
随机对照试验中不依从数据的主分层分析方法*
2014-04-04 03:26哈尔滨医科大学卫生统计教研室150081陈永杰张秋菊李慧婷刘美娜
中国卫生统计 2014年6期
哈尔滨医科大学卫生统计教研室(150081) 陈永杰 张秋菊 陈 霞 李慧婷 刘美娜
随机对照试验(randomized controlled trials,RCTs)是在“随机化”有效控制混杂因素的前提下估计处理效果的标准方法,广泛用于各研究领域中,例如教育研究、医学研究、心理研究及社会研究等[1]。然而,实际中随机对照试验经常会遇到不依从和结果缺失两个主要问题[2]。不依从(non-compliance)是指研究对象在随机分组后,不遵从试验的规定,随意改变处理措施或退出试验的现象。不依从现象往往会破坏随机化原则使最终的处理效应出现偏倚,导致很难准确估计处理的因果效应。目前针对随机对照试验中存在不依从数据的分析方法主要有:意向性分析(intention-to-treat,ITT)、接受干预措施分析(as-treated,AT)及遵循研究方案分析(per-protocol,PP)[3]。ITT估计遵循原来的随机分配,即“一旦被随机分配,就要参与分析”[2]的原则,将个体的不依从信息忽略掉,按照最初随机分配到处理组或对照组即作为处理个体或对照个体进行分析。由于不依从的影响,处理组中有对照组的效应,对照组中也有处理组的效应,该估计实际不是“处理措施”的因果效应而是“随机分配”的因果效应。ITT估计保证样本量的同时也引入了异质性,增大Ⅱ类错误的概率,低估处理措施的因果效应。AT估计是实际接受的处理,既不是处理的因果效应估计,也不是随机分配的因果效应估计,它破坏了随机化分组,造成选择偏倚的出现。PP估计是忽略不依从的个体,比较依从个体的效应,是处理的因果效应估计,但会减少样本含量,增大Ⅰ类错误的概率,高估处理措施的因果效应。
以上三种方法是分析随机对照试验不依从数据的经典方法,各有不足之处。近些年来,国外针对不依从数据的分析方法应运而生,包括工具变量(instrumental variables,IV)、主分层(principal stratification,PS)、倾向性得分(propensity scores,PS)和结构均数模型(structural mean model,SMM)[1]等,主要应用于社会研究和教育研究中,但并未涉及医学研究;国内依然使用ITT、PP和AT等传统方法,但是这些方法都不能在考虑不依从信息的同时给出准确的处理措施的因果效应估计,而主分层在一定程度上解决了这个难题。本文主要介绍主分层方法的原理,为解决随机对照试验的不依从问题提供新的方法,并为医学中的不依从数据分析开拓新的思路。
主分层的原理
主分层思想是因果效应估计中非常重要的思想,由Frangakis和Rubin于2002年正式提出[4]。不同处理组数所产生的主分层数不同,本文只对一个处理组和一个对照组的情形进行阐述,将观察个体按照分配的处理和可能接受的处理分成四层进行因果效应估计[4-5],分层如表1所示。

表1 主分层各层的定义
在主分层思想中,根据个体分配的处理和实际接受的处理判定其相应的主分层类型。实际中,个体只能接受一种处理,即不能同时被分到处理组和对照组,这会导致一部分结果观测不到,处理的因果效应不可识别[6]。为解决这一难题,主分层思想从个体扩展到群体。通过“随机化”使两个群体中的个体成为“理想化”的同质体,即解决了个体不能同时接受两种处理的难题,使处理的因果效应可识别。
应用主分层的另一个难题就是层数过多会给估计带来巨大的工作量,即使是最简单的四层也会导致繁琐的计算。在带有不依从现象的随机对照试验研究中,对照组通常无法获得处理组的处理措施,即不存在Di(0)=1,从表1中可以看出Always-taker和Defier两个层被排除,主分层类型只有两种可能:Complier和Never-taker[6]。由于处理组接受处理措施,它的依从性可以观察到;对照组的依从性不可观察[7]。在基于随机化假设下,认为处理组和对照组是均衡可比的,可以通过处理组的依从性推导对照组的依从性。这种情形的因果效应估计方法有基于Bayesian[5,8]的估计或基于Likelihood方法的估计[9-11]。也有学者将Bayesian和Likelihood方法应用于部分不依从数据的因果效应估计[12-13]。实际中,经常使用依从者的平均因果效应(complier average causal effect,CACE)估计处理措施的因果效应。
CACE的估计
依从者的平均因果效应在计量经济学中又称局部平均因果效应(local average treatment effect,LATE)[14]。由Sommer和Zeger首先提出该估计的雏形[15],Imbens和Rubin(1997)[5,16]应用Bayesian和Likelihood方法估计LATE(又称CACE)。后来的研究将该估计进行扩展,加入协变量[8],并应用于纵向数据的分析[9]。
在随机对照试验中只有Complier和Never-taker两种可能时对CACE进行估计,并分为仅考虑不依从信息和同时考虑缺失数据两种情况进行阐述。
1.仅考虑不依从信息时的CACE估计
CACE定义如下:
CACE=μ1c-μ0c
(1)
