中可以清晰地看出,产值差异度出现了颇具特点的变化规律。以地区国内生产总值差异度为例,其发展变化规律为:先平稳发展,随后快速上升,最终急速滑落。滑落后的数值基本与起点处的数值持平。而人均国内生产总值的发展变化规律则为敞口的V字形变化,其历史最低点在样本时间点的中期,V字形的两侧端口基本持平,V字形的两侧基本对称。
从图4中可以看出,其它数据的差异度出现三类变化特征。第一类的特征为稳步上升式的特征,这主要体现在出口总额的差异度方面。第二类的特征为平稳发展的特征,这主要体现在人均国内生产总值(现值)和全社会固定资产投资总额差异度方面。第三类的振荡式发展发展的特征,这主要体现在国际旅游收入的差异度方面。
3 多指标下的中国区域经济差异的模型化分析与研究
我们以人均地区国内生产总值差异度作为综合指标,用1.2中所说的其中xi代表第i个地区的国内生产总值差异度;以2.1中确定的12个指标作为分量指标。这样我们遵循1.2中的公式10,就可以确定区域经济发展差异的分解模型,
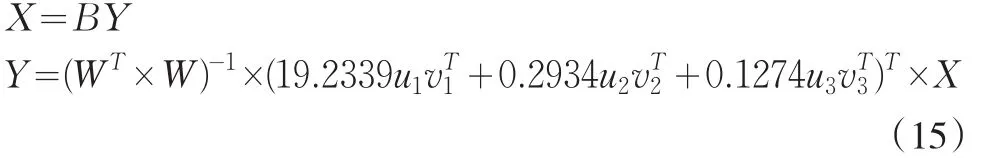
说明:变量说明与前述一致,不再赘述。
利用上述模型结果的各项参数,计算中国各区域发展之间的皮尔逊系数(简称相关系数,下同),从而对中国区域经济发展进行统计分类,得到如下结果(参见表2)。
从表2中展示的计算结果可以看出,中国区域经济的发展差异可以分为六个类,从第一类到第六类是根据皮尔逊相关系数计算得到,而计算皮尔逊相关系数所采用的向量数据则是采用奇异值分解的模型的结果。第一类的相

表2 中国区域经济差异分类研究结果
4 结论
关系数绝对值最高,达到了0.90-0.95;第二类的相关系数的绝对值次之,取值范围在0.75-0.90之间;第三类的相关系数绝对值又次之,达到了0.65-0.75;第四类的相关系数的绝对值低于第三类的取值,取值范围在0.55-0.65之间;第五类的相关系数绝对值更低,取值范围在0.45-0.55之间;第六类的相关系数的绝对值最低,取值范围在0.35-0.45之间。且每种类型所包含的对象数量也不同,第一类包含对象为1个,第二类包含对象2个,第三类包含对象5个,第四类包含对象9个,第五类包含对象9个,第六类包含对象数量为5个。在中国经济发展中具有倾斜扶持越多的区域其经济发展质量明显高于倾斜扶持越少的区域,且发展的差异是随着倾斜扶持数量的增加而增加的。北上广作为中国经济改革开放的重点支撑领域,其中北京作为中国的政治中心、经济中心、文化中心等中心;上海、广东作为中国经济发展的率先示范、重点扶持地区,在经济发展中享受了过多的倾斜性扶持,从而居于中国区域经济发展的最高端。长三角地区作为上海、广东经济圈的双重辐射区域,其经济发展受到的优惠、扶持自然不少,从而间接促进了其经济发展。而作为中部地区、西部地区其在政策上享受的倾斜性是自西部大开发以来才逐渐显现,而此开放力度是重点体现在西部的几个重点省——陕西、内蒙古、重庆等。这些省通过10多年的政策扶持,经济发展取得了突破性进展。而作为广大的西部地区,其整体经济发展依然滞后。这一点可以从最不发达地区(即第六类区域)中皆为西部地区得到体现。要想对中国区域经济整体推进,必须针对中西部地区的特点,制定出符合其自身特点的政策扶持方向,以及与之对应的政策扶持力度,才能提高此类区域的发展动力与持久力。这一点从西部地区内部的差异化发展中已经得到了充分体现。反观在此期间的东北地区发展,由于政策指引正确,扶持力度到位,加上当地政府的大力推进,东北三省的经济发展在中国整体经济发展中已经凸显出了明显的优势与特征,整体经济发展水平居中。中部地区由于受到东部经济发展的促进和吸引,其经济发展形势逐渐好转。
