
数据挖掘技术在高校图书馆中的应用
2013-10-25 03:23王若亭
铜仁学院学报 2013年5期
王若亭
( 贵州财经大学 图书馆,贵州 贵阳 550004 )
一、背景及意义
随着数据库技术的飞速发展,人们获得数据的手段越来越多。当前,人类拥有的数据在急剧地增加,但是对这些数据进行分析处理却很少,也就出现了人们所说的“数据丰富,知识贫乏”的局面。虽然说数据库技术在不断地提高,但是大多数的数据库系统也只是对数据库中的数据进行存取、检索、查询和统计等基本操作。人们通过数据库系统也只能获取对数据的统计、分类等少量信息,无法发现数据间存在的联系和规则,更难以发现隐藏在大量数据背后的信息。然而,隐藏在这些数据之后的信息才是更重要的。
高校是国家人才培养的基地,而图书馆是高校师生获取知识的最集中、最丰富的场所。图书馆的藏书布局对读者、学者有着很重要的指导意义。合理的馆藏布局不仅能方便读者获取所需的书籍,并且能推荐、指导其找到与之相关的书籍。数据挖掘作为对数据库系统中的数据进行分析、分类和推测的这样一门新技术,能够很好地解决图书馆大量数据背后的信息难题。因此,研究数据挖掘技术在图书馆管理系统中的应用具有非常重要的实际意义。
二、高校图书馆应用数据挖掘技术的现状、可行性和必要性
数据挖掘可以应用在很多领域,特别是在银行、保险、网上商城、交通和百货等领域中。对工作的开展、业务的推广和产品的促销等方面都起到很大的推进作用。因此,数据挖掘技术在很多领域内的应用也给图书馆的服务带来了启发。高校图书馆的读者具有年龄段相同、专业领域多样、数量多和研究方向不同等特点,这就要求图书馆能够提供给读者个性化、人性化的服务。在国外,图书馆的个性化服务开展得比较好。其中美国康耐尔大学的“我的图书馆”(My Library,图书馆的个性化服务系统)最具特色。另外,新西兰克莱斯特彻奇教育学院的“我的图书馆”,美国华盛顿大学图书馆的“我的门户”和加利福尼亚大学洛杉矶分院的“我的学院”等都是比较出名的国外图书馆个性化服务系统。在国内,陆续有高校图书馆开始推广图书馆个性化服务系统,比如华中科大图书馆的Mylibrary@HUST,它提供了期刊订阅,网页信息订阅和多数据库统一检索等服务。我馆使用金盘图书馆管理系统已有十余年,拥有大量的书目数据和流通数据,具备了数据分析环境。笔者在图书馆负责金盘图书馆管理系统的数据库维护工作,可以对所需要的书目、流通等数据进行数据采集。高校图书馆若能够提供给读者个性化的服务,将会大大地促进图书馆的发展,使更多的读者喜欢图书馆,愿意到图书馆来享受知识的熏陶。特别是如果我校能在新校区建立的新图书馆应用数据挖掘技术,分析出读者的借阅习惯和图书的关联,就能够安排合理的馆藏布局。这将方便读者借阅,对新馆的布局起到很好的指导意义。
三、数据挖掘的概念及相关技术
(一)概念
数据挖掘(DM,Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的,但又是潜在的有用信息和知识的过程。还有很多和这一术语相近的术语,如从数据库中发现知识(KDD),进行数据分析、知识抽取、模式分析、数据考古、数据采集、信息收割、商业智能、数据融合,以及决策支持等[1]。
(二)相关技术
本文应用数据挖掘技术中的关联规则和聚类分析来对图书馆的数据进行分析。
1.关联分析
关联分析就是从大量的数据中发现项集之间有趣的关联、相关关系或因果结构,以及项集的频繁模式。数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的取值之间存在某种规律性,就称为关联[2]。也就是说某两个或多个变量的组合频繁出现,就可以说这个组合是一种关联规则。
2.聚类