μ1c是处理组依从者的平均潜在结果,μ0c是对照组依从者的平均潜在结果。把对照组的总体均数μ0看作是μ0c和μ0n的混合分布:μ0=(1-πc)μ0n+πcμ0c。πc表示人群中依从者所占的比例,μ0n是对照组从不接受处理者(Never-taker)的均数。方程(1)可以写成:
(2)
学者Imbens,Angrist和Rubin提出五条假设证明了CACE是可识别的[17]。五个假设分别是:
(1)SUTVA假设(stable unit treatment value assumption)[18]:指研究个体间不存在关联性,即个体A是否接受处理与个体B无关;每个个体仅有一种结果被观测到,该假设又称一致性假设(consistency assumption)。
(2)随机化假设:即随机分组,此假设在随机对照试验中是成立的。
(3)排除限制性假设(exclusive restriction assumption,ER):在随机分组中,总是接受处理者(Aways-taker)和从不接受处理者的处理效应为零,同时μ0n=μ1n。
美国能源部(DOE)发言人Shaylyn Hynes称:“此历史性项目是美国近30多年来建设的首个大型核电项目,它将使美国保持在核技术领域的国际领导地位,并在未来数十年为美国提供可靠和清洁的电力。能源部希望该项目的成功建成将标志着美国核复兴的开始。”
(4)单调性假设(monotonicity assumption):在随机对照试验中,违背者(Defier)不存在。
(5)非零分子假设(nonzero numerator assumption):指研究人群中一定会有依从者存在。
在以上五个假设前提下,方程(2)可以变为方程(3),所有的参数都是可以估计得到,CACE可识别。
(3)
以上对CACE的估计是仅考虑不依从而未考虑缺失数据。然而,实际中不依从和缺失数据往往同时出现,数据的缺失对CACE的估计有很大影响,下面介绍考虑缺失数据时CACE的估计。
2.同时考虑不依从和缺失数据时CACE的估计
(4)
(5)
(6)

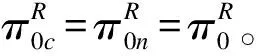
(7)
(8)
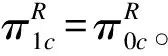
(9)
在实际应用时,要根据试验设计和数据本身的特点来选择不同假设情况下的CACE估计。
实例分析
本文引用G.DUNN等人于2003年发表的一篇文献的例子进行说明[19]。
G.DUNN等使用主分层的CACE方法对The Outcomes of Depression International Network (ODIN)的数据进行分析。ODIN是一个多中心随机对照试验,旨在调查欧洲城乡抑郁症患病率和结局,评估心理干预的效果。研究涉及9个研究中心:芬兰2个,爱尔兰2个,挪威2个,西班牙1个,英国2个。452名参与者被随机分配到三个组,包括解决问题组(n=128)、心理教育组(n=108)和对照组(n=189)。在干预后6个月调查参与者的依从性、失访情况和抑郁症严重程度(the beck depression inventory,BDI)。
CACE的分析结果显示,在不考虑多中心效应和基线协变量的影响下,CACE的估计结果为CACEMAR=-3.47(se=2.22),ITT=-1.88,与ITT的结果相比,CACE的结果显示干预效果更好,但两者都没有统计学意义。然而,在考虑基线协变量和基线BDI得分且假设数据缺失为随机缺失的情况下,CACE=-5.48(se=2.99),ITT=-2.34(se=0.94)。而灵敏度分析结果显示,当排除限制假设不成立,假设在不依从的人群中随机分配的效应在-2.5和2.5之间变化时,CACE的分析结果仍然显示干预有效果。当随机分配效应在-2.5时,CACE=-3.18(se=3.66),当随机分配效应在2.5时CACE=-6.04(se=1.73),这个结果与预期的当随机分配效应值为负值时CACE的值会接近于0并不一致,因此可以认为即使在假设条件不成立时,CACE估计仍然在合理的范围内。
以上分析结果显示,在考虑不依从和失访的情况下,CACE估计比ITT估计更准确,更能显示出干预措施的有效性;即使在前提假设条件不成立时,仍能得到比较稳健的CACE估计。
使用主分层应注意的问题
主分层在分析随机对照试验不依从数据时,在多个假设条件的基础上,可以充分利用所有数据的信息对处理措施的因果效应进行估计。在实际试验中,当有些假设不成立时,使用这些假设对因果效应进行估计得到的结果必定是有偏的,此时使用主分层估计因果效应,要对结果进行灵敏度分析,比较在假设不成立时结果是否会发生显著性变化,使最终的结果更加准确可靠[20]。
这里提出主分层的分析方法并不是提倡研究者在将来的数据分析时替代ITT等经典方法,而是要把主分层分析当做主要的分析之一,这样才能从数据中挖掘出更多有用的信息,对结果给出更加合理的解释[19]。
总结与展望
主分层方法在分析随机对照试验不依从性数据方面已经显示出了独特的优势,在实际数据满足几个假设条件的情况下得到的因果效应估计值比ITT、PP和AT更加准确可靠,但也有自身的局限性。如其所建立的几个假设在实际数据中是否成立就是一个很大的限制,在层数较多时因果效应的估计更加繁琐,这些都是主分层方法至今难以解决的问题。不过相信随着科技的发展、统计学家不断地专研探索,以上难题会逐渐得到解决,使主分层方法更加趋于成熟稳健。
参 考 文 献
1.张熙.多重填补方法估计存在不依从与缺失值的随机对照试验的因果效应.见林隧恒,主编.流行病与卫生统计学,2012.