通过上述分析,尤其是针对模型提供的分析结果,我们对中国区域经济发展产生的差异的深层次原因进行了论述,这也就是解释了,通过合成指标构成的新的指标因素对中国区域经济发展差异的合理性和正确性。
本文以中国大陆地区的31个省(市、自治区等)为最小数据单元,展开区域发展差异的多指标测度研究。在研究初期,我们通过广泛阅读国内外文献、方法论,确定了此次研究的思路,并结合前人的研究成果,自主构建了区域经济差异的分析模型,该模型是完全针对多指标确定的模型。在完成上述理论准备后,我们对最小研究单元的经济发展指标进行选取与测度,成功获取了它们在近10多年的主要指标数据。利用这些数据作为基础数据,进行了区域发展差异的宏观分析。从三大类,12个指标项对中国区域经济发展的差异度变化进行了深入研究,确定了各指标项的差异发展变化特征。在此基础上,针对整体差异度无法与分项差异度指标相结合的不足,利用自主构建的差异模型进行了模型研究。模型研究的重点是将基于GDP的整体差异度分解到12个分项指标的差异度上去,并根据分解结果得到的重要参数,对中国区域经济发展中存在的差异度进行分类。通过上述分析研究,最终有效地将中国区域经济发展存在的差异度,分解到3个最重要的新合成指标上来。从而有效地降低了对区域经济发展差异度分析指标过多,效果不理想的问题。利用这3个新合成的指标项,我们对中国区域经济发展进行了差异度深入分析,最终对中国区域经济发展存在的差异度进行了有效分类。从而找到了落后地区经济发展相对滞后的原因---政策扶持方向与当地现状吻合度不足,或政策扶持力度不足的问题。针对上述原因,在中国区域经济发展中,尤其是落后地区的区域经济发展中,如果能更加有针对性、更加有重点地提出区域经济发展扶持政策与政策力度,必将推进中国区域经济发展的更高质量前行。
[1]管卫华,林振山,顾朝林.中国区域经济发展差异及其原因的多尺度分析[J].经济研究,2006,(7).
[2]宫义飞,彭欢,皮天雷.中国区域经济增长和收敛的决定性因素——基于省际面板数据的证据[J].宏观经济研究,2012,(3).
[3]彭文慧.外资特征的区域差异与区域经济增长关系的实证研究[J].统计与决策,2012,(19).
[4]Kun Chen,Kung-Sik Chan,Nils Chr.Stenseth.Reduced Rank Sto⁃chastic Regression with a Sparse Singular Value Decomposition[J].Journal of the Royal Statistical Society:Series B(Statistical Methodol⁃ogy),2012,74(2).
[5]Christopher J.Martinez,James W.Jones.Atlantic and Pacific Sea Sur⁃face Temperatures and Corn Yields in the Southeastern USA:Iagged Relationships and Forecast Model Development[J].International Jour⁃nal of Climatology,2011,31(4).
猜你喜欢
四川化工(2022年3期)2023-01-16
现代制造技术与装备(2022年2期)2022-12-17
中国经济周刊(2022年8期)2022-05-07
发明与创新·小学生(2021年3期)2021-03-25
消费导刊(2018年9期)2018-08-14
北京教育·普教版(2017年1期)2017-02-05
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