聚类是一种特殊的分类,与分类分析法不同的是,聚类分析是在预先不知道欲划定类的情况下,根据信息相似度原则进行信息集聚的一种方法。聚类的目的是根据最大化类间的相似性、最小化类间的相似性这一原则合理地划分数据集合,并用显式或隐式的方法描述不同的类别[2]。
3.支持度和置信度
支持度(Support)和置信度(Confidence):关联规则表示为:X=>Y 的蕴涵式,这里 X⊂I,Y⊂I,并且 X∩Y=Ø。D 中的规则 X=>Y 是由支持度(support)和置信度(confidence)这两个数值来约束。支持度是事务D中包含X∪Y的百分比,即概率,置信度是事务D中包含X的事务同时也包含Y的百分比,即条件概率。具体描述是:

最小支持度与最小置信度:在进行关联规则挖掘时,要求用户预先设定支持度和置信度阈值,即在挖掘过程中只产生满足这两个阈值要求的关联规则,对于这样的支持度和置信度通常分别称为最小支持度(min_supp)和最小置信度(min_conf)。在事务数据库中挖掘关联规则的任务,就是在其中找出所有满足用户或专家指定最小支持度和最小置信度的强关联规则[3]。
四、图书馆业务数据的关联分析和聚类分析
(一)借阅图书类别间的关联分析
科技的发展使得学科间的联系越来越密切。读者在学习专业知识的过程中,经常要对一些相关知识进行了解、学习,这些相关知识可能属于同一领域中的不同学科,也可能属于完全不同的领域。通过对大量的读者借阅图书行为进行分析,能够找出图书类别之间的某些联系。这样既可以指导读者学习相关知识,更好地掌握、巩固专业知识,又能够合理地布局馆藏,以提高图书馆的服务水平和图书借阅率。
在对借阅图书类别进行关联分析中,笔者运用了数据挖掘分析工具对我校2008级学生3年的借阅数据进行分析。本次分析得出的结果是文学大类间的关联度比较高,比如I2中国文学类和I3各国文学类的支持度达到4.3%,置信度达到46.6%。在这一次关联分析结果中,唯一的大类间的关联就是 H3(常用外国语类)和O1(数学类),支持度为7.3%,置信度为37.7%。关联分析得出这样的结果,应该考虑英语和数学都是大学的基础课程和考研的必考课程,学生在准备考试的时候会同时借阅这两类图书。根据这样的分析结果,可以把它应用到图书馆馆藏布局上。通常图书馆都是按图书类别来排架,同学在借阅基础课程的书或考试科目的书时,要分别到不同类别的书架中查找,有时可能要跑几个书库才能借齐所需的书。通过这样的分析,我们可以将各类考试书籍和基础课程的图书放在一起,方便读者借阅。
(二)读者专业与其所借阅图书类别的关联分析
读者的阅读习惯和喜好是比较固定的,某专业的读者可能偏好于借阅某一类型的图书。对读者的专业与其所借阅的图书类别进行关联分析,可以掌握某专业读者的读书兴趣,在必要时可以向读者推荐他们所需的专业图书或感兴趣的图书。这样就减少了读者查找所需图书的时间,提高图书馆对读者服务的质量。
通过对专业和图书分类的关联进行分析,得到的结果为我校法学专业的学生所借的图书与D9(法律类)有关联,其置信度达到了63.867%。从这可看出法学专业的学生对于自身的专业书籍很感兴趣。这样的结果分析可以应用到读者个性化服务中,读者到图书馆借阅的图书通常与自己的专业有关系,因此,图书馆的工作人员可以根据读者的专业向他们推荐书籍,或者针对不同专业的读者分别开展专业类书籍的图书推广活动。
(三)读者借阅活跃程度的聚类分析
在大学读书期间,有的读者经常到图书馆借阅图书,而有的读者可能到办理离校手续时才第一次来图书馆。通过读者的借书数量对读者进行聚类分析,可将读者分为三类:活跃型读者、一般型读者、不活跃型读者。通过这样的方式对读者进行分类以后,图书馆可以根据实际情况来提高活跃型读者的借书册数,更好地推进他们读书的积极性,对于一般型读者和不活跃型读者,图书馆的工作人员应该加强与他们的联系和沟通,引导他们来图书馆借书。