2.Gupta SK.Intention-to-treat concept: A review.Perspect Clin Res,2011,2(3):109-112.
3.Rubin DB.[On the Application of Probability Theory to Agricultural Experiments.Essay on Principles.Section 9] Comment: Neyman (1923) and Causal Inference in Experiments and Observational Studies.Statistical Science,1990,5(4):472-480.
4.Nagelkerke N,Fidler V,Bernsen R,et al.Estimating treatment effects in randomized clinical trials in the presence of non-compliance.Stat Med,2000,19(14):1849-1864.
5.Holland PW.Statistics and causal inference.Journal of the American statistical Association,1986,81(396):945-960.
6.Jo B,Ginexi EM,Ialongo NS.Handling missing data in randomized experiments with noncompliance.Prev Sci,2010,11(4):384-396.
7.Peng Y,Little RJ,Raghunathan TE.An extended general location model for causal inferences from data subject to noncompliance and missing values.Biometrics,2004,60(3):598-607.
8.Rubin DB.Randomization analysis of experimental data: The Fisher randomization test comment.Journal of the American Statistical Association,1980,75(371):591-593.
9.Rubin DB.Causal inference using potential outcomes.Journal of the American Statistical Association,2005,100(469).
10.Dunn G,Maracy M,Tomenson B.Estimating treatment effects from randomized clinical trials with noncompliance and loss to follow-up: the role of instrumental variable methods.Stat Methods Med Res,2005,14(4):369-95.
11.Frangakis CE,Rubin DB.Addressing complications of intention-to-treat analysis in the combined presence of all-or-none treatment-noncompliance and subsequent missing outcomes.Biometrika,1999,86(2):365-379.
12.Levy DE,O’Malley AJ,Normand SL.Covariate adjustment in clinical trials with non-ignorable missing data and non-compliance.Stat Med,2004,23(15):2319-2339.
13.Frangakis CE,Rubin DB.Principal stratification in causal inference.Biometrics,2002,58(1):21-9.
14.Rubin DB.Bayesian inference for causal effects: The role of randomization.The Annals of Statistics,1978:34-58.
15.Guo T.Causal effects in randomized trials in the presence of partial compliance: breastfeeding on infant growth.McGill University.2009.
16.Little RJ,Rubin DB.Causal effects in clinical and epidemiological studies via potential outcomes:concepts and analytical approaches.Annual review of public health,2000,21(1):121-145.
17.McNamee R.Intention to treat,per protocol,as treated and instrumental variable estimators given non-compliance and effect heterogeneity.Stat Med,2009,28(21):2639-2652.
18.Pearl J.Causal inference in statistics:An overview.Statistics Surveys,2009,3: 96-146.
19.Dunn G,Maracy M,Dowrick C,et al.Estimating psychological treatment effects from a randomised controlled trial with both non-compliance and loss to follow-up.Br J Psychiatry,2003,183:323-331.
20.Jo B,Vinokur AD.Sensitivity Analysis and Bounding of Causal Effects With Alternative Identifying Assumptions.J Educ Behav Stat,2011,36(1):415-440.
猜你喜欢
甘肃教育(2021年12期)2021-11-02
军事文摘(2020年18期)2020-10-27
铁道通信信号(2020年9期)2020-02-06
劳动保护(2019年7期)2019-08-27
数学大王·趣味逻辑(2019年5期)2019-06-13
福建基础教育研究(2019年11期)2019-05-28
小学科学(学生版)(2019年5期)2019-05-21
动漫星空(兴趣百科)(2018年4期)2018-10-26
中学科技(2015年1期)2015-04-28
数学大世界·小学低年级辅导版(2010年12期)2010-11-27