图1显示出2008级本科生借书活跃程度划分结果。在读者借阅信息相关栏目中,我们可以看到有一些读者在入校3年中累计借阅的图书200多本,每个月差不多要借阅 7册的图书。这样的借阅行为是非常频繁、借阅量非常大的。我校图书馆目前设定每位本科生每次最多的借书册数是6册,对于图1中张海燕同学这类热爱读书的读者,每次借 6册图书的数量是不够的。根据聚类结果的划分,图书馆可以统一增加活跃类读者的借书册数,以满足该类型读者的需要。而对于不活跃型读者,图书馆利用推送技术(如Email、短信息等)主动发送读者感兴趣的信息,可增加这部分读者到馆借阅的机率。
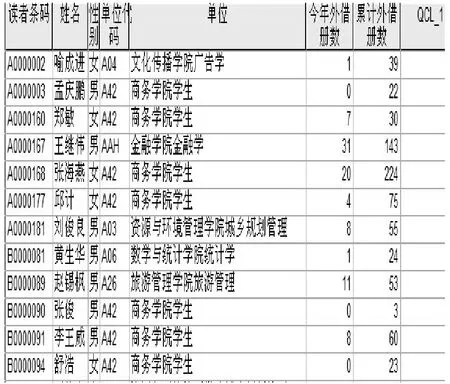
图1 2008级本科生借书活跃程度划分结果
(四)图书借阅活跃程度的聚类分析
图书馆里的藏书共计上百万册,有的图书借阅率很高,往往供不应求,书还没有归还,就被读者预约,而有的图书也许上了书架,就没有被人借阅过。对图书借阅活跃程度进行聚类分析,能使工作人员掌握热门图书的类别,加大图书的购买种类和册数,减少冷门图书的购买。这样合理规划,能最大限度地使用有限的购书经费。
图2、图3分别显示出热门图书、冷门图书类别的借阅次数。对我馆所有的馆藏图书进行聚类分析得出的结果是 I2(中国文学)、H3(常用外国语)、I1(世界文学)和I3(各国文学)都是热门类型的图书,如图2所示。而H0(语言学)、O3(力学)、TG(金属学与金属工艺)、D0(政治理论)等类别的图书几乎没有人借阅过,如图 3所示。将分析结果应用到图书采购上,采购人员应加大对I2(中国文学)、H3(常用外国语)、I1(世界文学)和I3(各国文学)图书的购买种类和册数,减少H0(语言学)、O3(力学)、TG(金属学与金属工艺)和 D0(政治理论)等类别冷门图书的购买。经过这样的合理规划,能最大限度地使用有限的购书经费。在馆藏布局上,对于冷门图书,可以将他们放置在基藏书库,节省图书馆书库的空间。而热门图书放置在读者进出的位置,方便读者取阅。
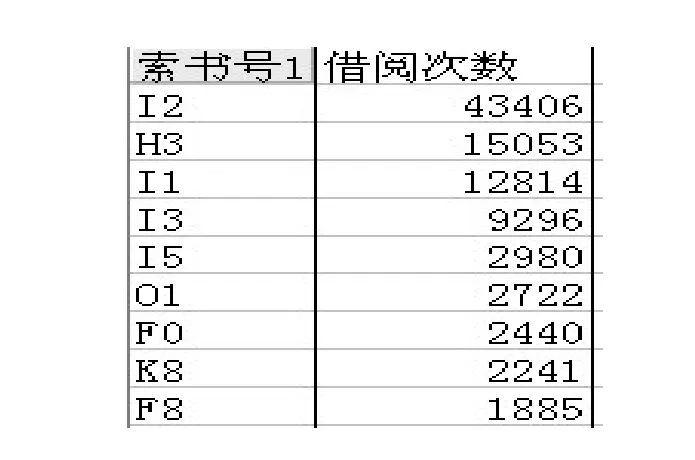
图2 热门图书类别的借阅次数
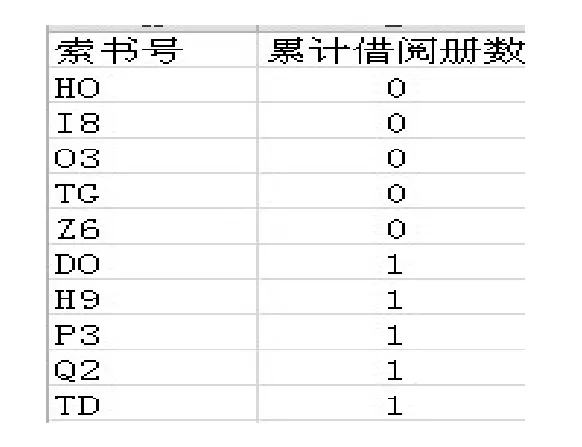
图3 冷门图书类别的借阅次数
五、总结与结论
通过对读者数据、书目数据和借阅数据的挖掘分析,总结归纳,使之应用到图书馆的读者服务、图书采购和馆藏布局3个方面。对读者个性化服务,采取的措施主要是:根据读者的专业推荐书籍,对各专业读者开展专业书籍的推广活动,增加活跃型读者的借书册数,加强与不活跃型读者的联系,来提高他们的借书兴趣。在图书采购方面,可以增加热门图书的购买册数,增加热门图书类型购买的种类,加大对活跃类型专业书籍的购买,减少冷门类型图书的购买。在馆藏布局方面,考试类和基础课程的图书摆放在一起,热门书籍放置在方便读者取阅的地方,冷门书籍收藏到基藏书库,这样可以节省书库的空间。
[1]邵峰晶,等.数据挖掘原理与算法[M].北京:中国水利水电出版社,2003.
[2]苏新宁.数据挖掘理论与技术[M].北京:科学技术文献出版社,2003.
[3]王正宇.数据挖掘在读者偏好研究中的应用[D].上海交通大学,2010.
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
数学小灵通(1-2年级)(2022年6期)2022-06-17
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
幼儿智力世界(2020年4期)2020-10-29
计算机应用(2018年5期)2018-07-25
快乐语文(2018年12期)2018-06-15
民族古籍研究(2018年1期)2018-05-21
西夏学(2016年2期)2016-10-26
新高考·英语进阶(高二高三)(2016年1期)2016-03-05
